Introduzione a Spatial SQL in Databricks: oltre 80 funzioni per analisi geospaziali ad alte prestazioni
Il miglior "magazzino" di dati è un lakehouse
di Kent Marten e Michael Johns
- Accelera le tue query geospaziali scalate con oltre 80 funzioni Spatial SQL, ora disponibili in anteprima pubblica.
- Archivia senza problemi dati planari e geodetici utilizzando i tipi di dati nativi GEOMETRY e GEOGRAPHY.
- Migliora la tua analisi spaziale con join spaziali ad alte prestazioni e dimentica l'indicizzazione manuale.
Ogni giorno, miliardi di punti dati sono legati a luoghi sulla mappa. Percorsi di consegna, visite ai negozi, reti stradali, torri cellulari e campi coltivati, tutti portano un contesto importante per prendere decisioni aziendali. Il problema è che analizzare questi dati su larga scala è stato difficile. I sistemi spaziali legacy sono lenti, richiedono indicizzazione manuale e spesso bloccano le informazioni in formati proprietari.
Oggi introduciamo Spatial SQL in Databricks. Spatial SQL porta l'analisi geospaziale direttamente sulla Databricks Platform. Ora puoi lavorare con i tipi di dati nativi GEOMETRY e GEOGRAPHY, utilizzare più di 80 funzioni SQL ed eseguire join spaziali ad alta velocità e prestazioni, il tutto mantenendo i tuoi dati aperti e pronti per la scalabilità.
I dati di localizzazione giocano un ruolo in quasi tutti i settori e Spatial SQL rende più facile utilizzare tali informazioni.
Ecco alcuni esempi:
- Le operazioni di vendita al dettaglio possono comprendere da dove provengono i loro clienti analizzando aree e traffico pedonale
- Gli analisti dei trasporti possono migliorare la sicurezza e l'esperienza del cliente analizzando incidenti stradali e connettività della rete cellulare
- Le società energetiche possono ottimizzare il dispiegamento delle squadre durante le interruzioni e trovare luoghi ideali per localizzare parchi eolici e solari
- Gli operatori agricoli possono applicare tecniche di agricoltura di precisione per ridurre i costi e migliorare l'efficienza della resa
- Gli analisti assicurativi possono comprendere il rischio analizzando gli indirizzi degli assicurati nelle zone di inondazione, incendi e uragani
- Le organizzazioni sanitarie possono confrontare e prevedere gli esiti sanitari analizzando i fattori ambientali attraverso le geografie
- E molto altro ancora!
Spatial SQL sta già aiutando i clienti ad accelerare le prestazioni e a ridurre i costi:
“Databricks Spatial SQL ha ridefinito il modo in cui eseguiamo join spaziali su larga scala. Integrando le funzioni Spatial SQL nelle nostre pipeline di elaborazione, abbiamo visto prestazioni oltre 20 volte più veloci e costi inferiori di oltre il 50% sugli stessi carichi di lavoro. Questa svolta rende possibile integrare e fornire dati ricchi di reti stradali a una scala e velocità che semplicemente non erano possibili prima.”
– Laxmi Duddu, Sr. Manager, Autonomy Data Platform & Analytics, Rivian Automotive
I clienti hanno precedentemente faticato a gestire e scalare i carichi di lavoro spaziali con sistemi legacy, librerie di terze parti o ricorrendo a strategie di indicizzazione manuale. Con Spatial SQL, i clienti ottengono semplicità e scalabilità pronte all'uso.
“Spatial SQL ci consente di scalare l'ETL geospaziale come mai prima d'ora. Invece di sovraccaricare i server PostGIS con query pesanti, spostiamo il carico su Databricks e sfruttiamo l'elaborazione distribuita, i join spaziali veloci e la gestione efficiente dei dati vettoriali. È un approccio più efficiente, resiliente e scalabile per la gestione di set di dati geospaziali grandi e complessi.”
— Pierre Chenaux, Tech Leader of Geospatial department, TotalEnergies
Un importante fattore di prestazioni è il supporto per i tipi di dati geospaziali di prima classe. Invece di archiviare dati geo in colonne stringa, binarie o decimali, ora puoi utilizzare i tipi di dati nativi GEOMETRY e GEOGRAPHY. Questi tipi includono statistiche di bounding box che Databricks utilizza durante l'esecuzione delle query per saltare dati irrilevanti e velocizzare i join. Spatial SQL fornisce anche funzioni di importazione per formati standard come Well Known Text, Well Known Binary, GeoJSON e semplici valori di latitudine o longitudine.
