Porta Databricks in Kiro IDE con la potenza di AI Dev Kit
Due modi per connettere Kiro IDE a Databricks Data Intelligence Platform — i quattro server MCP gestiti da Databricks per un percorso di 10 minuti, o il nuovo Databricks AI Dev Kit Power per l'accesso completo.
- Due percorsi per connettere Kiro IDE a Databricks: i quattro server MCP gestiti da Databricks (Genie, SQL, Unity Catalog Functions, Vector Search) per una configurazione di 10 minuti basata su PAT, oppure il nuovo Databricks AI Dev Kit Power — un clic, tutti gli strumenti e le competenze essenziali, quattro opzioni di autenticazione.
- Sviluppo assistito da IA ancorato ai metadati reali dell'area di lavoro: entrambi i percorsi ereditano le autorizzazioni a livello di riga, colonna e tag di Unity Catalog, così l'assistente scrive codice SQL con le tue colonne effettive e vede solo ciò che ti è consentito vedere — nessuna allucinazione, nessuna lettura non autorizzata.
- Scegli in base alle funzionalità: il percorso A è la configurazione più leggera per analisti e sviluppatori SQL-first; il percorso B sblocca l'intera piattaforma Databricks (pipeline, job, Mosaic AI, Agent Bricks, Lakebase, Asset Bundles) all'interno dell'IDE.
Perché è importante
Lo sviluppo assistito dall'IA fallisce nel momento in cui l'assistente deve indovinare i nomi delle colonne, il layout delle tabelle o quali cataloghi puoi leggere. La soluzione è il grounding: connetti l'assistente ai metadati dello spazio di lavoro in tempo reale tramite il Model Context Protocol (MCP), in modo che l'SQL generato utilizzi le colonne effettive a disposizione, i modelli dbt uniscano tabelle reali e ogni query erediti le autorizzazioni di Unity Catalog già configurate. Nulla lascia la piattaforma. L'IA vede solo ciò che puoi vedere tu.
Sono appena stati raggiunti due traguardi importanti che rendono tutto questo pratico nell'IDE Kiro:
In primo luogo, il Databricks AI Dev Kit ha aggiunto il supporto per Kiro a monte nella PR #511. L'installer unificato gestisce kiro come target di prima classe insieme a claude, cursor, copilot, codex e gemini. Un solo comando e Kiro acquisisce l'intero toolkit in ~/.kiro/skills/ e ~/.kiro/settings/mcp.json.
In secondo luogo, la Power Databricks AI Dev Kit è stata rilasciata nel catalogo Kiro Powers nella PR #129. Apri il pannello Powers, fai clic su Prova e la Power esegue l'intero onboarding: installer, collegamento MCP, rilevamento dell'autenticazione e caricamento delle competenze (skill).
Insieme ai quattro server MCP remoti gestiti da Databricks già inclusi nella piattaforma, hai due modi per collegare Kiro a Databricks. Entrambi condividono un risultato comune: gli sviluppatori rilasciano analisi, pipeline e workflow di agenti più velocemente quando l'assistente eredita i permessi reali dello spazio di lavoro invece di indovinare schemi, colonne e autorizzazioni.
Perché scegliere Databricks per lo sviluppo assistito dall'IA
I due traguardi sopra menzionati rendono Kiro × Databricks una soluzione pratica. Il motivo per cui è importante risiede in ciò che sta alla base. Tre elementi rendono Databricks il substrato ideale per lo sviluppo assistito dall'IA, indipendentemente dal percorso scelto.
Unity Catalog è l'unico livello di governance che ancora l'IA a livello di dati. Ogni chiamata MCP — Percorso A o Percorso B — eredita le autorizzazioni a livello di riga, colonna e tag. L'assistente non ha una vista privilegiata dei tuoi dati; vede esattamente ciò che vedi tu. Non c'è un livello di controllo degli accessi separato da gestire, né il rischio che l'IA scriva query su tabelle di cui non dovrebbe nemmeno conoscere l'esistenza.
Un'unica copia dei dati, un unico set di definizioni. Poiché Databricks è un lakehouse, la tabella su cui l'assistente esegue le query tramite databricks-sql è la stessa in cui scrive il tuo modello dbt, la stessa esposta dal tuo spazio Genie e la stessa da cui legge la tua dashboard AI/BI. Non c'è alcuna sincronizzazione da data warehouse a data lake che possa interrompersi, né un livello semantico separato da mantenere sincronizzato. Quando l'assistente si ancora a samples.tpch.lineitem, si sta ancorando alla stessa definizione utilizzata da qualsiasi altro strumento.
