Dai slancio alla modellazione dei dati con i modelli di dati di settore di Databricks
Modelli di dati predefiniti, convalidati da regole e pronti per il livello Silver per i 40 settori più grandi al mondo, pronti per essere distribuiti e governati sulla piattaforma Databricks.
- Oltre 40 modelli di dati di settore, pronti oggi. Modelli del livello Silver predefiniti e convalidati da regole per 40 settori, in due ambiti (MVM e ECM): distribuisci così come sono o personalizzali.
- Un set completo e governato di artefatti. Viene fornito come un unico file model.json (oltre a SQL DDL, DBML, ontologia) che si distribuisce su Unity Catalog con tabelle Delta, chiavi esterne, tag di classificazione e viste metriche.
- Distribuisci in poche ore. Indirizza model.json verso un Unity Catalog, scegli uno stile di catalogazione e ottieni un livello Silver classificato e validato tramite FK.
Il problema dei modelli di dati di settore
Da tre decenni, ai settori regolamentati e ad alta intensità di dati viene venduta la stessa scorciatoia: acquistare un modello di dati di settore. ACORD per le assicurazioni. FHIR e HL7 per la sanità. ARTS per il retail. Centinaia, a volte migliaia, di tabelle pubblicate da un organismo di standardizzazione o da un fornitore, presentate come un anno di lavoro racchiuso in una singola licenza.
La proposta è interessante, ma la realtà è ben più dolorosa. Un modello di dati di settore rappresenta la media di ogni azienda di quel comparto. Non conosce le tue linee di prodotto, le tue aree geografiche, i tuoi vincoli normativi, i tuoi sistemi legacy, le tue convenzioni di denominazione o la struttura della tua organizzazione: non sa cosa differenzia la tua attività. I team si ritrovano con centinaia di tabelle che non popoleranno mai, convenzioni di denominazione che non corrispondono alla loro terminologia e direzioni delle relazioni di cui i loro carichi di lavoro non hanno bisogno. Gran parte del valore dell'acquisto di un modello viene speso per ridurlo, rinominarlo e ricollegarlo, ovvero esattamente il lavoro che il modello avrebbe dovuto evitare.
Un modello di dati analitico solido, di quelli che gestiscono effettivamente l'analisi in produzione e il ML, ha storicamente richiesto da mesi a anni per essere creato.
Noi stiamo pubblicando qualcosa di diverso. Una libreria di modelli di dati di settore predefiniti per Lakehouse, disponibile oggi in un repository pubblico, pronta per essere distribuita come livello Silver del tuo ambiente Databricks per i 40 settori più grandi al mondo. Ogni modello di dati di settore viene fornito in due ambiti ed è basato su un rigoroso set di regole strutturali che comprende oltre 200 regole in 14 diversi domini di modellazione, rendendo l'output pronto per la produzione fin dal primo giorno. La buona notizia è che non si tratta di modelli rigidi o fissi: hai tutti gli strumenti per evolverli e personalizzarli in base alle esigenze della tua organizzazione.
Dove si collocano questi modelli di dati nel Lakehouse
In un'architettura medaglione di Databricks, il livello Bronze contiene i dati grezzi, il livello Silver contiene il modello analitico di base standardizzato da cui leggono analisti, strumenti di BI e data scientist, mentre il livello Gold contiene metriche derivate, KPI e aggregati.
Questi modelli di dati di base sono il livello Silver. Lakeflow e Auto Loader gestiscono l'ingestione. Ogni modello viene fornito con metriche precalcolate come churn_score o monthly_revenue_summary. Il modello di base è la fondazione analitica: il luogo in cui i concetti aziendali diventano tabelle affidabili, pronte per strumenti di BI, pipeline di feature e aggregati a valle.
