Il modo più veloce per federare dati SAP HANA in tempo reale in Databricks usando Spark JDBC
Il recente annuncio di SAP di una partnership strategica con Databricks ha generato un notevole entusiasmo tra i clienti SAP. Databricks, gli esperti di dati e AI, presenta un'opportunità interessante per sfruttare le capacità di analisi e ML/AI integrando SAP HANA con Databricks. Dato l'immenso interesse per questa collaborazione, siamo entusiasti di intraprendere una serie di blog approfonditi.
In molti scenari cliente, un sistema SAP HANA funge da entità primaria per le fondamenta dei dati provenienti da vari sistemi sorgente, tra cui SAP CRM, SAP ERP/ECC, SAP BW. Ora, sorge l'entusiasmante possibilità di integrare senza problemi questo robusto sistema sidecar analitico SAP HANA con Databricks, migliorando ulteriormente le capacità di dati dell'organizzazione. Collegando SAP HANA (con licenza HANA Enterprise Edition) con Databricks, le aziende possono sfruttare le capacità avanzate di analisi e machine learning (come MLflow, AutoML, MLOps) di Databricks sfruttando al contempo i dati ricchi e consolidati archiviati all'interno di SAP HANA. Questa integrazione apre un mondo di possibilità per le organizzazioni per sbloccare preziose informazioni e guidare decisioni basate sui dati in tutti i loro sistemi SAP.
Sono disponibili diversi approcci per federare tabelle SAP HANA, viste SQL e viste di calcolo in Databricks. Tuttavia, il modo più rapido è utilizzare SparkJDBC. Il vantaggio più significativo è che SparkJDBC supporta connessioni JDBC parallele dai nodi worker Spark all'endpoint HANA remoto.
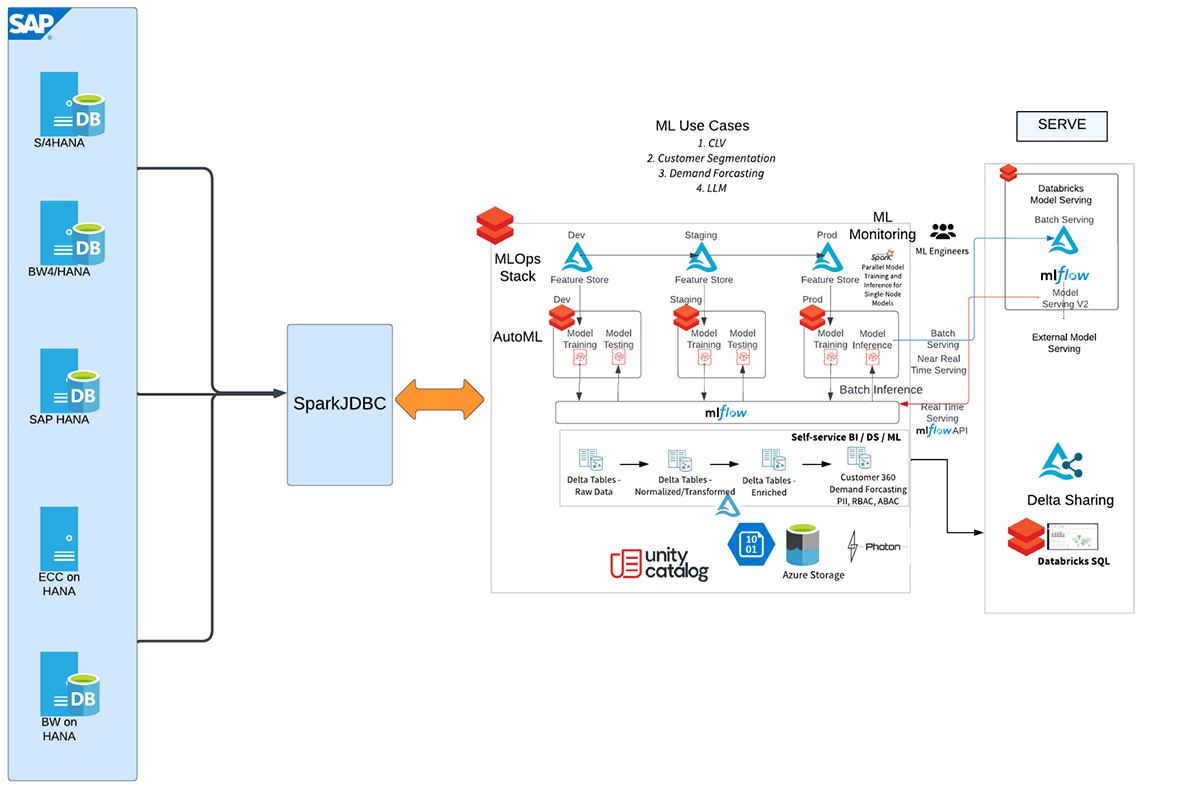
Iniziamo con l'integrazione SAP HANA e Databricks
Innanzitutto, SAP HANA 2.0 è installato nel cloud Azure e abbiamo testato l'integrazione con Databricks.