Questi tipi di dati sono completamente aperti in Parquet, Iceberg e Delta. Il team Databricks ha contribuito a definire le specifiche proposte, garantendo che non ci sia alcun blocco con magazzini proprietari. Con la SPIP Apache Spark™ approvata, GEOMETRY e GEOGRAPHY saranno presto tipi di dati di prima classe anche nel motore open source.
Cosa puoi fare con Spatial SQL?
Spatial SQL è più di un insieme di nuove funzioni. Ti fornisce gli elementi costitutivi per gestire l'intero percorso dei dati spaziali, dall'archiviazione e importazione all'analisi e trasformazione. Lavorando con tipi di dati nativi e operazioni efficienti, puoi integrare la localizzazione nelle query quotidiane senza aggiungere complessità.
Ecco alcune delle cose principali che puoi fare:
- Archiviare dati spaziali nativamente con GEOMETRY e GEOGRAPHY
- Importare ed esportare in formati come WKT, WKB, GeoJSON e GeoHash
- Creare nuovi oggetti con costruttori come ST_Point o ST_MakeLine
- Calcolare misurazioni utilizzando funzioni come ST_Distance e ST_AREA
- Eseguire join spaziali utilizzando relazioni come ST_Contains e ST_Intersects
- Trasformare tra sistemi di coordinate con ST_Transform
- Modificare, convalidare e combinare oggetti spaziali utilizzando ST_ISVALID o ST_UNION_AGG
- E molto altro ancora!
Queste funzionalità ti offrono un toolkit completo per l'analisi spaziale direttamente in SQL, disponibile anche con API Python e Scala. Quando le metti insieme, sbloccano flussi di lavoro reali che contano nella pratica, che illustreremo nella prossima sezione.
Esempi di Spatial SQL in pratica
I dati geospaziali sono ovunque e in crescita. Tracce GPS con latitudini e longitudini vengono emesse da un numero crescente di dispositivi, sensori e veicoli ogni secondo del giorno. Il mondo viene catalogato e aggiornato costantemente, con luoghi, strade, reti e confini modellati come punti, linee e poligoni. In tutti i settori – vendita al dettaglio, trasporti e logistica, energia, clima e scienze naturali, agricoltura, settore pubblico, servizi finanziari, immobiliare, assicurazioni, telecomunicazioni – la localizzazione è importante per ogni decisore che ha bisogno di comprendere il “dove” nei propri dati.
