Cinque semplici passi per implementare uno schema a stella in Databricks con Delta Lake
Un modo aggiornato per ottenere costantemente le migliori prestazioni dai database con schema a stella utilizzati nei data warehouse e nei data mart con Delta Lake
- Utilizza le tabelle Delta per creare le tabelle dei fatti e delle dimensioni.
- Utilizzare Liquid Clustering per garantire dimensioni file ottimali.
- Usa il Liquid Clustering sulle tue tabelle dei fatti.
Stiamo aggiornando questo blog per mostrare agli sviluppatori come sfruttare le ultime funzionalità di Databricks e i progressi di Spark.
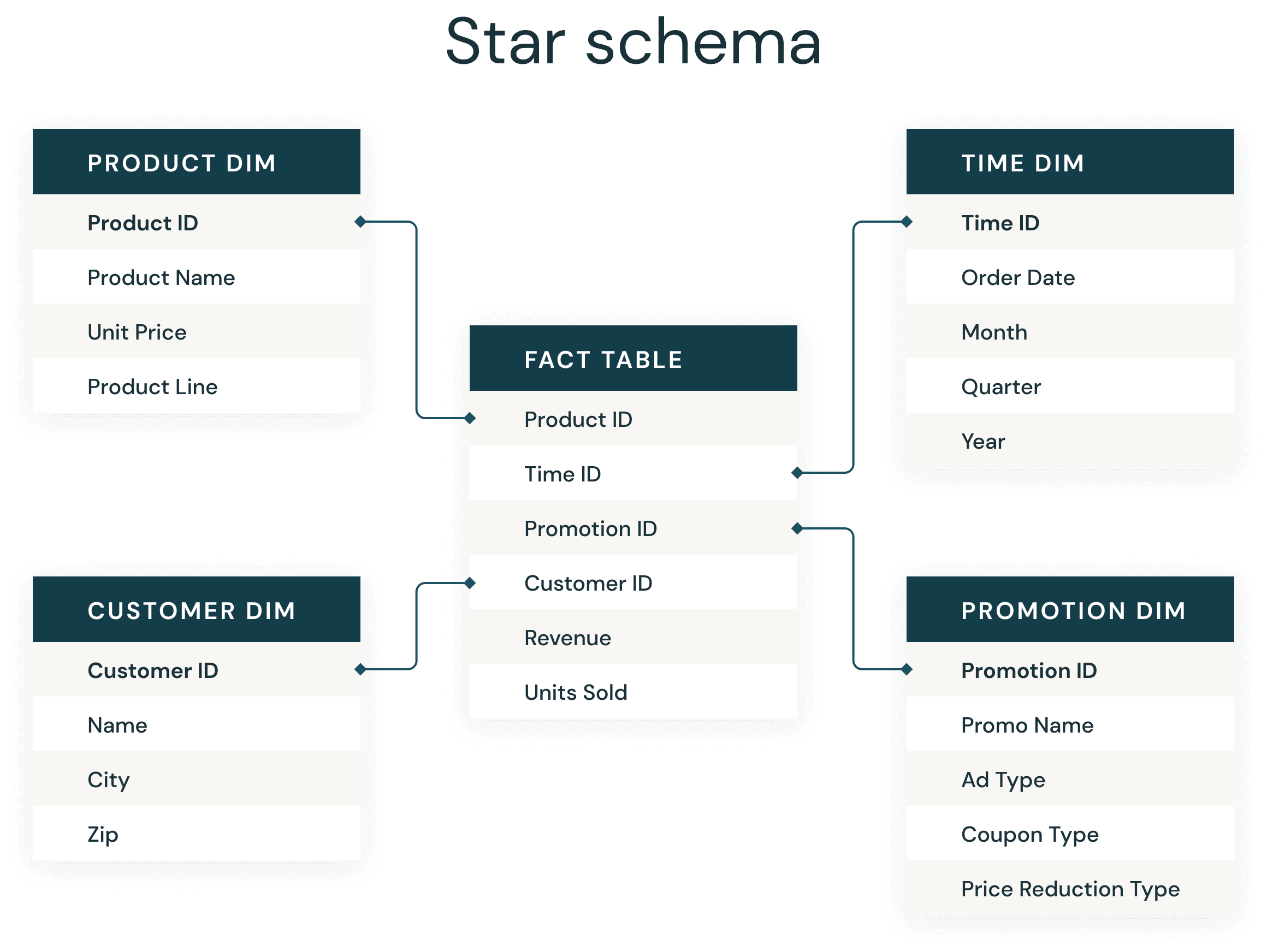
La maggior parte degli sviluppatori di data warehouse conosce molto bene l'onnipresente schema a stella. Introdotto da Ralph Kimball negli anni '90, uno schema a stella viene utilizzato per denormalizzare i dati aziendali in dimensioni (come tempo e prodotto) e fatti (come transazioni in importi e quantità). Uno schema a stella archivia i dati in modo efficiente, mantiene la cronologia e aggiorna i dati riducendo la duplicazione di definizioni di business ripetitive, rendendo veloci l'aggregazione e il filtraggio.
