La convergenza di formati di tabella aperti e cataloghi aperti: Catalog Commits è generalmente disponibile
Catalog Commits è la prossima evoluzione del lakehouse aperto
di Benjamin Mathew, Michelle Leon, Lukas Rupprecht e Ryan Johnson
Catalog Commits fa un grande passo avanti nell'unificare il lakehouse allineando Delta al modello orientato al catalogo di Iceberg. Con Catalog Commits, i cataloghi diventano il sistema di coordinamento per le tabelle Delta, gestendo la scoperta, l'accesso e lo stato delle tabelle tra i motori.
Oggi, siamo entusiasti di annunciare la Disponibilità Generale di Catalog Commits per tabelle gestite da UC. Questo è un importante aggiornamento della piattaforma che espande l'interoperabilità delle tabelle gestite da UC, rafforza le capacità di governance di UC e sblocca nuove funzionalità, tra cui transazioni multi-istruzione e multi-tabella.
In questo blog, tratteremo…
- Come Delta e Unity Catalog co-evolvono
- I problemi che Catalog Commits risolve
- Come funzionano Catalog Commits
- Come abilitare Catalog Commits sulle tabelle gestite da Unity Catalog
L'evoluzione di Delta Lake e Unity Catalog
Quando Delta Lake è stato creato, il lakehouse necessitava innanzitutto di transazioni affidabili su storage cloud aperto. All'epoca, i cataloghi non erano progettati per coordinare i moderni carichi di lavoro dei dati, quindi Delta fece una scelta architetturale rivoluzionaria: portò le garanzie ACID direttamente nei filesystem dei data lake. Questa base rese possibile il lakehouse.
Poiché il lakehouse è diventato il sistema di registrazione per più team, motori e carichi di lavoro AI, la necessità di una governance unificata attraverso questi diversi asset è diventata fondamentale. Unity Catalog ha fornito quel livello di governance mancante: un unico posto per scoprire, proteggere, controllare e coordinare l'accesso ai dati e agli asset AI attraverso cloud, formati e motori.
Insieme, Delta Lake e Unity Catalog hanno formato le fondamenta del moderno lakehouse. Tuttavia, operavano fianco a fianco: Delta gestiva lo stato transazionale a livello di storage e Unity Catalog governava l'accesso a livello di catalogo. Questa architettura era sufficiente all'inizio, ma man mano che le organizzazioni scalavano su più motori e carichi di lavoro, questo design ha portato a nuove sfide di coordinamento.
Le sfide odierne nel coordinamento tra tabelle e cataloghi
L'architettura originale orientata al filesystem di Delta è stata potente per portare le transazioni ai data lake, ma non è stata progettata per un mondo in cui il catalogo deve coordinare in modo coerente l'identità, l'accesso e lo stato delle tabelle tra molti motori. Poiché le organizzazioni pongono richieste sempre maggiori ai propri dati, la mancanza di coordinamento del catalogo ha esposto tre sfide persistenti:
- Il problema dello "split-brain": i motori esterni che scrivono direttamente nelle tabelle Delta nello storage degli oggetti causano la divergenza silenziosa dei metadati del catalogo, come gli schemi, dallo stato effettivo della tabella.
- Dispersione dell'accesso multi-motore e multi-agente: ogni motore, strumento e agente può accedere alle tabelle in modo diverso, con conseguente frammentazione della scoperta delle tabelle, audit incoerente e nessuna applicazione standardizzata dei controlli a livello di riga o colonna tra i sistemi.
