Protezione dall'esfiltrazione dei dati con Azure Databricks
Scopri i dettagli su come impostare un'architettura Azure Databricks sicura per proteggere dall'esfiltrazione dei dati
Ultimo aggiornamento: 30 ottobre 2025
Letture essenziali
Prima di iniziare, assicurati di avere familiarità con questi argomenti
- Architettura del calcolo serverless di Azure Databricks Architettura
- Terminologia chiave di Databricks
- Cos'è Azure Databricks Private Link (PL) Front-end e Back-end?
- Requisiti per workspace con Private Link abilitato
- Cos'è Service Endpoint Policies per workspace Azure
- Elenco IP per controller di ingresso IP Access List
- Connettività sicura dei cluster
- Networking di Databricks
- Unity Catalog
La Piattaforma Lakehouse di Azure Databricks fornisce un set unificato di strumenti per creare, distribuire, condividere e mantenere soluzioni dati di livello enterprise su larga scala. Databricks si integra con l'archiviazione cloud e la sicurezza nel tuo account cloud, e gestisce e distribuisce l'infrastruttura cloud per tuo conto.
L'obiettivo principale di questo articolo è mitigare i seguenti rischi:
- Accesso ai dati da un browser su Internet o da una rete non autorizzata utilizzando l'applicazione web Databricks.
- Accesso ai dati da un client su Internet o da una rete non autorizzata utilizzando l'API Databricks.
- Accesso ai dati da un client su Internet o da una rete non autorizzata utilizzando Azure Private Link o Service Endpoints.
- Un carico di lavoro compromesso sul cluster Azure Databricks che scrive dati su una risorsa di archiviazione non autorizzata su Azure o su Internet.
Azure Databricks è un servizio di prima parte e supporta gli strumenti e i servizi nativi di Azure che aiutano a proteggere i dati in transito e a riposo. Azure Databricks supporta controlli di sicurezza di rete, come route definite dall'utente, regole del firewall e Network Security Groups.
Oltre agli obiettivi tecnici per questo blog, vogliamo anche assicurarci che i concetti che presentiamo considerino:
- Semplicità: qualsiasi progetto di sicurezza dovrebbe essere ben compreso e manutenibile, e adattarsi alle competenze della tua organizzazione. Una soluzione di sicurezza che viene implementata e non completamente compresa può essere compromessa inavvertitamente.
- Costo operativo della soluzione: dovrebbe sempre essere preso in considerazione. Se un progetto di sicurezza viene abbandonato perché il costo è troppo elevato, allora la soluzione non è stata efficace. La sicurezza dovrebbe essere attenta ai costi e sostenibile.
Indicheremo aree di risparmio sui costi o preoccupazioni sui costi, cercando al contempo di chiarire perché e come funzionano le cose ogni volta che possiamo.
Prima di iniziare, diamo una rapida occhiata all'architettura di distribuzione di Azure Databricks qui:
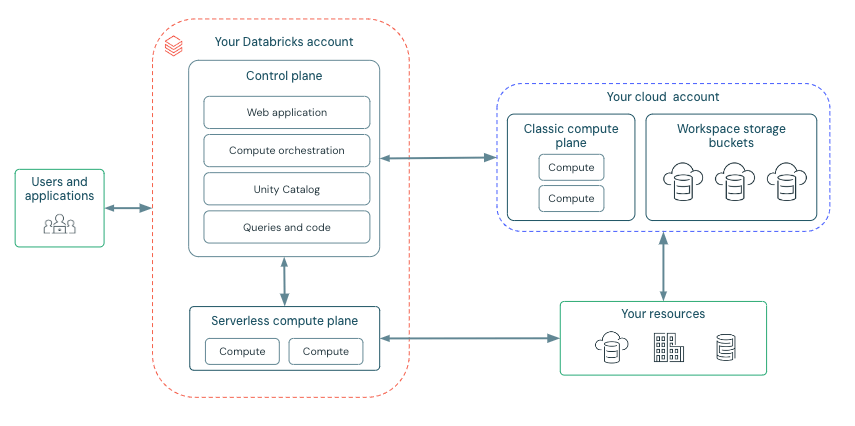
Azure Databricks è strutturato per facilitare la collaborazione sicura tra i team, gestendo molti servizi di backend, permettendoti di concentrarti su data science, data analytics e data engineering.
Azure Databricks è strutturato attorno a due componenti chiave: il piano di controllo e il piano di calcolo.
