Databricks Lakehouse e Data Mesh, Parte 1
di Sharon Richardson, Bernhard Walter, Pawarit Laosunthara, Guillermo Schiava D'Albano, Fran Medina Castro e Amr Ali
Questo è il primo post di una serie in due parti. In questo articolo introdurremo il concetto di data mesh e le funzionalità di Databricks disponibili per implementare un data mesh. Il secondo articolo esaminerà diverse opzioni di data mesh e fornirà dettagli sull'implementazione di un data mesh basato sul Databricks Lakehouse.
Il data mesh è un paradigma che descrive un insieme di principi e un'architettura logica per scalare le piattaforme di analisi dei dati. Lo scopo è ricavare maggior valore dai dati come asset su larga scala. Il termine 'data mesh' è stato introdotto da Zhamak Dehghani nel 2019 e ampliato nel suo articolo del 2020 Data Mesh Principles and Logical Architecture.
Al centro dell'architettura logica del data mesh ci sono quattro principi:
- Proprietà del dominio: adozione di un'architettura distribuita in cui i team di dominio - produttori di dati - mantengono la piena responsabilità dei propri dati durante tutto il loro ciclo di vita, dalla cattura alla cura, all'analisi e al riutilizzo
- Dati come prodotto: applicazione dei principi di gestione dei prodotti al ciclo di vita dell'analisi dei dati, garantendo che dati di qualità siano forniti ai consumatori di dati che possono trovarsi all'interno e all'esterno del dominio del produttore
- Piattaforma infrastrutturale self-service: adozione di un approccio indipendente dal dominio al ciclo di vita dell'analisi dei dati, utilizzando strumenti e metodi comuni per costruire, eseguire e mantenere prodotti dati interoperabili
- Governance federata: garanzia di un ecosistema di dati che aderisce alle regole organizzative e alle normative di settore attraverso la standardizzazione
I prodotti dati sono un concetto importante per il data mesh. Non sono intesi solo come set di dati, ma come dati trattati come un prodotto: devono essere individuabili, affidabili, auto-descrittivi, indirizzabili e interoperabili. Oltre ai dati e ai metadati, possono contenere codice, dashboard, feature, modelli e altre risorse necessarie per creare e mantenere il prodotto dati.
Molti clienti chiedono: "Possiamo creare un data mesh con Databricks Lakehouse?" La risposta è sì! Diversi dei maggiori clienti Databricks a livello mondiale hanno adottato il data mesh utilizzando il Lakehouse come fondamento tecnologico.
Databricks Lakehouse è una piattaforma cloud-native per dati, analisi e AI che combina le prestazioni e le funzionalità di un data warehouse con il basso costo, la flessibilità e la scalabilità di un moderno data lake. Per un'introduzione, leggi Cos'è un Lakehouse?
Il lakehouse affronta una preoccupazione fondamentale dei data lake che ha portato ai principi del data mesh: un data lake monolitico può diventare una palude di dati ingestibile. Databricks Lakehouse è un'architettura aperta che offre flessibilità nel modo in cui i dati vengono organizzati e strutturati, fornendo al contempo un'infrastruttura di gestione unificata per tutti i carichi di lavoro di dati e analisi.