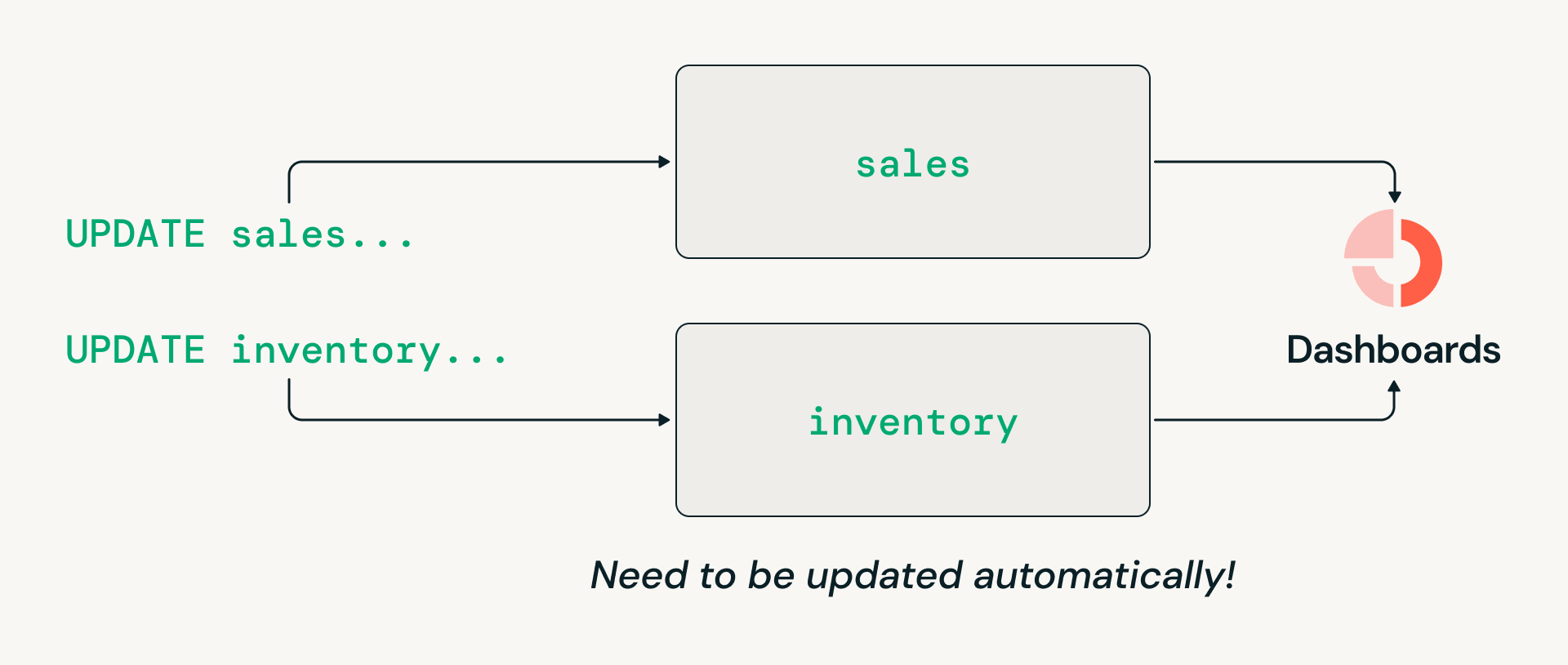
- Coordinamento delle transazioni multi-tabella: le architetture open lakehouse storicamente non hanno supportato scritture atomiche che abbracciano più tabelle, quindi le organizzazioni sono state costrette a mantenere data warehouse legacy specificamente per i carichi di lavoro transazionali.
Sfida #1: Problema dello "split brain" – mantenere sincronizzati cataloghi e tabelle di governance
Oggi, i cataloghi non sono nel percorso di lettura o scrittura per i motori Delta. Quindi, se un motore come Apache Flink vuole apportare una modifica allo schema di una tabella scrivendo direttamente nel livello di storage, il catalogo non viene informato di tali modifiche, creando uno stato di "split-brain" in cui i metadati del catalogo e lo stato effettivo della tabella divergono. Ciò può causare una deriva silenziosa dei metadati e fallimenti delle pipeline downstream.
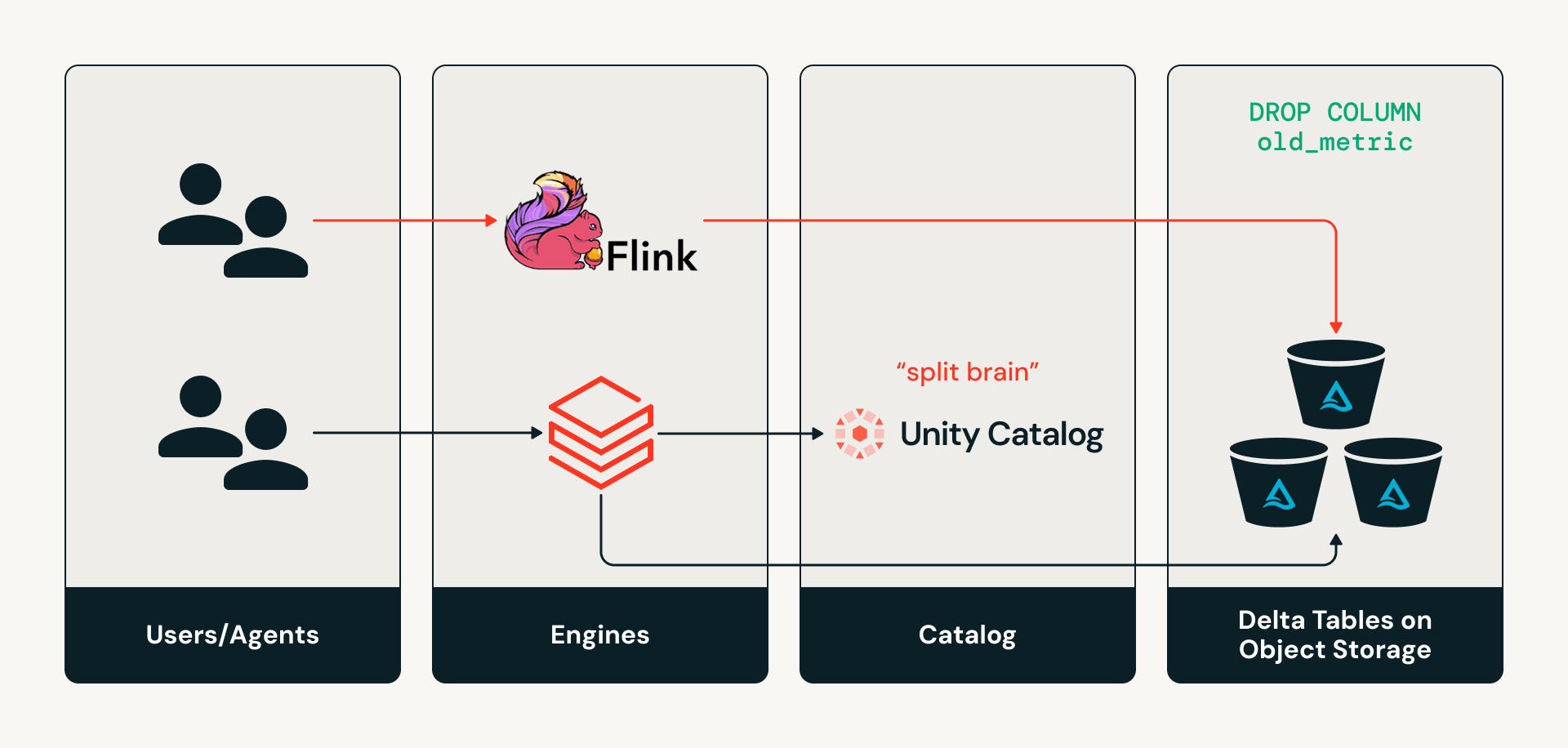
Sfida #2: Dispersione dell'accesso multi-motore e multi-agente
Le organizzazioni moderne utilizzano molti motori e strumenti per analizzare i dati, creare pipeline e alimentare l'AI. Storicamente, questi sistemi hanno avuto accesso ai dati direttamente dallo storage degli oggetti utilizzando percorsi statici. Ciò accoppia strettamente i carichi di lavoro allo storage fisico, rendendo