Piano di controllo:
Il piano di controllo di Azure Databricks, gestito da Databricks all'interno del proprio account Azure, funge da intelligenza principale della piattaforma. Fornisce servizi di backend per l'autenticazione utente, l'orchestrazione di cluster e job e la gestione dello spazio di lavoro, offrendo l'interfaccia web e gli endpoint API per l'interazione del servizio.
Mentre orchestra il ciclo di vita delle risorse di calcolo, non elabora direttamente i dati. Invece, il piano di controllo indirizza l'elaborazione dei dati al piano di calcolo separato, che opera all'interno della sottoscrizione Azure del cliente o del tenant Databricks per le distribuzioni serverless. I comandi dei notebook e molte altre configurazioni dello spazio di lavoro sono archiviati nel piano di controllo e crittografati a riposo.
Piano di calcolo:
Il piano di calcolo è responsabile dell'elaborazione dei tuoi dati. Il tipo specifico di calcolo utilizzato, serverless o classico, dipende dalle risorse di calcolo scelte e dalla configurazione dello spazio di lavoro. Sia il calcolo serverless che quello classico condividono alcune risorse come lo storage predefinito dello spazio di lavoro (dbfs) e le identità gestite associate al tuo tenant Azure.
Calcolo Serverless
Per il calcolo serverless, le risorse operano all'interno di un piano di calcolo in Azure gestito da Databricks. Azure Databricks gestisce quasi tutta l'infrastruttura sottostante, inclusi provisioning, scaling e manutenzione. Questo approccio offre:
- Operazioni semplificate: gli utenti possono concentrarsi su attività di data engineering e data science senza la necessità di gestire cluster o macchine virtuali.
- Efficienza dei costi: gli utenti pagano solo per le risorse di calcolo effettivamente consumate durante l'esecuzione dei carichi di lavoro, eliminando i costi associati ai cluster inattivi.
Le risorse serverless sono disponibili secondo necessità, riducendo i costi di inattività. Eseguono anche all'interno di un confine di rete sicuro nell'account Azure Databricks, con più livelli di sicurezza e controlli di rete.
Calcolo Classico di Azure Databricks
Con il calcolo classico di Azure Databricks, le risorse si trovano all'interno del tuo tenant cloud Azure. Questo fornisce un calcolo gestito dal cliente, in cui i cluster Databricks vengono eseguiti su risorse all'interno della tua sottoscrizione Azure, non del tenant Databricks. Questo offre:
- Isolamento naturale: le operazioni avvengono all'interno della tua sottoscrizione Azure e rete virtuale.
- Connessioni sicure: abilita connessioni sicure ad altri servizi Azure tramite endpoint di servizio o endpoint privati che gestisci e controlli.
Nota importante: i cluster classici, inclusi i warehouse SQL classici, potrebbero richiedere tempi di avvio più lunghi rispetto alle opzioni serverless a causa della necessità di effettuare il provisioning delle risorse dalla tua sottoscrizione Azure.
Distribuzione di workspace Databricks solo serverless (nuova): i workspace solo serverless sono workspace che possono eseguire solo calcolo serverless. Non c'è calcolo classico, quindi tutte le risorse di sistema sono gestite da Azure Databricks, che gestisce tutta l'infrastruttura sottostante, incluso lo storage predefinito del workspace.