L'implementazione comune di uno schema a stella per supportare le applicazioni di business intelligence è diventata così di routine e di successo che molti data modeler possono praticamente crearli a occhi chiusi. In Databricks, abbiamo prodotto moltissime applicazioni di dati e siamo costantemente alla ricerca di approcci di best practice che servano come regola generale, un'implementazione di base che garantisca un ottimo risultato.
Proprio come in un data warehouse tradizionale, ci sono alcune semplici regole empiriche da seguire su Delta Lake che miglioreranno in modo significativo i join dello schema a stella Delta.
Ecco i passaggi fondamentali per avere successo:
- Utilizza le Delta Table per creare le tabelle dei fatti e delle dimensioni.
- Utilizzare Liquid Clustering per ottenere le migliori dimensioni dei file
- Utilizza il Liquid Clustering sulle tue tabelle dei fatti
- Utilizza Liquid Clustering sulle chiavi della tabella delle dimensioni più grande e sui predicati probabili
- Sfruttare l'ottimizzazione predittiva per la manutenzione delle tabelle e la raccolta di statistiche
1. Utilizzare le tabelle Delta per creare le tabelle dei fatti e delle dimensioni
Delta Lake è un layer con formato di archiviazione aperto che semplifica inserimenti, aggiornamenti ed eliminazioni, e aggiunge transazioni ACID alle tabelle del data lake, facilitando manutenzione e revisioni. Delta Lake offre anche la possibilità di eseguire il dynamic file pruning per ottimizzare le query SQL e renderle più veloci.
La sintassi è semplice su Databricks Runtimes 8.x e versioni successive (l'attuale runtime Long Term Support è ora 15.4), dove Delta Lake è il formato di tabella default. È possibile creare una tabella Delta usando SQL nel modo seguente:
CREATE TABLE MY_TABLE (COLUMN_NAME STRING) CLUSTER BY (COLUMN_NAME);
Prima del runtime 8.x, Databricks richiedeva la creazione della tabella con la USING DELTA sintassi.
Prima del runtime 8.x, Databricks richiedeva la creazione della tabella con la sintassi USING DELTA.
2. Usa Liquid clustering per ottenere la dimensione ottimale dei file
Due delle maggiori perdite di tempo in una query Apache Spark™ sono il tempo impiegato per la lettura dei dati dallo storage cloud e la necessità di leggere tutti i file sottostanti. Con data skipping su Delta Lake, le query possono leggere selettivamente solo i file Delta che contengono i dati pertinenti, con un notevole risparmio di tempo. Il data skipping può essere d'aiuto con static file pruning, dynamic file pruning, static partition pruning e dynamic partition pruning.
Prima del Liquid Clustering, questa era un'impostazione manuale. Esistevano delle regole pratiche per assicurarsi che i file avessero dimensioni appropriate e fossero efficienti per le query. Ora con il Liquid Clustering, le dimensioni dei file vengono determinate e mantenute automaticamente con le routine di ottimizzazione.
Se state leggendo questo articolo (o avete letto la versione precedente) e avete già creato tabelle con ZORDER, dovrete ricreare le tabelle con il Liquid Clustering.
Inoltre, il Liquid Clustering si ottimizza per evitare file troppo piccoli o troppo grandi (asimmetria ed equilibrio) e aggiorna le dimensioni dei file man mano che nuovi dati vengono aggiunti per mantenere le tabelle ottimizzate.
3. Utilizzare Liquid Clustering sulle tabelle dei fatti
Per migliorare la velocità delle query, Delta Lake supporta la possibilità di ottimizzare il layout dei dati archiviati nel cloud storage con il Liquid Clustering. Raggruppa per le colonne che useresti in situazioni simili agli indici clusterizzati nel mondo dei database, sebbene non siano in realtà una struttura ausiliaria. Una tabella con clusterizzazione liquida clusterizzerà i dati nella definizione CLUSTER BY in modo che le righe con valori di colonna simili dalla definizione CLUSTER BY siano collocate nel set ottimale di file.
La maggior parte dei sistemi di database ha introdotto l'indicizzazione come metodo per migliorare le prestazioni delle query. Gli indici sono file e quindi, man mano che i dati crescono di dimensioni, possono diventare un altro problema di big data da risolvere. Invece, Delta Lake ordina i dati nei file Parquet per rendere più efficiente la selezione di intervalli sull'object storage. In combinazione con il processo di raccolta delle statistiche e il data skipping, le tabelle con clustering liquido sono simili alle attività operative di seek e scan nei database, un problema che gli indici hanno risolto, senza creare un altro collo di bottiglia di compute per trovare i dati che una query sta cercando.
Per le tabelle con Liquid Clustering, la best practice è limitare il numero di colonne nella clausola CLUSTER BY alle migliori 1-4. Abbiamo scelto le chiavi esterne (chiavi esterne per utilizzo, non chiavi esterne effettivamente applicate) delle 3 dimensioni più grandi che erano troppo estese per essere trasmesse in broadcast ai Worker.
