Costruzione di un framework di analisi A/B testing per il gaming mobile su Databricks
Come HARDlight ha scalato l'analisi degli esperimenti con modellazione statistica automatizzata, insight governati, dashboard con aggiornamento giornaliero e riepiloghi generati da LLM.
di Sanjay Ashok, Jack Holdsworth, Tingting Wan, Joel Dias, Richard Carr e Monika Kolodziejczyk
- Dai dati alle decisioni: come Sega HARDlight ha automatizzato l'analisi dei test A/B su Databricks attraverso l'ingestione standardizzata degli esperimenti, la modellazione statistica e la pubblicazione dei risultati, riducendo i flussi di lavoro manuali e consentendo un aumento di 2 volte della capacità di sperimentazione mensile senza personale aggiuntivo.
- Insight per ogni pubblico: monitoraggio con aggiornamento giornaliero con un riepilogo LLM e metriche progressivamente più granulari, diagnostica e azioni consigliate che democratizzano l'accesso a insight azionabili in tutta l'organizzazione.
- Fiducia attraverso la trasparenza: inferenza statistica coerente e viste AI/BI accessibili hanno aiutato i team a comprendere i risultati, a costruire fiducia e ad adottare un approccio scientifico condiviso alla sperimentazione.
Introduzione
Gli studi di giochi per dispositivi mobili dipendono dalla sperimentazione continua per perfezionare il gameplay, la monetizzazione e le operazioni live. Man mano che la sperimentazione scala, l'analisi diventa spesso il fattore limitante. I risultati vengono spesso assemblati manualmente, gli approcci statistici variano a seconda dell'analista e le intuizioni emergono giorni dopo che i segnali chiave sono emersi. Nel tempo, ciò crea attrito: iterazione più lenta, conclusioni incoerenti e declino della fiducia nei test A/B come strumento decisionale affidabile.
La Sfida
Presso HARDlight, la sfida non era solo la velocità, ma la fiducia. Approcci diversi portavano a interpretazioni diverse, rendendo più difficile l'allineamento e indebolendo la fiducia nella sperimentazione come strumento decisionale scientifico. Alcuni stakeholder necessitavano di un semplice stato giornaliero, altri volevano comprendere il comportamento dei giocatori o l'impatto aziendale, e un gruppo più ristretto richiedeva una validazione approfondita di specifici leve di gioco. Le dashboard e i report esistenti faticavano a soddisfare efficacemente questa gamma completa di esigenze. Affinché la sperimentazione potesse scalare, HARDlight aveva bisogno di un modo per standardizzare l'inferenza, rendere i risultati accessibili a diversi livelli di profondità e ricostruire la fiducia nei test A/B come processo decisionale condiviso e scientifico.
Per affrontare questo problema, HARDlight ha creato un framework di analisi dei test A/B nativo di Databricks che automatizza il percorso dai dati sperimentali all'intuizione pronta per le decisioni. L'analisi statistica è stata eseguita a monte in modo ripetibile e trasparente, e Databricks AI/BI ha presentato i risultati attraverso un'esperienza di aggiornamento giornaliero che iniziava con un riepilogo generato da LLM e consentiva un'esplorazione più approfondita con viste progressivamente granulari. Alla fine di ogni esperimento, i risultati venivano bloccati e conservati, garantendo che decisioni, contesto e apprendimenti rimanessero disponibili a lungo dopo la conclusione del test.
La Soluzione: Test A/B Automatizzati su Databricks
Il framework di HARDlight automatizza la sperimentazione dall'ingestione al supporto decisionale. All'interno di Databricks, le definizioni degli esperimenti e la telemetria vengono standardizzate, viene applicata la modellazione statistica in modo coerente e i risultati vengono pubblicati in una dashboard stratificata che si aggiorna quotidianamente durante la finestra di esecuzione. Un riepilogo LLM in cima fornisce una visione accessibile dello stato dell'esperimento, mentre sezioni più approfondite espongono KPI, diagnostica e azioni consigliate per gli utenti esperti.
