Come trasformare i flussi di lavoro di attivazione dei documenti con Genie e Agent Bricks
Trasforma i documenti in preziose informazioni aziendali con Databricks
di Elena Tesser
-I flussi manuali di estrazione di documenti in settori come media, comunicazioni e gaming rallentano i team, causando perdite di entrate e aumentando il rischio di conformità.
-Le aziende possono unire AI/BI Genie, Agent Bricks e Unity Catalog per stabilire un rigoroso flusso di lavoro multi-agente in grado di convertire documenti chiave in marketing, legale, finanza, risorse umane e altro ancora in dati governati, ricercabili e attuabili.
-Passando dall'estrazione all'orchestrazione multi-agente e alla scrittura di sistema, le organizzazioni possono fluire senza problemi dall'elaborazione, alla lettura, all'attivazione dei loro documenti
Esiste un divario nell'intelligenza documentale nelle aziende di oggi
Le organizzazioni si basano su montagne di documenti, da contratti, ad accordi di lavoro, accordi sui talenti e NDA, a ordini di inserzione pubblicitaria e contratti quadro di servizi e altro ancora. Ogni documento contiene preziose informazioni su potenziali ricavi, rischi e obblighi, tuttavia il modo in cui la maggior parte delle organizzazioni li gestisce non è cambiato molto negli ultimi decenni.
Eppure oggi, anche se le organizzazioni integrano sempre più l'IA per aiutarle a muoversi più velocemente, molti team si affidano ancora agli esseri umani per leggere PDF, copiare campi in fogli di calcolo e reinserire dati nei sistemi ERP, CRM e di pianificazione. Tutto ciò crea rischi significativi; i flussi di lavoro di elaborazione manuale portano a ritardi e potenziali perdite di fatturato dovute a errori umani, mentre la mancanza di governance impedisce ai team di verificare in modo affidabile i propri report.
Strumenti puntuali e architetture legacy non sono all'altezza
I leader comprendono che l'automazione dell'IA può aiutarli a superare queste sfide. Tuttavia, molti sono restii a integrare completamente l'IA nei loro flussi di lavoro, poiché i primi investimenti come motori OCR, sistemi di gestione del ciclo di vita dei contratti e soluzioni puntuali specifiche per dominio hanno spesso sottoperformato. Anche quando le organizzazioni sperimentano con GenAI, molti team finanziari, legali e operativi riportano ancora un valore scarso realizzato dagli investimenti in IA. Il problema, tuttavia, non è l'automazione dell'IA in sé, ma le basi dati frammentate e incomplete su cui poggiano questi primi strumenti.
Senza una base dati unificata e ben governata, mancano di contesto settoriale e organizzativo, sono isolati dai sistemi aziendali chiave, sono costruiti solo per la lettura, non per l'attivazione. Peggio ancora, quando si tenta di costruire un flusso di lavoro di agenti al di sopra, si ottiene un'esperienza disgiunta, incoerente e impossibile da scalare.
Adottare un approccio di piattaforma per l'attivazione dei documenti
Il momento cruciale per l'intelligenza documentale si verifica quando un'azienda passa dalla gestione dei flussi di lavoro con soluzioni puntuali alla loro costruzione su una base dati unificata e governata. Questo cambiamento apre la porta a un'esperienza multi-agente veramente unificata e scalabile che consente agli utenti tecnici e non tecnici di interrogare i propri dati aziendali strutturati e non strutturati, e quindi di intraprendere azioni appropriate su tali dati.
Tre funzionalità principali di Databricks lo rendono possibile:
- AI/BI Genie: un'esperienza BI nativa per l'IA che consente agli utenti aziendali di porre domande in linguaggio naturale su tabelle Delta governate, senza scrivere SQL.
- Agent Bricks: blocchi costitutivi riutilizzabili per agenti di alta qualità e pronti per la produzione, inclusi estrazione di informazioni, assistenti di conoscenza e orchestrazione, che sono costruiti e ottimizzati sui tuoi dati piuttosto che come prototipi unici.