L'intero stack IA è integrato, non aggiunto a posteriori. Mosaic AI Gateway instrada le chiamate ai modelli. Agent Bricks orchestra i workflow multi-agente. MLflow traccia esperimenti e valutazioni. Vector Search gestisce la ricerca semantica. Lakebase gestisce lo stato transazionale. Tutti questi elementi emergono nella Power, tutti sullo stesso UC. Non stai mettendo insieme cinque prodotti diversi; stai usando un'unica piattaforma.
C'è un quarto elemento che vale la pena menzionare: la Power stessa è realizzata da Databricks. Nessun'altra piattaforma dati offre una Power IDE con un solo clic per Kiro, Cursor, Claude, Copilot, Codex e Gemini. Il livello MCP è aperto, il protocollo es aperto, l'integrazione è aperta — ma l'esperienza che lo racchiude è progettata da Databricks specificamente per il modo in cui creano i nostri clienti.
I due percorsi in sintesi
Dimensione | Percorso A: Server MCP gestiti | Percorso B: Power Databricks AI Dev Kit |
|---|---|---|
Area di copertura | 4 server: Genie, SQL, UC Functions, Vector Search | Tutti gli strumenti e le competenze (skill) essenziali di Databricks |
Cosa ottieni | SQL in linguaggio naturale, ricerca semantica, esecuzione controllata delle funzioni | Copertura del Percorso A più pipeline, job, dashboard, Lakebase, Mosaic AI, Agent Bricks, Asset Bundles, MLflow, model serving, App |
Hosting | Gestito da Databricks (HTTPS remoto) | Server MCP Python locale tramite l'installer dell'AI Dev Kit |
Autenticazione (Auth) | PAT nell'ambiente shell (env) | OAuth U2M (consigliato), OAuth M2M, profilo .databrickscfg o PAT |
Configurazione | Modifica | Installazione della Power con un clic e flusso di autenticazione guidato |
Ideale per | Analisti e sviluppatori orientati all'SQL che desiderano un percorso di 10 minuti per porre domande al proprio data warehouse | Data engineer e sviluppatori di piattaforme che necessitano dell'intera area di copertura di Databricks in un unico IDE |
Architettura di integrazione in sintesi
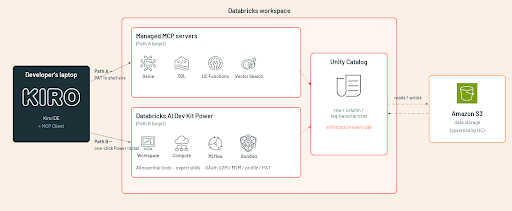
Entrambi i percorsi condividono lo stesso back-end: applicazione delle regole di Unity Catalog e identità dello spazio di lavoro Databricks. Si differenziano per l'area di copertura e il modello di autenticazione.
Percorso A: connettersi ai quattro server MCP gestiti
Questa è la configurazione più leggera. Un file mcp.json, un Personal Access Token di Databricks e la modifica di un profilo shell. In meno di 10 minuti Kiro comunica con Genie, SQL, Unity Catalog Functions e Vector Search.
Prerequisiti
- Uno spazio di lavoro Databricks su AWS con Unity Catalog abilitato.
- Un Personal Access Token (PAT) di Databricks o un token OAuth configurato per i server MCP che prevedi di utilizzare (
sql,unity-catalog,genie,vector-search). I PAT non utilizzati vengono revocati automaticamente dopo 90 giorni. - Kiro installato e avviato almeno una volta in modo che
~/.kiro/esista. - L'hostname del tuo spazio di lavoro nel formato
<workspace>.cloud.databricks.com.
Generare un PAT di Databricks
Nello spazio di lavoro Databricks, vai su Impostazioni, Sviluppatore, Token di accesso, Gestisci, Genera nuovo token. Imposta una scadenza in linea con la politica di rotazione del tuo team. Seleziona solo gli scope API necessari; il principio del privilegio minimo è preferibile alla comodità di selezionare "tutto". Copia immediatamente il token. Databricks non lo mostrerà di nuovo.