La scelta di Databricks consente governance e ripetibilità tra i team. Unity Catalog fornisce un unico piano di controllo per permessi e lineage degli asset sperimentali; Spark Declarative Pipelines orchestra pipeline affidabili per l'ingestione e le trasformazioni degli esperimenti; e MLflow supporta il tracciamento degli esperimenti e il packaging dei modelli per analisi riproducibili. Insieme, queste capacità mantengono dati e analisi governati, coerenti e facili da operare nel Lakehouse.
Una chiave innovazione è la "dashboard congelata" alla fine dell'esecuzione. Invece di passare al successivo aggiornamento, il framework conserva lo snapshot finale e le decisioni prese, insieme alle azioni consigliate. Questo istituzionalizza gli apprendimenti dagli esperimenti passati e consente agli stakeholder di rivisitare i risultati senza ambiguità.
Architettura Tecnica
Il framework di sperimentazione è costruito come un sistema nativo di Databricks che separa l'elaborazione dei dati, l'inferenza statistica e il consumo, mantenendo al contempo tutti gli output governati e riproducibili per impostazione predefinita. Questo design garantisce che il rigore analitico si scala senza aumentare l'overhead operativo o frammentare l'interpretazione tra i team.
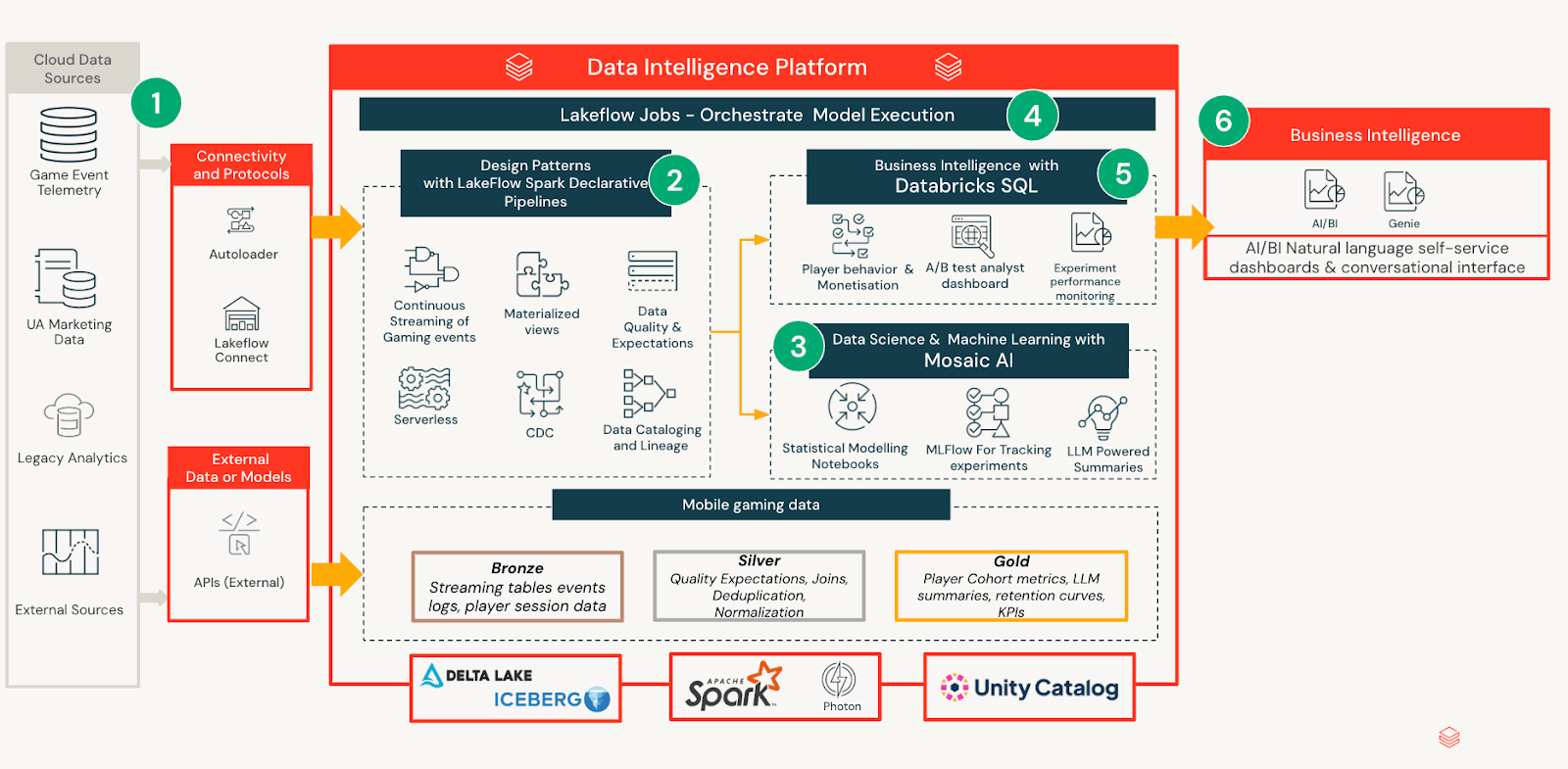
Ingestione Dati & Modellazione
Definizioni degli esperimenti, telemetria dei giocatori e metriche di risultato vengono ingerite da pipeline interne e curate in tabelle governate con schemi coerenti. Questa standardizzazione consente ad analisti e team di prodotto di ragionare sugli esperimenti in modo coerente, indipendentemente dal design o dalla durata del test. I notebook vengono utilizzati per calcolare modelli statistici che determinano stime di effetto, incertezze e impatti a livello di segmento nel tempo. Invece di incorporare la logica in dashboard o report, tutti gli output analitici vengono materializzati in un modello unificato di analisi degli esperimenti. Questo crea un livello semantico stabile su cui i consumatori downstream possono fare affidamento senza rieseguire l'analisi o reinterpretare i risultati.
