Disaccoppiato by design: ricerca vettoriale su scala miliardaria
di Zero Qu, Erik Lindgren, Sheng Zhan, Ankit Vij, Sergei Tsarev e Dima Kotlyarov
Introduzione
La ricerca vettoriale è diventata un'infrastruttura fondamentale per le applicazioni di IA, dalla ricerca all'interno del prodotto ai sistemi di raccomandazione, alla risoluzione di entità, fino alla generazione aumentata da recupero. Ma man mano che i set di dati crescono da milioni a miliardi di vettori, i sistemi creati per gestirli iniziano a guastarsi in modi costosi: i costi della memoria esplodono, l'ingestione blocca il serving e la scalabilità richiede la replica di tutto.
In Databricks, abbiamo riscontrato questi limiti con la nostra offerta originale di ricerca vettoriale, quindi siamo tornati ai principi fondamentali e l'abbiamo riprogettata da zero. Oggi, Databricks AI Search offre due opzioni di implementazione: endpoint Standard, che mantengono i vettori a piena precisione interamente in memoria per una latenza di decine di millisecondi, ed endpoint ottimizzati per lo storage, che separano lo storage dal compute per servire miliardi di vettori a una frazione del costo, con latenze delle query nell'ordine delle centinaia di millisecondi, un compromesso deliberato per carichi di lavoro in cui il costo e la Scale sono più importanti di tempi di risposta di pochi millisecondi.
Ricerca vettoriale ottimizzata per lo storage è stata modellata da tre decisioni ingegneristiche fondamentali:
- Separare lo storage dal calcolo. Gli indici vettoriali risiedono nello storage a oggetti del cloud e vengono caricati in memoria solo per il serving. L'ingestion viene eseguita su cluster Spark serverless effimeri, completamente isolata dal percorso di query.
- Crea algoritmi di indicizzazione distribuita su Spark. Anziché affidarci a librerie di indicizzazione per macchine singole, abbiamo sviluppato le nostre — clustering distribuito, compressione vettoriale e layout dei dati allineato alle partizioni — come Job Spark nativi che scalano linearmente con le dimensioni del cluster.
- Gestisci le query da un motore Rust con un'architettura a doppio runtime. Un motore di query appositamente creato utilizza pool di thread separati per l'I/O asincrono e il calcolo vettoriale legato alla CPU, in modo che l'uno non ostacoli l'altro.
Il risultato: indici da un miliardo di vettori creati in meno di 8 ore, indicizzazione 20 volte più veloce e costi di serving fino a 7 volte inferiori.
Questo post è il resoconto di ingegneria di come lo abbiamo costruito.
Il problema dei database vettoriali tradizionali
I limiti dell'accoppiamento stretto
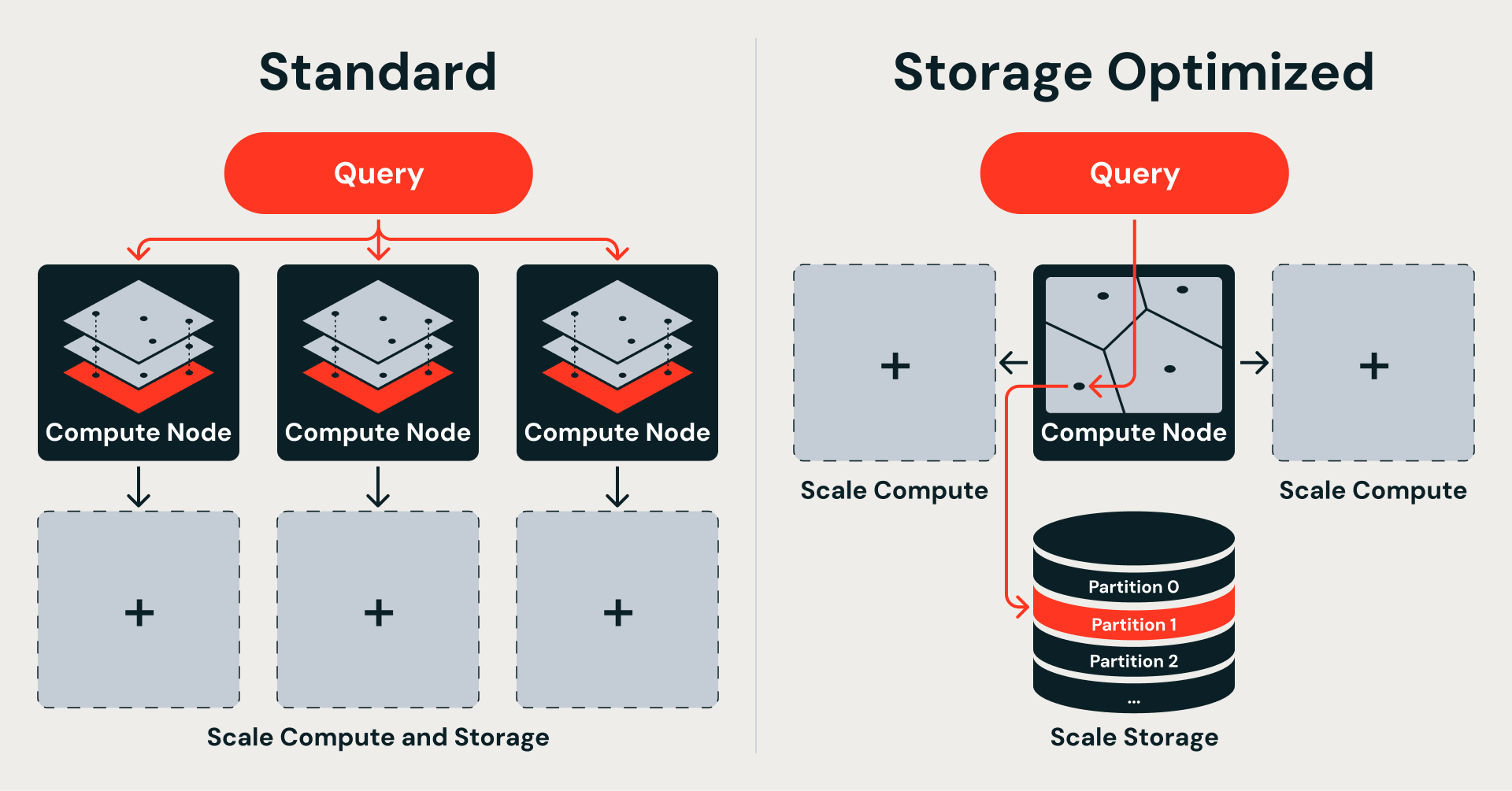
Molti database vettoriali di produzione, inclusa la nostra Standard AI Search, seguono un'architettura shared-nothing mutuata dalla ricerca per parole chiave distribuita. Ogni nodo possiede uno shard casuale del set di dati e gestisce un grafo HNSW (Hierarchical Navigable Small World) indipendente in memoria su vettori a precisione piena. L'HNSW offre un'eccellente qualità di ricerca, ma il grafo stesso deve risiedere interamente in memoria, rendendolo uno dei componenti più costosi da scalare. Questo design offre una bassa latenza e supporta aggiornamenti transazionali. Funziona bene fino a centinaia di milioni di vettori.
