Come le tabelle gestite di Unity Catalog automatizzano le prestazioni su larga scala
Le ottimizzazioni AI integrate offrono fino al 50%+ di risparmio sui costi e query 20 volte più veloci, senza necessità di ottimizzazione manuale
- Scopri le funzionalità che rendono le tabelle gestite di Unity Catalog (UC) la best practice standard per la gestione dei dati
- Riduci i costi del 50%+ e migliora le prestazioni delle query di 20x+ con Predictive Optimization sulle tabelle gestite di UC
- Risparmia tempo di ingegneria dei dati con ottimizzazioni dei dati automatiche e intelligenti che si adattano ai pattern di utilizzo
Unity Catalog (UC) tabelle gestite combinano una solida governance con un'interoperabilità senza interruzioni tra gli strumenti. Poiché i dati risiedono nello storage cloud di proprietà del cliente, le organizzazioni mantengono il pieno controllo sulla loro posizione fisica, beneficiando al contempo dell'intelligenza e dell'automazione integrate di Databricks.
Oggi, le tabelle gestite UC sono il tipo di tabella più comunemente utilizzato in Databricks; due tabelle UC su tre sono gestite. Questa adozione riflette la sua capacità di semplificare le operazioni, ridurre i costi e migliorare le prestazioni su larga scala.
Con le tabelle gestite UC, le organizzazioni possono essere certe di utilizzare sempre le ultime funzionalità delle tabelle. Queste tabelle vengono aggiornate automaticamente e, a differenza di altri tipi di tabelle, comprendono i modelli di utilizzo, consentendo di abilitare nuove funzionalità in modo sicuro e incrementale, senza intervento manuale.
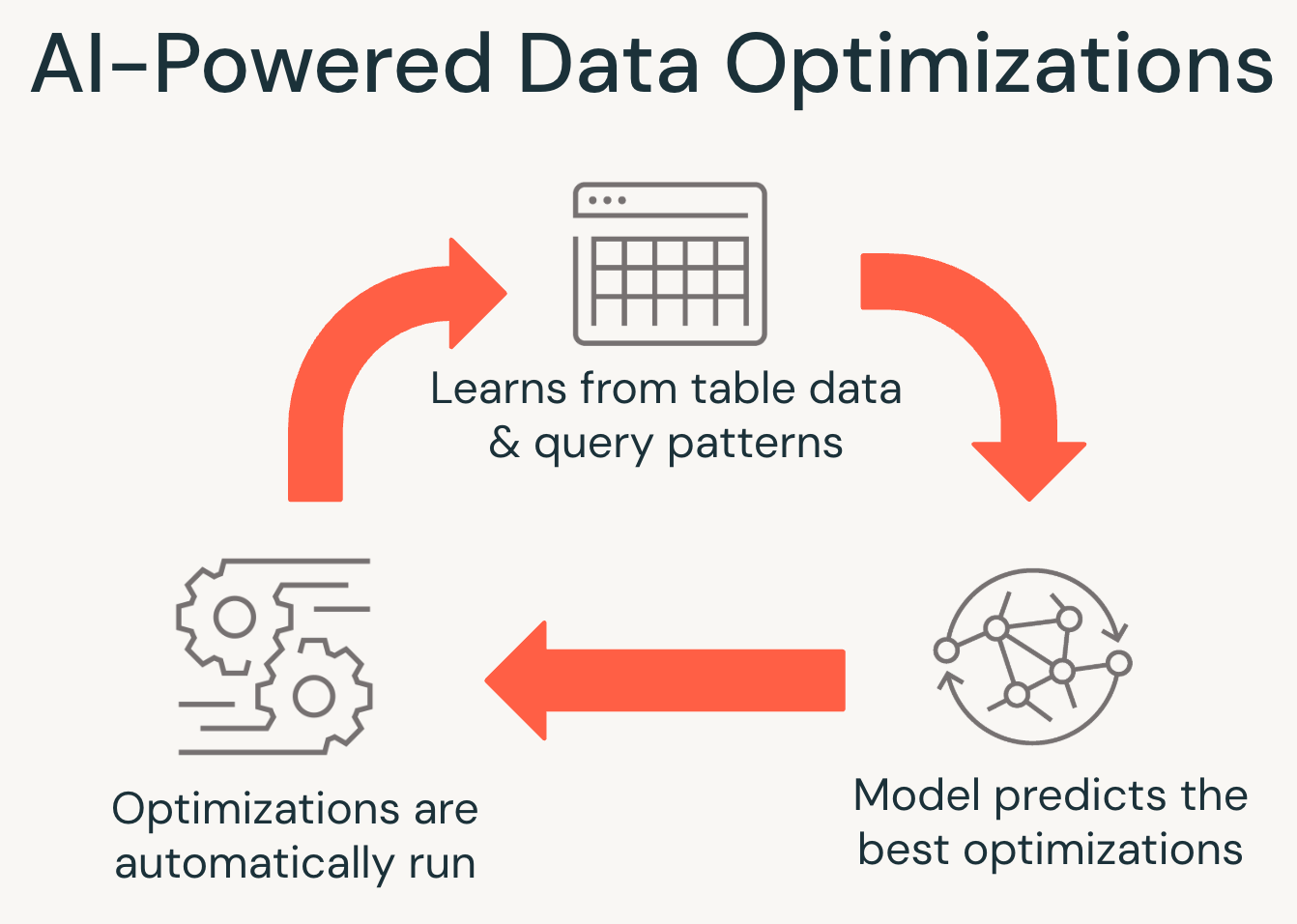
