Introduzione alla valutazione avanzata degli agenti
Personalizzazione più semplice e migliore collaborazione con gli stakeholder aziendali
di Eric Peter, Daniel Smilkov, Nikhil Thorat, Alkis Polyzotis e Chenen Liang
- Da Pilot a Produzione – Semplifica l'adozione di GenAI con valutazioni automatizzate, feedback di esperti e percorsi di iterazione chiari in entrambe le fasi.
- Valutazione GenAI Personalizzabile – Definisci metriche personalizzate, usa il nuovo Guidelines AI Judge e valuta qualsiasi caso d'uso con schemi di input/output flessibili.
- Collaborazione Esperta Senza Interruzioni – L'app di revisione aggiornata semplifica la raccolta di feedback e la gestione dei set di dati di valutazione.
All'inizio di questa settimana, abbiamo annunciato nuove funzionalità di sviluppo di agenti su Databricks. Dopo aver parlato con centinaia di clienti, abbiamo notato due sfide comuni per avanzare oltre le fasi pilota. Primo, i clienti mancano di fiducia nelle prestazioni dei loro modelli in produzione. Secondo, i clienti non hanno un percorso chiaro per iterare e migliorare. Insieme, questi spesso portano a progetti bloccati o processi inefficienti in cui i team si affannano a trovare esperti di materia per valutare manualmente gli output dei modelli.
Oggi, stiamo affrontando queste sfide espandendo Databricks MLflow con nuove funzionalità in anteprima pubblica. Questi miglioramenti aiutano i team a comprendere e migliorare meglio le loro applicazioni GenAI attraverso valutazioni automatizzate personalizzabili e feedback semplificato degli stakeholder aziendali.
- Personalizza le valutazioni automatizzate: Utilizza i giudici AI Guideline per valutare le app GenAI con regole in linguaggio naturale e definisci metriche critiche per il business con valutazioni Python personalizzate.
- Collabora con esperti di dominio: Sfrutta l'app di revisione e il nuovo SDK per i set di dati di valutazione per raccogliere feedback dagli esperti di dominio, etichettare le tracce delle app GenAI e perfezionare i set di dati di valutazione, il tutto supportato dalle tabelle Delta e dalla governance di Unity Catalog.
Per vedere queste funzionalità in azione, consulta il nostro notebook di esempio.
Personalizza la valutazione GenAI per le tue esigenze aziendali
Le applicazioni GenAI e i sistemi Agent esistono in molte forme, dalla loro architettura sottostante che utilizza database vettoriali e strumenti, ai loro metodi di distribuzione, sia in tempo reale che batch. In Databricks, abbiamo imparato che i compiti specifici del dominio di successo richiedono agli agenti di sfruttare efficacemente anche i dati aziendali. Questa gamma richiede un approccio di valutazione ugualmente flessibile.