A miliardi, crolla.
Il problema principale è l'accoppiamento. L'indice, i dati grezzi e il compute che li servono sono tutti legati allo stesso nodo. Scalare significa replicare tutto: più vettori richiedono più memoria, il che richiede più nodi, ognuno dei quali contiene una copia completa dell'indice e dei dati del proprio shard. Non c'è modo di scalare lo storage indipendentemente dalle compute.
L'accoppiamento si estende all'ingestione. La creazione dell'indice avviene all'interno del motore di ricerca stesso: le stesse risorse di compute che gestiscono le query si occupano anche della riorganizzazione dei dati, della ricostruzione degli indici e della compattazione. Con carichi di lavoro ad alta intensità di scrittura, la latenza delle query peggiora. Con carichi di lavoro ad alta intensità di query, l'ingestione rallenta drasticamente. Peggio ancora, ogni modifica dei dati (un upsert, una cancellazione, una compattazione) attiva la ricostruzione dei sottoindici, consumando cicli della CPU per la manutenzione anziché per l'elaborazione delle query.
Gli indici residenti in memoria sono costosi
È la permanenza in memoria che rende l'architettura veloce e, al contempo, costosa. Con 768 dimensioni e float a 32 bit, 100 milioni di vettori consumano circa 286 GiB di RAM, solo per i vettori, prima di qualsiasi overhead dell'indice. Un miliardo di vettori richiederebbe terabyte. A differenza dell'archiviazione su disco o a oggetti, dove il costo per gigabyte è trascurabile, la memoria è la risorsa più costosa dello stack. Ogni vettore aggiunto aumenta direttamente il costo della RAM.
Lo sharding casuale aggrava il problema. Poiché i vettori sono distribuiti senza tener conto della loro somiglianza semantica, ogni query deve essere inviata a tutti gli shard per raccogliere i risultati, a prescindere dalla pertinenza di ciascuno di essi. CPU, overhead di rete e latenza di coda aumentano tutti con il numero di shard. Aggiungere vettori significa aggiungere shard e ogni nuovo shard porta con sé il proprio indice residente in memoria.
Disaccoppiato per progettazione
La soluzione non consiste nell'ottimizzare questa architettura, ma nel rompere l'accoppiamento stesso.
La ricerca vettoriale ottimizzata per l'archiviazione parte da un'unica premessa: tutti i dati risiedono nell'archiviazione a oggetti nel cloud e i nodi di query sono stateless. Questo suddivide il sistema lungo due confini (lo storage dal compute, così i nodi di query non possiedono i dati, e l'ingestion dal serving, così la creazione degli indici non compete mai con le query in tempo reale) e dà origine a un'architettura a tre livelli:
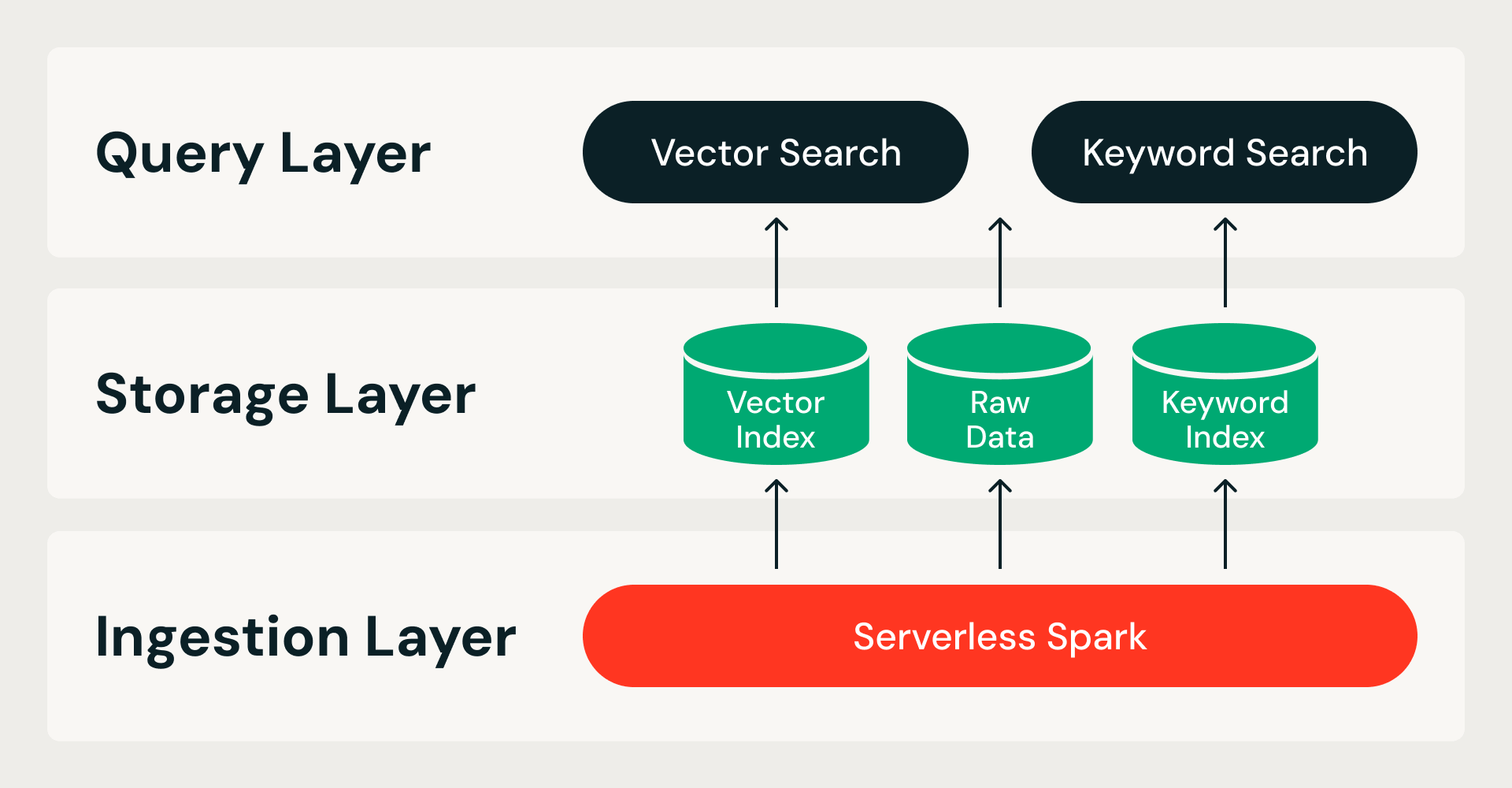
- Livello di ingestione. Una pipeline distribuita su Serverless Spark gestisce l'intera creazione dell'indice, dai dati grezzi all'indice finito. Ogni esecuzione è idempotente e ritentabile.