La struttura delle tabelle gestite UC abilita anche funzionalità AI avanzate che prima non erano possibili. Poiché tutte le letture e scritture passano attraverso Unity Catalog, Databricks può ottimizzare in modo intelligente i dati in base all'utilizzo effettivo, migliorando le prestazioni delle query, riducendo i costi di storage ed eliminando la manutenzione ordinaria.
I vantaggi principali includono:
- Aggiornamenti automatici con le ultime funzionalità
- Auto-manutenzione con compattazione, clustering e vacuuming
- Risparmio sui costi di storage e compute tramite ottimizzazione intelligente
- Accesso sicuro tramite API aperte, anche per client non Databricks
- Query più veloci su tutti i client, non solo in Databricks
In questo blog, forniremo un'analisi approfondita delle funzionalità che rendono efficaci le tabelle gestite UC, insieme ai recenti miglioramenti e un'anteprima di ciò che è previsto per il futuro.
"Le ottimizzazioni automatiche delle tabelle gestite di Unity Catalog ci hanno fatto risparmiare oltre 1 milione di dollari all'anno in costi di storage, eliminando al contempo la necessità di un noioso lavoro manuale su base giornaliera." —Abhinav Raghuvanshi, Associate Director of Data Engineering presso Zepto
Quali sono i vantaggi delle tabelle gestite di Unity Catalog?
Le tabelle gestite UC sono ottimizzate per impostazione predefinita, senza necessità di tuning manuale. Si adattano continuamente in base ai carichi di lavoro delle query per migliorare le prestazioni, ridurre i costi di storage e semplificare la gestione del ciclo di vita.
Le tabelle gestite UC semplificano inoltre le operazioni con funzionalità integrate come il vacuuming automatico, la compattazione dei file e la cache dei metadati. Poiché sono basate su formati aperti come Delta e Iceberg, le tabelle gestite UC si integrano facilmente con strumenti e motori di terze parti.