Informazioni SAP HANA installate in Azure:
| versione | 2.00.061.00.1644229038 |
| branch | fa/hana2sp06 |
| Sistema Operativo | SUSE Linux Enterprise Server 15 SP1 |
Ecco il flusso di lavoro di alto livello che illustra le diverse fasi di questa integrazione.
Si prega di consultare il notebook allegato per istruzioni più dettagliate sull'estrazione di dati dalle viste di calcolo e dalle tabelle di SAP HANA in Databricks utilizzando SparkJDBC.

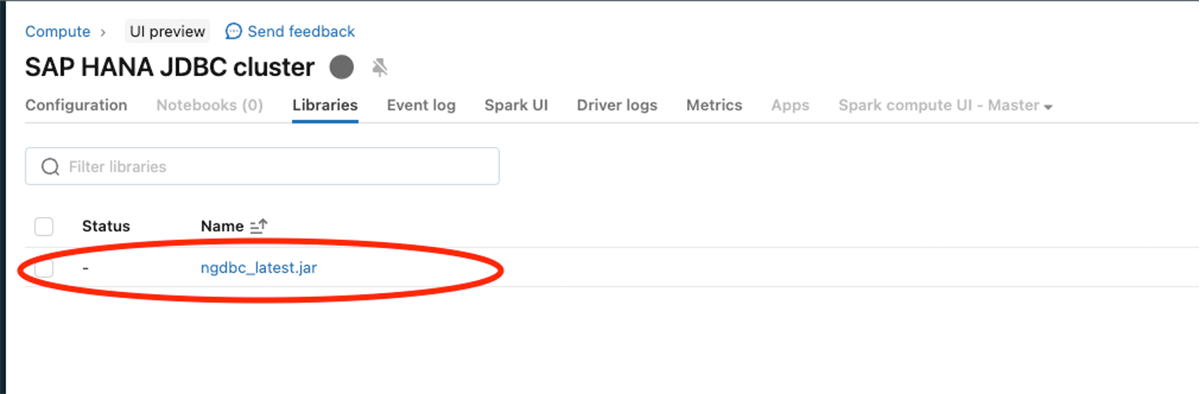
Configurare il jar JDBC di SAP HANA (ngdbc.jar) come mostrato nell'immagine seguente
Una volta eseguiti i passaggi precedenti, eseguire una lettura spark utilizzando il server SAP HANA e la porta JDBC.