le tabelle difficili da scoprire. Inoltre, poiché ogni motore legge le tabelle Delta direttamente dal livello di storage, che di solito supporta solo permessi granulari, è molto difficile applicare una governance coerente a livello di riga/colonna attraverso tutti i motori. Allo stesso modo, l'audit dell'accesso ai dati rimane frammentato perché non esiste un livello di accesso coerente per catturare le attività tra i motori, quindi gli amministratori potrebbero avere una visione incoerente di come i dati vengono effettivamente utilizzati.
Le organizzazioni necessitano di un luogo centrale per scoprire, governare e controllare i propri dati. Questa esigenza sta diventando ancora più urgente poiché gli agenti AI emergono come consumatori primari dei dati aziendali.
Sfida #3: Coordinamento delle transazioni su più tabelle
I carichi di lavoro di data warehousing richiedono spesso transazioni multi-tabella, come l'aggiornamento atomico delle tabelle vendite e inventario in modo che i lettori downstream vedano sempre una vista coerente. Tuttavia, il design storico orientato al filesystem di Delta Lake limitava le transazioni a singole tabelle. Di conseguenza, anche se molte organizzazioni desiderano consolidarsi sull'architettura lakehouse, hanno dovuto mantenere data warehouse legacy specificamente per questi carichi di lavoro.
