Costruzione, miglioramento e distribuzione di sistemi RAG basati su Knowledge Graph su Databricks
di Andrea Santurbano, Chandhana Padmanabhan, Jiayi Wu e Dan Pechi
- Panoramica di GraphRAG: Il blog esplora come i sistemi di retrieval-augmented generation (RAG) possano essere potenziati con database grafici come Neo4j, consentendo output AI più precisi catturando le relazioni semantiche tra entità nei dati strutturati.
- Casi d'uso e vantaggi: GraphRAG può essere applicato nella cybersecurity per il rilevamento delle minacce, così come in settori come la produzione per la manutenzione predittiva e la gestione della catena di approvvigionamento, fornendo approfondimenti più profondi da set di dati complessi.
- Implementazione su Databricks: Il blog illustra come costruire e distribuire un sistema GraphRAG su Databricks utilizzando Neo4j, mostrando l'integrazione di LLM, Delta Tables e il Agent Bricks Custom Agents per la distribuzione end-to-end.
Comprendere GraphRAG
Cos'è un Knowledge Graph?
Per capire perché si potrebbe usare un Knowledge Graph (KG) invece di un'altra rappresentazione di dati strutturati, è importante riconoscere la sua focalizzazione sulle relazioni esplicite tra entità—come aziende, persone, macchinari o clienti—e i loro attributi o caratteristiche associate. A differenza degli embedding o della ricerca vettoriale, che privilegiano la somiglianza in spazi ad alta dimensionalità, un Knowledge Graph eccelle nel rappresentare le connessioni semantiche e il contesto tra i punti dati. Un'unità base di un knowledge graph è un fatto. I fatti possono essere rappresentati come una tripletta in uno dei seguenti modi:
- HRT: <head, relation, tail>
- SPO: <subject, predicate, object>
Due semplici esempi di KG sono mostrati di seguito. L'esempio di sinistra di un fatto potrebbe essere <Andrea, ama, Irene>. Si può vedere che il KG non è altro che una collezione di molteplici fatti di questo tipo. Ma come si può notare, i grafi hanno una semantica poiché l'esempio di sinistra NON descrive una relazione romantica tra due persone, mentre l'esempio di destra DESCRIVE una relazione romantica tra due persone.

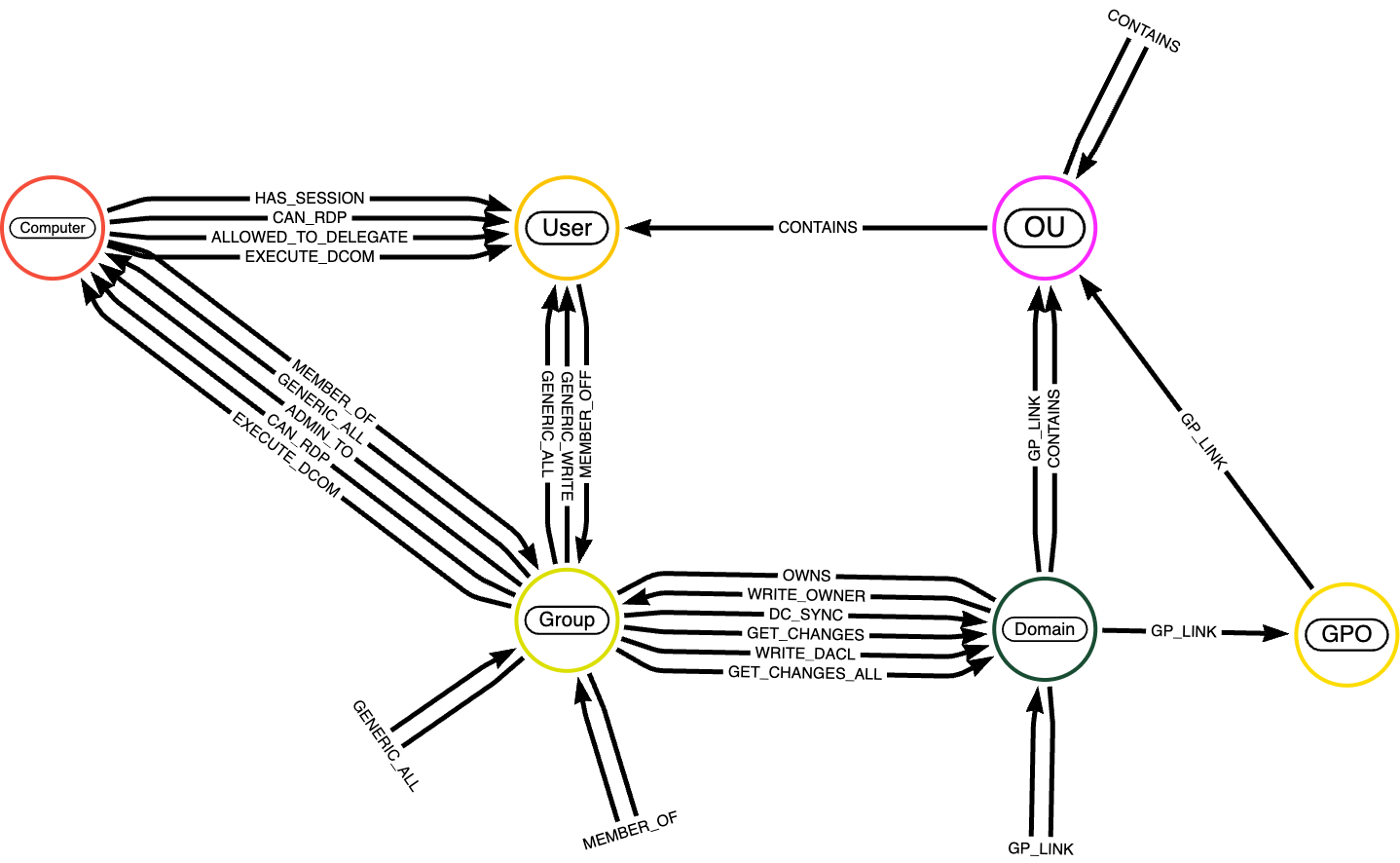
Ora che avete compreso l'importanza della semantica nei Knowledge Graphs, vi presentiamo il dataset che utilizzeremo nei prossimi esempi di codice: il dataset BloodHound. BloodHound è un dataset specializzato progettato per analizzare relazioni e interazioni all'interno di ambienti Active Directory. È ampiamente utilizzato per l'audit di sicurezza, l'analisi dei percorsi di attacco e per ottenere informazioni su potenziali vulnerabilità nelle strutture di rete.