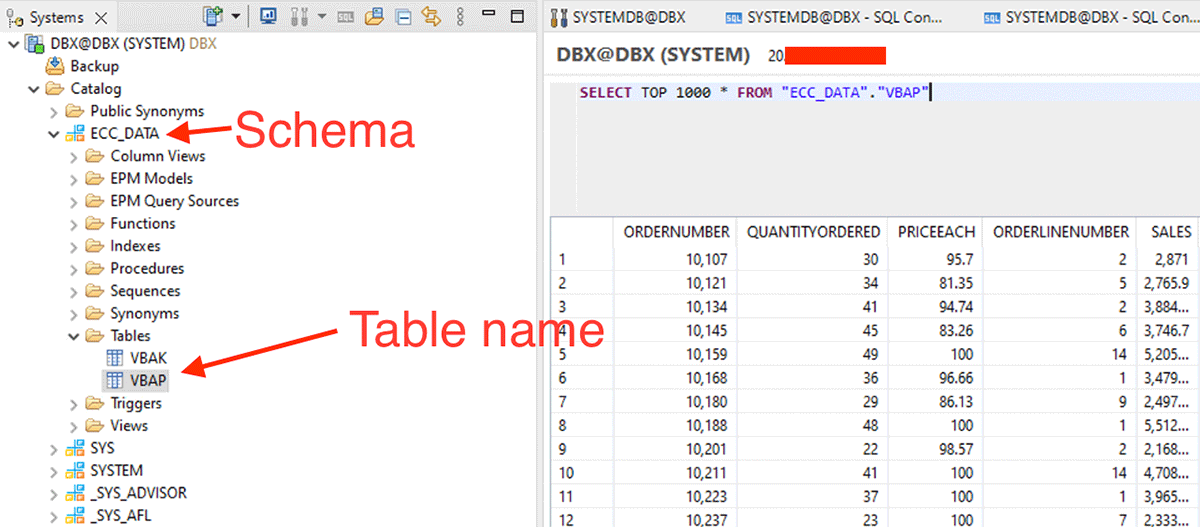
Iniziare a creare i dataframe utilizzando quanto mostrato di seguito con schema e nome tabella.
Inoltre, possiamo eseguire un filtro pushdown passando istruzioni SQL nell'opzione dbtable.
Per ottenere dati dalla Vista di Calcolo, dobbiamo fare quanto segue:
Ad esempio, questa vista di calcolo XS-classic è creata nello schema interno "_SYS_BIC".
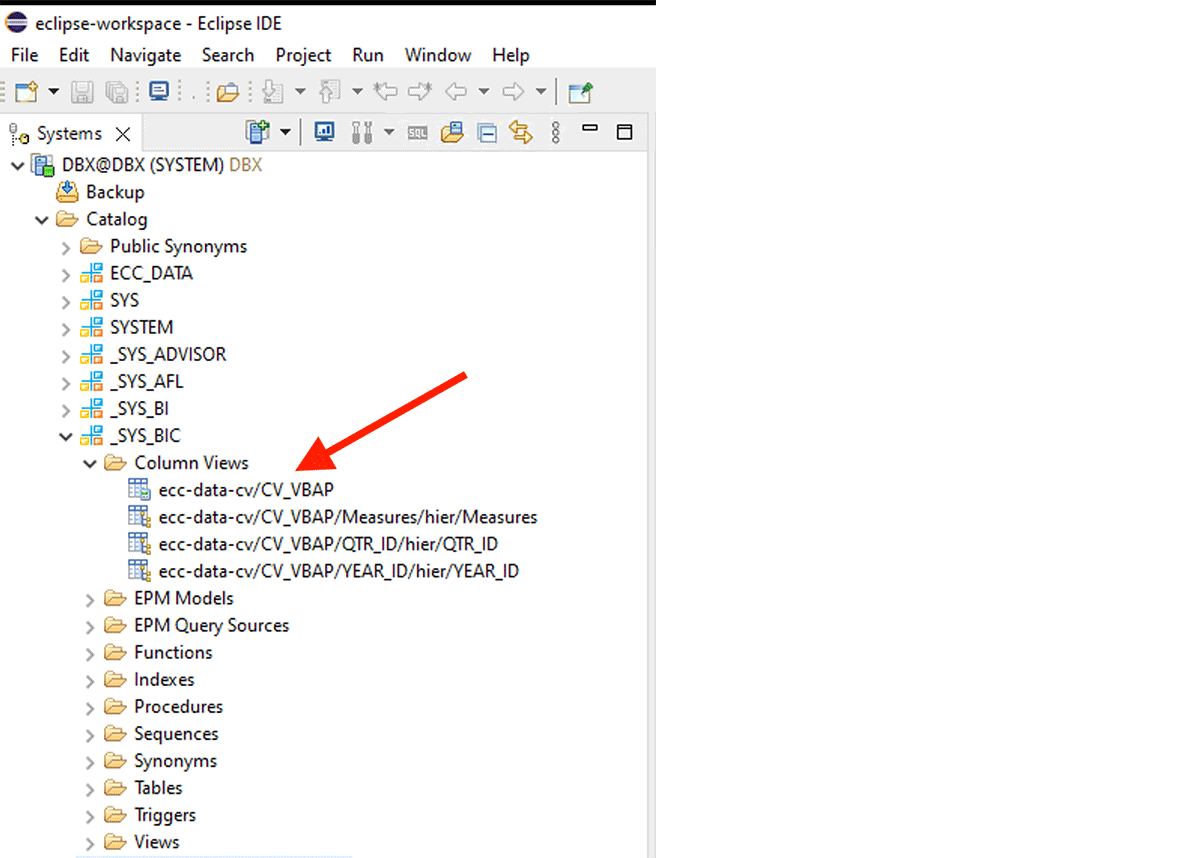
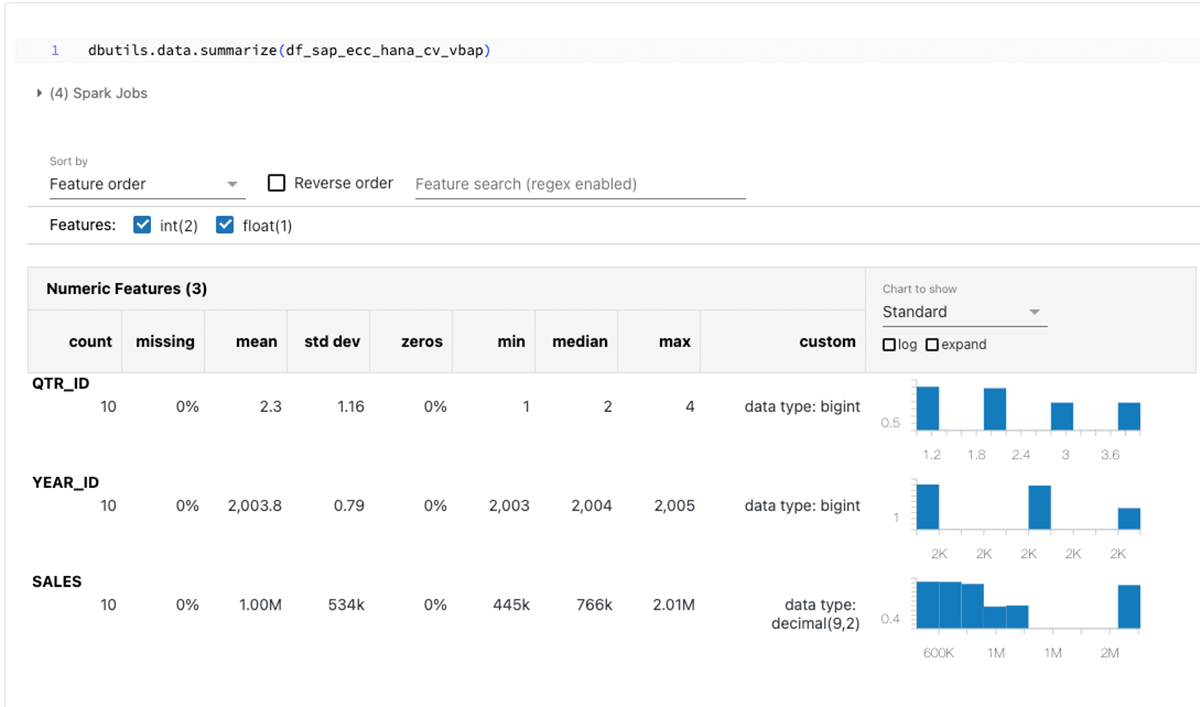
Questo snippet di codice crea un dataframe PySpark chiamato "df_sap_ecc_hana_cv_vbap" e lo popola da una Vista di Calcolo dal sistema SAP HANA (in questo caso, CV_VBAP).