Catalog Commits è la prossima evoluzione dell'open lakehouse
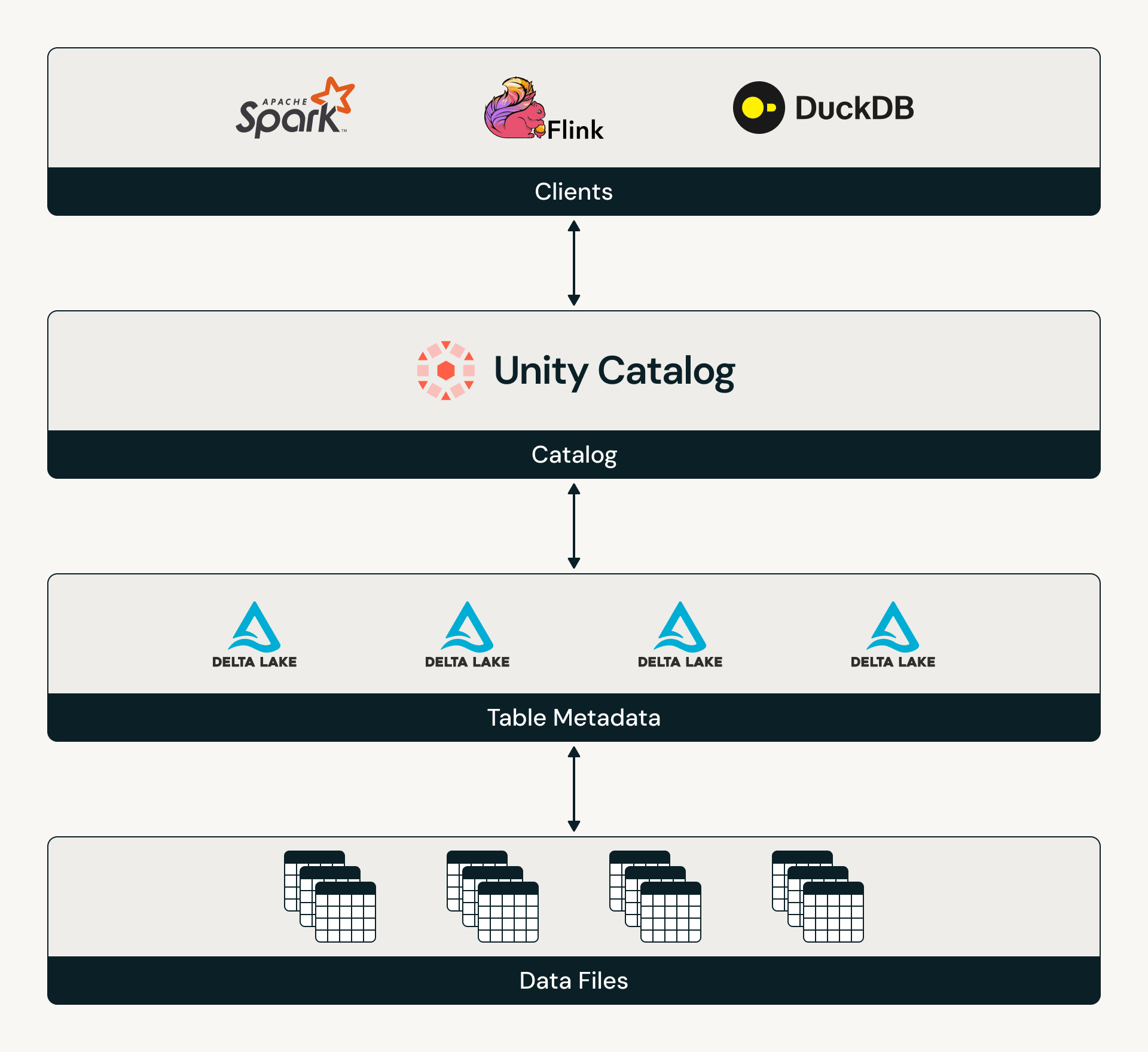
Catalog Commits è lo standard aperto per le tabelle Delta per integrarsi con un catalogo, rendendo il catalogo responsabile del coordinamento dell'accesso alle tabelle e del tracciamento dello stato più recente della tabella. Ora che sia Delta che Iceberg sono orientati al catalogo, i clienti possono fare affidamento sul fatto che le loro tabelle abbiano un modello standardizzato di scoperta e governance delle tabelle. Per saperne di più sulla specifica Catalog Commits, leggi il protocollo Delta e consulta l'implementazione di riferimento di Catalog Commits di Unity Catalog qui.
Su Databricks, Catalog Commits può essere abilitato sulle tabelle Delta gestite da UC. Una volta abilitato, Unity Catalog gestisce tutti gli accessi alle tabelle, creando un modello coerente di scoperta e autorizzazione per qualsiasi motore. Ciò consente alle organizzazioni di centralizzare veramente la governance sui propri asset.
Catalog Commits risolve le sfide di lunga data relative allo split-brain, alla dispersione multi-motore e al coordinamento multi-tabella.
1. Eliminazione del problema dello split-brain: Lo stato della tabella e il catalogo rimangono sincronizzati poiché tutti i motori accedono alle tabelle tramite le stesse API, eliminando qualsiasi rischio di deriva silenziosa dei metadati.
