Databricks a SIGMOD 2026
di Indrajit Roy
- Scopri come Databricks sta aprendo la strada alla prossima generazione di data engineering con Spark Declarative Pipelines (SDP), semplificando complessi carichi di lavoro ETL e di streaming.
- Approfondisci Enzyme, il nostro motore di manutenzione incrementale delle viste, che ha vinto una menzione d'onore alla conferenza SIGMOD.
- Incontra i nostri ingegneri alla conferenza per discutere di queste innovazioni leader del settore.
Databricks continua a guidare l'innovazione ingegneristica, spingendo costantemente i confini di ciò che è possibile nello spazio dei Dati e dell'IA. Siamo entusiasti di annunciare che il nostro lavoro su Spark Declarative Pipelines sarà presentato a SIGMOD 2026 e ha ricevuto una menzione d'onore alla conferenza. Ci recheremo a SIGMOD, dal 1 al 5 giugno, come sponsor Platino. SIGMOD si terrà a Bangalore, in India, che è anche un importante hub R&D di Databricks.
I nostri prossimi paper sull'ingegneria dei dati mostrano come Databricks ha semplificato l'elaborazione incrementale per i clienti. Ci sono due modi per scrivere programmi incrementali in Spark Declarative Pipelines (SDP), e i clienti possono combinarli all'interno di una pipeline:
- Gli ingegneri dei dati possono specificare Viste Materializzate per le trasformazioni. Il motore Enzyme le mantiene incrementalmente man mano che arrivano nuovi dati. Tutta la complessità dell'elaborazione incrementale è completamente nascosta ai creatori delle viste materializzate. Il paper SIGMOD 2026 “Enzyme: Incremental View Maintenance for Data Engineering” discute alcune di queste idee.
- Gli ingegneri dei dati esperti nell'elaborazione di stream possono invece utilizzare il motore di streaming di SDP per elaborare i dati in modo incrementale. Le API di streaming forniscono un'ampia varietà di costrutti – dagli operatori stateful ai watermark, rendendo facile esprimere logiche di business complesse come aggregazioni personalizzate. Le idee chiave nel nostro prodotto di streaming appariranno nel paper VLDB 2026 “A Decade of Apache Spark Structured Streaming: How We Evolved the Architecture To Meet Real-world Needs”.
Ecco un'anteprima del paper Enzyme e di ciò su cui il team ha lavorato:
Enzyme a SIGMOD 2026
Manutenzione Incrementale delle Viste
Supponiamo che tu sia un analista in un'azienda e voglia analizzare il numero totale di ordini venduti in una regione. La vista materializzata qui sotto fornisce la risposta.
CREATE MATERIALIZED VIEW order_report as
SELECT region, sum(orders)
FROM customer_and_order_table
GROUP by region
Man mano che vengono aggiunti nuovi ordini, ti aspetti che la vista materializzata rimanga aggiornata. Questa manutenzione dei dati è essenzialmente il problema della manutenzione incrementale delle viste. Mentre mantenere aggiornata la MV di esempio sopra sembra semplice, immagina se la MV dovesse unire dati da più tabelle o avesse funzioni finestra o facesse chiamate a funzioni LLM.
Innovazioni di Enzyme
Le viste materializzate (MV) sono popolari per l'accelerazione delle query – velocizzando i dashboard sui dati presenti nei data warehouse. Quando abbiamo creato Spark Declarative Pipelines, abbiamo deciso di andare oltre l'accelerazione delle query e applicare le viste materializzate ai casi d'uso extract-transform-load (ETL). La nostra osservazione chiave è che se le MV possono essere mantenute in modo efficiente e incrementale, ciò semplificherà notevolmente i carichi di lavoro ETL che altrimenti richiederebbero la scrittura di codice personalizzato complesso.
Enzyme si aggiunge alla ricca letteratura sulla manutenzione incrementale delle viste materializzate e dimostra come scalare queste tecniche su carichi di lavoro di produzione. Alcune delle innovazioni su cui il team ha lavorato sono:
- Supporto per estesi pattern di MV: Enzyme mantiene incrementalmente MV complesse in produzione, incluse quelle con join, funzioni finestra, aggregazioni e loro combinazioni. A differenza di altre soluzioni industriali, Enzyme supporta anche funzioni non deterministiche come current_date() e funzioni specifiche per l'IA.
- Supporto multi-lingua: Mentre la maggior parte delle soluzioni industriali si concentra solo su SQL, Enzyme supporta anche MV specificate in Python. Python è ora il linguaggio di scelta per la maggior parte dei carichi di lavoro di data engineering e AI. Enzyme risolve molte sfide interessanti che il supporto multi-lingua comporta, come il rilevamento accurato delle modifiche nella definizione della MV.
- Ottimizzazioni delle prestazioni: Enzyme dispone di molteplici ottimizzazioni per ridurre la quantità di dati da elaborare, comprese tecniche che determinano automaticamente se gli aggiornamenti debbano essere applicati a livello di partizione anziché di riga, riducendo così gli overhead di riscrittura. Memorizza selettivamente i risultati intermedi per ridurre i costi di IO. Utilizza un modello di costo che sfrutta le informazioni del piano e le esecuzioni precedenti per determinare la strategia di incrementalizzazione più efficiente.
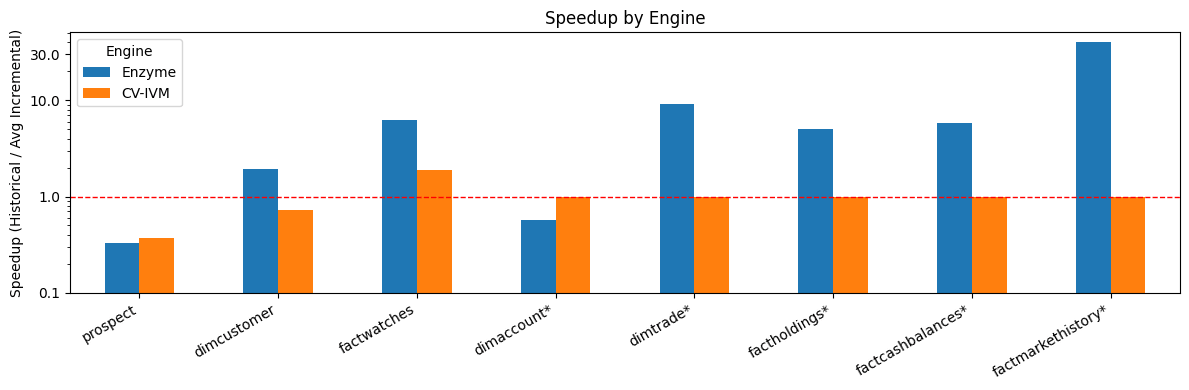
Figura 1: Enzyme ha prestazioni significativamente migliori rispetto a un'altra soluzione industriale concorrente (nome anonimizzato a CV-IVM a causa di restrizioni di licenza).
Interessato a saperne di più? Dai un'occhiata al paper e se sei a SIGMOD, partecipa al nostro intervento per maggiori dettagli.
Incontra il team a SIGMOD:
Fermati al nostro stand per incontrare il team e saperne di più sull'innovazione che sta avvenendo in Databricks. Inoltre, non perdere l'occasione di ascoltare direttamente da Ritwik Yadav, durante la sua presentazione a SIGMOD!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.