Ottimizzazioni intelligenti guidano i guadagni di costi e prestazioni
Le tabelle gestite UC applicano una serie di tecniche basate sull'IA per offrire risparmi sui costi fino al 50%+ e query più veloci di 20 volte:
Clustering Liquido Automatico
Le tabelle gestite UC raggruppano automaticamente i dati in base ai modelli di query osservati, senza richiedere alcuna configurazione manuale. Al contrario, le tabelle esterne UC richiedono ai data engineer di eseguire comandi OPTIMIZE e definire manualmente le chiavi di clustering. Con le tabelle gestite, Predictive Optimization gestisce il clustering dinamicamente, migliorando le prestazioni delle query e riducendo i costi di storage senza sforzi aggiuntivi. [Leggi di più]

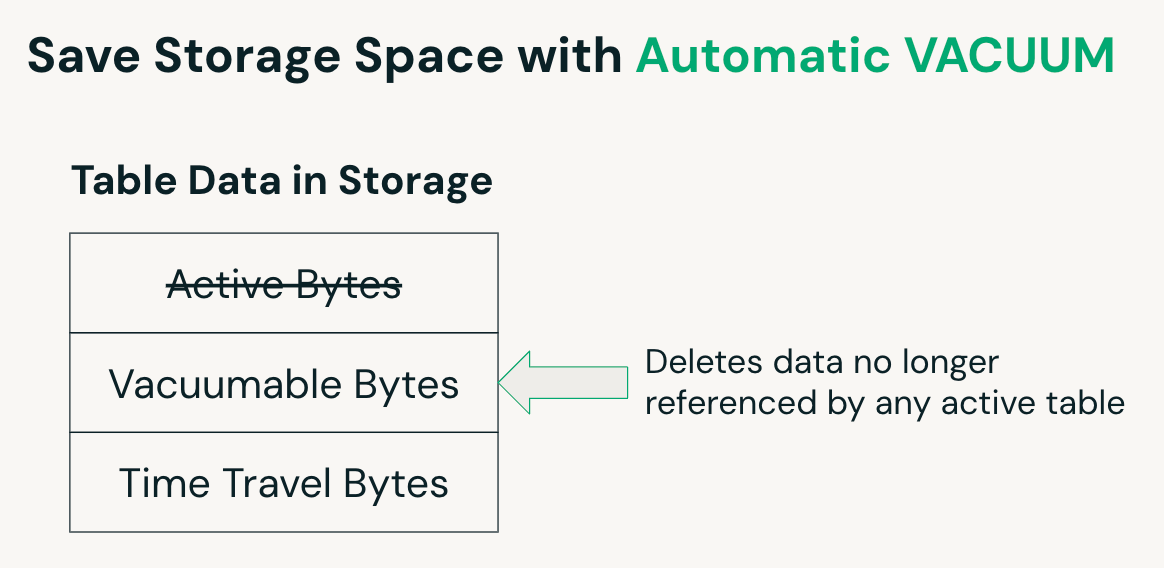
VACUUM Automatico
Sulle tabelle gestite UC, Predictive Optimization identifica automaticamente quando un'operazione VACUUM è vantaggiosa e la pianifica di conseguenza. VACUUM rimuove i file associati alle righe eliminate dopo un periodo di conservazione definito, contribuendo a ridurre l'utilizzo dello storage. Per le tabelle esterne UC, questo processo deve essere gestito manualmente eseguendo il comando VACUUM.
DROP Differito con Pulizia Automatica
Quando una tabella gestita UC viene eliminata, i dati sottostanti nello storage cloud vengono eliminati automaticamente dopo 7 giorni, contribuendo a ridurre i costi di storage ed evitare file orfani. Al contrario, l'eliminazione di una tabella esterna UC non elimina i dati; gli utenti devono rimuovere manualmente i file dal loro bucket di storage. Se questo passaggio viene omesso, i dati rimangono, portando a un utilizzo non necessario dello storage. Vedere la sezione roadmap per i futuri miglioramenti a questo comportamento.