Architettura di alto livello
Percorso di comunicazione di rete
Comprendiamo il percorso di comunicazione che vorremmo proteggere. Azure Databricks può essere utilizzato da utenti e applicazioni in numerosi modi, come mostrato di seguito:
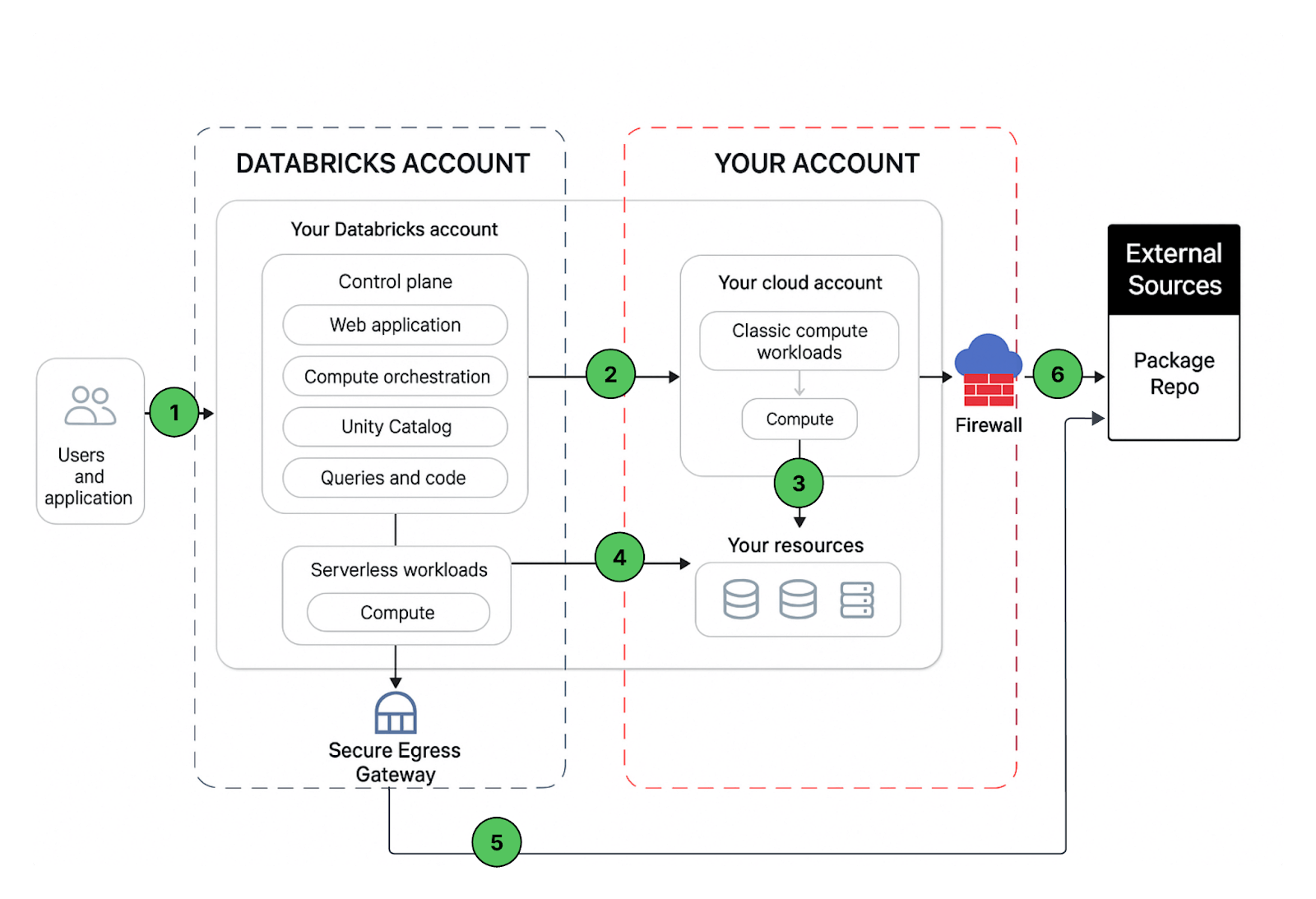
Una distribuzione di workspace Databricks include i seguenti percorsi di rete che potresti proteggere:
- Utente o Applicazioni all'applicazione web Azure Databricks, alias workspace, o alle API REST di Databricks
- Piano di calcolo classico di Azure Databricks, rete virtuale, verso il servizio del piano di controllo di Azure Databricks. Questo include il relay di connettività sicura del cluster e la connessione del workspace per gli endpoint delle API REST.
- Piano di calcolo classico verso i tuoi servizi di archiviazione (es: ADLS gen2, database SQL)
- Piano di calcolo serverless verso i tuoi servizi di archiviazione (es: ADLS gen2, database SQL)
- Egress sicuro dal piano di calcolo serverless tramite policy di rete (firewall in uscita) verso origini dati esterne, ad esempio repository di pacchetti come pypi o maven
- Egress sicuro dal piano di calcolo classico tramite firewall in uscita verso origini dati esterne, ad esempio repository di pacchetti come pypi o maven (potrebbe essere qualsiasi appliance in uscita in esecuzione su Azure, ad esempio Palo Alto)
Dal punto di vista dell'utente finale, l'elemento 1 richiede controlli in ingresso e gli elementi da 2 a 6 richiedono controlli in uscita.
In questo articolo, la nostra area di interesse è proteggere il traffico in uscita dai tuoi carichi di lavoro Databricks, fornire al lettore una guida prescrittiva sull'architettura di distribuzione proposta e, mentre ci siamo, condivideremo anche le best practice per proteggere il traffico in ingresso (utente/client verso Databricks).