L'unità organizzativa principale all'interno della piattaforma Databricks Lakehouse che corrisponde al concetto di domini in un data mesh è il 'workspace'. Un Databricks Lakehouse può avere uno o più workspace, ognuno dei quali abilita la proprietà locale dei dati e il controllo degli accessi.
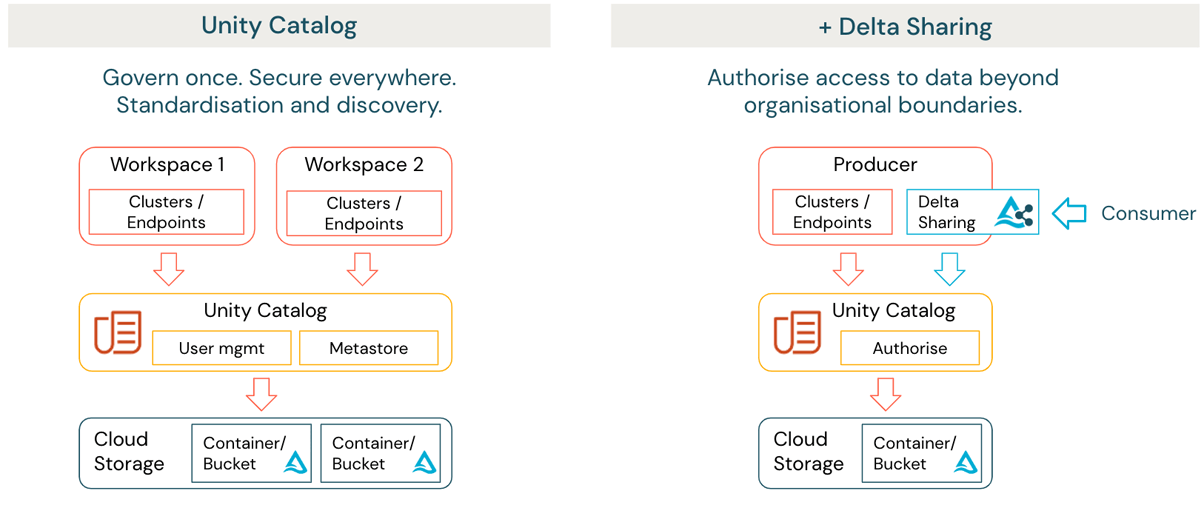
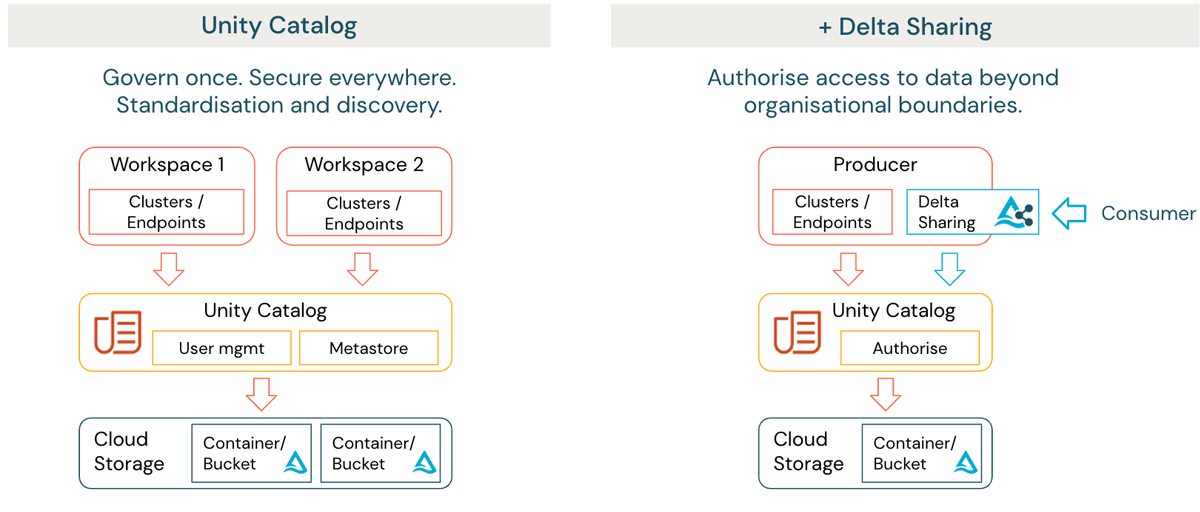{kind=link}
Ogni workspace incapsula uno o più domini, funge da hub per la collaborazione e consente al/ai dominio/i di gestire i propri prodotti dati utilizzando un'infrastruttura comune self-service e indipendente dal dominio. Ciò può includere l'automazione nel provisioning dell'ambiente e l'orchestrazione delle pipeline di dati utilizzando servizi integrati come Databricks Workflows, e l'automazione del deployment utilizzando il provider Terraform di Databricks. Unity Catalog fornisce governance federata, discovery e lineage come servizio centralizzato a livello di account dell'organizzazione che esegue Databricks. (figura 1 lato sinistro).
Molte organizzazioni hanno la necessità di considerare come i dati possano essere condivisi in modo sicuro con parti esterne oltre un confine di governance. Ciò può applicarsi anche a domini interni ospitati su diversi provider cloud e regioni. Databricks Lakehouse fornisce una soluzione sotto forma di Delta Sharing (figura 1 lato destro). Delta Sharing consente alle organizzazioni di condividere dati in modo sicuro con parti esterne indipendentemente dalla piattaforma di calcolo. I dati non necessitano di essere duplicati e l'accesso viene automaticamente verificato e registrato.
Delta Sharing fornisce anche le basi per una gamma più ampia di attività di condivisione dati esterna. Ciò include la pubblicazione o l'acquisizione di dati tramite un marketplace di dati come il Databricks Marketplace, e la collaborazione sicura sui dati attraverso confini organizzativi e tecnici, abilitata all'interno della piattaforma Databricks come Databricks Cleanrooms.
La combinazione di Unity Catalog e Delta Sharing significa che la piattaforma Databricks Lakehouse offre flessibilità nel modo in cui un'organizzazione sceglie di organizzare e gestire dati e analisi su larga scala, incluse implementazioni che coprono più provider cloud, diverse regioni geografiche e implementazioni che richiedono la capacità di condividere asset di dati con entità esterne. Con Databricks Lakehouse, i dati possono essere organizzati in un data mesh, ma possono anche essere organizzati utilizzando qualsiasi architettura appropriata, da completamente centralizzata a completamente distribuita.
La seconda parte di questo post del blog esaminerà diverse opzioni di data mesh e fornirà dettagli su come implementare un data mesh basato su Databricks Lakehouse.
Per saperne di più sulle funzionalità di Databricks Lakehouse menzionate in questo post:
- Cos'è un Lakehouse
- Cos'è Databricks Lakehouse
- Introduzione a Databricks Unity Catalog
- Introduzione a Databricks Delta Sharing
- Introduzione a Databricks Cleanrooms
- Introduzione a Databricks Marketplace
- Provider Terraform di Databricks
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.