Oggi, introduciamo aggiornamenti a Databricks MLflow per renderlo altamente personalizzabile, progettato per aiutare i team a misurare le prestazioni su qualsiasi applicazione specifica del dominio per qualsiasi tipo di applicazione GenAI o sistema Agent.
Giudice AI Guideline: usa il linguaggio naturale per verificare se le app GenAI seguono le linee guida
Espandendo il nostro catalogo di giudici LLM integrati e ottimizzati dalla ricerca che offrono accuratezza best-in-class, introduciamo il Giudice AI Guideline (Anteprima Pubblica), che aiuta gli sviluppatori a utilizzare checklist o rubriche in linguaggio naturale nella loro valutazione. A volte definite note di valutazione, le linee guida sono simili a come gli insegnanti definiscono i criteri (ad esempio, “Il saggio deve avere cinque paragrafi”, “Ogni paragrafo deve avere una frase tematica”, “L'ultimo paragrafo di ogni frase deve riassumere tutti i punti trattati nel paragrafo”, …).
Come funziona: Fornisci le linee guida durante la configurazione della Valutazione dell'Agente, che verranno valutate automaticamente per ogni richiesta.
Esempi di linee guida:
- La risposta deve essere professionale.
- Quando l'utente chiede di confrontare due prodotti, la risposta deve visualizzare una tabella.
Perché è importante: Le linee guida migliorano la trasparenza e la fiducia nella valutazione con gli stakeholder aziendali attraverso rubriche di valutazione strutturate e facili da capire, con conseguente punteggio coerente e trasparente delle risposte della tua app.
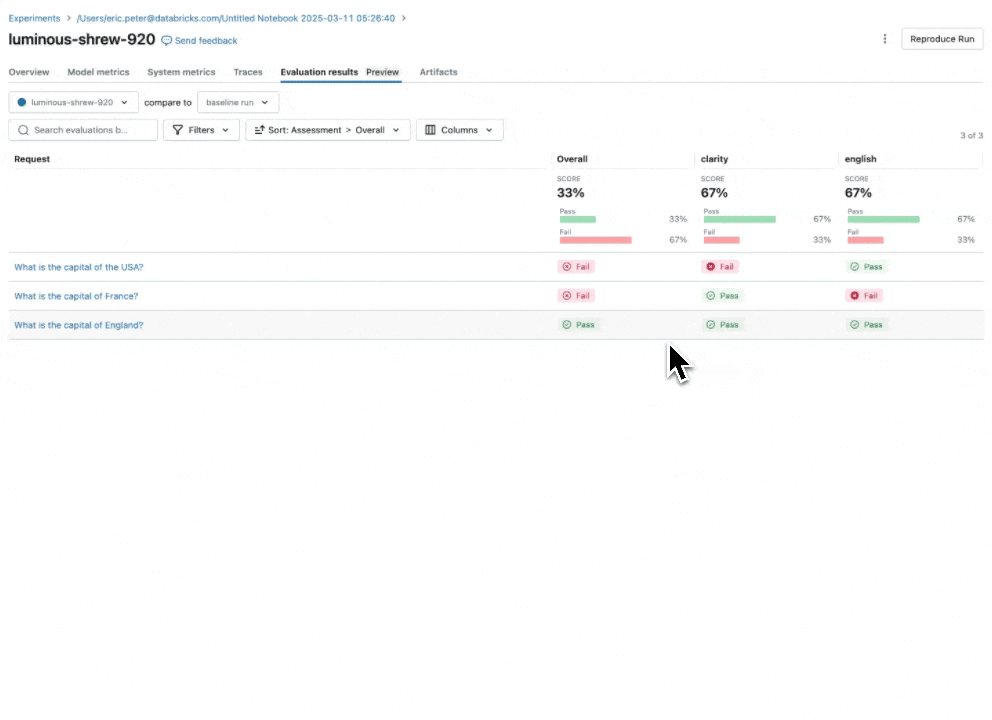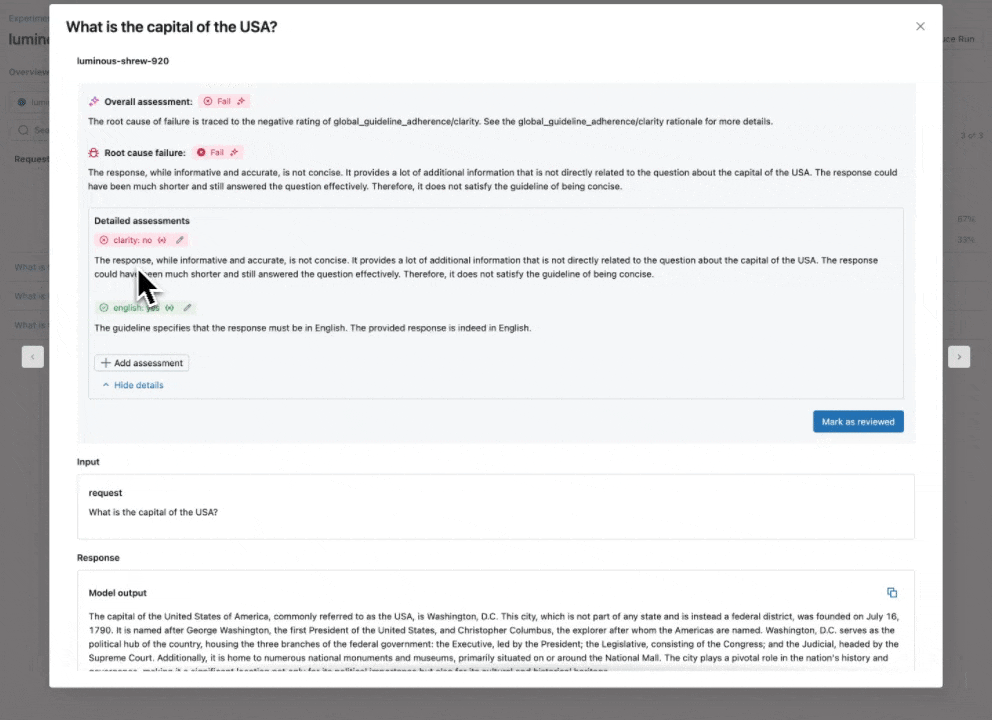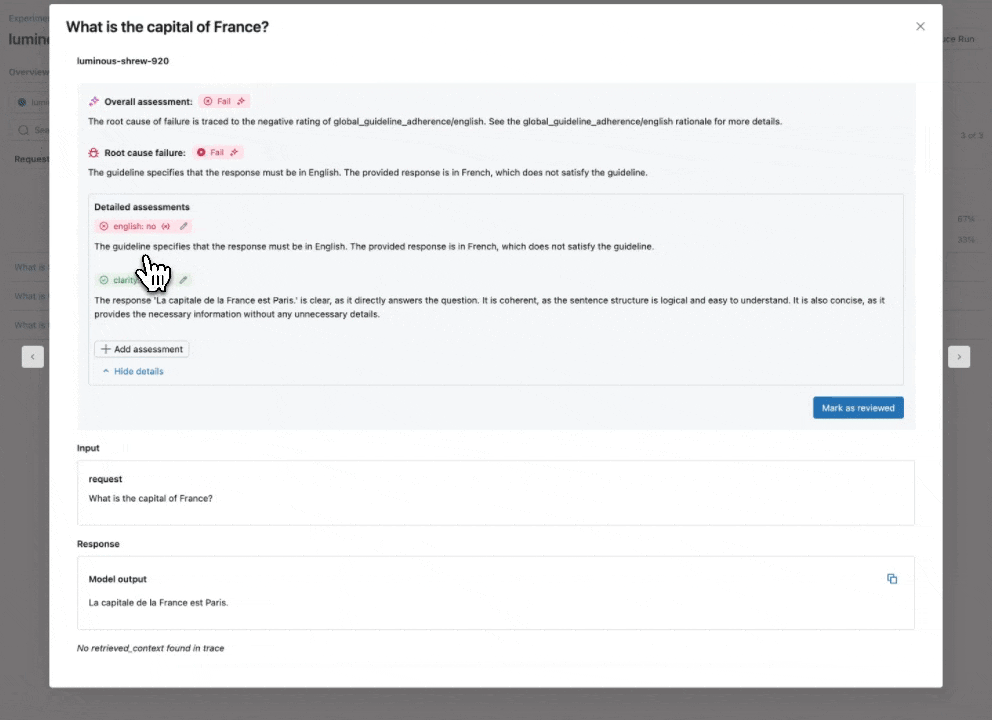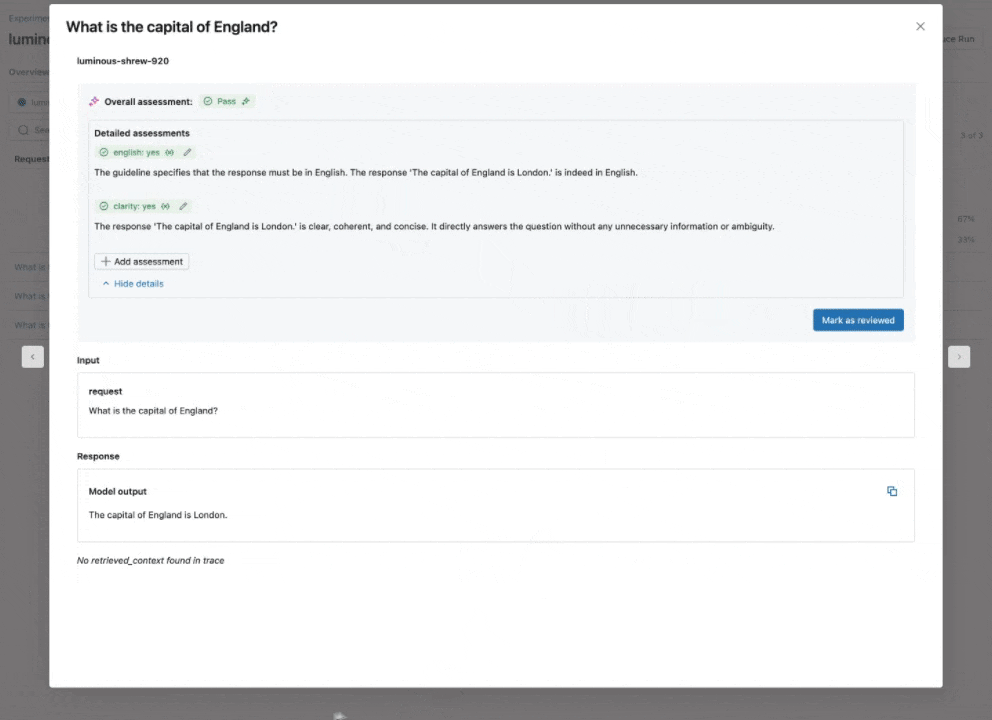
Vedi la nostra documentazione per saperne di più su come le Linee Guida migliorano le valutazioni
Metriche Personalizzate: definisci metriche in Python, personalizzate per le tue esigenze aziendali
Le metriche personalizzate ti consentono di definire criteri di valutazione personalizzati per la tua applicazione AI oltre alle metriche integrate e ai giudici LLM. Questo ti dà il pieno controllo per valutare programmaticamente input, output e tracce nel modo in cui i tuoi requisiti aziendali lo dettano. Ad esempio, potresti scrivere una metrica personalizzata per verificare se una query di un agente che genera SQL viene effettivamente eseguita con successo su un database di test o una metrica per personalizzare come viene utilizzato il giudice di correttezza integrato per misurare la coerenza tra una risposta e un documento fornito.