Dove Kiro memorizza la configurazione MCP
Kiro legge la configurazione MCP dai file JSON in due ambiti (scope); quello dello spazio di lavoro sovrascrive quello dell'utente.
- Ambito utente (User scope):
~/.kiro/settings/mcp.jsonsi applica a ogni spazio di lavoro. - Ambito spazio di lavoro (Workspace scope):
$PWD/.kiro/settings/mcp.jsonsi applica solo allo spazio di lavoro corrente e sovrascrive la voce dell'ambito utente con la stessa chiave.
Installazione con un clic dalla directory del server Kiro
Apri kiro.dev/docs/mcp/servers/, trova la riga relativa a Databricks e fai clic su Aggiungi a Kiro. Il browser avvierà Kiro e aprirà una finestra di dialogo di conferma con una configurazione precompilata. Conferma per scrivere la voce databricks-sql in ~/.kiro/settings/mcp.json. La voce fa riferimento a due variabili d'ambiente che non esistono ancora; le configureremo nel passaggio successivo.
Verificare (o aggiungere) la voce databricks-sql
Impostare le variabili d'ambiente
Nel profilo della shell che avvia Kiro (in genere ~/.zshrc su macOS):
Esegui il source del profilo (source ~/.zshrc) prima di avviare Kiro. Chiudi completamente Kiro (Cmd+Q su macOS) e riaprilo. L'operazione Ricarica finestra (Reload Window) non rilegge le variabili d'ambiente; solo il riavvio del processo lo fa.
Aggiungere Genie, UC Functions e Vector Search
Tutti e quattro i server gestiti da Databricks si connettono come MCP HTTP remoti. L'handshake di inizializzazione va a buon fine anche con un URL segnaposto; il server convalida la risorsa solo quando viene richiamato uno strumento. Uno stato di connessione non funzionante, in cui tools/call restituisce RESOURCE_DOES_NOT_EXIST o PERMISSION_DENIED, è la modalità di errore più comune. Esegui prima questi controlli preliminari (pre-flight check):
- Genie: conferma che esista uno spazio Genie e che tu possa aprirlo. L'ID dello spazio appare nell'URL.
- Funzioni UC: verifica che la funzione esista e di avere
EXECUTE. Elenca le funzioni conSELECT * FROM system.information_schema.routines WHERE routine_type = 'FUNCTION'. - Vector Search: verifica che esista un endpoint con almeno un indice accessibile in Catalog, Vector Search.
- Ambito del PAT: un PAT con ambito workspace può comunque raggiungere
PERMISSION_DENIEDsu spazi Genie o indici vettoriali se l'utente non dispone dell'autorizzazione Can View sulla risorsa specifica. Gli spazi Genie sono condivisi singolarmente.
Aggiungi le variabili d'ambiente aggiuntive (DATABRICKS_GENIE_MCP_URL, DATABRICKS_UC_FUNCTIONS_MCP_URL, DATABRICKS_VECTOR_SEARCH_MCP_URL) e aggiorna mcp.json alla configurazione completa:
Formati URL per server:
Server | Modello URL |
|---|---|
databricks-genie | https:// |
databricks-sql | https:// |
databricks-uc-functions | https:// |
databricks-vector-search | https:// |
Esci e riavvia nuovamente Kiro. Apri la sezione MCP SERVERS del pannello di Kiro; le quattro voci databricks-* appariranno con indicatori di stato verdi. Fai clic su Riconnetti su qualsiasi elemento rosso e verifica nuovamente il pre-flight. Prova a inviare una prima query a basso rischio nel pannello della chat: "Elenca i cataloghi a cui ho accesso."
Percorso B: installa Databricks AI Dev Kit Power
I quattro server gestiti coprono SQL, ricerca semantica e analisi in linguaggio naturale, il che è sufficiente per molti sviluppatori. Se il tuo flusso di lavoro include pipeline, job, model serving, Lakebase, Asset Bundles, Mosaic AI, Agent Bricks, dashboard AI/BI, MLflow o Databricks Apps, la configurazione a quattro server ti costringerà a copiare e incollare continuamente nell'interfaccia utente del workspace per tutto il giorno.
Databricks AI Dev Kit Power risolve questo problema. Un'unica installazione. Tutti gli strumenti e le competenze essenziali, quattro opzioni di autenticazione, tutti caricabili su richiesta.