Opzioni di distribuzione del workspace
Sono disponibili diverse opzioni per creare un'area di lavoro Azure Databricks sicura accessibile da connessioni on-premise o VPN (senza accesso a Internet). Come best practice, consigliamo di proteggere l'accesso all'area di lavoro utilizzando endpoint privati (Private Link) con una distribuzione standard o semplificata. L'opzione consigliata è la distribuzione standard. L'area di lavoro può essere distribuita tramite il portale di Azure o modelli ARM All-in-one o utilizzando i modelli Terraform Security Reference Architecture (SRA) che consentono la distribuzione di aree di lavoro Databricks e infrastrutture cloud configurate con le best practice di sicurezza.
Private Link front-end vs back-end: Private Link front-end, noto anche come utente verso area di lavoro. Private Link back-end, noto anche come piano di calcolo verso piano di controllo:
Distribuzione standard (consigliata): Per una maggiore sicurezza, Databricks consiglia di utilizzare un endpoint privato separato per le connessioni front-end (client) da una VNet di transito separata. È possibile implementare connessioni Private Link sia front-end che back-end o solo la connessione back-end. Utilizzare una VNet separata per incapsulare l'accesso utente, separato dalla VNet utilizzata per le risorse di calcolo nel piano dati classico. Creare endpoint Private Link separati per l'accesso back-end e front-end. Seguire le istruzioni in Abilita Azure Private Link come distribuzione standard.
È necessaria un'ulteriore considerazione per l'archiviazione di sistema, la messaggistica e l'accesso ai metadati dal piano di calcolo, poiché questi servizi non sono accessibili tramite l'endpoint privato back-end.
Account di archiviazione gestiti dal sistema (solo piano di calcolo classico): Questi account di archiviazione sono necessari per avviare e monitorare i cluster Databricks. Questi account di archiviazione si trovano nel tenant Databricks e devono essere consentiti tramite policy di endpoint di servizio (consigliato), le alternative sarebbero l'utilizzo di tag di servizio di archiviazione che tendono ad essere troppo ampi e facilitano l'esfiltrazione di dati, o l'elenco di consenti individuale dell'FQDN o degli indirizzi IP (non consigliato):
- Artefatto: Immagini Databricks Runtime di sola lettura > 11 GB / nodo cluster
- Registrazione: Messaggistica pesante di lettura/scrittura, inclusa la registrazione di controllo.
- Tabelle di sistema: Dati di controllo, UC e di sistema di sola lettura.
Archiviazione predefinita dell'area di lavoro (DBFS): File system distribuito comune utilizzato per lo spazio di lavoro temporaneo, i servizi, i risultati SQL temporanei (recupero cloud), i driver. Può essere protetto tramite endpoint privati utilizzando la funzionalità DBFS privata per il calcolo classico e l'endpoint di servizio o l'endpoint privato per il calcolo serverless.
Messaggistica: (Event Hub, solo piano di calcolo classico) Questa è una risorsa accessibile pubblicamente utilizzata per il tracciamento della discendenza e altre messaggistiche leggere. Può essere consentita tramite il tag di servizio EventHub nell'UDR e/o nel Firewall.
Metadati: (SQL, solo piano di calcolo classico): Questa è una risorsa accessibile pubblicamente utilizzata per il traffico legacy del metastore Hive.
Accesso all'account di archiviazione a livello utente: Account ALDS e Blob Storage utilizzati per i dati del cliente anziché per i dati di sistema.
Risorse di prima parte: Cosmos DB, Azure SQL, DataFactory ecc…
Risorse esterne: S3, BigQuery, Snowflake ecc…
Architettura di protezione dell'esfiltrazione dati di alto livello
Consigliamo un'architettura di riferimento hub and spoke. In questo modello, la rete virtuale hub ospita l'infrastruttura condivisa necessaria per connettersi a origini validate e, facoltativamente, ad ambienti on-premise. Le reti virtuali spoke si connettono in peering con l'hub e contengono aree di lavoro Azure Databricks isolate per diverse unità aziendali o team.
Questa architettura hub-and-spoke consente la creazione di più VNet spoke personalizzate per vari scopi e team. L'isolamento può essere ottenuto anche creando subnet separate per team diversi all'interno di un'unica, grande rete virtuale. In questi casi, è possibile stabilire più aree di lavoro Azure Databricks isolate, ciascuna nella propria coppia di subnet, e distribuire Azure Firewall in una subnet separata all'interno della stessa rete virtuale.