Raccolta Automatica di Statistiche
Le tabelle gestite UC raccolgono automaticamente statistiche che migliorano le prestazioni delle query tramite uno skipping dei dati più intelligente e una migliore pianificazione dei join. Metriche chiave, come i valori minimi e massimi delle colonne, aiutano il sistema a identificare ed escludere file irrilevanti durante l'esecuzione delle query, riducendo l'overhead di compute. Mentre le tabelle esterne UC generano statistiche sulle prime 32 colonne per impostazione predefinita, le tabelle gestite UC danno priorità dinamica alle colonne più rilevanti per i carichi di lavoro delle query effettivi. [Leggi di più]

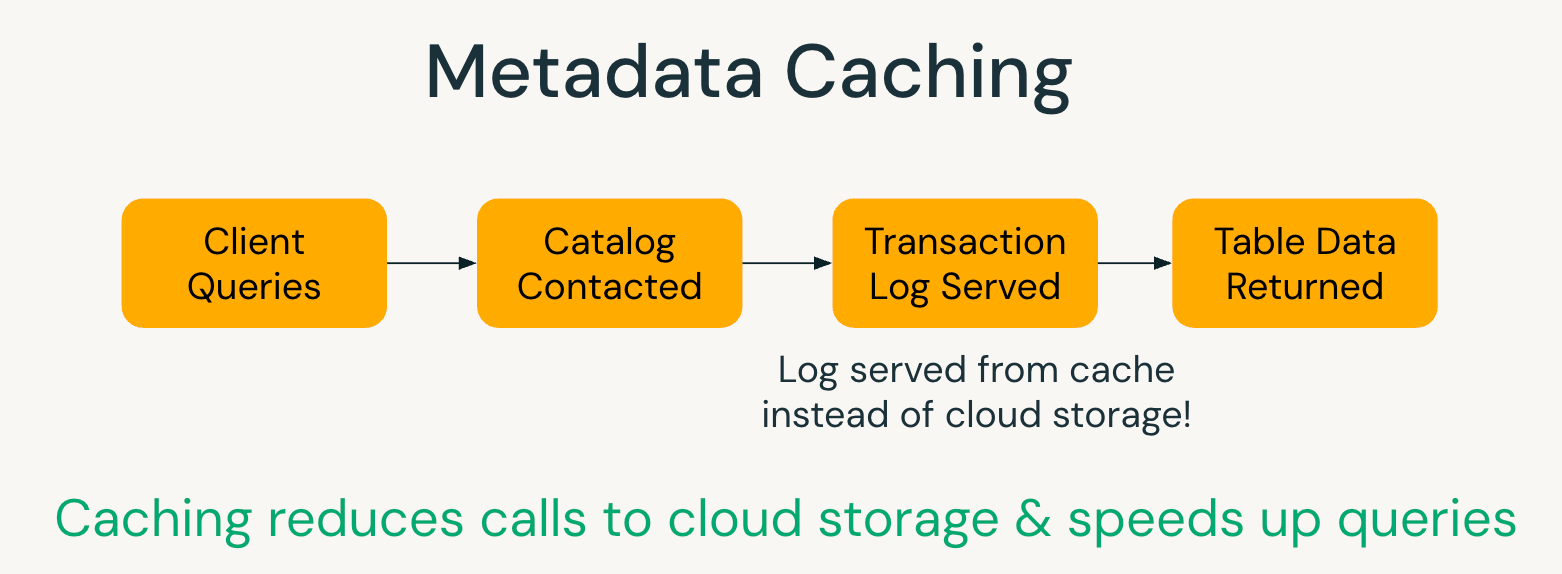
Caching dei Metadati
Le tabelle gestite UC utilizzano la cache in memoria dei metadati di transazione per ridurre l'accesso ai log di transazione basati su cloud. Ciò riduce i costi di compute e migliora le prestazioni di pianificazione delle query. La funzionalità è esclusiva delle tabelle gestite UC, dove Databricks può tracciare tutte le scritture e garantire che i metadati memorizzati nella cache rimangano coerenti con lo stato attuale.
Ottimizzazione delle Dimensioni dei File
Databricks utilizza l'IA per compattare automaticamente i file in dimensioni ottimali, in base ai modelli appresi da migliaia di implementazioni reali. Questa ottimizzazione avviene durante la scrittura dei dati e contribuisce a migliorare le prestazioni delle query riducendo la frammentazione dei file e l'overhead di scansione. [Leggi di più]

Aperte e Interoperabili per Progettazione
Le tabelle gestite UC sono costruite su formati aperti come Delta e Iceberg, consentendo un'ampia compatibilità con l'ecosistema dati moderno. Possono essere accessibili da qualsiasi motore che supporti questi formati, inclusi Trino, DuckDB, Apache Spark™, Daft e strumenti integrati con il catalogo REST Iceberg, come Dremio.