Consegna di Intuizioni basata su AI/BI
Sopra questo livello di analisi governato, Databricks AI/BI fornisce un'interfaccia accessibile per il consumo dei risultati degli esperimenti. Ogni aggiornamento giornaliero genera un riepilogo LLM conciso rivolto a stakeholder non tecnici, traducendo output statistici validati in linguaggio naturale. La dashboard utilizza la divulgazione progressiva: gli utenti possono fermarsi al riepilogo quando soddisfatti, o esplorare livelli più approfonditi di metriche, diagnostica e analisi di segmenti man mano che la loro curiosità aumenta. Questa esperienza stratificata consente una scansione rapida mantenendo la profondità analitica disponibile per la validazione degli esperti.

Ciclo di Vita e Persistenza dell'Esperimento
Durante la fase live, la dashboard si aggiorna quotidianamente in modo che i team possano tracciare la traiettoria e reagire ai segnali. Al termine, la dashboard si congela per preservare risultati, decisioni e azioni consigliate. Questo ciclo di vita crea un record verificabile che accelera l'onboarding e riduce l'analisi duplicata negli esperimenti futuri.
Strati della Dashboard Spiegati
La dashboard è progettata per guidare gli utenti attraverso i risultati di un esperimento in una sequenza chiara e deliberata. Inizia con la semplicità e svela gradualmente maggiori dettagli per coloro che sono interessati a esplorare ulteriormente. Ogni sezione affronta una domanda diversa, ed è del tutto accettabile fermarsi una volta che il lettore ha ottenuto le informazioni necessarie.
Riepilogo dell'esperimento generato da LLM: In cima alla dashboard si trova un riepilogo generato da LLM. Mentre un esperimento è attivo, fornisce una visione semplice e di alto livello di come stanno andando le cose, evidenziando segnali precoci senza trarre conclusioni premature.