Prerequisiti
| Elemento | Dettagli |
|---|---|
| Rete Virtuale |
|
| Subnet | Tre subnet: Host (Pubblica), Container (Privata) e Subnet endpoint privato (per contenere endpoint privati per l'archiviazione, DBFS e altri servizi Azure che potresti utilizzare) |
| Tabelle di routing | Instrada il traffico in uscita dalle subnet Databricks verso l'appliance di rete, Internet o le origini dati On-prem |
| Azure Firewall | Ispeziona qualsiasi traffico in uscita e intraprende azioni in base alle policy di consenti/nega |
| Zone DNS private | Fornisce un servizio DNS affidabile e sicuro per gestire e risolvere i nomi di dominio in una rete virtuale (può essere creato automaticamente come parte della distribuzione se non disponibile) |
| Policy di endpoint di servizio | Policy per consentire l'accesso a qualsiasi account di archiviazione non basato su endpoint privato, inclusa l'archiviazione di sistema per l'account di archiviazione dell'area di lavoro (dbfs), l'archiviazione di artefatti e registri e le tabelle di sistema. |
| Azure Key Vault | Memorizza la CMK per la crittografia di DBFS, disco gestito e servizi gestiti. |
| Connettore di accesso Azure Databricks | Richiesto se si abilita Unity Catalog. Per connettere identità gestite a un account Azure Databricks allo scopo di accedere ai dati registrati in Unity Catalog |
| Elenco dei servizi Azure Databricks da consentire nel Firewall | Si prega di seguire questa documentazione pubblica e creare un elenco di tutti gli IP e nomi di dominio pertinenti alla tua distribuzione databricks |
Architettura di distribuzione
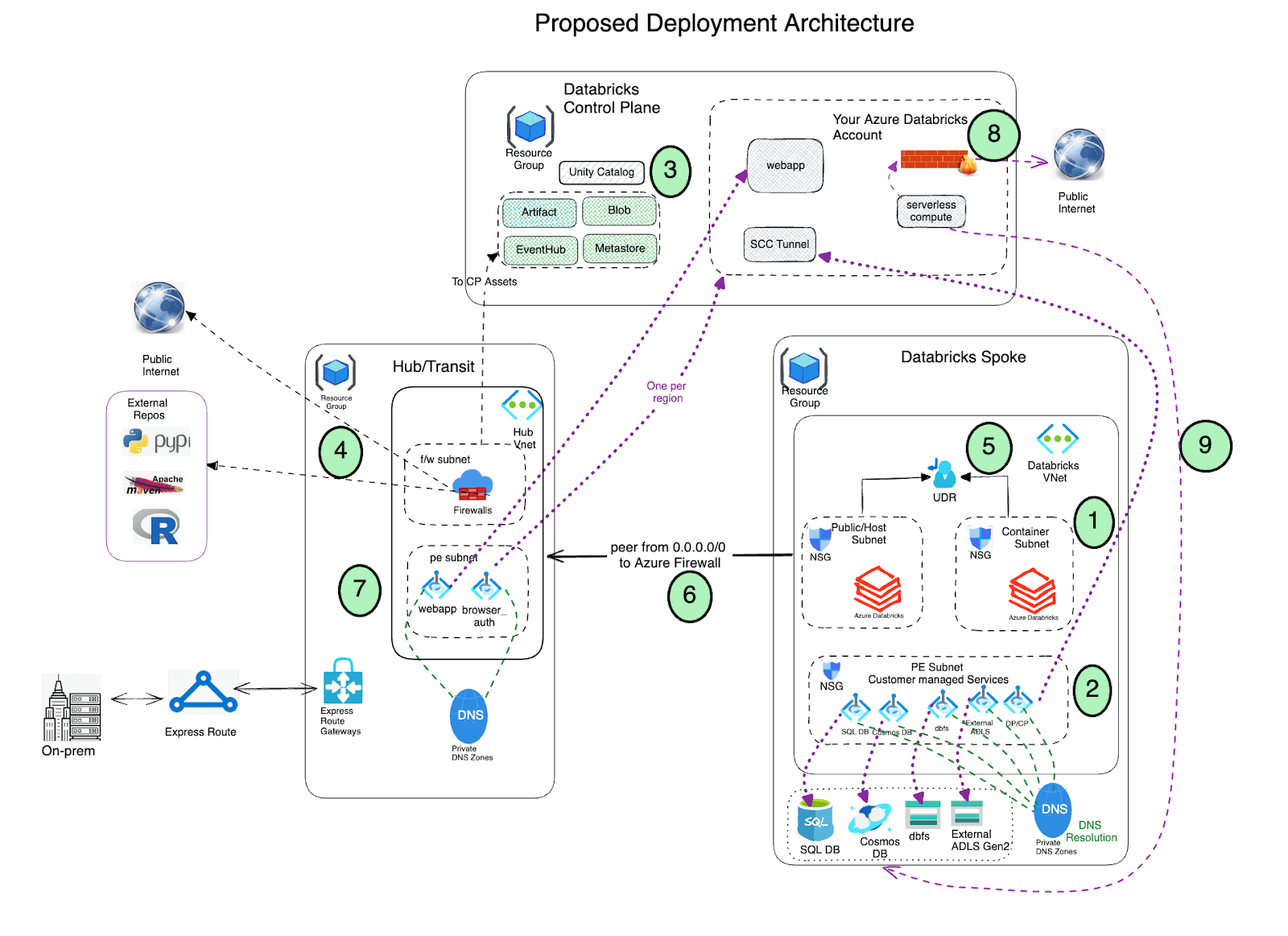
- Distribuisci Azure Databricks con la connettività cluster sicura (SCC) abilitata in una rete virtuale spoke utilizzando l'iniezione VNet e Private Link.
- La rete virtuale deve includere due subnet dedicate a ciascuna area di lavoro Azure Databricks: una subnet privata e una subnet pubblica (sentiti libero di usare una nomenclatura diversa). Si noti che esiste una relazione uno-a-uno tra queste subnet e un'area di lavoro Azure Databricks. Non è possibile condividere più aree di lavoro tramite la stessa coppia di subnet e deve essere utilizzata una nuova coppia di subnet per ogni area di lavoro diversa.