Abbiamo preparato quattro brevi esempi per iniziare a lavorare con i nuovi tipi di dati ed espressioni spaziali con i seguenti obiettivi.
- Preparare i dati per un'elaborazione efficiente utilizzando il nuovo tipo GEOMETRY
- Eseguire l'arricchimento dei dati combinando due set di dati spaziali utilizzando un join spaziale
- Trasformare i dati in un sistema di riferimento spaziale appropriato per migliorare l'accuratezza delle misurazioni di distanza
- Misurare la distanza tra due città
In questi esempi, utilizzeremo set di dati di indirizzi, edifici e divisioni da OvertureMaps.org. Questi set di dati sono offerti per il download in vari modi, come GeoParquet.
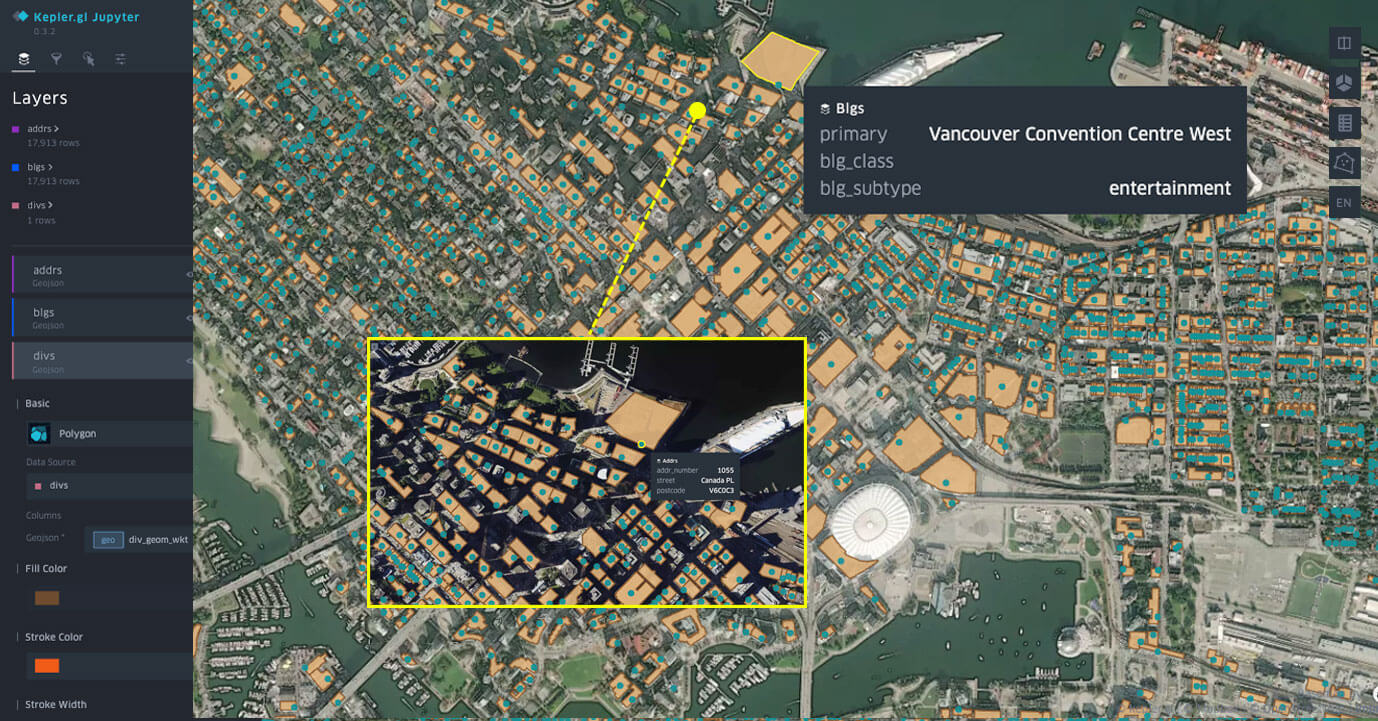
Set di dati Overture Maps visualizzati in Databricks Notebook con kepler.gl.
1. Creazione di una colonna GEOMETRY
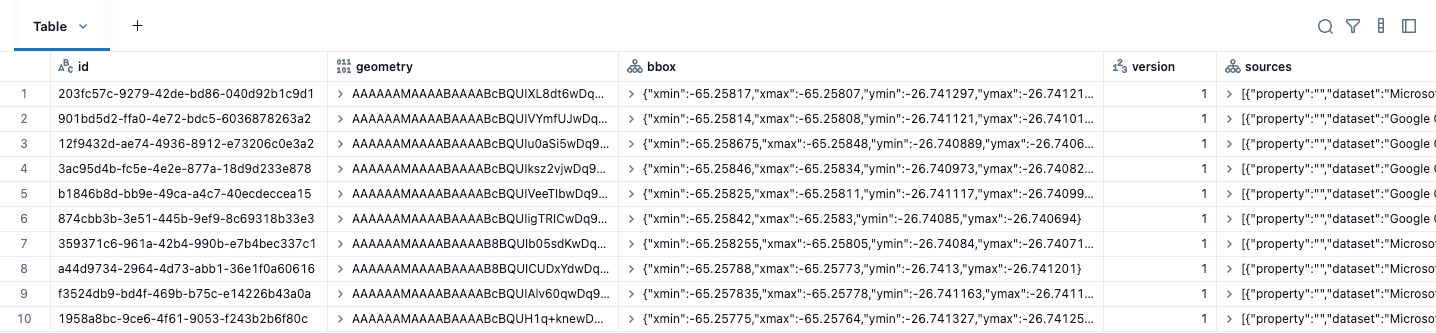
Il primo passo prima di eseguire qualsiasi analisi spaziale è convertire i tuoi dati per utilizzare i tipi di dati GEOMETRY o GEOGRAPHY. Dopo aver scaricato i dati di Overture Maps, dobbiamo semplicemente creare una colonna GEOMETRY nativa dalla colonna di geometria WKB fornita e rimuovere altre colonne non necessarie come bbox. Un bounding box è il rettangolo più piccolo che contiene una geometria. Nelle query spaziali, i bounding box velocizzano le query scartando rapidamente i dati che non possono sovrapporsi. Se due bounding box non si intersecano, le geometrie al loro interno sicuramente non lo fanno, quindi il database può saltare il costoso controllo di intersezione e ridurre la quantità di dati elaborati. Non abbiamo bisogno del campo bbox perché queste informazioni sono ora gestite nelle statistiche delle colonne. Per questi set di dati, gli indirizzi sono PUNTI, mentre edifici e divisioni sono POLIGONI / MULTI-POLIGONI. Ecco i dati degli edifici inizialmente scaricati, che mostrano le prime cinque colonne.