- Livello di archiviazione. Un formato di archiviazione personalizzato e nativo per il cloud funge da sistema di riferimento. Combina un formato di file colonnare per i dati grezzi e gli indici vettoriali con un formato di indice invertito per la ricerca per parole chiave, il tutto gestito da transazioni ACID con frammenti di dati immutabili.
- Livello query. Due servizi stateless gestiscono le letture. Il servizio di ricerca vettoriale mantiene un indice compresso in memoria e recupera i dati a piena precisione dall'object storage on demand. La ricerca per parole chiave serve indici invertiti per il filtraggio dei metadati e la ricerca per parole chiave. Entrambi i servizi scalano in modo indipendente, quindi le risorse possono essere ottimizzate per adattarsi al carico di lavoro.
Una struttura di indice per l'object storage
Se i dati si trovano nell'object storage, l'indice deve essere partizionabile: il motore di query deve recuperare solo le sezioni pertinenti, non caricare l'intera struttura in memoria.
I grafi HNSW non hanno questa proprietà. Ogni salto di ricerca può avvenire in qualsiasi punto del grafo, quindi l'intera struttura deve risiedere in memoria per gestire una singola query. Non esiste un modo naturale per suddividere un grafo HNSW in frammenti che corrispondano a file di object storage.
L'IVF (Inverted File Index) adotta un approccio diverso: raggruppa i vettori per prossimità intorno a centroidi appresi e cerca solo i cluster più vicini al momento della query. Ogni cluster è mappato direttamente su un frammento di dati nell'object storage, recuperabile in modo indipendente, senza caricare il resto dell'indice.
Questa scelta dell'algoritmo dipende direttamente da dove si trovano i dati. La ricerca vettoriale standard mantiene l'indice completo in memoria per garantire la velocità, il che lega insieme storage e compute. La versione ottimizzata per lo storage sposta i dati nell'object storage per garantire la scalabilità, il che li libera, ma richiede un indice che si scompone in partizioni autonome e recuperabili. L'IVF fornisce esattamente questo:
Indicizzazione distribuita dei vettori su Spark
IVF ci fornisce la struttura di indice corretta per un'archiviazione separata. La sfida di ingegneria consiste nel costruirlo su larga scala. La maggior parte delle librerie di indicizzazione vettoriale, come FAISS, ScaNN e Annoy, presuppone che tutti i dati possano essere contenuti in una singola macchina. Questo funziona con decine di milioni di vettori. Con un miliardo di vettori con embedding a 768 dimensioni, si parla di terabyte di dati grezzi in virgola mobile prima ancora di start a costruire un indice. Nessuna singola macchina è in grado di gestire una simile mole di dati in modo efficiente e, anche se potesse, il tempo di ingestione diventerebbe un collo di bottiglia seriale che aumenta con ogni nuova riga.
Avevamo bisogno di un'indicizzazione che scalasse orizzontalmente. Quindi abbiamo implementato ogni algoritmo di indicizzazione da zero — K-means distribuito, prodotto Quantization e layout dei dati allineato alla partizione — come Job PySpark nativi in esecuzione su cluster Spark serverless effimeri. Nessuna libreria di indicizzazione a macchina singola nel percorso critico. L'aggiunta di più executor riduce linearmente il tempo per i passaggi più costosi.
La pipeline di ingestione
Ogni esecuzione di ingestion viene eseguita come un grafico aciclico diretto di fasi, racchiuso in una transazione ACID.