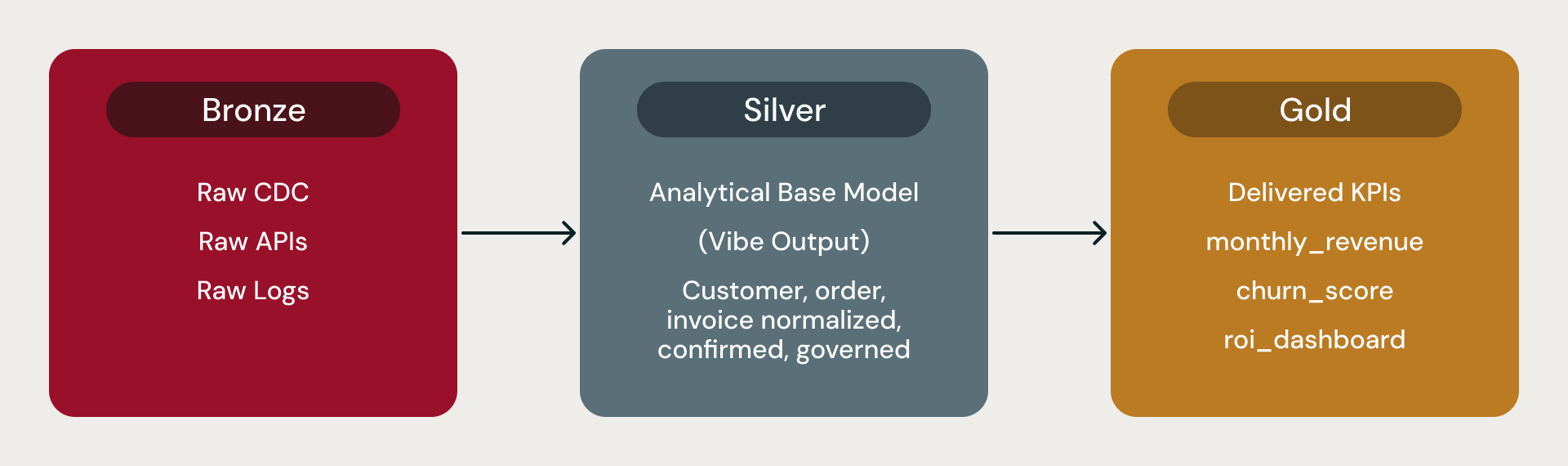
Bronze, Silver, Gold
Due ambiti: MVM e ECM
Ogni modello di base è pubblicato in due ambiti. Entrambi vengono distribuiti a partire dallo stesso file logico model.json; entrambi seguono le stesse regole; entrambi hanno la stessa profondità di attributi per tabella. La differenza sta nell'ampiezza.
Minimum Viable Model (MVM). Dal trenta al cinquanta percento del numero di tabelle di un ECM. Solo funzioni aziendali essenziali. Ideale per le SMBs, distribuzioni rapide, proof of concept e MVPs. Un MVM non è uno scheletro o un giocattolo dimostrativo: ogni tabella ha la stessa ricchezza di attributi della controparte ECM. La leggerezza deriva da un numero inferiore di domini e tabelle, mai da tabelle più povere.
Expanded Coverage Model (ECM). Copertura completa. Tutte le divisioni, incluso il back office aziendale. Tutti i domini che ci si aspetterebbe da un modello Fortune 100. Massima ampiezza.
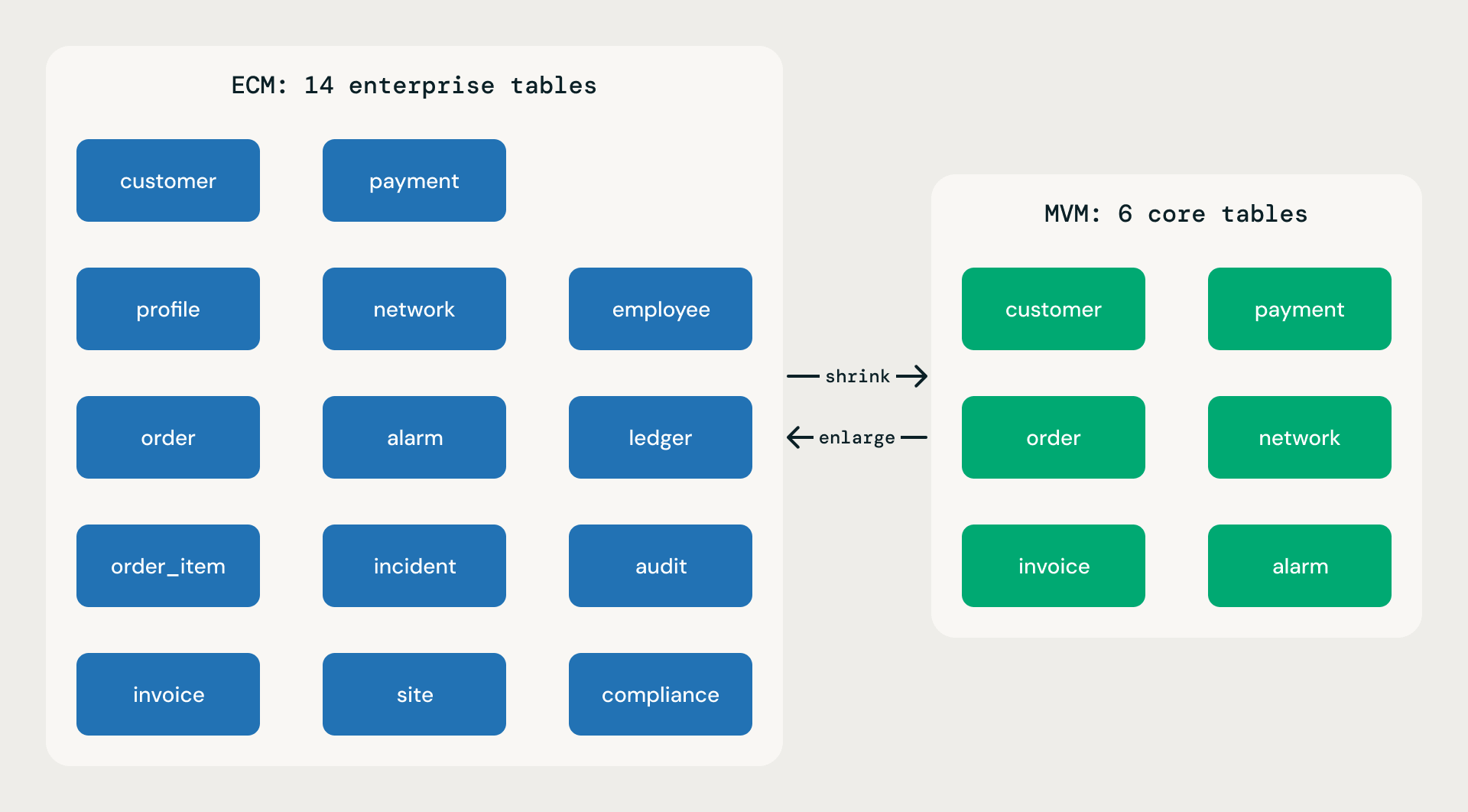
Ambito MVM vs ECM
Perché entrambi gli ambiti sono importanti? L'obiettivo non è far perdere tempo alle organizzazioni per adattare il modello ai propri dati aziendali, ma piuttosto iniziare rapidamente con l'analisi sul Lakehouse, quindi partire con l'ambito giusto significa già risparmiare tempo.
I due ambiti non sono linee di manutenzione separate. Ciascuno può essere derivato dall'altro attraverso una singola trasformazione: shrink ecm produce un sottoinsieme MVM che protegge i prodotti principali e mantiene le chiavi esterne essenziali; enlarge mvm fa il contrario. Nessuna versione viene mai sovrascritta: entrambe le operazioni creano una nuova versione numerata accanto a quella originale.
Cosa rende diversi questi modelli
I modelli di base che stiamo pubblicando non sono semplici modelli di settore standard rinominati. Sono prodotti da un agente IA disciplinato e guidato da regole che impone la qualità strutturale in ogni fase di modellazione. Ecco alcuni punti salienti:
Dimensionamento a livelli di settore. Ogni modello è dimensionato in base alla complessità effettiva del suo settore. Il classificatore utilizza sette dimensioni (densità normativa, complessità delle parti, profondità della gerarchia dei prodotti, gestione dell'infrastruttura, modello canonico di settore, complessità delle transazioni e panorama dei sistemi operativi) per collocare ciascun settore in uno dei cinque livelli, che determinano poi il numero di domini, di prodotti per dominio e la profondità degli attributi.
