Presentazione delle funzionalità di federazione del lakehouse in Unity Catalog
Scopri, interroga e gestisci tutti i tuoi dati, indipendentemente da dove si trovino
di Matei Zaharia, Andrew Li, Can Efeoglu, Cyrielle Simeone, Sachin Thakur e Daniel Tenedorio
Lakehouse Federation è ora in anteprima pubblica!
I team di dati affrontano molte sfide per accedere rapidamente ai dati giusti, principalmente a causa della frammentazione dei dati, del tempo e dei costi necessari per consolidarli e delle difficoltà nella gestione della governance dei dati su più sistemi.
Ecco perché oggi, al Data+AI Summit, siamo entusiasti di annunciare le funzionalità di Lakehouse Federation in Unity Catalog, che consentono alle organizzazioni di creare un'architettura data mesh altamente scalabile e performante con una governance unificata.
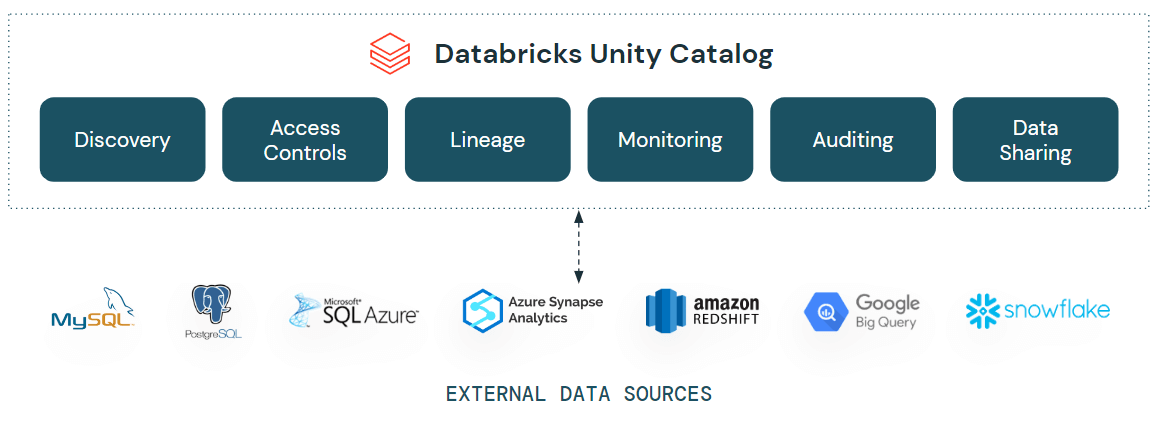
Unity Catalog fornisce una soluzione di governance unificata per dati e AI. Le funzionalità di Lakehouse Federation in Unity Catalog consentono di individuare, eseguire query e governare i dati su più piattaforme dati, tra cui MySQL, PostgreSQL, Amazon Redshift, Snowflake, Azure SQL Database, Azure Synapse, BigQuery di Google e altre ancora, dall'interno di Databricks senza spostare o copiare i dati, il tutto in un'esperienza semplificata e unificata. Ciò significa che le funzionalità di sicurezza avanzate di Unity Catalog, come i controlli degli accessi a livello di riga e colonna, le funzionalità di individuazione come i tag e la provenienza dei dati, saranno disponibili per queste sorgenti di dati esterne, garantendo una governance coerente.
"I data scientist e gli utenti aziendali possono ora accedere a diverse sorgenti di dati tramite un'interfaccia utente uniforme con autorizzazioni coerenti gestite in un unico posto", ha dichiarato Jelle de Jong, Tech Lead di Bayer. "Stiamo standardizzando continuamente il nostro formato dei dati in Delta Lake, ma siamo entusiasti che Lakehouse Federation ci abbia permesso di iterare con agilità prima di investire nell'estrazione dei dati."
La frammentazione dei dati rallenta l'innovazione
Migliaia di organizzazioni di ogni dimensione stanno innovando in tutto il mondo e in tutti i settori industriali con i dati e l'IA sulla Databricks Lakehouse Platform. Tuttavia, per ragioni storiche, organizzative o tecnologiche, i dati sono sparsi su numerosi sistemi operativi e analitici, causando ulteriori sfide:
- Difficoltà a individuare e accedere a tutti i dati: la maggior parte delle organizzazioni dispone di dati preziosi distribuiti su più sorgenti di dati. Potrebbe trovarsi in diversi database, un data warehouse, sistemi di object storage e altro ancora. Questo porta a dati e informazioni dettagliate incomplete, che impediscono ai clienti di prendere decisioni informate e di innovare più velocemente.
- Esecuzione lenta a causa di colli di bottiglia di ingegneria: per eseguire query sui dati su più sorgenti di dati, i clienti devono in genere spostare prima i dati dalle sorgenti di dati esterne alla piattaforma prescelta. Per alcuni dati, potrebbe non valerne la pena. Alcuni dati impiegano troppo tempo per arrivare in un'unica posizione unificata, rallentando l'innovazione.