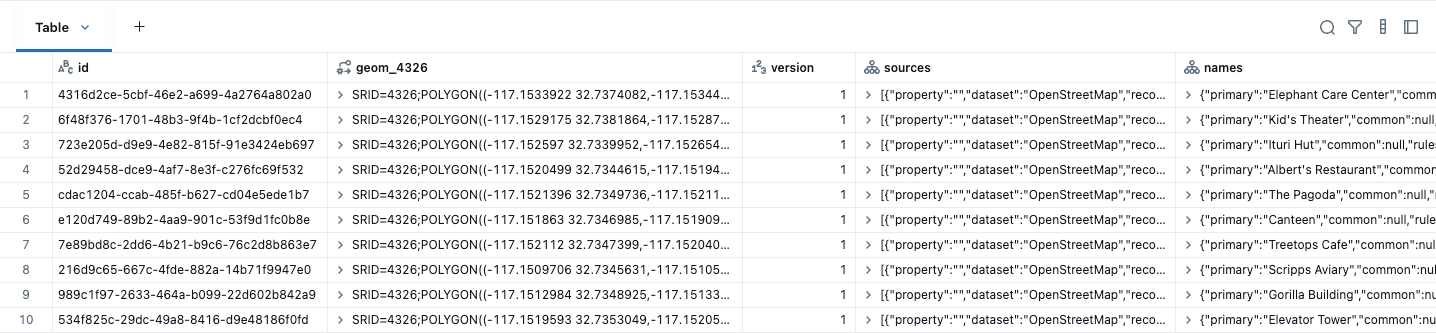
Questi dati possono essere facilmente convertiti in una tabella Lakehouse con GEOMETRY nativa utilizzando ST_GeomFromWKB, mostrato nell'esempio seguente per gli edifici. Sappiamo che i nostri dati sono in WGS84 (EPSG:4326), quindi lo specifichiamo nella creazione del tipo spaziale. Un SRID identifica il sistema di coordinate dei tuoi dati spaziali, che definisce le unità (come gradi o metri) utilizzate nei calcoli come distanza e area. Devi impostare un SRID valido quando crei una colonna di geometria, altrimenti la query restituirà un errore. Nota anche che i nostri tipi nativi vengono visualizzati in un formato di facile comprensione (EWKT).
Oltre a WKB, i dati spaziali possono anche essere importati direttamente nei nostri tipi nativi dai formati di interscambio più comuni:
- Coordinate di latitudine e longitudine utilizzando ST_POINT
- WKT utilizzando ST_GeomFromWKT o ST_GeomFromText
- WKB utilizzando ST_GeomFromWKB o ST_GeomFromBinary
- GeoJSON utilizzando ST_GeomFromGeoJSON
- GeoHash utilizzando ST_PointFromGeoHash
Analogamente, i dati spaziali possono essere esportati come una serie di formati:
- WKT utilizzando ST_AsWKT o ST_AsText
- WKB utilizzando ST_AsWKB o ST_AsBinary
- GeoJSON utilizzando ST_AsGeoJSON
- WKT esteso utilizzando ST_AsEWKT
- WKB esteso utilizzando ST_AsEWKB
- GeoHash utilizzando ST_GeoHash
Nota: abbiamo anche espressioni di importazione ed esportazione per i tipi GEOGRAPHY.
2. Unione spaziale di più dataset
Le unioni spaziali sono tra le operazioni più importanti e ampiamente utilizzate nell'elaborazione di dati geospaziali. Consentono di combinare attributi da diversi dataset ed eseguire aggregazioni o arricchimento dei dati in base alle loro relazioni spaziali, come contenimento, intersezione e prossimità. Ciò rende le unioni spaziali essenziali per rispondere a domande del mondo reale come identificare quali edifici rientrano in una zona alluvionabile, assegnare dati demografici del censimento agli indirizzi dei clienti e analizzare veicoli connessi all'interno delle aree di copertura cellulare. Poiché gran parte dell'analisi geospaziale dipende dall'integrazione di più dataset, le unioni spaziali sono spesso un primo passo nell'analisi spaziale esplorativa, nella modellazione spaziale e nel processo decisionale basato sulla posizione.
Successivamente, uniremo le tabelle degli indirizzi e delle divisioni utilizzando un'unione spaziale. Chiunque abbia lavorato con fonti di dati di indirizzi sa che gli indirizzi possono essere dati disordinati (una causa comune è che paesi diversi utilizzano sistemi di indirizzi diversi). Inoltre, la tabella degli indirizzi non include una gerarchia amministrativa completa (ad es. nessuna informazione sulla contea per gli indirizzi USA). Quindi utilizzeremo la tabella delle divisioni per convalidare le informazioni sulla città e arricchirla aggiungendo informazioni equivalenti alla contea.