| Tier | Etichetta | Caratteristiche distintive | Domini MVM | Prodotti/Dominio ECM |
|---|---|---|---|---|
| tier_1 | Ultra-complesso | Servizi bancari, assicurazioni, grandi aziende farmaceutiche | 15–22 | 14–28 |
| tier_2 | Complesso | Telecomunicazioni, energia, sanità | 12–18 | 14–26 |
| tier_3 | Moderato | Produzione manifatturiera, retail | 10–15 | 12–24 |
| tier_4 | Standard | Logistica, agricoltura | 8–12 | 10–20 |
| tier_5 | Semplice | Consulenza, SaaS, media | 5–8 | 8–18 |
Gergo specifico del settore. Ciascun modello utilizza la terminologia effettivamente parlata nel proprio settore. Le telecomunicazioni utilizzano msisdn, arpu, imsi, cdr. Il settore minerario utilizza rom, cut_off_grade, jorc. La sanità utilizza icd, cpt, drg. I servizi bancari utilizzano iban. Questi elementi non sono un'aggiunta tardiva: definiscono i nomi delle colonne, le convenzioni per le chiavi primarie e la struttura dei tag di governance.
L'impalcatura a tre divisioni. Ogni modello è organizzato in tre anelli concentrici:
- Operations rappresenta ciò che l'azienda fa fisicamente: rete, flotta, impianti, infrastruttura.
- Business rappresenta chi serve e come guadagna: clienti, fatturazione, prodotti, vendite.
- Corporate rappresenta l'impalcatura di supporto: HR, finanza, conformità.
Il rapporto è imposto da regole (rule G06-R001): Operations più Business devono rappresentare almeno l'80% di tutti i domini; Corporate è limitato al 20%. Ciò evita la modalità di errore più comune della modellazione non vincolata, ovvero modelli che sono per metà HR, finanza e affari legali, e carenti sul nucleo operativo che effettivamente gestisce l'attività.
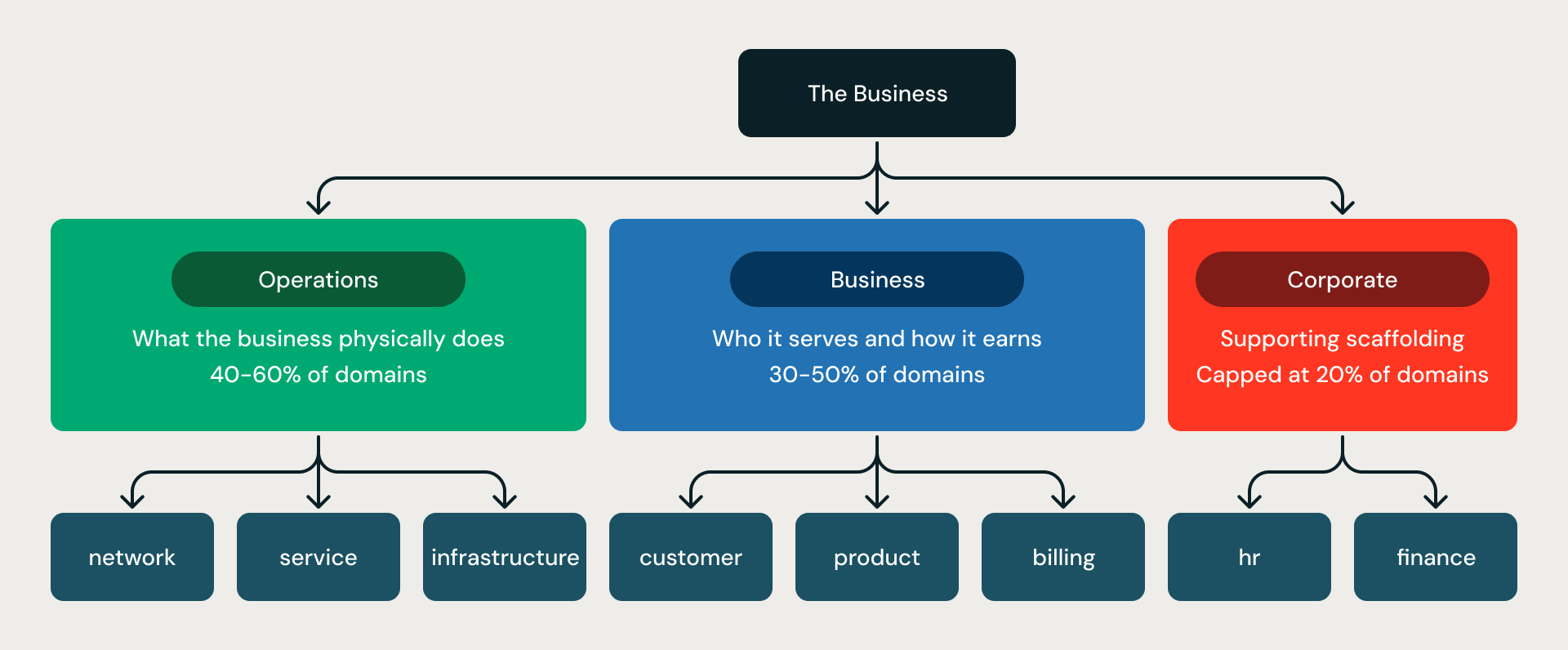
Le tre divisioni
La gerarchia a sei livelli. Ogni modello segue la stessa struttura rigorosa: Organizzazione → Divisione → Dominio → Sottodominio → Prodotto → Attributo. La gerarchia non è un suggerimento; è imposta da regole strutturali, da due livelli di revisione degli architetti e dall'analisi statica al termine di ogni pipeline.