- Scarsa conformità tra sistemi a silo: una governance frammentata porta alla duplicazione degli sforzi e aumenta il rischio di non poter monitorare e proteggersi da accessi inappropriati o fughe di dati, il che ostacola la collaborazione e la democratizzazione dei dati.
Unifica il tuo patrimonio di dati con Lakehouse Federation in Unity Catalog
Lakehouse Federation risolve queste criticità e semplifica per le organizzazioni l'esposizione, la query e la governance di sistemi di dati isolati come estensione del loro lakehouse. Con queste nuove funzionalità è possibile:
- Crea una vista unificata del tuo data estate: classifica e individua automaticamente tutti i tuoi dati, strutturati e non strutturati, in un unico posto e consenti a tutti i membri della tua organizzazione di accedere ed esplorare in modo sicuro tutti i dati a loro disposizione, indipendentemente da dove si trovino.
- Eseguire query e combinare tutti i dati in modo efficiente con un unico motore: accelera l'analisi ad hoc e la prototipazione per tutti i tuoi casi d'uso relativi a dati, analitiche e IA sui dati più completi, senza necessità di acquisizione e con un unico motore. La pianificazione avanzata delle query tra le fonti e la memorizzazione nella cache garantiscono prestazioni ottimali delle query anche quando si accede e si combinano dati da più piattaforme con un'unica query.
- Protezione dei dati su più sorgenti di dati: usa un unico modello di autorizzazione per impostare e applicare regole di accesso e proteggere tutti i tuoi dati su più sorgenti di dati. Applica regole come la sicurezza a livello di riga e colonna e i criteri basati su tag, centralizza l'auditing in modo coerente tra le piattaforme, monitora l'utilizzo dei dati e soddisfa i requisiti di conformità grazie a provenienza dei dati e auditability integrati.
“La Lakehouse Federation ci permette di combinare dati, come quelli sull'utilizzo, sulle vendite e sulla telemetria di gioco, provenienti da più fonti e su più cloud, e di visualizzarli e interrogarli tutti da un unico posto. Ora lasciamo i dati nella sorgente di dati originale, ma possiamo utilizzarli dalla Lakehouse di Databricks", ha dichiarato Felix Baker, Head of Data Services di SEGA Europe. "Dato che non dobbiamo più spostare i nostri dati finanziari, che vengono aggiornati di frequente, risparmiamo tempo prezioso da dedicare a offrire ai nostri consumatori la migliore esperienza di gioco possibile”.
"La Lakehouse Federation ci ha permesso di procedere più rapidamente al consolidamento del nostro attuale panorama di dati in Unity Catalog. "Questo semplifica la governance dei dati di Shell: più set di dati diventano individuabili in un unico posto, l'autenticazione è standardizzata e diventa possibile eseguire query tra set di dati con un linguaggio di programmazione comune", ha affermato Bryce Bartmann, Chief Advisor per la Tecnologia Digitale di Shell. "In definitiva, ci rende più efficaci nell'affrontare la trasformazione in atto oggi nel settore energetico."
Queste nuove funzionalità, unite alla interfaccia Hive aperta annunciata di recente, consentono alle organizzazioni di centralizzare la gestione dei dati, l'individuazione e la governance in Unity Catalog e di connettersi a esso da un'ampia gamma di piattaforme di elaborazione, tra cui Amazon EMR, Apache Spark, Amazon Athena, Presto, Trino e altre. La nuova interfaccia elimina la necessità di mantenere più Data Catalog e garantisce una governance dei dati coerente su queste piattaforme.
E ora?
Queste funzionalità sono attualmente in anteprima pubblica, così puoi iniziare subito!
Stiamo inoltre estendendo le funzionalità di governance di Unity Catalog a vari formati di archiviazione aperti, tra cui Apache Iceberg e Hudi, con la public preview del Delta Universal Format ("UniForm"). Questa integrazione consente di leggere le tabelle Delta come se fossero tabelle Iceberg (e presto anche Apache Hudi), rendendo Unity Catalog l'unico catalogo universale che supporta tutti e tre i principali formati di archiviazione aperti per lakehouse.
Infine, in futuro, sarà anche possibile eseguire il push delle policy di accesso definite in Unity Catalog alle sorgenti di dati federate per un'applicazione coerente ovunque si acceda ai dati. Questo elimina la necessità di gestire definizioni di policy ridondanti su diversi strumenti di governance.
Guarda il keynote del Data+AI Summit 2023 di Matei Zaharia, co-fondatore e Chief Technology Officer di Databricks, per saperne di più.
Registrati al Data + AI Summit qui per partecipare di persona o virtualmente e scoprire le ultime novità in materia di dati, analitiche e IA!
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.