Cosa otterrai
Area | Copertura |
|---|---|
SQL e calcolo | Esegui SQL su warehouse; esegui Python o Scala su cluster; gestisci il ciclo di vita del calcolo |
Pipeline e job | Spark Declarative Pipelines (tabelle di streaming, CDC, SCD di tipo 2, Auto Loader); DAG di job multi-task |
Unity Catalog | Tabelle, volumi, concessioni, tag, credenziali di archiviazione, tabelle di sistema, viste metriche, External Iceberg Reads |
Dashboard AI/BI | Visualizzazioni, KPI, dashboard di analisi |
Spazi Genie | Esplorazione dei dati in linguaggio naturale su dataset governati |
Agent Bricks | Assistenti di conoscenza (RAG) e supervisori multi-agente |
Vector Search | Ricerca semantica e RAG con indici gestiti |
Model Serving | Modelli ML, agenti IA e API Foundation Model (FMAPI) con pagamento in base ai token, instradabili tramite AI Gateway |
MLflow | Esperimenti, valutazioni, strumentazione delle tracce, query sulle metriche |
Lakebase | PostgreSQL gestito con provisioning e scalabilità automatica per carichi di lavoro OLTP |
Databricks Apps | App web full-stack sul Lakehouse |
Asset Bundles | Infrastruttura come codice per le risorse Databricks |
Installa con un clic
All'interno di Kiro, apri il pannello Powers, cerca databricks e fai clic su Prova. Il Power esegue il programma di installazione ufficiale di Databricks AI Dev Kit in modalità Kiro non interattiva:
Il programma di installazione scarica il server MCP, crea un ambiente virtuale uv e inserisce la libreria di competenze esperte in ~/.kiro/skills/. Il Power copia le competenze nella propria directory steering/ in modo che vengano caricate su richiesta in base all'attività da svolgere. Nessun contenuto è integrato nel Power stesso; tutto viene recuperato da upstream, in modo che le competenze rimangano aggiornate.
Le quattro opzioni di autenticazione
Il flusso di onboarding del Power rileva le credenziali esistenti e ti guida nella scelta corretta. Tutte e quattro sono documentate inline:
Opzione | Cos'è | Ideale per |
|---|---|---|
A: OAuth U2M (consigliato per l'uso interattivo) | La CLI Databricks apre un browser, ti autentichi come te stesso e l'SDK si aggiorna automaticamente ogni ora | Un singolo sviluppatore umano su una workstation. Il flusso interattivo più sicuro, senza segreti a lungo termine che rischiano di essere esposti |
B: OAuth M2M | Un service principal Databricks si autentica con | Agenti headless, CI/CD o di produzione |
C: Profilo | Indirizza il Power verso un profilo che utilizzi già per la CLI Databricks o altri strumenti | Hai già un profilo funzionante e non vuoi configurare nuovamente l'autenticazione |
D: Personal Access Token (legacy) | Token di tipo Bearer nel blocco env | Strumenti che non supportano OAuth o workspace senza OAuth U2M abilitato |
Il mcp.json del Power viene fornito con disabled: true finché non scegli un'opzione; nulla si connette finché non hai esplicitamente scelto e configurato le tue credenziali. Il flusso di rilevamento delle credenziali è neutrale. Se vengono rilevate più credenziali, tutte e quattro le opzioni vengono presentate in ordine, senza impostazioni predefinite e senza riutilizzo invisibile all'utente.
Verifica l'installazione
Riavvia Kiro, apri il pannello MCP SERVERS e conferma che la voce databricks sia connessa (verde). Chiedi alla chat: "Get my current Databricks user." Questa singola chiamata testa l'autenticazione, la risoluzione delle variabili d'ambiente e l'abilitazione del server. Se funziona, l'intera catena è integra.
Come scegliere tra i due percorsi
Un semplice albero decisionale:
- Devi solo eseguire SQL, porre domande in linguaggio naturale su dataset governati tramite Genie e cercare negli indici vettoriali? Usa il Percorso A. I quattro server gestiti fanno esattamente questo e la configurazione richiede solo 10 minuti.