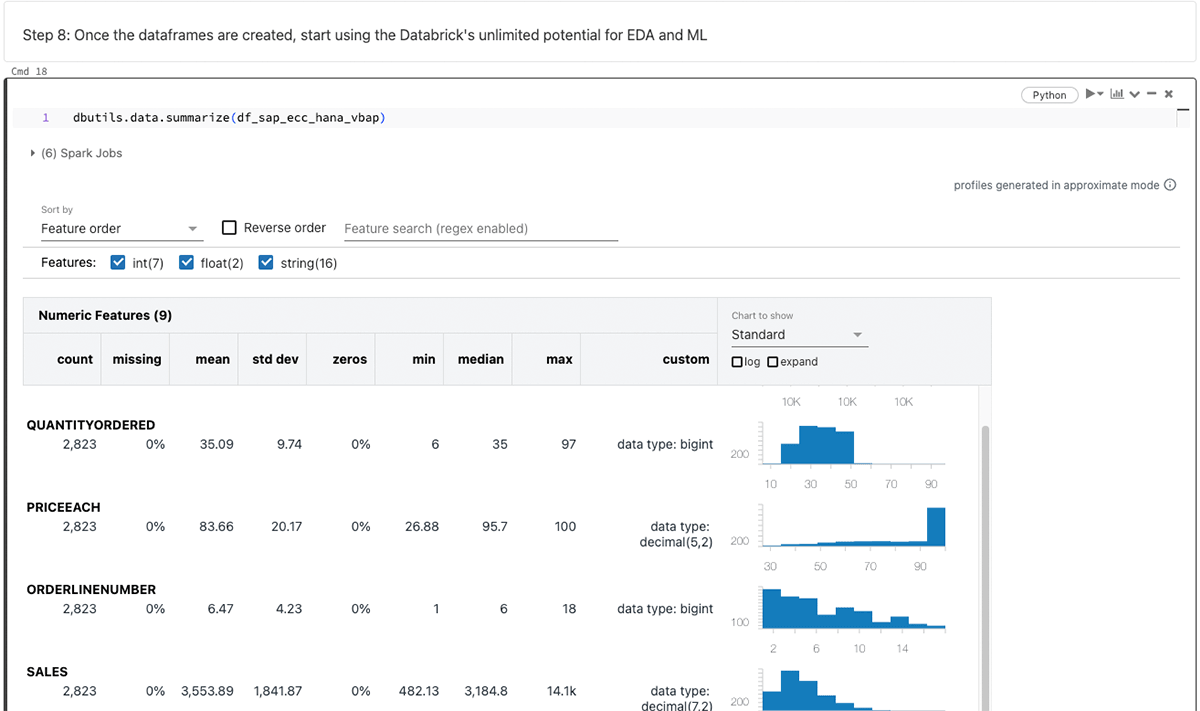
Dopo aver generato il dataframe PySpark, sfrutta le infinite capacità di Databricks per l'analisi esplorativa dei dati (EDA) e il machine learning/intelligenza artificiale (ML/AI).
Riassumendo i dataframe sopra:
L'obiettivo di questo blog ruota attorno a SparkJDBC per SAP HANA, ma vale la pena notare che metodi alternativi come FedML, hdbcli e hana_ml sono disponibili per scopi simili.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.