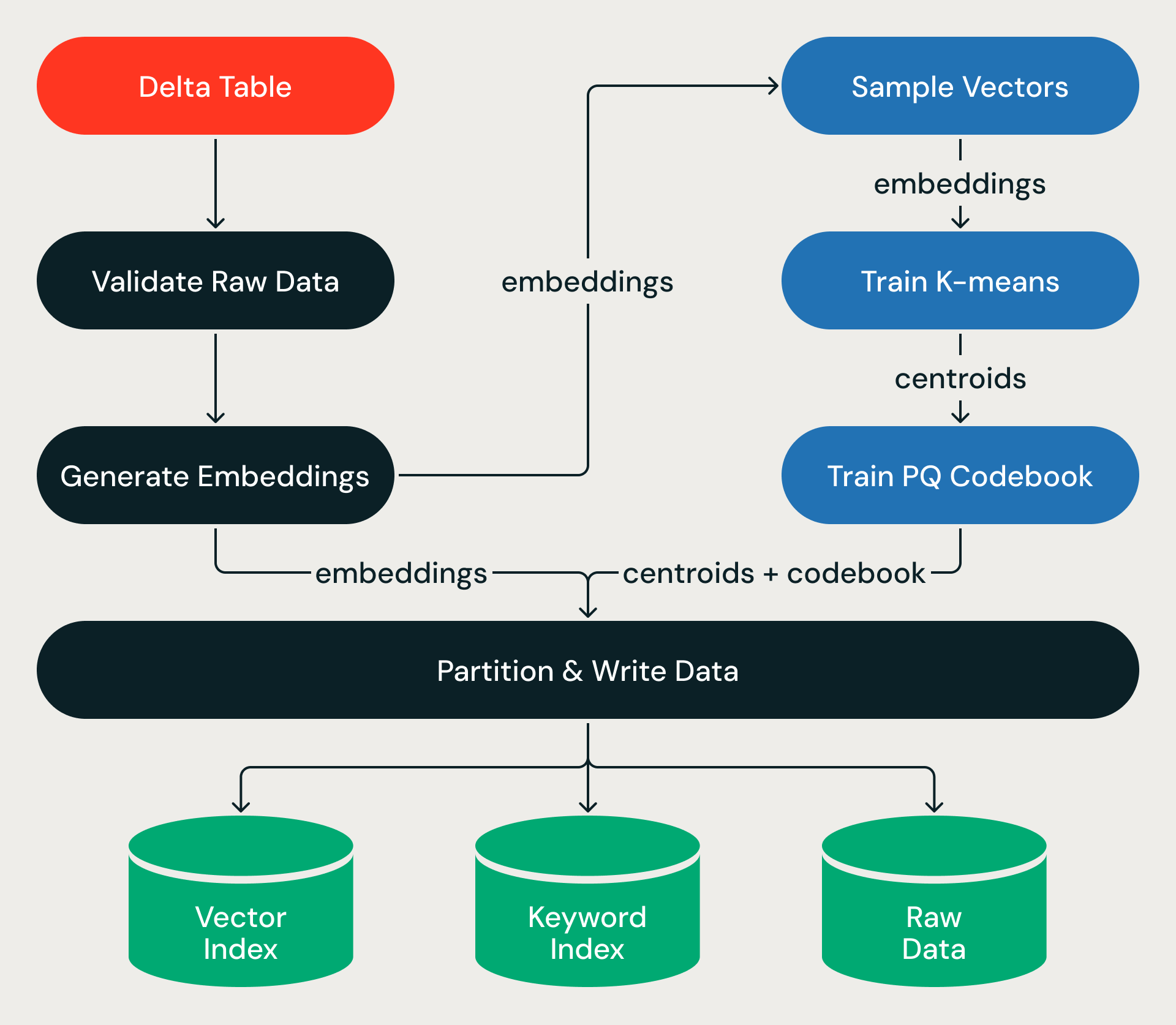
La pipeline parte da una Delta Table di origine. Per gli indici basati su testo di origine (anziché su vettori pre-calcolati), dopo aver convalidato i dati di origine, la pipeline chiama Databricks Model Serving per generare embedding vettoriali per le righe nuove o aggiornate, trasformando miliardi di record di testo in vettori ad alta dimensionalità su larghissima scala.
A partire da questo, la pipeline esegue il training su un piccolo campione, apprendendo la struttura dello spazio vettoriale, quindi applica tale struttura al set di dati completo, assegnando ogni vettore a una partizione, comprimendolo e scrivendo i risultati nell'object storage. L'addestramento è economico; il passaggio sull'intero set di dati, che mescola terabyte di dati tra gli executor, è dove si concentra il tempo di esecuzione effettivo.
K-means: partizionamento su larga scala
Il clustering K-means partiziona lo spazio vettoriale in regioni: le partizioni IVF che consentono alle query di effettuare ricerche in una frazione dei dati invece che nella loro totalità. Per un set di dati da un miliardo di righe, creiamo circa 32.000 partizioni. La domanda è: come si esegue il K-means su questa scala quando le implementazioni standard presuppongono che tutti i dati possano essere contenuti in una singola macchina?
Viene creata da zero su Spark.
La nostra implementazione utilizza un modello ibrido: Spark gestisce lo spostamento distribuito dei dati, mentre JAX, una libreria di calcolo numerico con algebra lineare accelerata dall'hardware, gestisce i calcoli matematici all'interno di ogni executor. Ogni iterazione K-means è una pipeline Spark in tre fasi:
- Assegna — ogni executor calcola le distanze dal suo batch locale di vettori a tutti i centroidi correnti, trovando il cluster più vicino per ogni vettore.
- Shuffle: Spark ripartiziona i dati in base all'ID del centroide, co-localizzando tutti i vettori assegnati allo stesso cluster.
- Aggregazione: ogni esecutore calcola le nuove posizioni dei centroidi a partire dai suoi vettori co-locati.
Il calcolo della distanza è il ciclo critico. JAX lo compila in un'unica operazione matriciale in batch per executor, calcolando l'intera matrice di distanza batch per centroide in una sola volta anziché iterare sui singoli vettori.
L'addestramento viene eseguito su un campione, non sull'intero set di dati: per un miliardo di righe, si tratta di circa 8 milioni di vettori (~0,8% dei dati). Questa non è una scelta arbitraria: il costo di K-means per iterazione è O(n × k × d), dove n è la dimensione del campione, k il numero di cluster e d la dimensione. Impostando sia n che k in modo proporzionale a √N, il costo totale dell'addestramento diventa O(N × d), lineare rispetto alla dimensione del set di dati, indipendentemente dalla Scale.
Questa scelta è anche statisticamente ben fondata: la teoria dei coreset mostra che campioni O(k) sono sufficienti per un clustering k-means di alta qualità su dati ben distribuiti e, poiché k scala con √N, la dimensione del nostro campione è dimostrabilmente adeguata. L'addestramento si completa in una manciata di iterazioni e salva i centroidi tramite checkpoint nell'object storage per le fasi successive della pipeline.