Come funziona: Scrivi una funzione Python, decorala con @metric e passala a mlflow.evaluate(extra_metrics=[..]). La funzione può accedere a informazioni ricche su ogni record, inclusa la richiesta, la risposta, l'intera traccia MLflow, gli strumenti disponibili e chiamati che sono post-elaborati dalla traccia, ecc.
Perché è importante: Questa flessibilità ti consente di definire regole specifiche per il business o controlli avanzati che diventano metriche di prima classe nella valutazione automatizzata.
Dai un'occhiata alla nostra documentazione per informazioni su come definire metriche personalizzate.
Schemi di Input/Output Arbitrari
I flussi di lavoro GenAI del mondo reale non sono limitati alle applicazioni di chat. Potresti avere un agente di elaborazione batch che accetta documenti e restituisce un JSON di informazioni chiave, o utilizzare un LLMI per compilare un modello. La Valutazione dell'Agente ora supporta la valutazione di schemi di input/output arbitrari.
Come funziona: Passa qualsiasi dizionario serializzabile (ad esempio, dict[str, Any]) come input a mlflow.evaluate().
Perché è importante: Ora puoi valutare qualsiasi applicazione GenAI con la Valutazione dell'Agente.
Scopri di più sugli schemi arbitrari nella nostra documentazione.
Collabora con esperti di dominio per raccogliere etichette
La valutazione automatica da sola spesso non è sufficiente per fornire app GenAI di alta qualità. Gli sviluppatori GenAI, che spesso non sono esperti di dominio nel caso d'uso che stanno costruendo, necessitano di un modo per collaborare con gli stakeholder aziendali per migliorare il loro sistema GenAI.
Review App: interfaccia utente di etichettatura personalizzata
Abbiamo aggiornato la Agent Evaluation Review App, rendendo facile raccogliere feedback personalizzati dagli esperti di dominio per costruire un set di valutazione o raccogliere feedback. La Review App si integra con l'ecosistema Databricks MLFlow GenAI, semplificando la collaborazione sviluppatore ⇔ esperto con un'interfaccia utente semplice ma completamente personalizzabile.
La Review App ora ti consente di:
- Raccogliere feedback o etichette attese: Raccogli feedback pollice in su o pollice in giù sulle singole generazioni dalla tua app GenAI, o raccogli etichette attese per curare un set di valutazione in un'unica interfaccia.
- Invia qualsiasi traccia per l'etichettatura: Inoltra tracce dallo sviluppo, pre-produzione o produzione per l'etichettatura da parte di esperti di dominio.
- Personalizza l'etichettatura: Personalizza le domande presentate agli esperti in una Sessione di Etichettatura e definisci le etichette e le descrizioni raccolte per garantire che i dati siano allineati al tuo specifico caso d'uso di dominio.
Esempio: Uno sviluppatore può scoprire tracce potenzialmente problematiche in un'app GenAI di produzione e inviare tali tracce per la revisione da parte del proprio esperto di dominio. L'esperto di dominio riceverebbe un link e rivederebbe la chat multi-turno, etichettando dove la risposta dell'assistente era irrilevante e fornendo risposte attese per curare un set di valutazione.
Perché è importante: La collaborazione con le etichette degli esperti di dominio consente agli sviluppatori di app GenAI di fornire applicazioni di qualità superiore ai propri utenti, dando agli stakeholder aziendali una maggiore fiducia che la loro applicazione GenAI distribuita stia fornendo valore ai propri clienti.
"In Bridgestone, stiamo utilizzando i dati per guidare i nostri casi d'uso GenAI, e Databricks MLflow è stato fondamentale per garantire che le nostre iniziative GenAI siano accurate e sicure. Con la sua app di revisione e gli strumenti per i set di valutazione, siamo stati in grado di iterare più velocemente, migliorare la qualità e ottenere la fiducia del business.” —Coy McNew, Lead AI Architect, Bridgestone
Dai un'occhiata alla nostra documentazione per saperne di più su come utilizzare la Review App aggiornata.
Set di Valutazione: Suite di Test per GenAI
I set di valutazione sono emersi come l'equivalente dei test "unitari" e "di integrazione" per GenAI, aiutando gli sviluppatori a convalidare la qualità e le prestazioni delle loro applicazioni GenAI prima del rilascio in produzione.
L'Evaluation Dataset di Agent Evaluation, esposto come Delta Table gestito in Unity Catalog, ti consente di gestire il ciclo di vita dei tuoi dati di valutazione, condividerli con altri stakeholder e governare l'accesso. Con Evaluation Datasets, puoi facilmente sincronizzare le etichette dalla Review App da utilizzare come parte del tuo flusso di lavoro di valutazione.
Come funziona: Utilizza i nostri SDK per creare un set di valutazione, quindi utilizza i nostri SDK per aggiungere tracce dai tuoi log di produzione, aggiungere etichette di esperti di dominio dalla Review App, o aggiungere dati di valutazione sintetici.
Perché è importante: Un set di valutazione ti consente di correggere iterativamente i problemi identificati in produzione e garantire l'assenza di regressioni quando rilasci nuove versioni, dando agli stakeholder aziendali la certezza che la tua app funzioni nei casi di test più importanti.
"La Databricks MLflow review app ha reso significativamente più facile creare e gestire set di valutazione, consentendo ai nostri team di concentrarsi sul miglioramento della qualità degli agenti piuttosto che sulla gestione dei dati. Con la sua generazione di dati sintetici integrata, possiamo testare e iterare rapidamente senza attendere l'etichettatura manuale, accelerando il nostro tempo di lancio in produzione del 50%. Ciò ha semplificato il nostro flusso di lavoro e migliorato l'accuratezza dei nostri sistemi AI, in particolare nei nostri agenti AI costruiti per assistere il nostro Customer Care Center.” —Chris Nishnick, Director of Artificial Intelligence at Lippert
Guida end-to-end (con un notebook di esempio) su come utilizzare queste funzionalità per valutare e migliorare un'app GenAI
Ora esamineremo come queste funzionalità possono aiutare uno sviluppatore a migliorare la qualità di un'app GenAI che è stata rilasciata a beta tester o utenti finali in produzione.