Questo processo di convalida e arricchimento dei dati sarebbe diverso da risolvere senza un'unione spaziale. Per fare ciò, dobbiamo trovare l'indirizzo all'interno della divisione. Utilizzeremo ST_Contains per eseguire un'unione spaziale punto-in-poligono, lasciando che Databricks gestisca gli interni dell'operazione, senza necessità di indicizzazione spaziale fai-da-te.
Ora possiamo standardizzare più facilmente alla città, stato, contea e paese corretti, ad es. sostituire le città mancanti negli indirizzi con quelle fornite nella tabella delle divisioni.
Dopo aver convalidato gli indirizzi, abbiamo seguito un approccio simile per unire gli indirizzi agli edifici utilizzando ST_Intersects per arricchire la tabella Buildings con informazioni sugli indirizzi. Per gli Stati Uniti, questa unione spaziale ha abbinato 44 milioni di indirizzi a edifici, con 55 milioni di edifici rimasti non abbinati. Nel prossimo esempio, vediamo come possiamo utilizzare la prossimità per identificare potenzialmente edifici che non sono stati abbinati a un indirizzo.
3. Trasformazione dei dati in specifici sistemi di riferimento spaziale
I dataset geospaziali vengono spesso creati in diversi sistemi di riferimento delle coordinate (CRS), come latitudine-longitudine (WGS84) o sistemi proiettati come UTM, a seconda della loro origine e scopo. Mentre ogni CRS definisce come la superficie curva della terra è rappresentata su una mappa piana, l'utilizzo di dataset con proiezioni non corrispondenti può causare disallineamento delle caratteristiche, distorsione delle distanze o produrre unioni spaziali e misurazioni errate. Un negozio situato in una zona alluvionabile non corrisponderà in un'unione spaziale se si utilizzano sistemi di coordinate diversi. Per un'analisi accurata, sia che si calcolino aree, si uniscano layer o si visualizzino relazioni spaziali, è essenziale garantire che tutti i dataset vengano trasformati nella stessa proiezione in modo che condividano un riferimento spaziale coerente.
Per identificare gli indirizzi entro la prossimità dei restanti 55 milioni di edifici non abbinati negli Stati Uniti, proiettiamo i nostri dati GEOMETRY WGS84 a Conus Albers (EPSG:5070) per il Nord America, che ci fornisce unità in metri. Ciò si ottiene con la funzione ST_Transform.
Applichiamo ST_DWithin tra i nostri edifici e indirizzi USA non abbinati, utilizzando un valore di distanza entro di soli 2 metri.
Il valore di distanza entro può essere aumentato secondo necessità per raccogliere un set di potenziali corrispondenze di indirizzi; inoltre, un CTE ricorsivo può essere utile per iterare su più distanze. Per questo esempio, un poligono di filtro ci consente di isolare facilmente la nostra ricerca nelle vicinanze di Saint Petersburg, Florida. Il poligono viene inizialmente preparato da WKT utilizzando ST_GeomFromWKT, quindi trasformato in SRID 5070 per corrispondere ai dati di indirizzi ed edifici.
Per impostare i dataset per il CTE ricorsivo, applichiamo un filtro spaziale sui nostri dati intersecando edifici e indirizzi con il poligono di ricerca, mostrando gli edifici sottostanti (gli indirizzi vengono gestiti in modo simile).
Il CTE ricorsivo sottostante itera sugli edifici per identificare candidati indirizzi entro 5, 10 e 15 metri. La tabella dei risultati rimuove gli indirizzi duplicati su distanze successive utilizzando la seguente espressione di finestra: QUALIFY RANK() OVER (PARTITION BY blg_id,addr_id ORDER BY dwithin) = 1.