I nodi nel dataset BloodHound rappresentano entità all'interno di un ambiente Active Directory. Questi includono tipicamente:
- Utenti: rappresenta account utente individuali nel dominio.
- Gruppi: rappresenta gruppi di sicurezza o di distribuzione che aggregano utenti o altri gruppi per l'assegnazione di permessi.
- Computer: rappresenta macchine individuali nella rete (workstation o server).
- Domini: rappresenta il dominio Active Directory che organizza e gestisce utenti, computer e gruppi.
- Unità Organizzative (OU): rappresenta contenitori utilizzati per strutturare e gestire oggetti come utenti o gruppi.
- GPO (Group Policy Objects): rappresenta le policy applicate a utenti e computer all'interno del dominio.
Una descrizione dettagliata delle entità nodo è disponibile qui. Le relazioni nel grafo definiscono interazioni, appartenenze e permessi tra i nodi; una descrizione completa degli archi è disponibile qui.
Quando scegliere GraphRAG rispetto a RAG Tradizionale
Il vantaggio principale di GraphRAG rispetto a RAG standard risiede nella sua capacità di eseguire corrispondenze esatte durante la fase di recupero. Ciò è reso possibile, in parte, preservando esplicitamente la semantica delle query in linguaggio naturale nel linguaggio di query del grafo downstream. Mentre le tecniche di recupero denso basate sulla somiglianza del coseno eccellono nel catturare la semantica fuzzy e nel recuperare informazioni correlate anche quando la query non è una corrispondenza esatta, ci sono casi in cui la precisione è fondamentale. Questo rende GraphRAG particolarmente prezioso in domini in cui l'ambiguità è inaccettabile, come la conformità, il settore legale o dataset altamente curati.
Detto questo, i due approcci non si escludono a vicenda e vengono spesso combinati per sfruttare i rispettivi punti di forza. Il recupero denso può ampliare la rete per la rilevanza semantica, mentre il knowledge graph affina i risultati con corrispondenze esatte o ragionamento sulle relazioni.
Quando scegliere RAG Tradizionale rispetto a GraphRAG
Sebbene GraphRAG abbia vantaggi unici, presenta anche delle sfide. Un ostacolo chiave è definire correttamente il problema: non tutti i dati o casi d'uso sono adatti a un Knowledge Graph. Se il compito coinvolge testo altamente non strutturato o non richiede relazioni esplicite, la complessità aggiunta potrebbe non valerne la pena, portando a inefficienze e risultati subottimali.