- Azure Databricks crea un'archiviazione blob predefinita (nota anche come archiviazione radice) durante il processo di distribuzione, utilizzata per archiviare log e telemetria. Sebbene l'accesso pubblico sia abilitato su questa archiviazione, l'assegnazione di negazione creata su questa archiviazione proibisce qualsiasi accesso esterno diretto all'archiviazione; è accessibile solo tramite l'area di lavoro Databricks. Le distribuzioni Azure Databricks ora supportano la connettività privata all'account di archiviazione predefinito dell'area di lavoro (DBFS).
- Importante: Come best practice, NON è consigliato archiviare dati applicativi nel contenitore radice (DBFS) di archiviazione. L'accesso al contenitore radice DBFS può ora essere disabilitato e invece consigliamo di utilizzare i volumi di Unity Catalog. I volumi di Unity Catalog offrono governance e sicurezza moderne rispetto all'archiviazione radice DBFS.
- Configura gli endpoint Private Link per i tuoi Servizi Dati Azure (account di archiviazione, Eventhub, database SQL, ecc.) in una subnet separata all'interno della rete virtuale spoke di Azure Databricks. Questo garantirebbe che tutti i dati del carico di lavoro vengano accessi in modo sicuro tramite la rete backbone di Azure con protezione predefinita contro l'esfiltrazione dei dati (fare riferimento a questo blog per maggiori dettagli). Inoltre, in generale, è perfettamente accettabile distribuire questi endpoint in un'altra rete virtuale collegata in peering a quella che ospita l'area di lavoro di Azure Databricks. Tieni presente che gli endpoint privati comportano costi aggiuntivi ed è accettabile sfruttare (in base alle policy di sicurezza della tua organizzazione) i Service Endpoint anziché gli endpoint privati per accedere ai servizi dati di Azure, in particolare utilizzando le Service Endpoint Policy per un accesso sicuro agli account di archiviazione
- Sfrutta Azure Databricks Unity Catalog per una soluzione di governance unificata.
Distribuisci Azure Firewall (o un'altra Network Virtual Appliance) in una rete virtuale hub. Con Azure Firewall, potresti configurare:
- Regole Applicazione che definiscono i nomi di dominio completi (FQDN) accessibili tramite il firewall. È altamente raccomandato utilizzare le Regole Applicazione per le risorse del piano di controllo di Azure Databricks control plane, ad esempio: piano di controllo, web app e relay SCC.