- Creazione di pipeline, gestione di job, deployment di Asset Bundles, lavoro con Lakebase, sviluppo di Databricks Apps o chiamata di Mosaic AI / Agent Bricks? Usa il Percorso B. L'intero toolkit ha una superficie troppo ampia per essere integrato come server MCP remoti una tantum.
- Ibrido? Esegui entrambi. Il Percorso A e il Percorso B non sono in conflitto. Il Power scrive la propria voce
mcpServers.databricks, mentre i quattro server del Percorso A (databricks-genie,databricks-sql,databricks-uc-functions,databricks-vector-search) sono chiavi separate. Kiro li mostra tutti nel pannello MCP.
Per gli sviluppatori che prevedono di usare Kiro quotidianamente per i carichi di lavoro Databricks, il Percorso B è la soluzione migliore a lungo termine. Il Percorso A è la risposta giusta se hai solo 10 minuti e un SQL warehouse con cui vuoi chattare.
Dal punto di vista dello sviluppatore
Entrambi i percorsi hanno un impatto diverso a seconda di chi utilizza l'IDE. Quattro profili, quattro punti deboli, quattro risposte.
L'analytics engineer. Passi metà della giornata a interrogare tabelle che non hai mai visto e l'altra metà a fare copia-incolla tra il tuo editor e l'interfaccia utente del workspace. Il Percorso A risolve questo problema in 10 minuti. I server Genie e SQL basano ogni query su metadati di schema reali; l'assistente scrive basandosi sulle tue colonne effettive, senza tirare a indovinare; e ogni risultato eredita le tue autorizzazioni di Unity Catalog. Smetterai di passare da una scheda all'altra.
Il data engineer. La tua giornata è fatta di pipeline, job, Asset Bundles e dei passaggi tra ambienti diversi che ne conseguono. Creare manualmente databricks.yml ed eseguire databricks bundle deploy dalla barra laterale del terminale è il metodo lento. Il Percorso B è quello veloce. Le competenze del Power relative a pipeline, job e Asset Bundles producono, validano ed eseguono il deployment di IaC a partire da una singola conversazione. Spark Declarative Pipelines, CDC, SCD Type 2, Auto Loader: tutto generato a partire dalle tue tabelle UC reali e pronto per il commit.
Lo sviluppatore di AI / agenti. Ti occupi di collegare chiamate ai modelli, valutazione, governance e orchestrazione degli agenti su tre o quattro strumenti che non concordano del tutto sullo schema. Il Percorso B copre l'intera gamma di soluzioni Databricks AI: Mosaic AI Gateway per routing e fallback, Agent Bricks per supervisori multi-agente e assistenti di conoscenza, MLflow per la valutazione, Vector Search per il recupero delle informazioni, il tutto governato da UC end-to-end. Il tuo agente eredita gli stessi permessi di chi lo chiama, e le tue tracce di valutazione finiscono nello stesso workspace delle tue esecuzioni di addestramento.
Lo sviluppatore di piattaforme. Gestisci le risorse Databricks come codice, effettui il passaggio tra dev/stage/prod e rispondi alla domanda "c'è stata una deriva (drift)?" con cadenza settimanale. La competenza Asset Bundles del Percorso B, insieme alle competenze di gestione di Unity Catalog, genera il bundle completo, lo valida rispetto allo stato effettivo del tuo workspace ed evidenzia eventuali derive prima che creino problemi. Smetterai di gestire un set di YAML manualmente e un altro in un documento.
Un flusso di lavoro che puoi eseguire oggi stesso
Qualunque sia il percorso scelto, questo esercizio basa l'assistente sui metadati reali del workspace utilizzando il catalogo samples.tpch, disponibile in ogni workspace Databricks.
Chiedi: "Quali colonne e tipi ha samples.tpch.lineitem e qual è la distribuzione dei dati per anno l_shipdate?"
Kiro restituisce lo schema effettivo e un istogramma da una singola query eseguita tramite MCP. Nomi di colonna reali, distribuzione reale, nessuna allucinazione.
Chiedi: "Bozza di un modello dbt che unisca lineitem a orders e aggreghi i ricavi per nazione per trimestre."
Kiro produce SQL utilizzando i nomi reali delle colonne (l_extendedprice, l_discount, o_orderdate) invece di tirare a indovinare. Poiché ha prima interrogato lo schema, conosce i tipi esatti e il livello di granularità.