Un'altra sfida è strutturare e mantenere il Knowledge Graph. La progettazione di uno schema efficace richiede un'attenta pianificazione per bilanciare dettaglio e complessità. Una progettazione dello schema scadente può influire sulle prestazioni e sulla scalabilità, mentre la manutenzione continua richiede risorse e competenze.
Le prestazioni in tempo reale sono un'altra limitazione. I database grafici come Neo4j possono avere difficoltà con le query in tempo reale su dataset di grandi dimensioni o frequentemente aggiornati a causa di traversate complesse e query multi-hop, rendendoli più lenti dei sistemi di recupero denso. In tali casi, un approccio ibrido—utilizzando il recupero denso per la velocità e il perfezionamento del grafo per l'analisi post-query—può fornire una soluzione più pratica.
GraphDB e embedding
I database grafici come Neo4j spesso offrono anche funzionalità di ricerca vettoriale tramite indici HNSW. La differenza qui è come utilizzano questo indice per fornire risultati migliori rispetto ai database vettoriali. Quando si esegue una query, Neo4j utilizza l'indice HNSW per identificare gli embedding corrispondenti più vicini in base a misure come la somiglianza del coseno o la distanza euclidea. Questo passaggio è cruciale per trovare un punto di partenza nei dati che si allinei semanticamente con la query, sfruttando la semantica implicita fornita dalla ricerca vettoriale.
Ciò che distingue i database grafici è la loro capacità di combinare questo recupero iniziale basato su vettori con le loro potenti capacità di attraversamento. Dopo aver trovato il punto di ingresso utilizzando l'indice HNSW, Neo4j sfrutta la semantica esplicita definita dalle relazioni nel knowledge graph. Queste relazioni consentono al database di attraversare il grafo e raccogliere contesto aggiuntivo, scoprendo connessioni significative tra i nodi. Questa combinazione di semantica implicita dagli embedding e semantica esplicita dalle relazioni del grafo consente ai database grafici di fornire risposte più precise e ricche di contesto di quanto ciascun approccio potrebbe ottenere da solo.
GraphRAG End-to-End in Databricks
GraphRAG è un ottimo esempio di sistemi Compound AI in azione, dove più componenti AI lavorano insieme per rendere il recupero più intelligente e consapevole del contesto. In questa sezione, daremo uno sguardo generale a come tutto si integra.
Architettura GraphRAG
Di seguito è riportato un diagramma architetturale che dimostra come le domande in linguaggio naturale di un analista possano recuperare informazioni da un knowledge graph Neo4j.