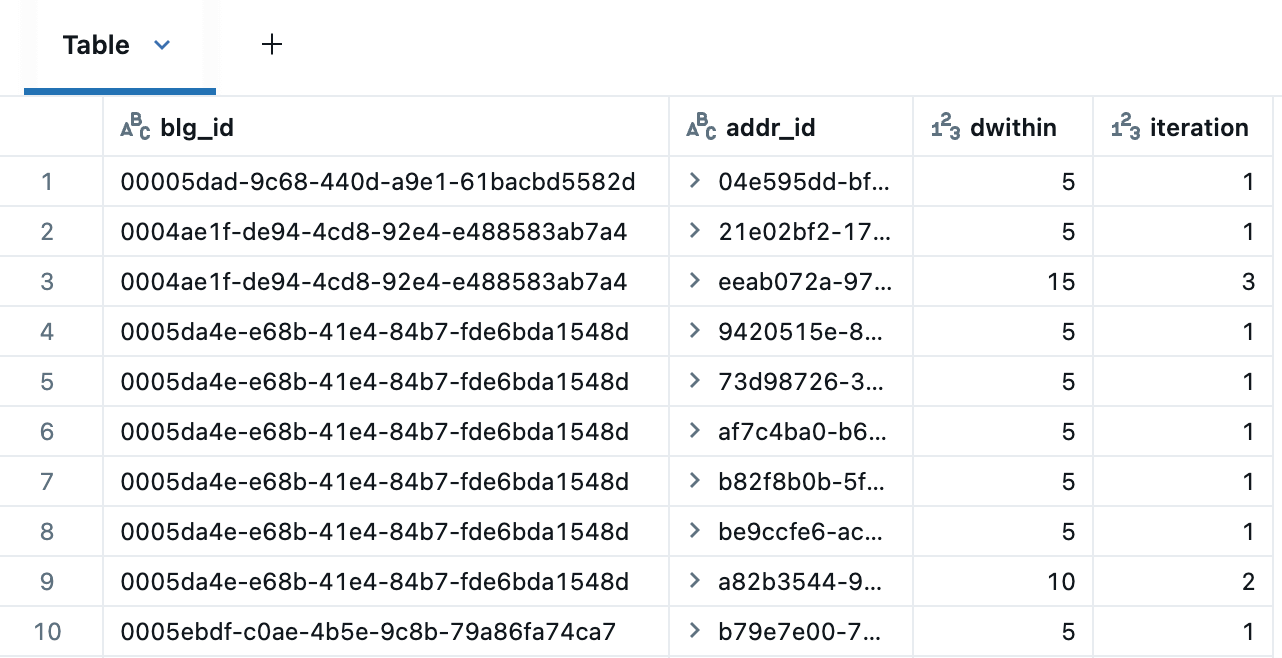
Ecco i candidati di indirizzo attorno a uno degli edifici, che mostrano corrispondenze a 5m (blu), 10m (arancione) e 15m (verde). Questo viene renderizzato utilizzando le Mappe a Marcatori integrate di Databricks in modalità di clustering, che espanderanno i punti vicini per una più facile visualizzazione. Creando una Dashboard, potremmo anche aver utilizzato le Mappe a Punti AI/BI, che supportano il cross-filtering e il drill-through.
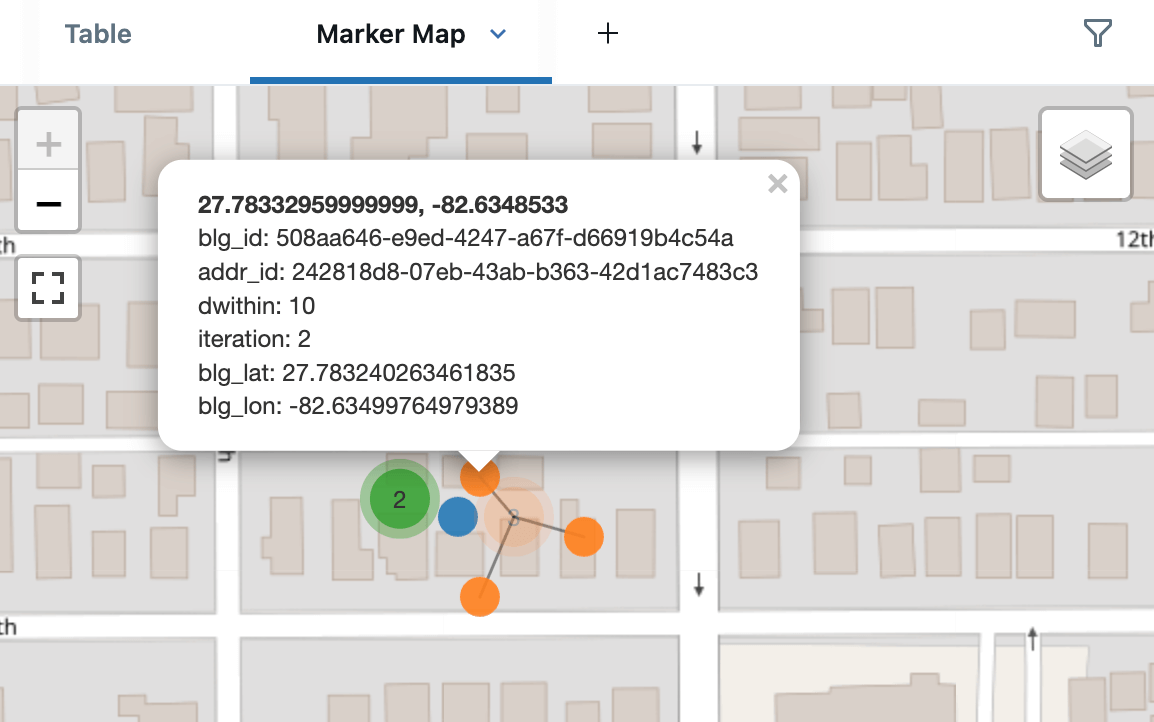
Ci sono numerosi usi alternativi delle CTE Ricorsive per l'elaborazione spaziale, ad esempio, l'implementazione dell'algoritmo di Prim per costruire un albero ricoprente minimo dei tuoi punti di consegna.