Chiedi: "Esegui la mia nuova aggregazione su samples.tpch e confronta il numero di righe con lo snapshot della scorsa settimana in poc.gold.revenue_by_nation_qtr."
Kiro esegue entrambe le query ed evidenzia le differenze. Se un numero sembra errato, "Mostrami la lineage per gold.revenue_by_nation_qtr" recupera le tabelle a monte da system.access.table_lineage. Una volta verificato, Kiro genera il JSON del job Databricks per il modello ed elenca quali cataloghi e schemi tocca.
Nel Percorso B, lo stesso flusso di lavoro si estende a "Genera l'Asset Bundle per questo job ed eseguine il deployment in staging", o "Crea una dashboard AI/BI supportata da questa aggregazione", o "Collega questo a un endpoint Mosaic AI Gateway con un modello di fallback", il tutto senza mai lasciare l'IDE.
Best practice, indipendentemente dal percorso
- Autenticazione con privilegi minimi. Genera un PAT separato per ogni workstation e set di ambiti. Nel Percorso B, preferisci OAuth U2M ai PAT per l'uso interattivo.
- Non fare mai il commit delle credenziali. Memorizza
DATABRICKS_ACCESS_TOKENnel profilo della tua shell o in un gestore di segreti. Non inserirlo mai inmcp.jsonsottoposto a controllo di versione. - Ambito per progetto. Mantieni gli ID dello spazio Genie e i percorsi dell'indice Vector Search in
$PWD/.kiro/settings/mcp.jsonin modo che ogni progetto porti con sé i propri collegamenti alle risorse. - Affidati ai permessi di UC. Tutti i percorsi applicano le autorizzazioni basate su righe, colonne e tag di Unity Catalog. L'AI eredita i tuoi permessi effettivi a ogni chiamata. Non c'è un livello di controllo degli accessi separato da gestire.
- Riavvia, non ricaricare. Kiro legge le variabili d'ambiente una sola volta all'avvio del processo. Dopo aver modificato il profilo della shell o aggiunto l'autenticazione, esci completamente (Cmd+Q su macOS) e riapri.
Risoluzione dei problemi
"Server non trovato" o stato rosso su una voce MCP.
Percorso A: controlla echo $DATABRICKS_SQL_MCP_URL nella shell che ha avviato Kiro. Un valore vuoto significa che Kiro non può risolvere l'URL. Conferma che mcp.json a livello di workspace non stia sovrascrivendo la configurazione a livello di utente. Verifica che il PAT sia ancora valido in Impostazioni, Sviluppatore, Token di accesso.
Percorso B: reinserisci il flusso di rilevamento delle credenziali dall'onboarding del Power. Se il server MCP restituisce Invalid access token o 401, l'hook di ripristino 401 integrato del Power mette in pausa le chiamate agli strumenti e mostra nuovamente le opzioni di autenticazione.
Connesso a MCP ma le chiamate agli strumenti restituiscono RESOURCE_DOES_NOT_EXIST o PERMISSION_DENIED.
Il fallimento più comune del Percorso A. L'handshake di inizializzazione va a buon fine con un URL segnaposto perché il server rimanda la convalida delle risorse al momento dell'invocazione. Esegui nuovamente i controlli preliminari per il server specifico (lo spazio Genie esiste ed è condiviso con te, la funzione esiste e disponi di EXECUTE, l'indice vettoriale esiste e disponi di Visualizzazione consentita).
Provalo oggi stesso. Il Databricks AI Dev Kit Power è il modo più rapido per avere l'intera piattaforma — pipeline, job, Lakebase, Mosaic AI, Agent Bricks e tutto il resto elencato sopra — all'interno di Kiro. Installalo direttamente dal catalogo Kiro Powers all'indirizzo github.com/kirodotdev/powers, oppure visita github.com/databricks-solutions/ai-dev-kit per installare il toolkit sottostante per Kiro o qualsiasi IDE supportato (Claude, Cursor, Copilot, Codex, Gemini). Per i quattro server MCP gestiti da Databricks, l'installazione con un clic si trova su kiro.dev/docs/mcp/servers/.
Hai feedback o hai riscontrato un problema? Segnala un problema su databricks-solutions/ai-dev-kit — li leggiamo tutti.
Le opinioni e le idee qui condivise sono personali e non costituiscono una politica ufficiale di Databricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.