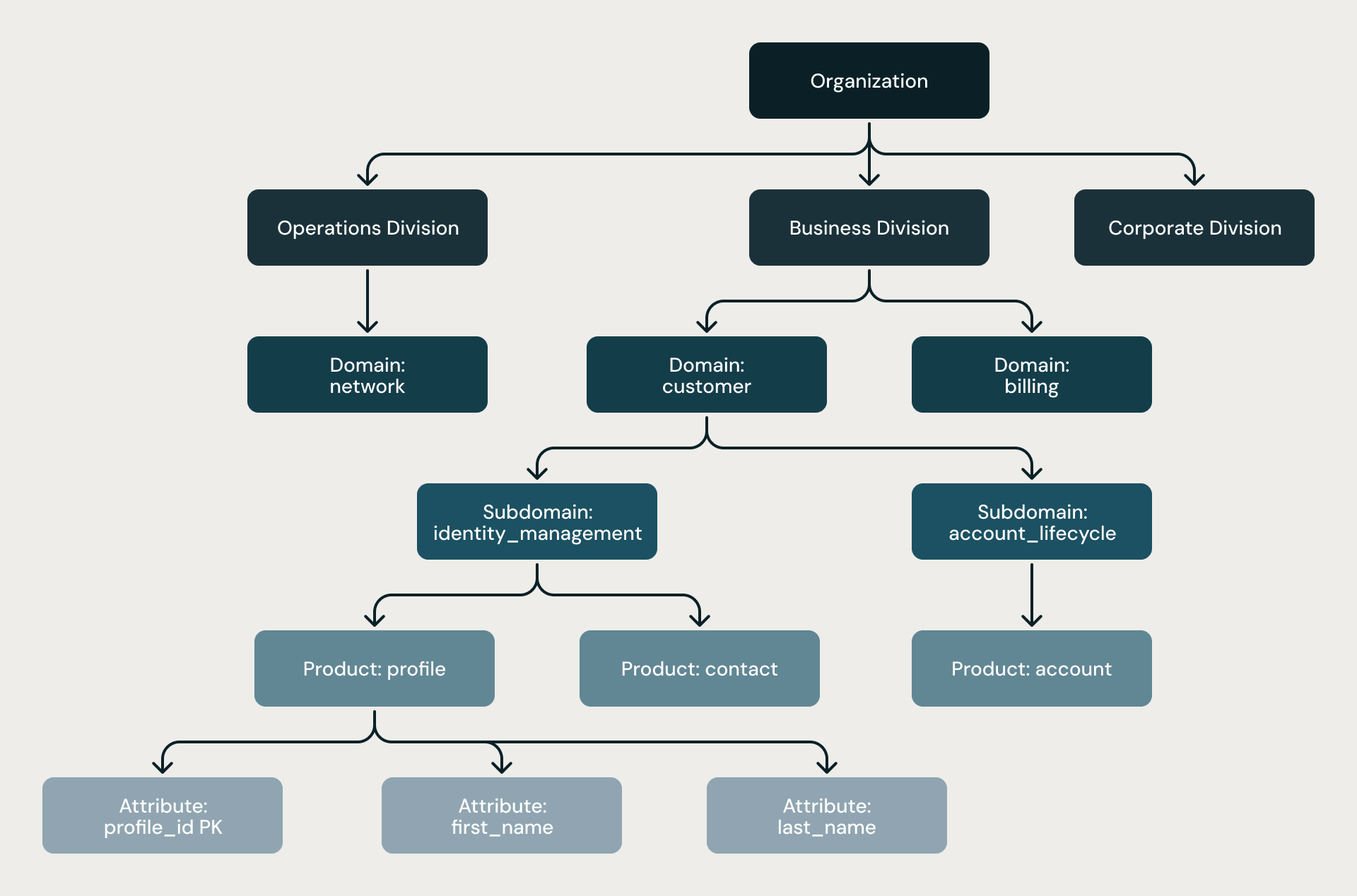
Gerarchia a quattro livelli
Oltre 200 regole applicabili. Ogni modello di base viene convalidato rispetto a più di 200 regole organizzate in oltre 14 gruppi: convenzioni di denominazione, deduplicazione semantica, chiavi esterne, chiavi primarie, normalizzazione, struttura del dominio, tipi di dati, tag di classificazione, applicazione di relazioni/DAG, qualità, progettazione del prodotto, vincoli di stile, distribuzione dello schema fisico e dimensionamento del sottodominio. Ogni tabella deve avere una chiave primaria. Ogni chiave esterna deve puntare a una destinazione reale. Ogni dominio supera il test dell'organigramma: “Potrebbe esistere nell'organizzazione un vero reparto/team con questo nome?”. Nessun ciclo. Nessun silo e rigorosa aderenza al Single Source Of Truth (SSOT).
Un modello logico, tre layout fisici. Ciascun modello di base viene fornito come un singolo file model.json indipendente dall'ambiente. Lo stesso modello logico si distribuisce in modo pulito su Unity Catalog in tre stili di catalogazione: un catalogo (singolo confine di governance), un catalogo per divisione (Operations / Business / Corporate isolati) o un catalogo per dominio (compatibile con data-mesh). Se si esegue nuovamente la distribuzione in uno stile diverso, il modello logico non viene minimamente toccato.
Un esempio pratico: il modello ECM per le compagnie aeree v1
Per rendere questo concetto concreto, ecco il modello ECM per le compagnie aeree disponibile oggi nel repository.
| Metrica | Valore |
|---|---|
| Ambito del modello | ECM v1 |
| Domini totali | 19 |
| Sottodomini totali | 60 |
| Prodotti totali | 420 |