- Regole di Rete che definiscono indirizzo IP, porta e protocollo per gli endpoint che non possono essere configurati tramite FQDN. Parte del traffico richiesto da Azure Databricks deve essere incluso nella whitelist utilizzando le regole di rete.
Se utilizzi un'appliance firewall di terze parti anziché Azure Firewall, funziona ugualmente. Tieni presente che ogni prodotto ha le sue sfumature ed è meglio coinvolgere i team di supporto prodotto e di sicurezza di rete pertinenti per risolvere eventuali problemi specifici.
- Il Service Tag di AzureDatabricks non è richiesto se gli endpoint privati sono abilitati per l'area di lavoro.
- Quando si utilizzano le Service Endpoint Policy, non sono necessarie regole di rete per gli account di archiviazione gestiti da Databricks (artefatti, logging e tabelle di sistema) nel firewall. Inoltre, non sono necessari o raccomandati tag di servizio di archiviazione.
- Azure Databricks effettua anche chiamate aggiuntive ai servizi NTP, CDN, Cloudflare, driver GPU e archivi esterni per i set di dati demo che devono essere inclusi nella whitelist in modo appropriato.
Il traffico di rete non locale dai subnet del piano di calcolo di Databricks dovrebbe essere instradato attraverso un'appliance di uscita come Azure Firewall utilizzando un route definito dall'utente (ad esempio, una route predefinita 0.0.0.0/0). Ciò garantisce che tutto il traffico in uscita venga ispezionato. Tuttavia, l'uscita verso il piano di controllo, utilizzando endpoint privati, bypasserà queste tabelle di route e le appliance di uscita. Altri componenti del piano di controllo, come SQL, Event Hubs e archiviazione, verranno tuttavia instradati attraverso la tua appliance di uscita.
- Per gli account di archiviazione del servizio Databricks (artefatti, logging e tabelle di sistema), potresti considerare l'opzione di bypassare la tua appliance di uscita (NVA o firewall) per evitare potenziali limitazioni e ridurre i costi di trasferimento dati. L'accesso allo storage degli artefatti da solo può rappresentare fino a 11 GB scaricati per nodo cluster. Si consiglia di utilizzare i service endpoint per lo storage in combinazione con le Service Endpoint Policy. Queste policy garantiscono che l'area di lavoro possa accedere solo agli account di archiviazione designati per artefatti, logging e tabelle di sistema inclusi nella sua policy allegata tramite la sua subnet. Le Service Endpoint Policy sono compatibili anche con altri accessi ad account di archiviazione non tramite private link. Con le service endpoint policy, non sono necessari o raccomandati tag di servizio di archiviazione.
- In alternativa, il traffico in uscita verso gli asset del Piano di Controllo può essere instradato direttamente a Internet aggiungendo regole di Service Tag alla tabella di route, bypassando il firewall. Questo può aiutare a evitare limitazioni e costi aggiuntivi di trasferimento dati associati alle Network Virtual Appliance.
Considerazione Importante: Tieni presente che questo consentirà l'uscita verso account e servizi di archiviazione in tutta la regione, non solo verso quelli a cui intendi accedere. Questo è un fattore critico da considerare attentamente quando si progetta la propria architettura di sicurezza.
- Configura il peering di rete virtuale tra le reti virtuali spoke di Azure Databricks e hub di Azure Firewall.
- Distribuisci endpoint privati per il Front end e l'autenticazione del browser (per SSO) sull'Hub Vnet (subnet dell'endpoint privato)
- Configura le policy di rete per il calcolo serverless per governare il traffico di rete in uscita. Tieni presente che il calcolo serverless è collegato al tuo Account Azure Databricks
- Configura la Configurazione Connettività di Rete (NCC) di Azure Databricks per stabilire una connessione sicura tra le tue risorse di calcolo serverless e i tuoi servizi di archiviazione Azure (come ADLS Gen2 e SQL Database) utilizzando Azure Private Link.
Domande Comuni con Architettura di Protezione dall'Esfiltrazione dei Dati
Posso usare i service endpoint per proteggere l'esfiltrazione dei dati verso i Servizi Dati Azure?
Sì, i Service Endpoint forniscono una connettività sicura e diretta ai servizi Azure posseduti e gestiti dai clienti (ad es. ADLS gen2, Azure KeyVault o eventhub) tramite un percorso ottimizzato sulla rete backbone di Azure. I Service Endpoint possono essere utilizzati per proteggere la connettività alle risorse Azure esterne solo alla tua rete virtuale.