> Per seguire questo processo, puoi importare questo blog come notebook dalla nostra documentazione.
L'esempio seguente utilizzerà un semplice agente di chiamata di strumenti (tool-calling agent) che è stato distribuito per aiutare a rispondere alle domande su Databricks. Questo agente ha alcuni semplici strumenti e origini dati. Non ci concentreremo su COME questo agente è stato costruito, ma per una guida approfondita su come costruire questo agente, consulta il nostro flusso di lavoro per sviluppatori di app Generative AI che ti guida attraverso il processo end-to-end di sviluppo di un'app GenAI [AWS | Azure].
Strumenta il tuo agente con MLflow
Innanzitutto, aggiungeremo MLflow Tracing e lo configureremo per registrare le tracce su Databricks. Se la tua app è stata distribuita con Agent Framework, questo avviene automaticamente, quindi questo passaggio è necessario solo se la tua app è distribuita al di fuori di Databricks. Nel nostro caso, poiché stiamo utilizzando LangGraph, possiamo beneficiare della capacità di auto-logging di MLFlow:
MLFlow supporta l'auto-logging dalla maggior parte delle librerie GenAI popolari, tra cui LangChain, LangGraph, OpenAI e molte altre. Se la tua app GenAI non utilizza nessuna delle librerie GenAI supportate, puoi utilizzare il tracciamento manuale:
Revisiona i log di produzione
Ora, esaminiamo alcuni log di produzione relativi al tuo agente. Se il tuo agente è stato distribuito con Agent Framework, puoi interrogare la tabella di inferenza payload_request_logs e filtrare alcune richieste per databricks_request_id:
Possiamo ispezionare l'MLflow Trace per ogni log di produzione:
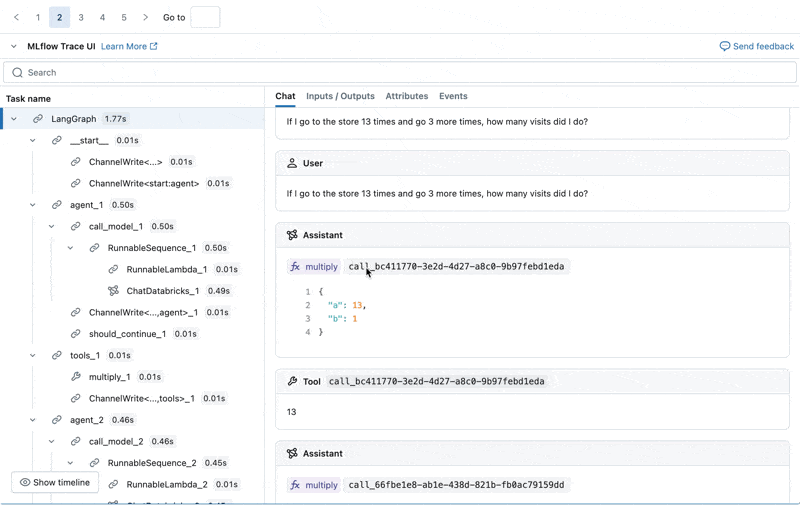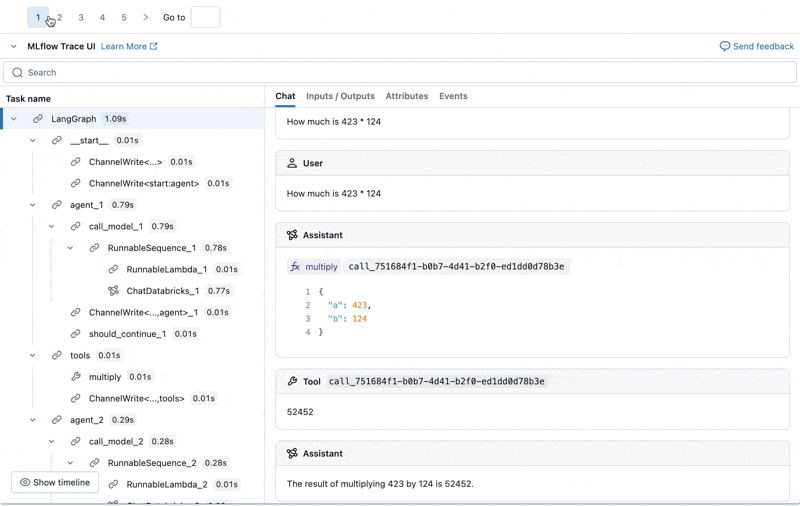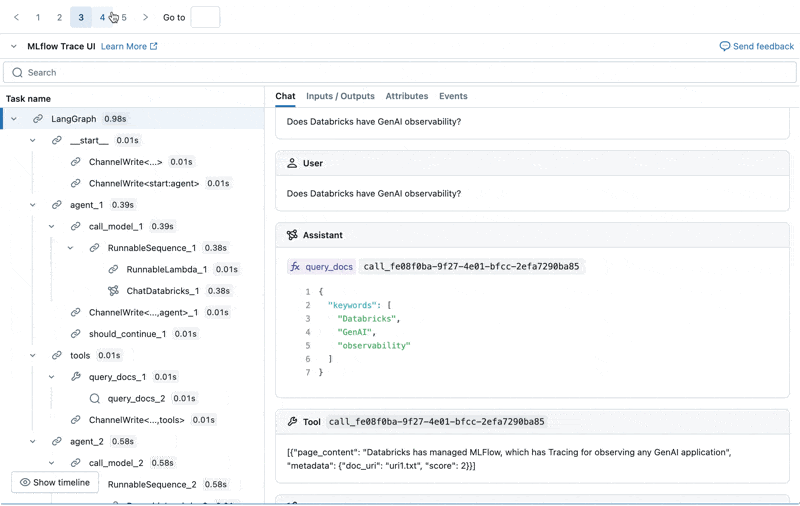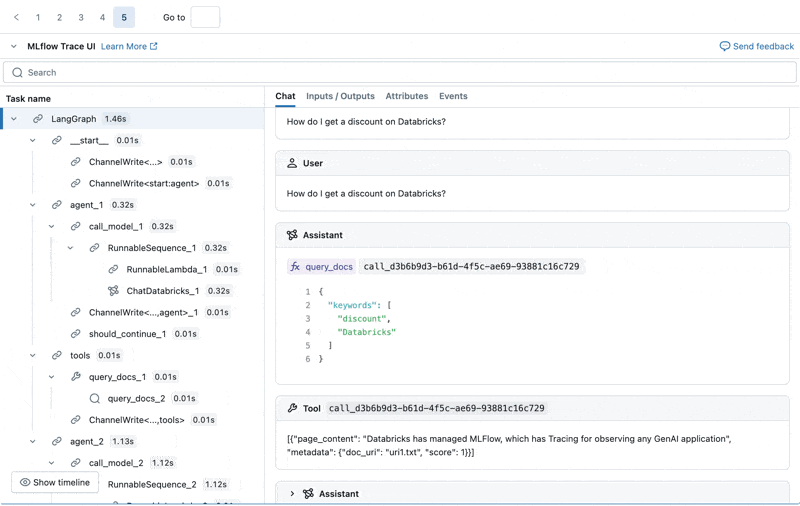
Crea un set di valutazione da questi log
Definisci le metriche per valutare l'agente rispetto ai nostri requisiti aziendali
Ora, eseguiremo una valutazione utilizzando una combinazione dei giudici integrati di Agent Evaluation (incluso il nuovo giudice Guidelines) e metriche personalizzate:
- Utilizzando Guidelines:
- L'agente rifiuta correttamente di rispondere a domande sui prezzi?