Abilita motori esterni a scrivere su tabelle Delta gestite da Unity Catalog
"Storicamente, lo streaming di dati in un lakehouse governato significava riconciliare i metadati del catalogo fuori banda e sperare che nulla andasse fuori sincrono. Catalog Commits elimina completamente questo divario. Con il servizio Kafka nativo di StreamNative, alimentato da Ursa per l'architettura senza disco e senza leader di Kafka, i dati vengono trasmessi e registrati direttamente tramite Unity Catalog, in modo che ogni record venga registrato come una riga governata immediatamente interrogabile da qualsiasi motore."—Sijie Guo, Co-Founder & CEO, StreamNative
2. Risoluzione della dispersione dell'accesso multi-motore: Poiché ogni motore e agente utilizza API di catalogo standardizzate per risolvere le tabelle, le organizzazioni non hanno più bisogno di codificare percorsi di storage o gestire permessi a livello di filesystem.
Abilita una governance coerente e migliorata su tutti i motori
3. Abilita i carichi di lavoro tradizionali di warehousing sul lakehouse: Il motore Databricks e Unity Catalog possono coordinare scritture atomiche che abbracciano più tabelle. Ciò porta semantiche ACID multi-tabella nel lakehouse, abilitando i carichi di lavoro tradizionali di data warehousing.
Abilita l'esecuzione di transazioni multi-tabella su Databricks
“Le transazioni, unite alle nuove funzionalità SQL come SQL Scripting e Stored Procedures, ci consentono di migrare con sicurezza i nostri carichi di lavoro di data warehousing più critici su Databricks. Questi carichi di lavoro sono alla base dell'analisi essenziale per la nostra attività e avere garanzie transazionali robuste sul lakehouse cambia le regole del gioco.” —Gal Doron, Head of Data, AnyClip
Inoltre, l'abilitazione di Catalog Commits sulle tabelle gestite da UC sblocca anche:
- Auditabilità olistica: Unity Catalog centralizza i metadati delle tabelle e le policy di accesso, consentendo ai team di ispezionare permessi e proprietà delle tabelle tramite un'interfaccia di catalogo coerente anziché fare affidamento esclusivamente sui log di archiviazione di basso livello.
- Ottimizzazioni automatiche delle tabelle: Unity Catalog sfrutta la sua visibilità su tutti gli accessi alle tabelle per organizzare al meglio i dati delle organizzazioni in base ai loro specifici pattern di query, tramite Liquid Clustering e Predictive Optimization.
- Fondamenta per prestazioni migliori: Unity Catalog può informare direttamente i motori sui metadati a livello di tabella senza che il motore debba recuperare i metadati dallo storage cloud, rimuovendo una delle principali cause di latenza dei metadati.
Insieme, queste funzionalità rendono le tabelle gestite da UC con Catalog Commits la base più aperta, governata e performante per il moderno lakehouse.
Abilita oggi stesso Catalog Commits sulle tue tabelle
Catalog Commits su Databricks è generalmente disponibile oggi! Abilitando Catalog Commits sulle tabelle gestite da Unity Catalog, vengono sbloccate le seguenti funzionalità:
- Interoperabilità potenziata: Scritture di motori esterni su tabelle Delta gestite da UC
- Governance più robusta: Sblocca una governance coerente e migliorata su tutti i motori
- Nuove funzionalità: Transazioni multi-istruzione e multi-tabella
I prodotti Databricks che leggono o scrivono su tabelle gestite da UC, dall'ingestion al consumo gold, ora supportano Catalog Commits. Questi includono Streaming Tables, Delta Sharing, Zerobus, Lakeflow Connect, AI Gateway, MLflow e Lakeflow Job Triggers. Allo stesso modo, Catalog Commits è attualmente supportato da motori in tutto l'ecosistema, tra cui Delta Spark, Delta Flink, Starburst Trino, DuckDB e StreamNative.
È anche facile per qualsiasi motore supportare Catalog Commits integrandosi con Delta Kernel, una libreria condivisa di API che astrae i dettagli a livello di protocollo. Delta Kernel semplifica il supporto delle ultime funzionalità Delta per i connettori con semplici aggiornamenti di versione.
Creare una tabella Delta gestita da UC con Catalog Commits abilitato è facile. Utilizzando Databricks Runtime 16.4+, esegui:
Per aggiornare una tabella Delta gestita da UC esistente per abilitare Catalog Commits, usa Databricks Runtime 18.0+ ed esegui:
Inizia con Catalog Commits e unisciti a noi al Data and AI Summit per saperne di più sul nostro lavoro nella costruzione dell'open lakehouse!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.