Posso usare le service endpoint policy con i servizi di archiviazione gestiti da Databricks?
Sì, le Service Endpoint Policy sono disponibili in anteprima pubblica dal 01/10/2025. Vedi: Configura le policy dei service endpoint di rete virtuale Azure per l'accesso allo storage dal calcolo classico
Posso usare una Network Virtual Appliance (NVA) diversa da Azure Firewall?
Sì, puoi utilizzare un'NVA di terze parti purché le regole del traffico di rete siano configurate come discusso in questo articolo. Tieni presente che abbiamo testato questa configurazione solo con Azure Firewall, sebbene alcuni dei nostri clienti utilizzino altre appliance di terze parti. È ideale distribuire l'appliance nel cloud piuttosto che averla on-premises.
Posso avere una subnet firewall nella stessa rete virtuale di Azure Databricks?
Sì, puoi. Secondo l'architettura di riferimento Azure, è consigliabile utilizzare una topologia di rete virtuale hub-spoke per pianificare meglio il futuro. Se scegli di creare la subnet di Azure Firewall nella stessa rete virtuale delle subnet dell'area di lavoro di Azure Databricks, non avrai bisogno di configurare il peering di rete virtuale come discusso nel Passaggio 6 sopra.
Posso filtrare il traffico IP del SCC Relay del piano di controllo di Azure Databricks tramite Azure Firewall?
Sì, puoi, ma vorremmo che tenessi a mente questi punti:
- Quando si utilizzano endpoint privati per il piano di controllo di Databricks, il traffico tra i cluster Azure Databricks (data plane) e il servizio SCC Relay rimane privato sulla rete Azure e non transita su Internet pubblico. Questo è principalmente traffico di gestione per garantire il corretto funzionamento dell'area di lavoro di Azure Databricks.
- Quando si utilizza l'accesso non privato al piano di controllo di Databricks, gli intervalli CIDR di SCC Relay e WebUI sono coperti dal service tag AzureDatabricks. Per altri tipi di firewall / NVA, fare riferimento all'ultima versione di Indirizzi IP e domini per i servizi e gli asset di Azure Databricks. Raccomandiamo vivamente di utilizzare un FQDN di regola applicazione per il tunnel SCC nelle configurazioni delle regole del firewall.
- Il servizio SCC Relay e il data plane necessitano di una comunicazione di rete stabile e affidabile; l'introduzione di un firewall o di un appliance virtuale tra di essi crea un singolo punto di errore, ad esempio in caso di errata configurazione di una regola del firewall o di manutenzione programmata, che potrebbe causare ritardi eccessivi nell'avvio del cluster (problema transitorio del firewall) o impedire la creazione di nuovi cluster, o influire sulla pianificazione e sull'esecuzione dei job.
È possibile analizzare il traffico accettato o bloccato da Azure Firewall?
Sì, per questo requisito consigliamo di utilizzare i log e le metriche di Azure Firewall.
È possibile aggiornare un'installazione Databricks non NPIP esistente (distribuzione Databricks gestita) a un'area di lavoro abilitata per NPIP o PL?
Sì, una distribuzione Databricks gestita può essere aggiornata a un'area di lavoro VNet Injected.
Perché sono necessarie due subnet per area di lavoro?
Un'area di lavoro richiede due subnet, comunemente note come subnet "host" (o "pubblica") e "container" (o "privata"). Ogni subnet fornisce un indirizzo IP all'host (Azure VM) e al container (Databricks runtime, noto anche come dbr) che viene eseguito all'interno della VM.
La subnet pubblica o host dispone di IP pubblici?
No, quando si crea un'area di lavoro utilizzando secure cluster connectivity (SCC), nessuna delle subnet di Databricks dispone di indirizzi IP pubblici. È solo che il nome predefinito della subnet host è public-subnet. SCC garantisce che nessun traffico di rete dall'esterno della rete entri, ad esempio tramite SSH, in una delle istanze di calcolo dell'area di lavoro Databricks.
È possibile ridimensionare/modificare le dimensioni delle subnet dopo la distribuzione?
Sì, è possibile ridimensionare o modificare le dimensioni delle subnet dopo la distribuzione. È anche possibile modificare la rete virtuale o i nomi delle subnet (anteprima pubblica con limitazioni). Contattare il supporto Azure e inviare un caso di supporto per il ridimensionamento delle subnet.
È possibile sostituire/modificare le reti virtuali dopo la distribuzione?
Sì, fare riferimento alla documentazione pubblica.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.