L'accesso sicuro è reso possibile tramite API aperte e credential vending, consentendo agli strumenti esterni di interagire con i dati governati senza duplicarli. Ciò semplifica l'architettura e abilita un'unica fonte di verità per i carichi di lavoro di analytics e AI.
Anche il supporto per le scritture di terze parti è in espansione. In anteprima privata, le tabelle gestite UC accettano ora scritture da client Delta non Databricks, come Apache Spark, rendendo più facile l'integrazione con framework di elaborazione esterni mantenendo la governance di Unity Catalog.
Delta Sharing, l'unico protocollo di condivisione aperto del settore, migliora ulteriormente l'interoperabilità consentendo l'accesso sicuro in sola lettura ai dati sottostanti, anche per i destinatari che non utilizzano Databricks. Queste funzionalità consentono di estendere l'accesso ai dati governati tra piattaforme, partner e applicazioni.
Poiché queste ottimizzazioni si applicano a livello di layout dei dati, i miglioramenti delle prestazioni sono universali. Gli strumenti esterni beneficiano dello stesso layout clusterizzato, file compattati e statistiche avanzate, con conseguenti query più veloci e letture più efficienti, indipendentemente dal motore.
Cosa c'è nella roadmap
Sono in arrivo diverse nuove funzionalità che renderanno le tabelle gestite da UC ancora più potenti e flessibili:
Osservabilità a livello di tabella
Ottieni visibilità su tabelle inutilizzate, finestre di conservazione, tendenze delle dimensioni delle tabelle e metadati personalizzati, semplificando la gestione dei costi e l'applicazione delle best practice.
Periodi UNDROP configurabili
Personalizza la finestra di conservazione per le tabelle eliminate, incluso il supporto per l'eliminazione immediata per ridurre ulteriormente i costi di archiviazione.
Strumenti di riorganizzazione di schemi e cataloghi
Comandi per spostare tabelle tra cataloghi e schemi, aiutando i team a mantenere i set di dati logicamente organizzati man mano che gli ambienti evolvono.
Transazioni multi-istruzione e multi-tabella (Anteprima privata)
Supporto per commit atomici su più tabelle. Se un'operazione fallisce, l'intera transazione viene annullata, migliorando l'affidabilità per operazioni sui dati complesse.
Iniziare con le tabelle gestite da UC
Le tabelle gestite da UC sono abilitate per impostazione predefinita e facili da adottare, sia che si creino nuove tabelle sia che si convertano quelle esistenti.
Crea una nuova tabella gestita
Per i nuovi carichi di lavoro, le tabelle gestite da UC vengono create senza la necessità di specificare una posizione di archiviazione. Databricks gestisce automaticamente il percorso dei dati nello spazio di archiviazione cloud di proprietà del cliente:
CREATE OR REPLACE TABLE catalog.schema.my_managed_table
Converti una tabella esterna UC esistente in gestita
Le organizzazioni che desiderano convertire in tabelle gestite possono utilizzare il seguente comando per convertire tabelle esterne UC:
ALTER TABLE catalog.schema.my_external_table SET MANAGED
Visualizza la documentazione e richiedi l'accesso all'anteprima pubblica limitata utilizzando questo modulo.
Converti tabelle esterne (non UC)
Per i team che migrano da tipi di tabelle esterne, la conversione in tabelle gestite da UC è disponibile in Anteprima privata. Ciò semplifica il consolidamento della governance e dell'ottimizzazione sotto Unity Catalog. Puoi richiedere l'accesso all'anteprima limitata utilizzando questo modulo.
Prova le funzionalità avanzate in anteprima
Per sperimentare funzionalità come scritture di terze parti su tabelle gestite, transazioni multi-tabella o riorganizzazione dello schema, contatta il tuo team di account Databricks per unirti ai relativi programmi di anteprima.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.