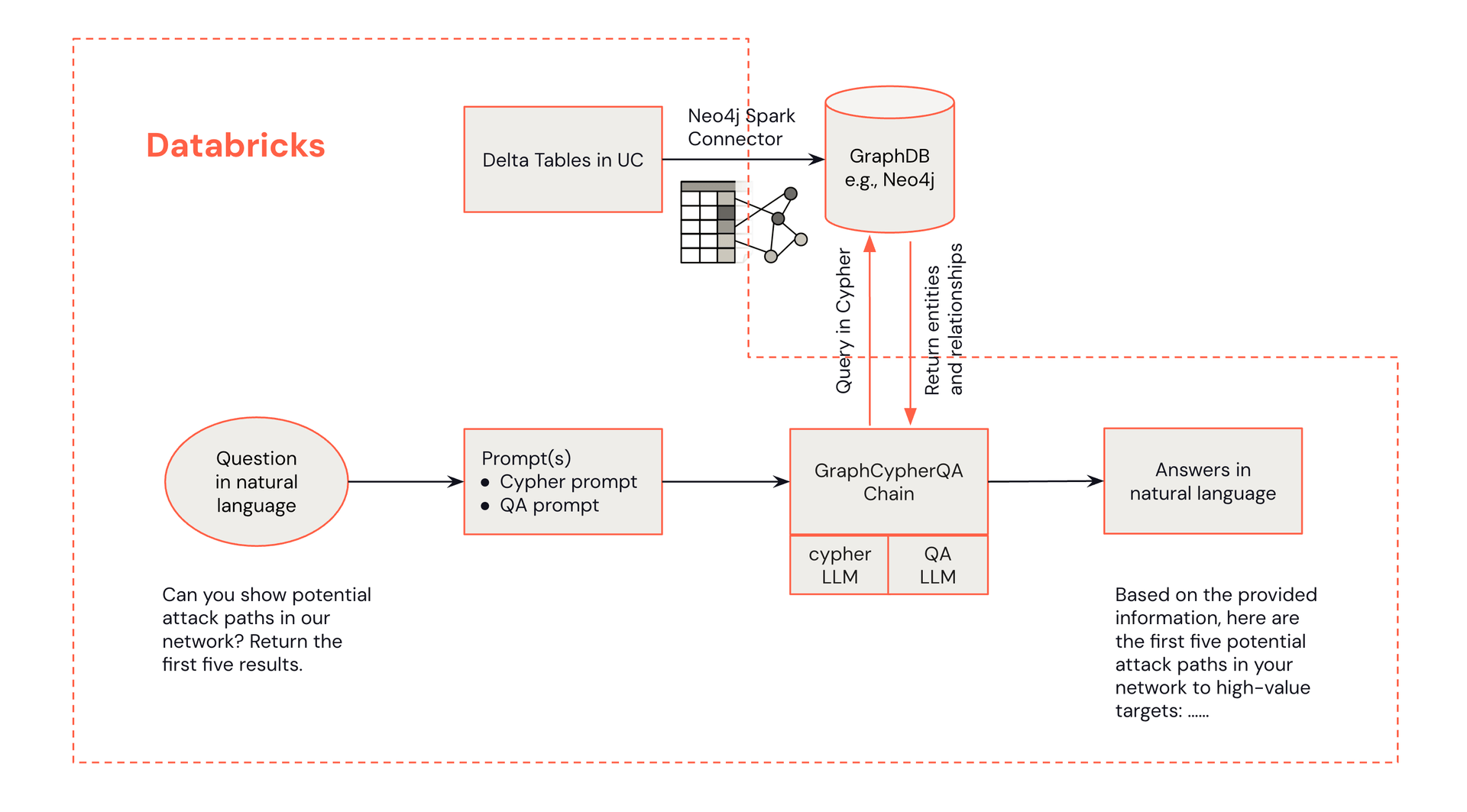
L'architettura per il rilevamento delle minacce basato su GraphRAG combina i punti di forza di Databricks e Neo4j:
- Interfaccia Analista Security Operations Center (SOC): Gli analisti interagiscono con il sistema tramite Databricks, avviando query e ricevendo raccomandazioni di allerta.
- Elaborazione Databricks: Databricks gestisce l'elaborazione dei dati, l'integrazione LLM e funge da hub centrale per la soluzione.
- Neo4j Knowledge Graph: Neo4j memorizza e gestisce il knowledge graph di cybersecurity, abilitando query di relazioni complesse.
Panoramica dell'Implementazione
Per questo blog, saltiamo i dettagli del codice: consultate il repository GitHub per l'implementazione completa. Esaminiamo i passaggi chiave per costruire e distribuire un agente GraphRAG.
- Costruire un Knowledge Graph da Delta Tables: Nel notebook, abbiamo discusso scenari su dati strutturati e non strutturati. Il Neo4j Spark Connector fornisce un mezzo molto semplice per trasformare i dati in Unity Catalog in entità grafiche (nodi/relazioni).
- Distribuire LLM per Query Cypher e QA: GraphRAG richiede LLM per la generazione di query e la sintesi. Abbiamo dimostrato come distribuire gpt-4o, llama-3.x, un modello text2cypher fine-tuned da HuggingFace e servirli utilizzando un endpoint con throughput provisionato.
- Creare e Testare la Catena GraphRAG: Abbiamo dimostrato come utilizzare diversi LLM per Cypher e QA LLM e prompt tramite GraphCypherQAChain. Ciò ci consente di ottimizzare ulteriormente con risultati di tracciamento glass-box utilizzando MLflow Tracing.
- Distribuisci l'agente con Agent Bricks Custom Agents: Utilizza Agent Bricks Custom Agents e MLflow per distribuire l'agente. Nel notebook, il processo include il logging del modello, la sua registrazione in Unity Catalog, la sua distribuzione su un endpoint di serving e il lancio di un'app di revisione per la chat.

Conclusione
GraphRAG è un approccio potente ma altamente personalizzabile per costruire agenti che offrono output di IA più deterministici e contestualmente pertinenti. Tuttavia, il suo design è specifico per il caso d'uso, richiedendo un'architettura ponderata e un'ottimizzazione specifica del problema. Integrando knowledge graph con l'infrastruttura scalabile e gli strumenti di Databricks, puoi costruire sistemi di Compound AI end-to-end che combinano in modo trasparente dati strutturati e non strutturati per generare insight azionabili con una comprensione contestuale più approfondita.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.