4. Misurazione delle distanze tra le località
La prossimità è un concetto fondamentale nell'analisi spaziale perché la distanza determina spesso la forza o la rilevanza delle relazioni tra le località. Sia che si identifichi l'ospedale più vicino, si analizzino le concorrenze tra negozi o si mappino i modelli di pendolarismo, comprendere quanto siano vicine le caratteristiche l'una all'altra fornisce un contesto critico.
Continuando con il nostro set di dati di esempio, abbiamo eseguito la stessa operazione di trasformazione Conus Albers sulle nostre città in Florida per misurarne le distanze. Stiamo misurando dal centro geometrico delle città, generato utilizzando la funzione: ST_Centroid.
Quando si calcola la distanza tra due GEOMETRIE, ci sono diverse funzioni da considerare:
- ST_Distance - Restituisce la distanza cartesiana nelle unità delle GEOMETRIE fornite, calcolando il percorso in linea retta basato sulle loro coordinate x e y, come se la Terra fosse piatta.
- ST_DistanceSphere - Restituisce la distanza sferica (sempre in metri) tra due GEOMETRIE puntuali, misurata sul raggio medio dell'ellissoide WGS84 della Terra, con punti di coordinate che si presume abbiano unità di gradi, ad esempio, SRID 4326 sarebbe valido ma non SRID 5070.
- ST_DistanceSpheroid - Restituisce la distanza geodetica (sempre in metri) tra due GEOMETRIE puntuali sull'ellissoide WGS84 della Terra; inoltre, con punti di coordinate che si presume abbiano unità di gradi. Ancora una volta, SRID 4326, o qualsiasi altro SRID con unità in gradi, sarebbero input validi per questo esempio.
I vari calcoli di distanza vengono applicati tra city1 e city2 con ST_Distance utilizzata per le GEOMETRIE in 5070, quindi ST_DistanceSphere e ST_DistanceSpheroid per le GEOMETRIE in 4326.
Tra le funzioni di distanza, ci aspetteremmo che ST_DistanceSpheriod (misurazioni basate sulla forma ellissoidale della Terra) sia la più accurata in questo caso, seguita da ST_DistanceSphere (le misurazioni assumono che la Terra sia una sfera perfetta). Si noti che ST_Distance è più utile quando si lavora su sistemi di riferimento di coordinate proiettati o quando la curvatura