- Unity Catalog: governance unificata, lineage e controllo degli accessi granulare su dati, agenti AI e persino server MCP, dal documento sorgente alla risposta dell'agente e al write-back del sistema.
Il flusso di lavoro di attivazione dei documenti multi-agente
Su questa base, implementiamo un flusso di lavoro di attivazione dei documenti fasi che i team tecnici e non tecnici possono adottare e replicare passo dopo passo.
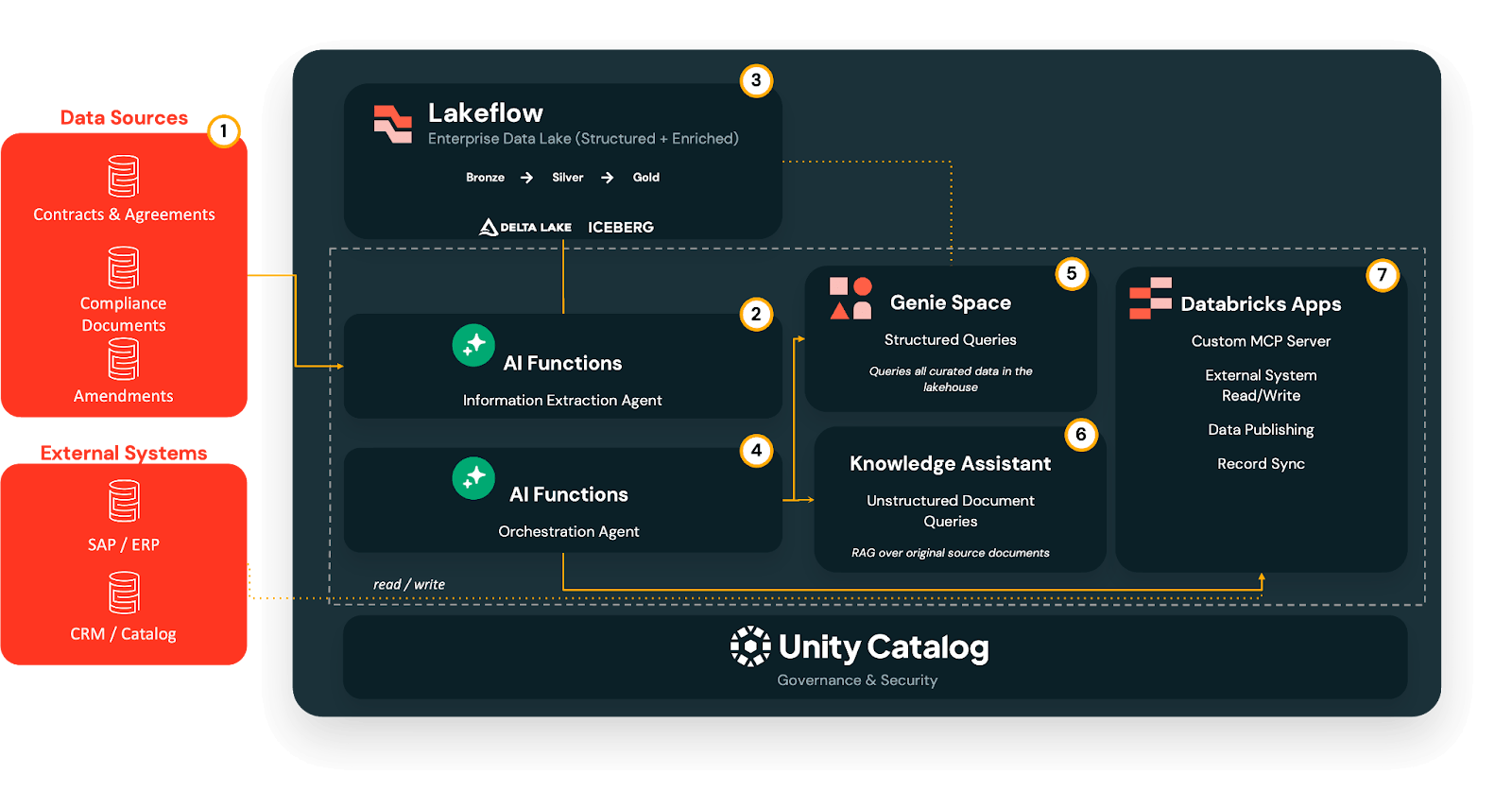
Fase 1 - Estrai: da PDF a tabelle Delta governate
Nella Fase 1, l'Agente di Estrazione Informazioni utilizza l'estrazione basata su LLM per convertire documenti non strutturati (PDF, DOC/DOCX, PPT/PPTX, immagini) in campi strutturati, senza costruire pipeline OCR personalizzate o parser unici.