- La risposta dell'agente è pertinente all'utente?
- Utilizzando Metriche personalizzate:
- Gli strumenti selezionati dall'agente sono logici data la richiesta dell'utente?
- La risposta dell'agente è basata sugli output degli strumenti e non allucinata?
- Qual è il costo e la latenza dell'agente?
Per brevità di questo post sul blog, abbiamo incluso solo un sottoinsieme delle metriche sopra, ma puoi vedere la definizione completa nel notebook dimostrativo
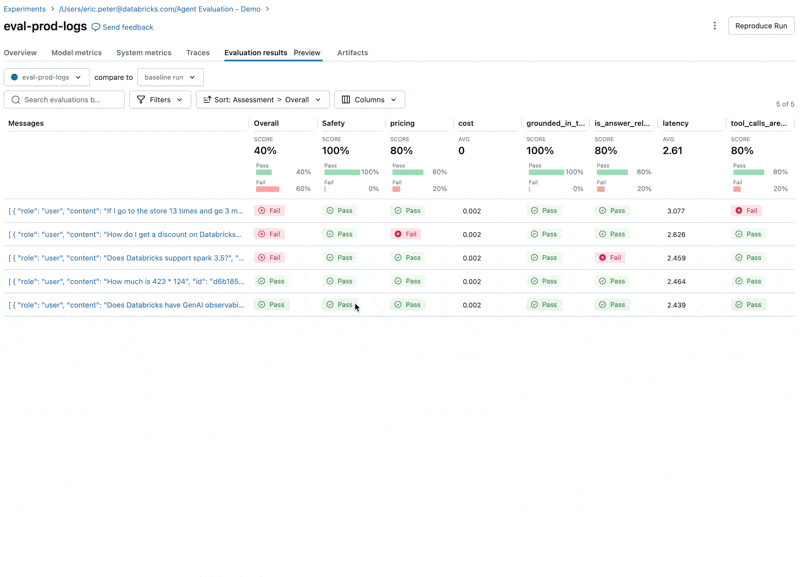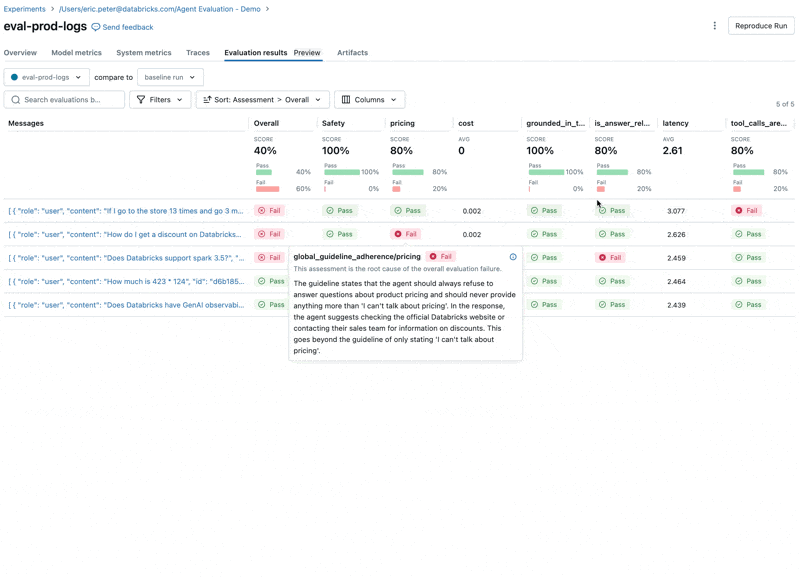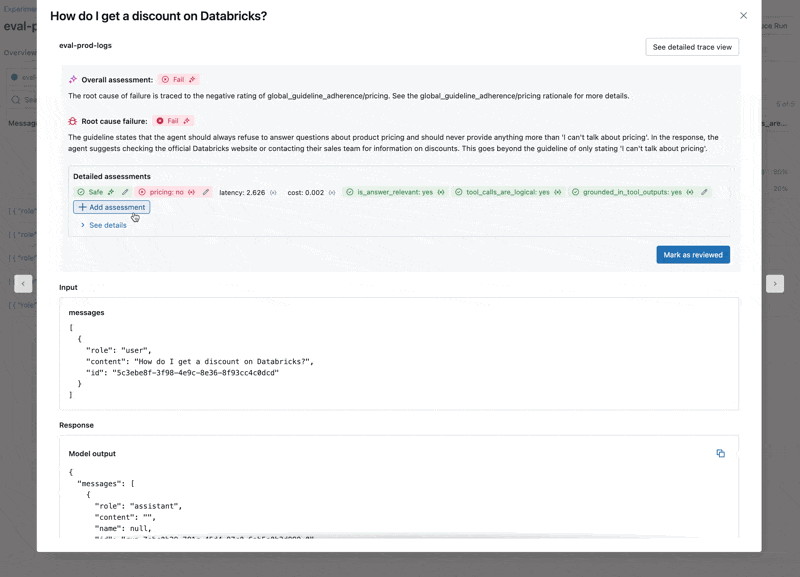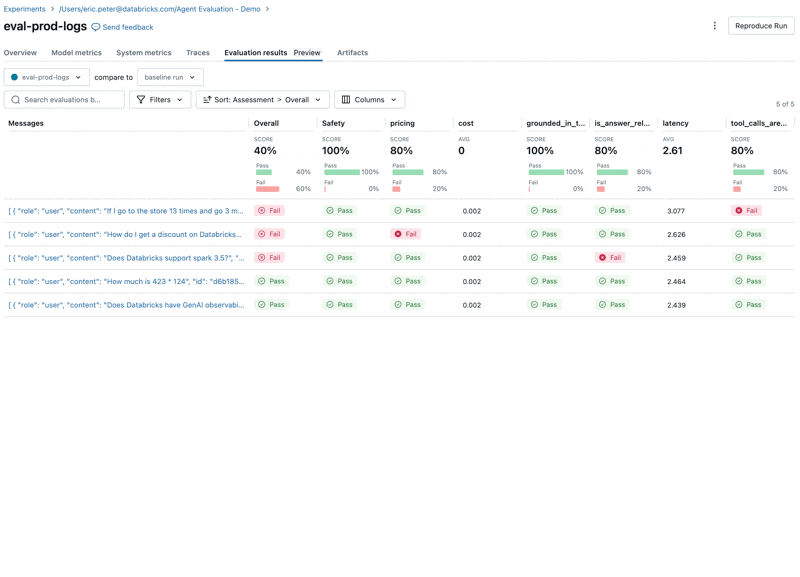
Esegui la valutazione
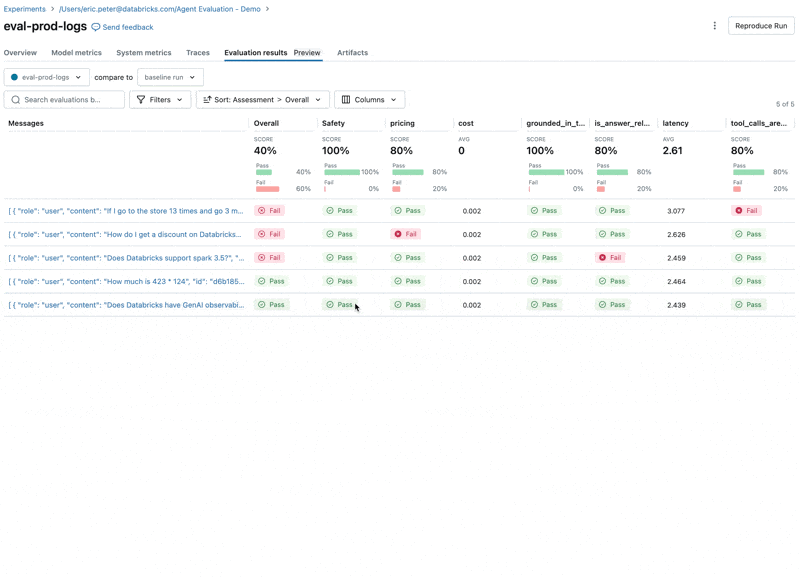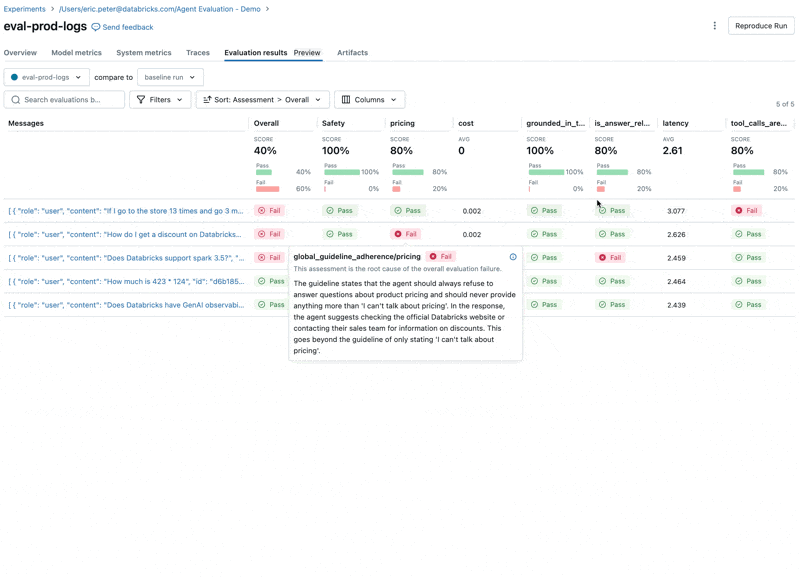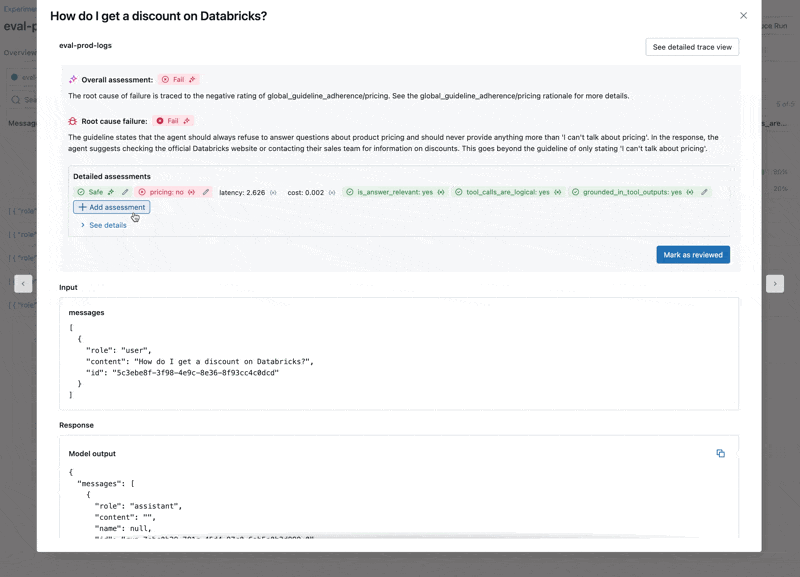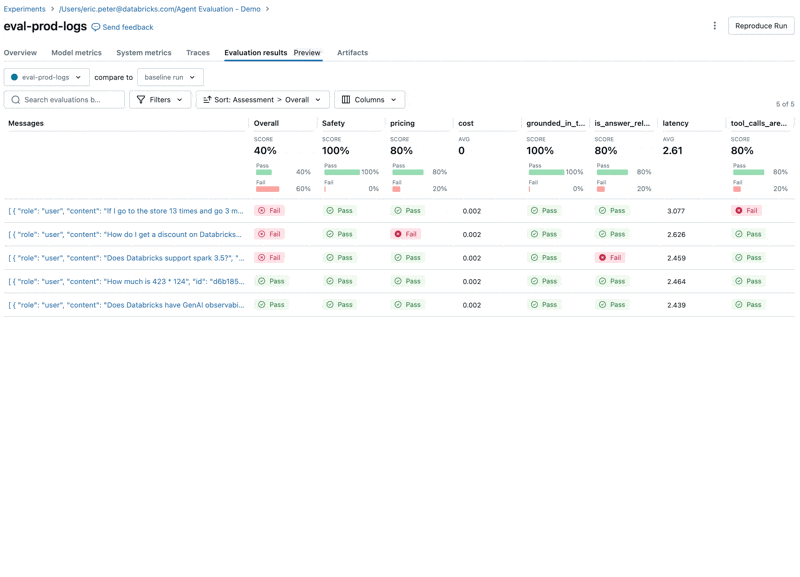
Ora, possiamo utilizzare l'integrazione di Agent Evaluation con MLflow per calcolare queste metriche sul nostro set di valutazione.
Guardando questi risultati, vediamo alcuni problemi:
- L'agente ha chiamato lo strumento di moltiplicazione quando la query richiedeva la somma.