Quantizzazione del prodotto: compressione della memoria 64x
Il K-means ci fornisce partizioni grezze. La Quantizzazione del prodotto (PQ) comprime i vettori in modo da poter effettivamente eseguire ricerche al loro interno su larga scala. L'idea è suddividere ogni vettore a 768 dimensioni in 48 sottovettori da 16 dimensioni ciascuno e sostituire ogni sottovettore con un singolo byte che punta alla voce più vicina in un codebook appreso. Un vettore da 3.072 byte diventa di 48 byte, con un rapporto di compressione di 64x. Per un miliardo di vettori a 768 dimensioni, questo riduce quasi 3 TiB di dati grezzi a circa 45 GiB.
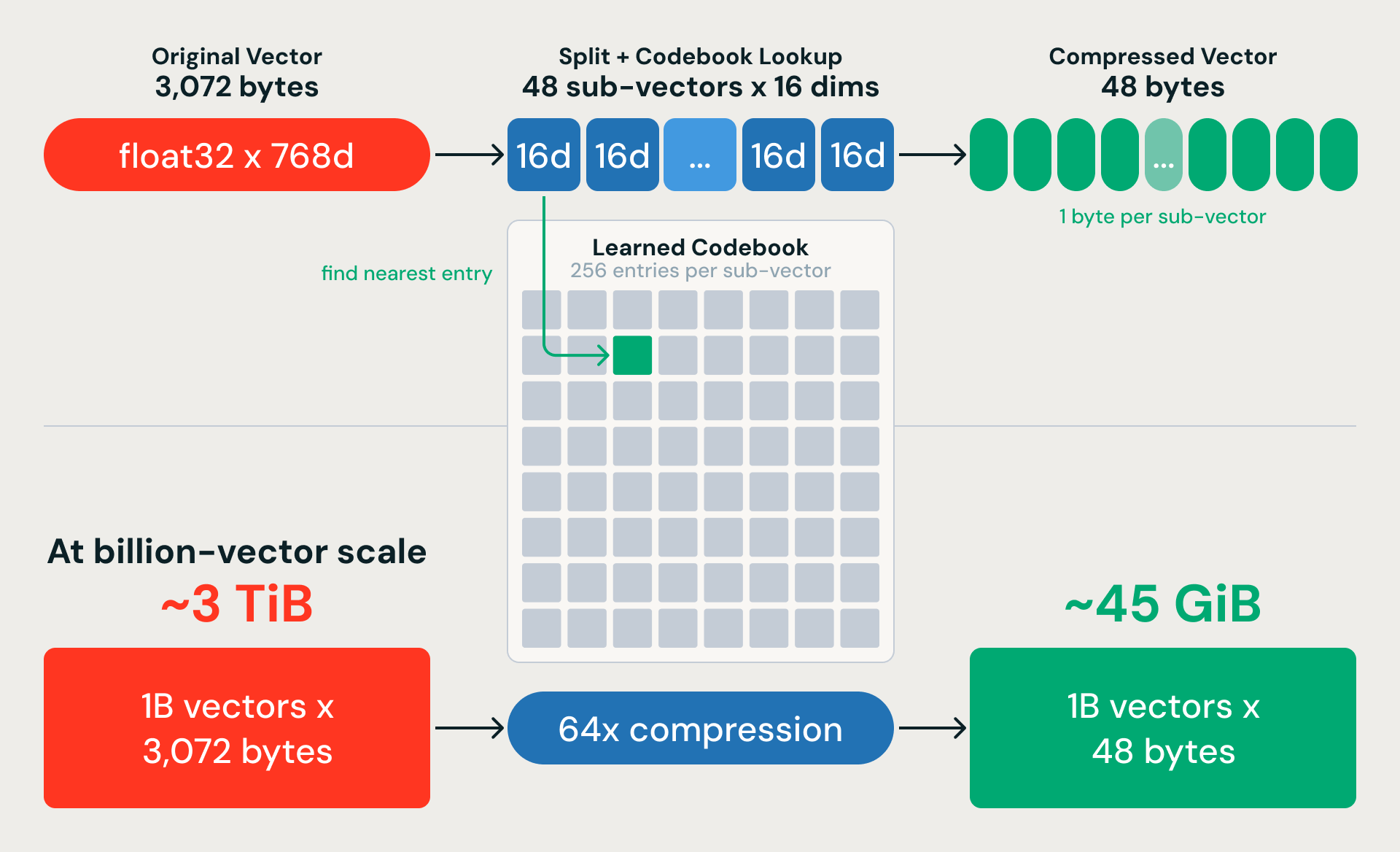
La compressione è lossy, ma una scelta progettuale chiave consente di recuperare gran parte dell'accuratezza: addestriamo il PQ su vettori residui (la differenza tra ogni embedding e il suo centroide K-means più vicino) anziché sugli embedding grezzi. K-means cattura la struttura su larga scala; PQ deve solo codificare la variazione a grana fine all'interno di ogni partizione.
Dall'addestramento all'archiviazione
Con i centroidi e i codebook PQ addestrati sul campione, la pipeline elabora ogni riga, assegnando a ogni vettore un ID di partizione (il suo centroide più vicino) e un codice PQ compresso. Per un set di dati da un miliardo di righe, questa è la fase della pipeline a più alta intensità di dati: un job Spark sull'intero set di dati che calcola distanze e codifiche su ogni executor.
Poi arriva lo shuffle. La pipeline ripartiziona l'intero set di dati in base all'ID di partizione, collocando fisicamente i vettori della stessa partizione IVF negli stessi frammenti di dati sull'object storage. Questa operazione è costosa (terabyte di dati si spostano tra gli executor), ma è ciò che rende veloci le query. Senza co-locazione, l'analisi di una singola partizione IVF disperderebbe le letture su migliaia di file. Con essa, la stessa analisi interessa una manciata di frammenti contigui.
La scrittura produce tre output, ciascuno ottimizzato per un percorso di query diverso:
- Indice vettoriale: codici PQ compressi e metadati delle partizioni, scritti in un formato che il motore di query carica in memoria per una ricerca ANN veloce.
- Indice di parole chiave — file di indice invertito per il filtraggio dei metadati e la ricerca ibrida per parole chiave.
- Dati grezzi — embedding a piena precisione memorizzati in un formato a colonne ottimizzato sia per le scansioni sequenziali che per l'accesso casuale, recuperati on demand durante il re-ranking.