Una volta concluso l'esperimento, il riepilogo cambia ruolo. Diventa una chiara spiegazione di ciò che è accaduto, evidenziando le metriche che si sono mosse con alta confidenza, in ordine di priorità e in linguaggio semplice. L'obiettivo è aiutare i team a comprendere rapidamente il risultato e perché è importante.
Risultati confermati e impatto statistico: Per un pubblico più tecnico, la sezione successiva presenta una visione strutturata dei risultati statisticamente significativi. Metriche chiave come il valore di vita del giocatore (LTV) e la retention sono elencate accanto a dimensioni dell'effetto e livelli di confidenza, rendendo facile validare le conclusioni senza approfondire l'analisi grezza.
Impatto previsto sul valore di vita: La dashboard mostra quindi l'impatto stimato sul valore di vita del giocatore per i gruppi di controllo e di variante. Incertezza e margini di errore sono mostrati esplicitamente, rafforzando che queste sono stime informate, non previsioni assolute.
Impatto dei ricavi per fonte: I risultati sono suddivisi per flusso di ricavi, inclusi annunci, acquisti in-app e ricavi totali. Questo aiuta i team a capire se le modifiche sono diffuse o guidate da specifici canali di monetizzazione.
Coinvolgimento e comportamento dei giocatori: Oltre ai ricavi, vengono presentate metriche di coinvolgimento come la retention e il comportamento delle sessioni per garantire che i guadagni aziendali siano considerati insieme all'esperienza del giocatore e alla salute a lungo termine.
Analisi a livello di segmento: La segmentazione è centrale nel modo in cui HARDlight progetta e valuta gli esperimenti. Questa sezione mostra come diversi segmenti di giocatori rispondono a una modifica, sia essa definita da retention, progressione o altri tratti comportamentali. Aiuta i team a confermare che le esperienze mirate funzionano come previsto, senza danneggiare altre parti della base di giocatori.
Meccaniche di monetizzazione ed economia di gioco: Strati più approfonditi esplorano come gli esperimenti influenzano i sistemi di gioco, incluse le prestazioni degli annunci per posizionamento, le prestazioni degli acquisti in-app per categoria di prodotto e le modifiche ai flussi di valuta hard e soft tra fonti e destinazioni.
Loop di gameplay principali e appendici: Al livello più profondo, grafici e tabelle dettagliate coprono meccaniche di gameplay come gare, personaggi e oggetti, insieme a visualizzazioni statistiche di supporto. Questo livello è destinato agli utenti esperti che desiderano trasparenza completa o necessitano di riutilizzare le intuizioni in lavori futuri.
Insieme, questi livelli consentono alle intuizioni di emergere naturalmente. I team possono muoversi rapidamente quando la risposta è chiara, o approfondire quando sorgono domande, il tutto lavorando dalla stessa fonte di dati governata e affidabile.
Questa struttura è resa possibile da Databricks AI/BI, che consente di presentare output analitici complessi in modo pulito senza incorporare codice personalizzato o flussi di lavoro solo per analisti nelle dashboard. Risultati statistici, proiezioni e analisi a livello di segmento vengono calcolati a monte nei notebook e materializzati in tabelle governate, mentre AI/BI fornisce un livello di presentazione flessibile in cima. Ciò elimina la necessità di eseguire Python all'interno delle dashboard, semplifica la manutenzione e rende fattibile per un team snello iterare ed evolvere il sistema nel tempo.
Altrettanto importante, AI/BI rende possibile servire pubblici molto diversi dagli stessi dati sottostanti. Riepiloghi narrativi, risultati tabellari, grafici e diagnostica approfondita possono coesistere senza duplicare la logica o frammentare l'interpretazione. Questo è stato un cambiamento chiave rispetto agli approcci precedenti, dove i vincoli degli strumenti imponevano compromessi tra profondità analitica, accessibilità e sostenibilità.