| Attributi totali | 17.278 |
| Chiavi primarie | 420 |
| Chiavi esterne | 2.877 |
| Media attributi/prodotto | 41,1 |
| Viste metriche | 203 |
Visualizzato come un grafo, il DAG completo si presenta così (ogni rettangolo è un dominio, ogni cerchietto è una tabella e ogni linea è un collegamento FK):

Airline ECM v1 come DAG connesso
I diciannove domini si suddividono chiaramente nelle tre divisioni. Operations contiene airport, crew, fleet, flight, inventory, maintenance e route. Business contiene ancillary, cargo, loyalty, passenger, reservation, revenue, service e ticket. Corporate contiene compliance, finance, safety e workforce.

Domini aerei per divisione
Analizzando nel dettaglio un singolo dominio — flight operations — la struttura diventa leggibile a livello operativo. I sottodomini per resource loading, flight operations e passenger services contengono i prodotti a cui un analista delle operazioni attinge effettivamente: leg, flight_plan, oooi_event, atc_clearance, dispatch_release, notam_brief, tech_log, weight_balance, fuel_uplift, pax_segment. (ogni cerchio è una tabella, ogni linea è una relazione FK)

Dominio Flight
Andando ancora più a fondo, su un singolo data product — la Air Waybill (awb) all'interno del dominio cargo — è possibile vedere esattamente come funzionano i collegamenti tra domini diversi. awb si connette a corporate_account nel dominio passenger, station in airport, leg in flight, profit_center, ledger_account e company_code in finance, e screening_result in compliance. Queste sono le join che un analista dei ricavi cargo esegue ogni giorno, e sono presenti perché il DAG cross-dominio è stato creato appositamente per supportarle.