Infine, il Liquid Clustering sostituisce la necessità sia di ZORDER che del partizionamento, quindi se si utilizza il Liquid Clustering, non è più necessario, né possibile, eseguire esplicitamente il partizionamento hive delle tabelle.
4. Utilizza il Liquid Clustering sulle chiavi della dimensione più grande e sui predicati probabili
Dato che state leggendo questo blog, è probabile che abbiate a che fare con dimensioni e che nelle vostre tabelle dimensionali esista una chiave surrogata o primaria. Una chiave che è un big integer, convalidata e che deve essere univoca. Dopo il databricks runtime 10.4, le colonne Identity sono state rese generalmente disponibili e fanno parte della CREATE TABLE sintassi.
Databricks ha anche introdotto vincoli non applicati di chiavi primarie e chiavi esterne in Runtime 11.3 e sono visibili nei cluster e negli Workspaces abilitati per Unity Catalog.
Una delle dimensioni su cui stavamo lavorando aveva oltre 1 miliardo di righe e ha beneficiato del file skipping e del dynamic file pruning dopo aver aggiunto i nostri predicati alle tabelle clusterizzate. Le nostre dimensioni più piccole sono state clusterizzate sul campo chiave di dimensione e trasmesse in broadcast nel join ai fatti. Analogamente a quanto consigliato per le tabelle dei fatti, limitare il numero di colonne nel Cluster By ai 1-4 campi nella dimensione che con maggiore probabilità verranno inclusi in un filtro, oltre alla chiave.
Oltre al file skipping e alla facilità di manutenzione, il clustering liquido consente di aggiungere più colonne rispetto a ZORDER ed è più flessibile del partizionamento in stile Hive.
5. Eseguire Analyze Table per raccogliere statistiche per l'Adaptive Query Execution Optimizer e abilitare la Predictive Optimization
Uno dei principali progressi in Apache Spark™ 3.0 è stato l'Adaptive Query Execution, o AQE in breve. A partire da Spark 3.0, AQE include tre funzionalità principali: il coalescing delle partizioni post-shuffle, la conversione di join sort-merge in join broadcast e l'ottimizzazione degli skew join. Insieme, queste funzionalità consentono le prestazioni accelerate dei modelli dimensionali in Spark.
Per consentire ad AQE di sapere quale piano scegliere, è necessario raccogliere le statistiche sulle tabelle. Puoi farlo eseguendo il comando ANALYZE TABLE. I clienti hanno segnalato che la raccolta di statistiche sulle tabelle ha ridotto in modo significativo l'esecuzione delle query per i modelli dimensionali, inclusi i join complessi.
ANALYZE TABLE MY_BIG_DIM COMPUTE STATISTICS FOR ALL COLUMNS
È comunque possibile sfruttare Analyze table come parte delle routine di caricamento, ma ora è preferibile abilitare semplicemente la Predictive Optimization su account, catalogo e schema.
ALTER CATALOG [catalog_name] {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
ALTER {SCHEMA | DATABASE} schema_name {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
L'ottimizzazione predittiva elimina la necessità di gestire manualmente le operazioni di manutenzione per le tabelle gestite da Unity Catalog in Databricks.
Con l'ottimizzazione predittiva abilitata, Databricks identifica automaticamente le tabelle che trarrebbero vantaggio dalle attività operative di manutenzione e le esegue per l'utente. Le attività operative di manutenzione vengono eseguite solo se necessario, eliminando le esecuzioni non necessarie per le attività operative di manutenzione e l'onere associato al monitoraggio e alla risoluzione dei problemi di prestazioni.
Attualmente le ottimizzazioni predittive eseguono Vacuum e Optimize sulle tabelle. Tieni d'occhio gli aggiornamenti per la Predictive Optimization e resta sintonizzato per sapere quando la funzionalità incorporerà l'analisi della tabella e la raccolta di statistiche, oltre all'applicazione automatica delle chiavi clusterizzate liquide.
Conclusione
Seguendo le linee guida di cui sopra, le organizzazioni possono ridurre i tempi di query; nel nostro esempio, abbiamo migliorato le prestazioni delle query di 9 volte sullo stesso cluster. Le ottimizzazioni hanno ridotto notevolmente l'I/O e hanno garantito che venissero elaborati solo i dati necessari. Abbiamo anche tratto vantaggio dalla struttura flessibile di Delta Lake, in quanto è in grado sia di scalare che di gestire i tipi di query che verranno inviate ad hoc dagli strumenti di Business Intelligence.
Dalla prima versione di questo blog, Photon è ora attivo per default per il nostro Databricks SQL Warehouse ed è disponibile nei cluster All Purpose e Jobs. Scopri di più su Photon e sul potenziamento delle prestazioni che fornirà a tutte le query Spark SQL con Databricks.
I clienti possono aspettarsi un miglioramento delle prestazioni delle loro query ETL/ELT e SQL attivando Photon nel Databricks Runtime. Combinando le best practice qui descritte con il Databricks Runtime abilitato per Photon, è possibile ottenere prestazioni delle query a bassa latenza in grado di superare i migliori data warehouse in cloud.
Crea oggi stesso il tuo database a schema a stella con Databricks SQL.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.