Gli output grezzi atterrano in una pipeline medaglione Lakeflow:
- Bronze: campi estratti grezzi così come sono.
- Silver: valori puliti e standardizzati, con ID canonici risolti e codici normalizzati.
- Gold: tabelle pronte per il business ottimizzate per l'interrogazione e l'analisi.
Questa estrazione viene eseguita al momento dell'ingestione, non al momento dell'interrogazione, quindi tutto ciò che segue si basa su una base dati coerente e governata.
Fase 2: Interroga - Analisi self-service con Genie
Una volta che i termini chiave sono strutturati nelle tabelle Delta, l'AI/BI Genie offre agli utenti aziendali un'interfaccia self-service per porre domande in linguaggio naturale.
Punta Genie alle tabelle del livello gold e gli utenti possono porre domande come “Quali contratti scadono il prossimo trimestre in EMEA?” o “Quali contratti di pubblicazione hanno livelli di condivisione dei ricavi che si attivano al di sopra di una determinata soglia di spesa?” Genie traduce quindi queste query in SQL, applica le autorizzazioni di Unity Catalog e restituisce risultati tabulari o visivi, eliminando il collo di bottiglia dell'analista pur mantenendo l'accesso ai dati governato.
Fase 3: Comprendi - Risposte a livello di clausola con Knowledge Assistant
Alcune domande non possono essere risolte solo dagli aggregati. I team legali, di diritti e di conformità spesso hanno bisogno di sapere esattamente cosa dice una clausola specifica.
Qui, un Knowledge Assistant, un agente conversazionale basato su RAG, viene eseguito direttamente sui documenti sorgente originali archiviati nei volumi di Unity Catalog.
Può rispondere a domande come: “Quali sono le restrizioni di sublicenza nell'accordo Warner?” o “Abbiamo diritti SVOD per lo Show X in Francia nel 2027, e sono esclusivi?” L'assistente restituisce quindi snippet a livello di clausola con citazioni ai PDF originali, mantenendo la piena tracciabilità.
Fase 4: Orchestra - una porta d'accesso unica con un supervisore multi-agente
Man mano che aggiungi più agenti, non vuoi che gli utenti decidano quale strumento aprire per ogni domanda.
Il Multi-Agent Supervisor agisce come un unico punto di ingresso conversazionale che analizza ogni query e la instrada allo specialista giusto:
- Domande strutturate → Spazi Genie
- Domande a livello di clausola → Knowledge Assistant
- Azioni di sistema → Connettori basati su MCP e flussi downstream
Gli utenti pongono semplicemente la loro domanda e il supervisore seleziona il percorso corretto, combinando contesto non strutturato e strutturato quando necessario.
Fase 5: Agisci - dall'intuizione agli aggiornamenti di sistema con MCP
Infine, i server MCP trasformano la comprensione dei documenti in azioni incapsulando API di sistemi esterni (ERP, HRIS, CRM, piattaforme pubblicitarie, sistemi di diritti, Slack) come strumenti che il supervisore può chiamare.