Tutti e tre vengono scritti come frammenti immutabili: una volta scritti, non vengono più modificati. Al termine della scrittura, un manifest di versione pubblica atomicamente il nuovo indice. Questo è il contratto tra ingestion e serving: un insieme di frammenti di dati immutabili e allineati alle partizioni sull'archiviazione a oggetti, pronti per essere letti direttamente dal motore di query.
Ingestione su larga scala
Storage Optimized supporta indici di oltre un miliardo di vettori a 768 dimensioni, un cambiamento radicale rispetto a Standard AI Search, che ha un limite di 320 milioni di vettori.
Poiché l'ingestion viene eseguita su cluster Spark effimeri, completamente disaccoppiati dal serving, la scalabilità è una questione di aggiunta di executor. In pratica, questo si traduce in miglioramenti di ordini di grandezza nelle build degli indici di produzione:

Una volta che l'indice è stato scritto e pubblicato atomicamente sull'object storage, la domanda successiva è: come si gestiscono le query su di esso in modo abbastanza veloce per la produzione?
Un motore di query per l'object storage
La separazione dello storage dal compute risolve il problema dei costi. Ma ne introduce uno nuovo: ogni query ora comporta round trip di rete verso l'object storage. L'indice compresso, abbastanza piccolo da stare in memoria, viene caricato all'avvio, ma gli embedding a precisione completa rimangono nello storage BLOB e vengono recuperati on demand o serviti da una cache del disco locale. Il layer di serving deve essere abbastanza veloce in modo che lo spostamento dei dati off-node non comprometta la latenza delle query.
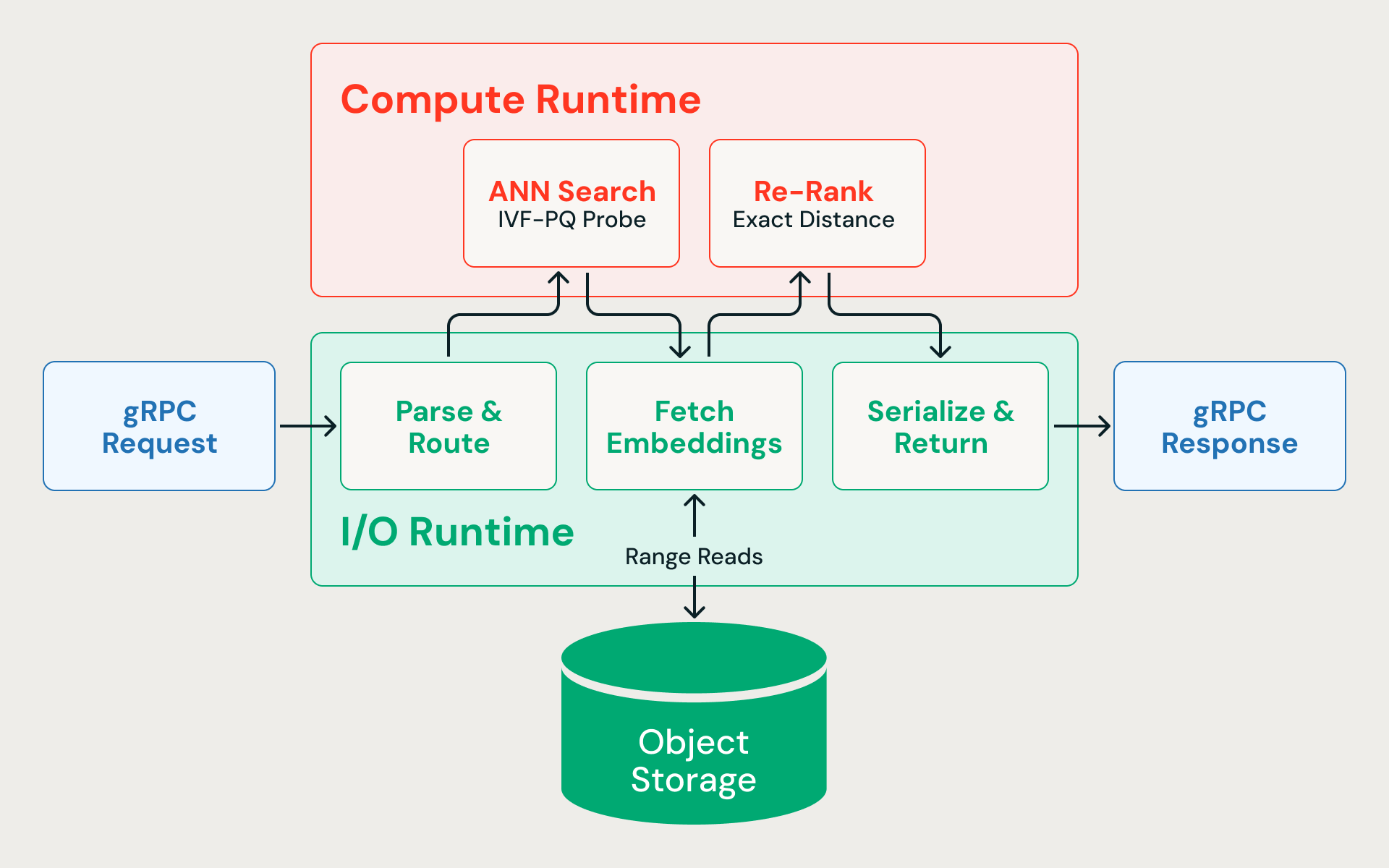
Anatomia di una query
Ecco cosa succede quando una ricerca dei vicini più prossimi raggiunge il motore:
- Analisi e instradamento (I/O). La richiesta gRPC arriva sul runtime di I/O asincrono, viene deserializzata e instradata all'indice corretto.
- Ricerca ANN (CPU). Il vettore della query viene confrontato con i centroidi dei cluster IVF per identificare le partizioni più pertinenti. Vengono analizzate solo quelle partizioni, scansionando i vettori compressi per calcolare le distanze approssimative. La ricerca recupera deliberatamente un numero eccessivo di candidati (ad esempio, 400 quando il chiamante ne richiede 10) perché le distanze quantizzate sono approssimative e una rete iniziale più ampia migliora la recall finale dopo il re-ranking.