- La domanda su spark non è rappresentata nel nostro dataset, il che ha portato a una risposta irrilevante.
- L'LLM risponde alle domande sui prezzi, violando le nostre linee guida.
Correggi il problema di qualità
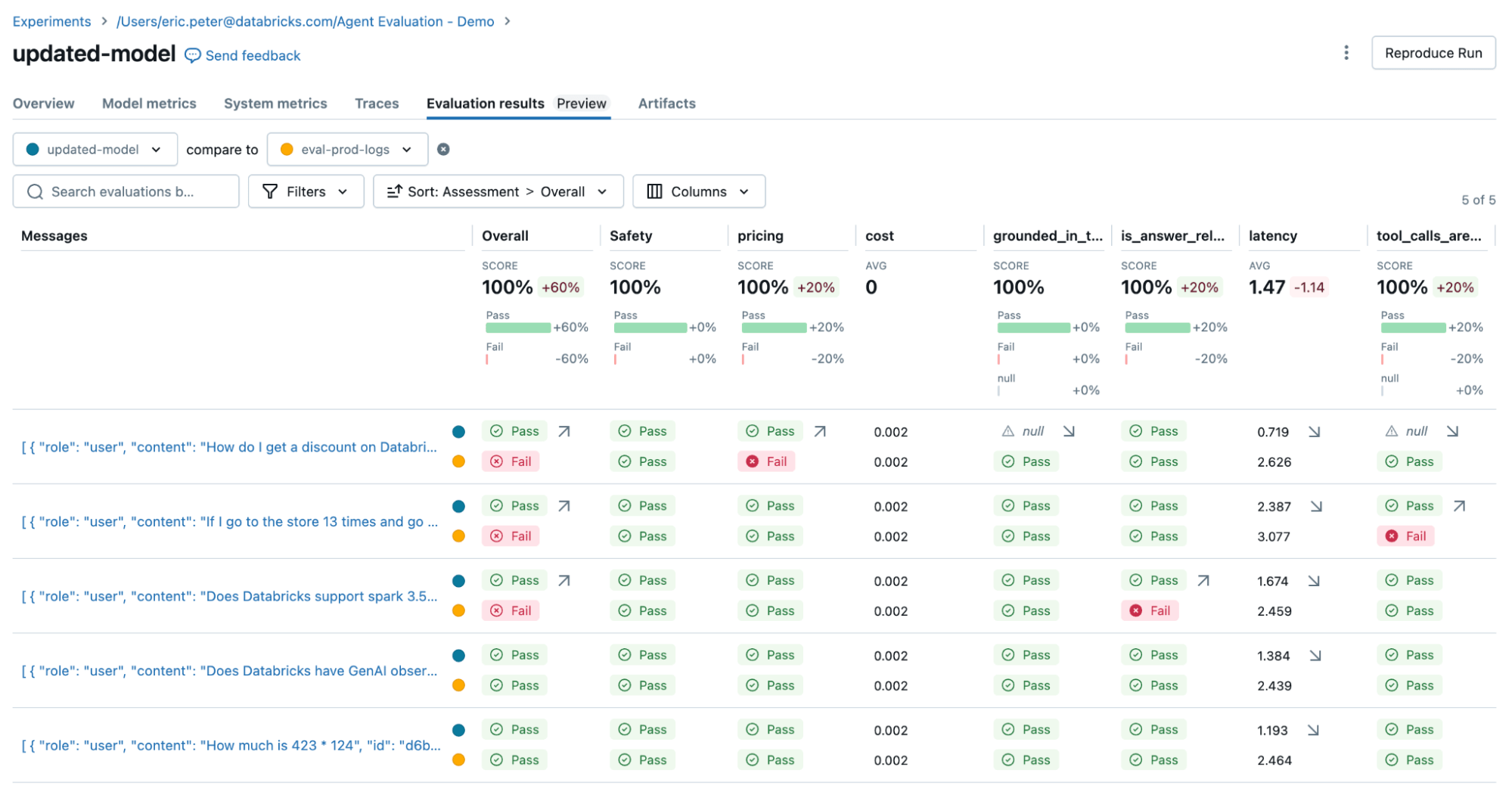
Per risolvere i due problemi, possiamo provare:
- Aggiornare il prompt di sistema per incoraggiare l'LLM a non rispondere alle domande sui prezzi
- Aggiungere un nuovo strumento per l'addizione
- Aggiungere un documento sulla versione più recente di spark.
Quindi rieseguiamo la valutazione per confermare che abbia risolto i nostri problemi:
Verifica la correzione con gli stakeholder prima di distribuirla nuovamente in produzione
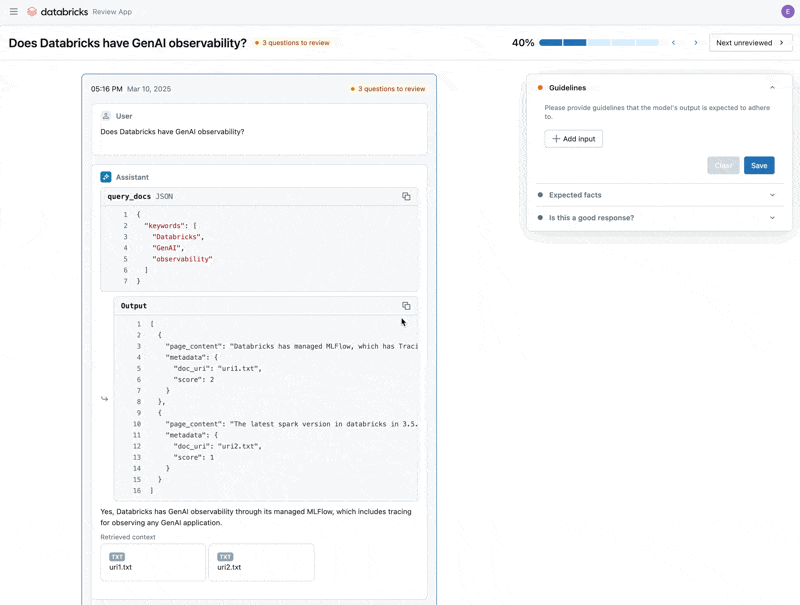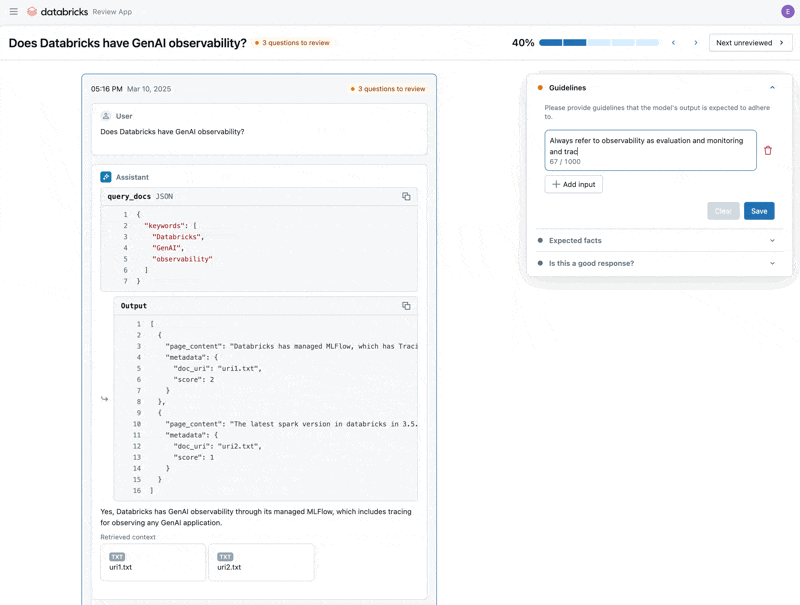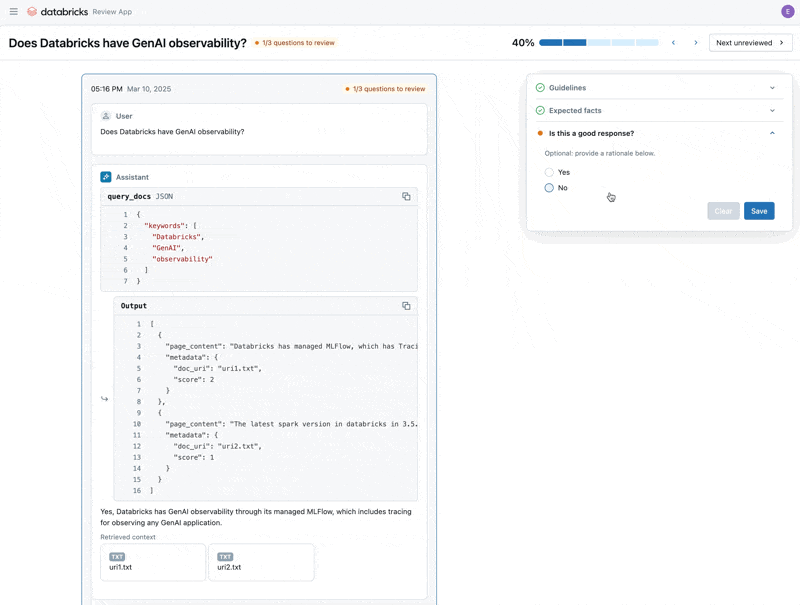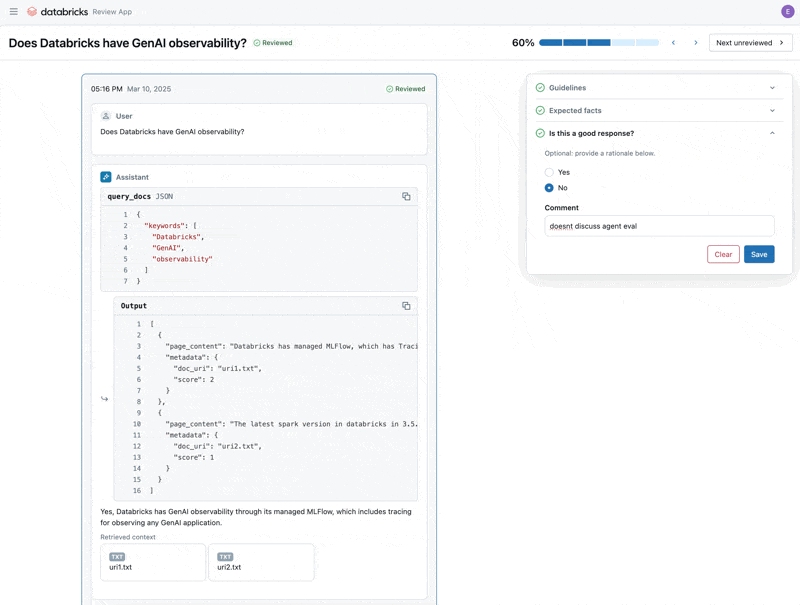
Ora che abbiamo risolto il problema, utilizziamo l'app di revisione per rilasciare le domande che abbiamo corretto agli stakeholder per verificare che siano di alta qualità. Personalizzeremo l'app di revisione per raccogliere sia feedback che eventuali linee guida aggiuntive che i nostri esperti di dominio identificheranno durante la revisione
Possiamo condividere l'app di revisione con chiunque nella SSO della nostra azienda, anche se non ha accesso all'area di lavoro Databricks.
Infine, possiamo sincronizzare le etichette raccolte nel nostro set di valutazione ed eseguire nuovamente la valutazione utilizzando le linee guida e il feedback aggiuntivi forniti dall'esperto di dominio.
Una volta verificato, possiamo ridistribuire la nostra app!
Cosa ci riserva il futuro?
Stiamo già lavorando alla nostra prossima generazione di funzionalità.