Ciò consente di intraprendere il corso d'azione migliore in base ai dati estratti e al contesto organizzativo. Gli esempi includono::
- Inserire dati di diritti convalidati in SAP e sincronizzarli con un catalogo di titoli o CRM.
- Aggiornare le autorizzazioni e i pacchetti nei sistemi di fatturazione e assistenza clienti in base ai termini estratti.
- Attivare flussi di lavoro negli strumenti di ticketing o di gestione dei progetti quando vengono rilevate scadenze normative o obblighi di correzione.
Infine, poiché tutto ciò è governato da Unity Catalog, ogni campo rimane tracciabile fino al documento da cui proviene, con lineage e audit trail tra agenti e write-back del sistema.
Casi d'uso specifici del settore nei media, agenzie, ad tech e telecomunicazioni
Questo flusso di lavoro di attivazione dei documenti può essere applicato in una vasta gamma di settori e casi d'uso. Tuttavia, può essere particolarmente efficace per settori come le Telecomunicazioni e i Media e l'Intrattenimento, dove i clienti si basano su enormi quantità di dati strutturati e non strutturati in rapida evoluzione all'interno dei loro documenti. Indipendentemente dalle esigenze aziendali o dal profilo utente, esiste un'applicazione per trasformare documenti pertinenti in insight puliti e governati e nell'azione successiva appropriata.
- Editori e studi media
- Tracciare contratti di diritti e licenze, rispondere a domande come “Abbiamo i diritti di streaming per il Titolo X in Germania fino al 2027?” e segnalare proattivamente i contratti in scadenza nei prossimi 90 giorni.
- Estrarre termini di condivisione dei ricavi e distribuzione in tabelle strutturate e pipeline di numeri convalidati nei sistemi ERP e di pianificazione.

- Agenzie media
- Estrai listini prezzi, soglie AVB e trigger di fatturazione dai contratti di acquisto media e riconciliati automaticamente rispetto alla consegna e alla spesa.
- Struttura brief dei clienti e report di ricerca in dati riutilizzabili per sistemi di pianificazione e analisi delle campagne.
- Piattaforme Ad tech
- Attiva normative sulla privacy e documenti di policy pubblicitaria per rispondere a “Quali normative attive richiedono meccanismi di opt-out per il targeting comportamentale?” e applica controlli nei motori di consenso e policy.
- Traccia licenze dati e termini API per prevenire l'addestramento o l'attivazione di modelli non conformi.
- Provider di telecomunicazioni
- Gestisci contratti di servizio e wholesale, termini di accordi di roaming e interconnect, e leasing di torri, con chiara visibilità su SLA, escalator e finestre di rinnovo.
- Governa i diritti dei clienti e i bundle end-to-end, sincronizzando i diritti validati con i sistemi di fatturazione, CRM e supporto.
In tutti questi scenari, i clienti vedono miglioramenti come chiusure di fine mese più rapide, ricavi recuperati, riduzione delle perdite e minor rischio operativo, il tutto riducendo lo sforzo manuale per i team finance, legali, operations e marketing.
Cosa fare
Se i tuoi team si affidano ancora a flussi di lavoro documentali manuali e strumenti disconnessi, ora è il momento di modernizzare l'intelligenza documentale su una piattaforma dati e AI governata.
- Esplora Databricks per media e intrattenimento e telecomunicazioni per vedere come contratti, policy e accordi si inseriscono nella tua strategia dati più ampia.
- Parla con il tuo team account Databricks per una proof of value mirata sull'attivazione dei documenti, iniziando con un caso d'uso ad alto impatto e una singola linea di business.
- Approfondisci le storie dei clienti come SEGA, First American, e Vale per vedere come le organizzazioni stanno già trasformando documenti non strutturati in dati governati e azionabili su larga scala.
Unificando estrazione, query, RAG, orchestrazione e scrittura di sistema su Databricks, puoi andare oltre il semplice “leggere documenti” per attivarli, sbloccando così nuove entrate, riducendo il rischio e liberando i tuoi team per concentrarsi su attività a maggior valore.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.