terrestre può essere altrimenti ignorata. Anche se SRID 5070 è in metri, possiamo vedere gli effetti dei calcoli cartesiani su distanze maggiori. ST_Distance generalmente non sarebbe una scelta adatta per SRID 4326, dato che la distanza coperta da un grado di longitudine cambia drasticamente man mano che ci si sposta dall'equatore verso i poli, ad esempio, 1 grado di longitudine differisce fino a 6 km solo all'interno dello stato della Florida.
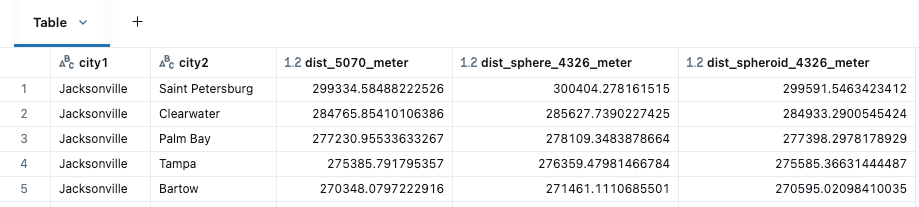
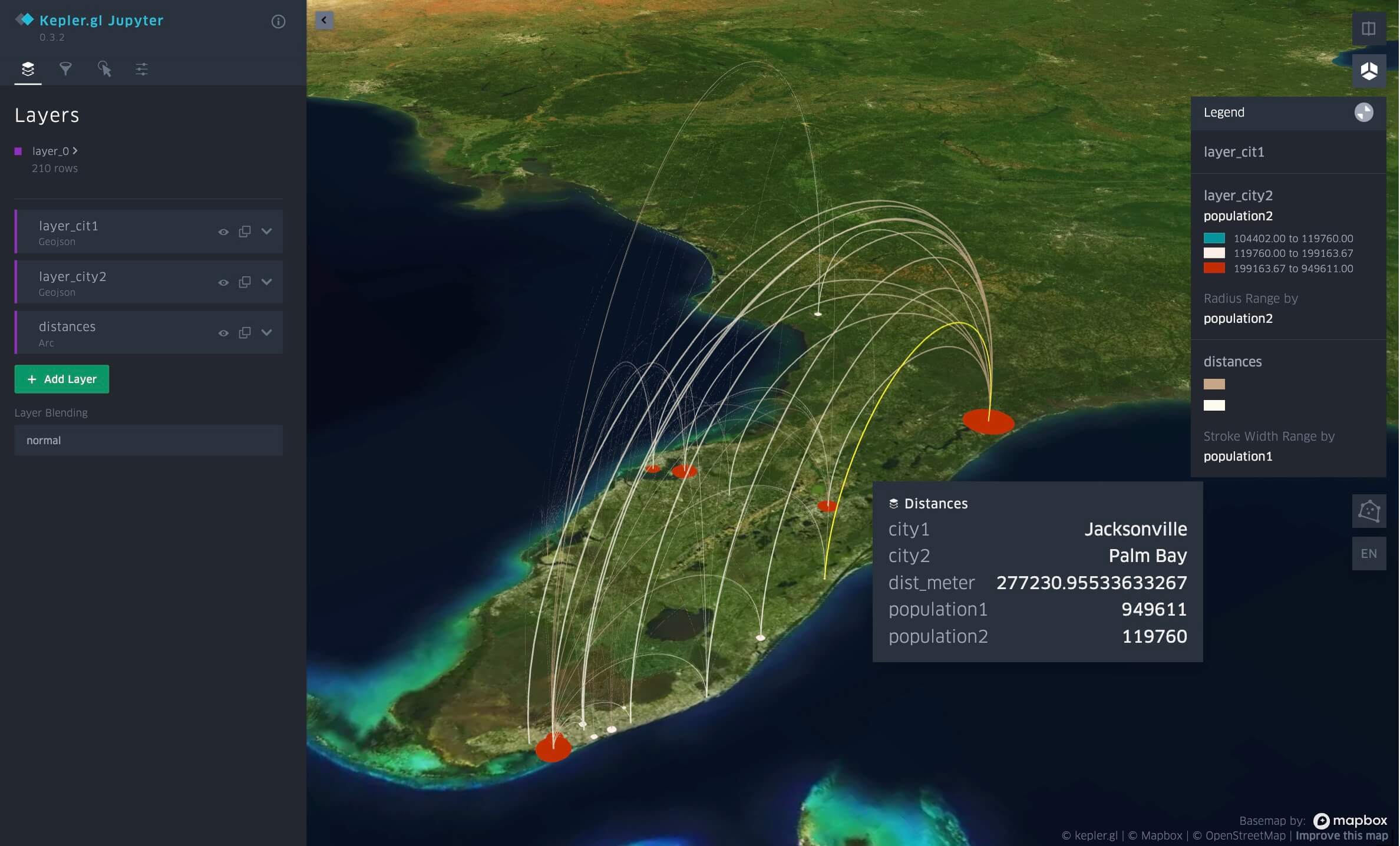
Prossimità per distanza tra città della Florida, visualizzata in Databricks Notebook con kepler.gl.
Spatial SQL include oltre 80 funzioni, che consentono ai clienti di eseguire operazioni comuni sui dati spaziali con semplicità e scalabilità. Grazie a Spatial SQL, i clienti stanno iniziando a cambiare il loro approccio alla gestione e all'integrazione con i sistemi GIS:
“I dati spaziali sono al centro di tutto ciò che facciamo in OSPRI, che si tratti di tracciabilità del bestiame, eradicazione delle malattie o gestione dei parassiti. Databricks Spatial SQL ci consente di integrare completamente Databricks con tutto il nostro lavoro. Questi progressi ci consentono di spostare grandi attività di modellazione spaziale basate su desktop su una piattaforma in cui sono più vicine ai dati e possono essere eseguite in parallelo, ad alta velocità. Settimane di iterazioni tra i confini operativi possono essere comodamente eseguite in uno o due giorni, riducendo il nostro tempo decisionale. Queste nuove funzioni ci consentono inoltre di rendere Databricks il livello di integrazione tra i nostri sistemi transazionali e la nostra piattaforma GIS, garantendo che possa essere informata dai dati di tutta l'organizzazione senza compromessi.” - Campbell Fleury, Manager, Data and Information Products, OSPRI New Zealand
Cosa c'è dopo
C'è così tanto che puoi fare con Spatial SQL in Databricks, con altro in arrivo, incluse nuove espressioni e join spaziali più veloci. Se desideri condividere quali espressioni ST aggiuntive richiedi, compila questo breve sondaggio.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.