Risultati e Impatto
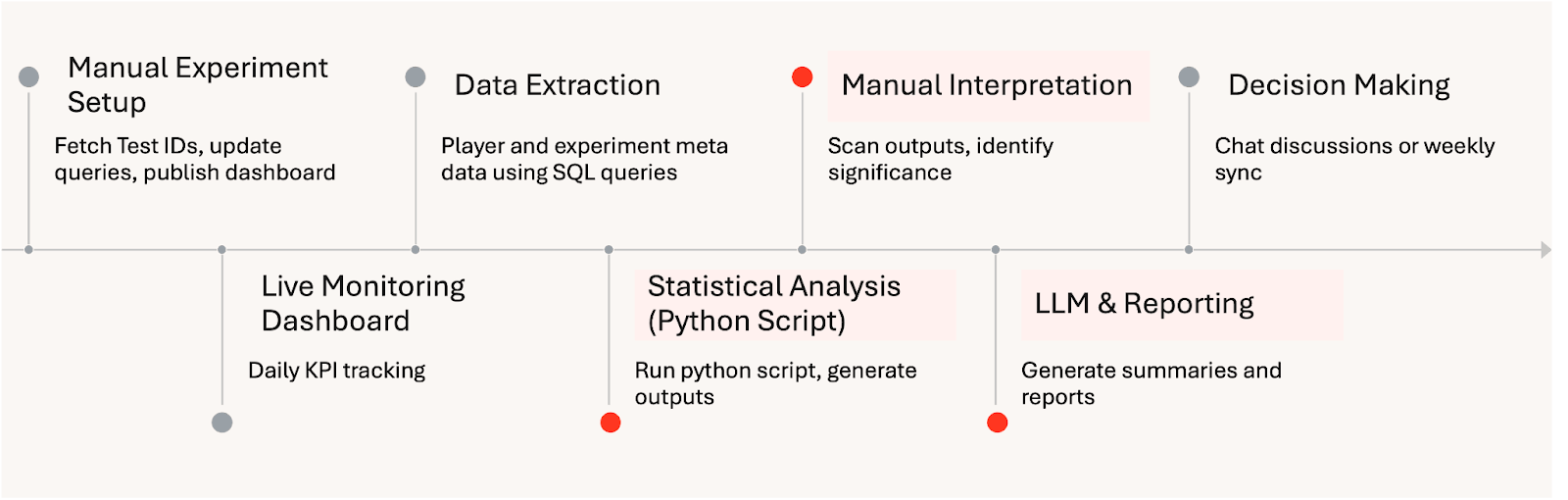
Il framework ha cambiato radicalmente il modo in cui operano le sperimentazioni in HARDlight. Automatizzando l'analisi e standardizzando l'inferenza statistica, il team di dati ha ridotto lo sforzo manuale di oltre otto ore a settimana. Standardizzando le esecuzioni degli esperimenti con Databricks Workflows, il team ha eliminato gran parte del lavoro manuale di configurazione precedentemente richiesto per ogni analisi. Questo consente di risparmiare circa un giorno per esperimento e ha permesso un aumento mirato di due volte della capacità mensile di test A/B senza aumentare il personale.