- Recupero dei vettori a precisione completa (I/O). Le letture simultanee di intervalli di byte recuperano gli embedding grezzi per ogni candidato dallo spazio di archiviazione cloud. Poiché la pipeline di ingestione co-loca le righe della stessa partizione IVF nello stesso frammento di dati, queste letture sono soggette a potatura per partizione (partition-pruned), interessando un numero ridotto di file invece di accedere in modo casuale all'intero set di dati. Questo passaggio domina la latenza end-to-end.
- Riordino (CPU). Agli embedding a piena precisione viene assegnato un punteggio tramite il calcolo esatto della distanza, recuperando l'accuratezza persa a causa della compressione.
- Serializzare e restituire (I/O). I risultati finali top-N vengono serializzati con i metadati associati e restituiti al chiamante.
Ogni query si alterna tra I/O asincrono e calcolo legato alla CPU. Se i calcoli della distanza bloccano il runtime asincrono, le letture in sospeso dallo storage si accumulano e la latenza aumenta vertiginosamente.
Due runtime
La soluzione consiste nel non lasciarli mai competere per gli stessi thread. Il motore di query, scritto in Rust per una latenza prevedibile senza pause del GC, suddivide l'esecuzione su due pool di thread dedicati: uno per l'I/O asincrono e uno per i calcoli vettoriali legati alla CPU. Nessuno dei due carichi di lavoro può andare a discapito dell'altro.
Il runtime I/O viene eseguito sull'executor asincrono Tokio e gestisce il parsing delle richieste gRPC, le letture di intervalli dal blob storage, la comunicazione tra servizi e la serializzazione delle risposte. Poiché le letture dallo storage costituiscono il collo di bottiglia della latenza, questo runtime deve mantenere centinaia di richieste simultanee in corso senza bloccarsi.
Il runtime di calcolo esegue i calcoli della distanza vettoriale, l'analisi delle partizioni e il re-ranking su un proprio pool di thread. Un sottoinsieme di core della CPU è esplicitamente riservato per il runtime di I/O; al compute non è mai consentito di consumare l'intera macchina.
Read Coalescing
Oltre all'isolamento dei thread, il percorso di I/O stesso ha richiesto un'ottimizzazione. La profilazione iniziale ha rivelato che il motore inviava all'object storage molte piccole letture di intervalli a singolo vettore. Ogni chiamata comporta un overhead per richiesta e una variabilità della latenza (con code lunghe che raggiungono centinaia di millisecondi), quindi molte richieste di piccole dimensioni si traducevano in un'elevata varianza della latenza per query.
La soluzione è stata il read coalescing: invece di emettere una lettura di intervallo per vettore, il livello di storage ordina le richieste di intervalli di byte in sospeso per offset del file e unisce quelle che rientrano in una finestra di dimensioni di blocco configurabile in un'unica lettura. Richieste meno numerose e più grandi significano un minore overhead per chiamata, ma ogni lettura unita recupera anche byte di cui la query non ha bisogno, causando una read amplification. Il compromesso ha richiesto una messa a punto empirica.
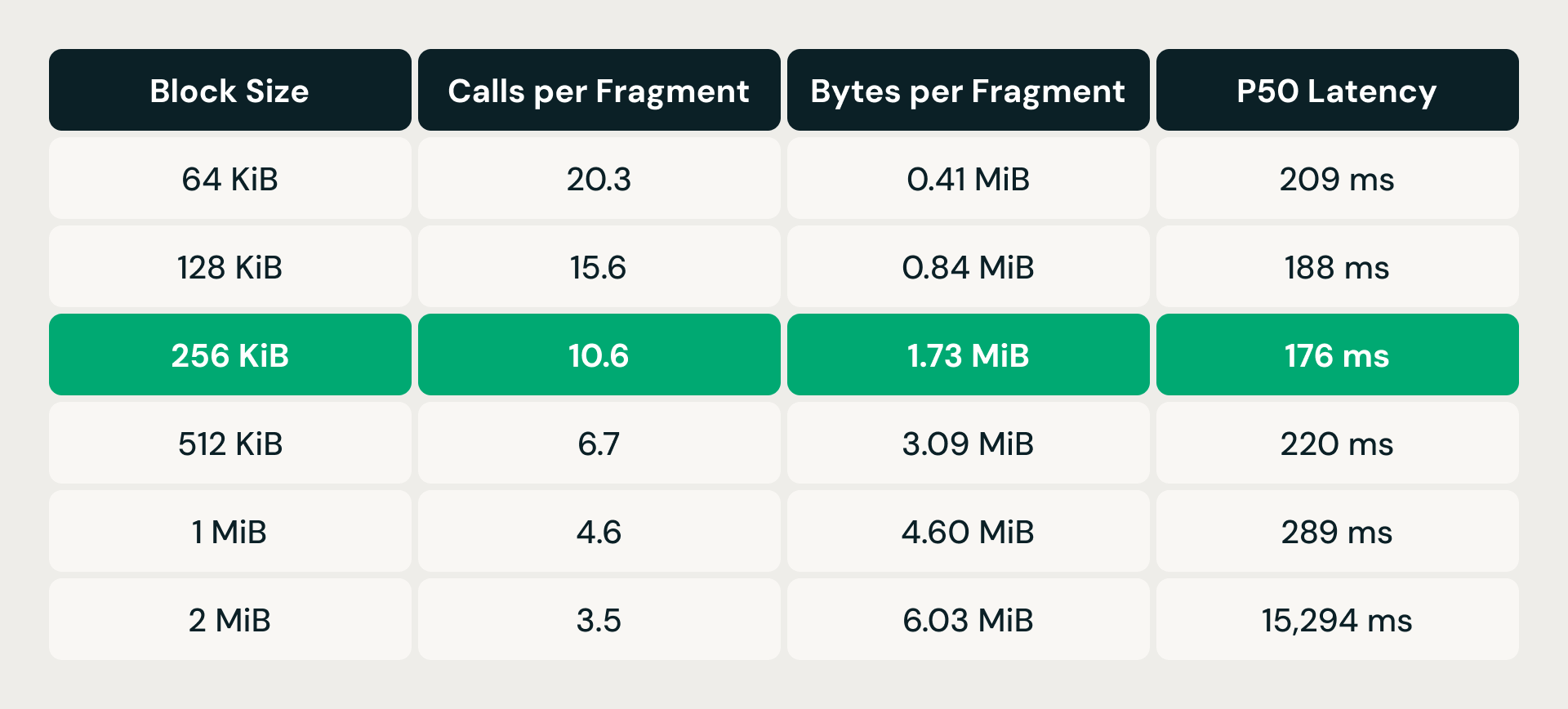
A 64 KiB, ogni frammento di dati richiedeva oltre 20 chiamate di storage ma recuperava meno di mezzo megabyte: l'overhead per richiesta era predominante. Raddoppiando la dimensione del blocco, il numero di chiamate si è ridotto costantemente e la latenza è migliorata fino a 256 KiB. Ma superato quel punto, l'amplificazione della lettura ha preso il sopravvento: a 512 KiB, la latenza è risalita al di sopra della baseline di 64 KiB nonostante un numero di chiamate molto inferiore. A 2 MiB è esplosa a oltre 15 secondi. Il punto ottimale di 256 KiB ha quasi dimezzato le chiamate mantenendo l'amplificazione della lettura sotto i 2 MiB per frammento, offrendo la latenza p50 più bassa di qualsiasi configurazione testata.