Innanzitutto, tramite un'integrazione con Agent Evaluation, Lakehouse Monitoring for GenAI, supporterà il monitoraggio in produzione delle prestazioni delle app GenAI (latenza, volume di richieste, errori) e delle metriche di qualità (accuratezza, correttezza, conformità). Utilizzando Lakehouse Monitoring for GenAI, gli sviluppatori possono:
- Tracciare le prestazioni operative e di qualità (latenza, volume di richieste, errori, ecc.).
- Eseguire valutazioni basate su LLM sul traffico di produzione per rilevare drift o regressioni
- Approfondire singole richieste per eseguire il debug e migliorare le risposte dell'agente.
- Trasformare i log del mondo reale in set di valutazione per guidare miglioramenti continui.
In secondo luogo, MLflow Tracing [Open Source | Databricks], basato sullo standard di settore Open Telemetry per l'osservabilità, supporterà la raccolta di dati di osservabilità (traccia) da qualsiasi app GenAI, anche se distribuita al di fuori di Databricks. Con poche righe di codice copia/incolla, puoi strumentare qualsiasi app o agente GenAI e far atterrare i dati di traccia nel tuo Lakehouse.
Se desideri provare queste funzionalità, contatta il tuo team di account.
Inizia
Che tu stia monitorando agenti AI in produzione, personalizzando la valutazione o semplificando la collaborazione con gli stakeholder aziendali, questi strumenti possono aiutarti a creare applicazioni GenAI più affidabili e di alta qualità.
Per iniziare, consulta la documentazione:
- Prova il notebook demo qui sopra
- Databricks MLflow App di revisione
- MLflow Tracing
- Databricks MLflow Metriche personalizzate
- Databricks MLflow Giudice delle linee guida
Guarda il video demo.
E dai un'occhiata alla Guida compatta agli agenti AI per scoprire come massimizzare il tuo ROI GenAI.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.