Data product Air Waybill
Cosa si ottiene con il deployment
Ogni modello di base viene fornito con un set completo di artefatti.
Artefatti logici. Un singolo file model.json (il formato di interscambio principale), un file readme.md leggibile, esportazioni flat di domini, prodotti e attributi, esportazioni in formato Excel e CSV, file SQL DDL (uno per dominio più un file FK cross-dominio), un diagramma di schema DBML e un'ontologia RDF/Turtle.
Artefatti fisici quando si esegue il deployment in Unity Catalog. Schemi di Unity Catalog (uno per dominio o per sottodominio, a seconda dello stile di catalogazione), tabelle Delta per ogni prodotto, vincoli di chiave esterna (foreign-key) applicati in ordine di dipendenza, tag di classificazione di Unity Catalog (PII, limitato, pubblico), viste metriche di Databricks per definizioni di KPI riutilizzabili e dati di esempio sintetici con riferimenti FK validi per l'esplorazione immediata.
Il file model.json è l'unità fondamentale. Esegui il commit su Git. Confronta due versioni. Condividilo tra i vari ambienti. Consegnalo a un revisore della sicurezza senza concedere l'accesso alla produzione. Esegui nuovamente il deployment in dev, staging e prod con tre diversi stili di catalogazione e otterrai tre ambienti il cui contenuto logico è identico a livello di byte.
I punti di forza di questo approccio
- Velocità. Le fondamenta del Silver layer che prima richiedevano mesi ora si riducono a un semplice passaggio di deployment.
- Specificità. I modelli utilizzano il linguaggio del settore: la sua terminologia, il suo quadro normativo e la sua realtà operativa.
- Copertura delle regole. Oltre 200 regole applicabili garantiscono una coerenza che la maggior parte dei modelli scritti a mano non raggiunge mai.
- Governance. Ogni colonna contenente dati sensibili viene classificata e taggata. Ogni PK/FK segue un'unica convenzione. Ogni stile di catalogazione è riproducibile.
- Duplice natura. Lo stesso artefatto è uno schema relazionale, un diagramma DBML, un'ontologia di knowledge graph e un deployment fisico di Unity Catalog.
- Separazione logico-fisica. Un solo file model.json, tre stili di catalogazione. Esegui nuovamente il deployment con zero lavoro aggiuntivo.
Aspetti da considerare
I modelli di base sono un punto di partenza, non un prodotto finale finito. La competenza di dominio è ancora fondamentale: la revisione da parte di esperti migliorerà sempre un modello in modi che solo un professionista che lavora all'interno di quell'azienda può individuare. I sotto-settori molto specifici sono meno pronti all'uso rispetto ai settori principali. Inoltre, le organizzazioni con comitati rigidi per l'approvazione dei modelli di dati devono comunque sottoporre l'output a revisione; ciò che cambia è la velocità di creazione dell'artefatto, non l'obbligo di governarlo.
Riteniamo che questo compromesso sia quello giusto. Un modello di base che si distribuisce in poche ore ed è strutturalmente solido rappresenta un punto di partenza migliore rispetto a un modello che richiede un anno per essere adattato.
Provalo oggi stesso
Il repository dei 40 modelli di dati di settore per Lakehouse si trova all'indirizzo https://github.com/databricks-industry-solutions/databricks-industry-data-models Ogni settore viene fornito con un MVM e un ECM. Scegli l'ambito più adatto alla tua organizzazione, collegalo a Unity Catalog e avrai un Silver layer distribuito, classificato e con convalida FK pronto per l'analisi dei dati.
Novità in arrivo
Un modello di base è solo un punto di partenza; ecco perché tutti i modelli sono alla versione v1, e questa non è la forma finale. Ogni organizzazione ha terminologie, divisioni e processi aziendali che persino il miglior modello generico non riuscirà a rispecchiare esattamente. In un post successivo, vedremo come personalizzare ed evolvere i modelli v1 utilizzando un agente di modellazione IA basato sul linguaggio naturale, descrivendo le modifiche desiderate in un linguaggio semplice e producendo una versione personalizzata (v2, v3, ecc.), preservando al contempo il rigore strutturale dell'originale.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.