Mettendo tutto insieme
Tutto in questa architettura scambia la latenza delle query con la scalabilità e il costo. A 768 dimensioni e con risultati top-10, la recall, ovvero la frazione dei vicini più prossimi reali restituiti, rimane sopra il 94% a 10 milioni di vettori, sopra il 91% a 100 milioni e si mantiene al 90% anche a un miliardo: la fase di re-ranking, che recupera i vettori a piena precisione dall'object storage e ricalcola le distanze esatte, recupera l'accuratezza che i codici compressi da soli perderebbero su larga scala. Quel round-trip di re-ranking è anche ciò che domina il tempo di query: le query restituiscono risultati in circa 300 millisecondi con 10 milioni di vettori e circa 500 millisecondi con un miliardo, rispetto ai 20-50 millisecondi degli endpoint Standard, che mantengono tutto in memoria.
Cosa si ottiene in cambio di questi millisecondi extra: le compilazioni degli indici su scala di miliardi di vettori si completano in meno di 8 ore, 20 volte più velocemente dello Standard su set di dati di grandi dimensioni. La prodotto Quantization comprime l'impronta di memoria di più di un ordine di grandezza, l'ingestion viene eseguita su cluster Spark effimeri che rilasciano le risorse dopo ogni build e la separazione dello storage dall'elaborazione delle query significa che nessuna delle due parti è sovradimensionata. Il risultato è un costo fino a 7 volte inferiore per i clienti sulla stessa scala.
Per molti carichi di lavoro, come ricerca semantica, pipeline di raccomandazione e generazione aumentata da recupero, questo compromesso favorisce chiaramente la scalabilità e il costo. Le fasi post-recupero (ranking, filtraggio, generazione LLM) spesso dominano il tempo end-to-end, rendendo invisibile all'utente finale la differenza tra 40 e 400 millisecondi. Per il serving sensibile alla latenza, dove ogni millisecondo conta, Standard AI Search rimane lo strumento migliore. Le due opzioni sono complementari: strumenti diversi per carichi di lavoro diversi.
Cosa abbiamo imparato
Costruire un sistema di ricerca vettoriale da zero, invece di ottimizzare quello che avevamo, ci ha costretti a fare una serie di scommesse che si rivelano vincenti solo se combinate.
La separazione tra storage e compute funziona solo se il motore di query è abbastanza veloce. Lo spostamento dei dati fuori dal nodo consente di risparmiare, ma aggiunge operazioni di I/O a ogni query, che si tratti di round trip di rete verso l'archiviazione a oggetti o di letture da una cache su disco locale. Il motore Rust a doppio runtime esiste appositamente per assorbire tale latenza: l'I/O asincrono mantiene centinaia di letture in corso, mentre i thread della CPU gestiscono il calcolo della distanza senza bloccarsi. Senza quel motore, l'architettura fornirebbe un'archiviazione economica e query lente: un compromesso non allettante.
L'indicizzazione distribuita funziona solo se il formato dell'indice la supporta. Costruire K-means e PQ su Spark ci offre una scalabilità orizzontale per l'ingestion, ma l'output deve essere qualcosa che il motore di query possa servire direttamente dall'object storage senza una fase di ricostruzione. Il formato di storage personalizzato (frammenti di dati immutabili, manifesti delle transazioni separati, semantica ACID sul cloud storage) chiude il cerchio. L'ingestione scrive direttamente nel formato che il motore di query legge.
La compressione è la leva economica. La quantizzazione del prodotto non riduce solo il costo della memoria. Cambia la sostenibilità dell'architettura. Senza questo livello di compressione, l'archiviazione in memoria di codici quantizzati per un miliardo di vettori richiederebbe comunque terabyte di RAM e il vantaggio in termini di costi rispetto alla Standard AI Search svanirebbe. La PQ rende possibile mantenere in memoria la fase di ricerca ANN, spostando tutto il resto sull'object storage.
Queste non sono ottimizzazioni indipendenti. Se ne rimuovessimo una qualsiasi, il sistema diventerebbe troppo costoso, troppo lento da costruire o troppo lento da servire per essere pratico.
Conclusione
I problemi difficili che ci attendono derivano direttamente da questi compromessi. Migliorare ulteriormente le prestazioni delle query (risposte più veloci, throughput più elevato, migliore concorrenza) attraverso un caching più intelligente, un'archiviazione a più livelli e rappresentazioni in memoria più dense. Rendere gli aggiornamenti quasi in tempo reale su una scala di miliardi di elementi. Andare oltre la distanza vettoriale grezza come segnale di classificazione finale, verso una classificazione appresa e multi-stadio che combina somiglianza vettoriale, pertinenza delle parole chiave e contesto di dominio per ottenere risultati che non siano solo i più vicini, ma i più utili.
Crediamo che la prossima generazione di prodotti di IA sarà costruita su un'infrastruttura non ancora inventata e che gli ingegneri che la realizzeranno daranno forma a ciò che l'IA può fare. Se vuoi essere uno di loro, vieni a costruire con noi!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.