Flusso di lavoro manuale per l'analisi degli esperimenti:
Consegna automatizzata degli insight degli esperimenti su Databricks:
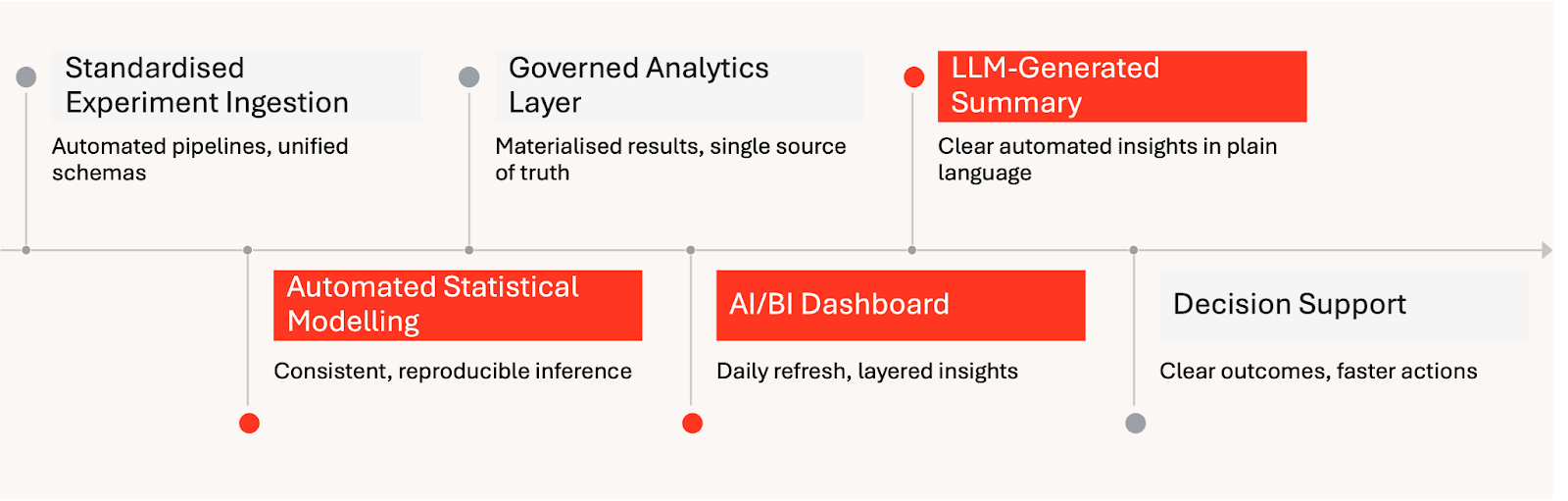
Oltre ai guadagni di efficienza, il sistema ha migliorato la coerenza e la fiducia nei risultati. L'archivio dei dashboard bloccato funge ora da fonte di verità duratura per gli esperimenti completati, riducendo le analisi ripetute e facilitando ai team la revisione delle decisioni passate con il contesto completo. Ciò ha ridotto significativamente l'overhead per il mantenimento della conoscenza storica tra i team.
Forse l'aspetto più importante è che il framework ha cambiato il modo in cui gli insight vengono consumati in tutto lo studio. Con più esperimenti in esecuzione in parallelo, i team ricevono ora aggiornamenti giornalieri abilitati per AI/BI che sostituiscono l'aggregazione e l'interpretazione manuale di più giorni. Genie sarà abilitato direttamente sul dashboard, consentendo agli utenti di porre domande su ciò che stanno vedendo ed esplorare i risultati con parole proprie, senza dover comprendere il modello di dati sottostante. Insieme, riepiloghi chiari, metriche governate, output statistici trasparenti e accesso conversazionale hanno contribuito a costruire fiducia tra i team di prodotto, LiveOps e ingegneria, rafforzando la sperimentazione come modo di lavorare scientifico e condiviso.
Prossimi passi
HARDlight prevede di estendere il framework con un'applicazione di forecasting, estendendo il framework dall'analisi descrittiva e inferenziale a una guida lungimirante. La visione più ampia è la sperimentazione predittiva e l'ottimizzazione a ciclo chiuso, utilizzando il Lakehouse per automatizzare ulteriormente il ciclo dall'ipotesi alla distribuzione, preservando al contempo la governance e la coerenza con Unity Catalog, Spark Declarative Pipelines e MLflow. Questo approccio basato sui dashboard può avere un impatto significativo per altri studi con esigenze simili, sovrapponendo riepiloghi LLM a metriche governate e diagnostica per scalare la sperimentazione con fiducia su Databricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.