Dal Lakehouse alla Mente Digitale: progettare un ecosistema di IA multi-agente su Databricks Agent Bricks
Scopri come Edmunds ha trasformato il suo data lakehouse in una piattaforma AI multi-agente intelligente con Agent Bricks per l'attivazione, l'automazione e l'innovazione continua.
- Edmunds ha creato un ecosistema multi-agente nativo per l'AI su Databricks Agent Bricks, passando da un'archiviazione passiva dei dati a un'automazione intelligente in tempo reale per tutte le funzioni di acquisto dell'auto.
- Agenti specializzati come DataDave raggiungono un'accuratezza del 95% in analisi complesse, mentre le offerte di marketing registrano tassi di conversione migliori grazie agli insight ricavati dal lakehouse unificato.
- L'architettura consente un'automazione scalabile, la collaborazione tra agenti ed esperienze proattive e personalizzate sia per i team interni sia per gli acquirenti di auto.
Nelle aziende di oggi, disporre di un data lakehouse ampio e unificato è fondamentale per attivare i dati. Con un lakehouse, le organizzazioni possono trasformare un repository passivo in un motore dinamico e intelligente che anticipa le esigenze, automatizza le conoscenze specialistiche e guida decisioni più informate. In Edmunds, questa priorità ha portato al lancio di Edmunds Mind, la nostra iniziativa per creare un sofisticato ecosistema AI multi-agente direttamente sulla Databricks Data Intelligence Platform.
Questa evoluzione architetturale è alimentata da un momento cruciale nel settore automobilistico. Tre tendenze chiave sono confluite:
- L'ascesa dei modelli linguistici di grandi dimensioni (LLM) come potenti motori di ragionamento
- La scalabilità e la governance di piattaforme come Databricks come base sicura
- L'emergere di solidi framework agentici per orchestrare l'automazione. Questi fattori rendono possibili sistemi che sarebbero sembrati inimmaginabili solo pochi anni fa
Questa trasformazione non consiste solo nell'aggiungere un altro strumento di AI, ma anche nel riprogettare radicalmente la nostra organizzazione per operare come una realtà AI-native. I principi, i componenti e le strategie alla base di questo nucleo intelligente sono dettagliati nel nostro progetto architetturale riportato di seguito.
“Databricks ci offre una base sicura e governata per eseguire più modelli come GPT-4o, Claude e Llama e cambiare provider in base all'evoluzione delle nostre esigenze, il tutto tenendo sotto controllo i costi. Questa flessibilità ci consente di automatizzare la moderazione delle recensioni e migliorare la qualità dei contenuti più rapidamente, in modo che chi acquista un'auto possa ottenere informazioni affidabili in tempi più brevi.”—Gregory Rokita, VP of Technology, Edmunds
Passare da un'azienda ricca di dati a una guidata dagli insight
La nostra visione è quella di evolvere da un'azienda ricca di dati a un'organizzazione guidata dagli insight. Sfruttiamo l'AI per creare l'esperienza di acquisto auto più affidabile, personalizzata e predittiva del settore.
Questo obiettivo viene raggiunto attraverso quattro pilastri strategici chiave:
- Attivare i dati su scala: Passare da dashboard statiche a un'interazione dinamica e conversazionale con i dati.
- Automatizzare le competenze: Codificare la preziosa logica dei nostri esperti di dominio in agenti autonomi e riutilizzabili.
- Accelerare l'innovazione di prodotto: Fornire ai nostri team un toolkit di agenti intelligenti per creare funzionalità di nuova generazione.
- Ottimizzare le operazioni interne: Ottenere significativi guadagni di efficienza automatizzando flussi di lavoro interni complessi.
Al centro di questa visione c'è il nostro vantaggio competitivo più significativo: l'Edmunds Data Moat. Questa solida base di dati automobilistici è guidata dal nostro inventario di veicoli usati leader del settore, dal set più completo di recensioni di esperti e da un'intelligence sui prezzi best-in-class, integrata da ampie recensioni dei consumatori e annunci di nuovi veicoli. Questo intero ecosistema è unificato e gestito all'interno del nostro ambiente Databricks, creando un asset unico e potente. Edmunds Mind è il motore che abbiamo costruito per sbloccare il suo pieno potenziale.
All'interno del Digital Agent Framework
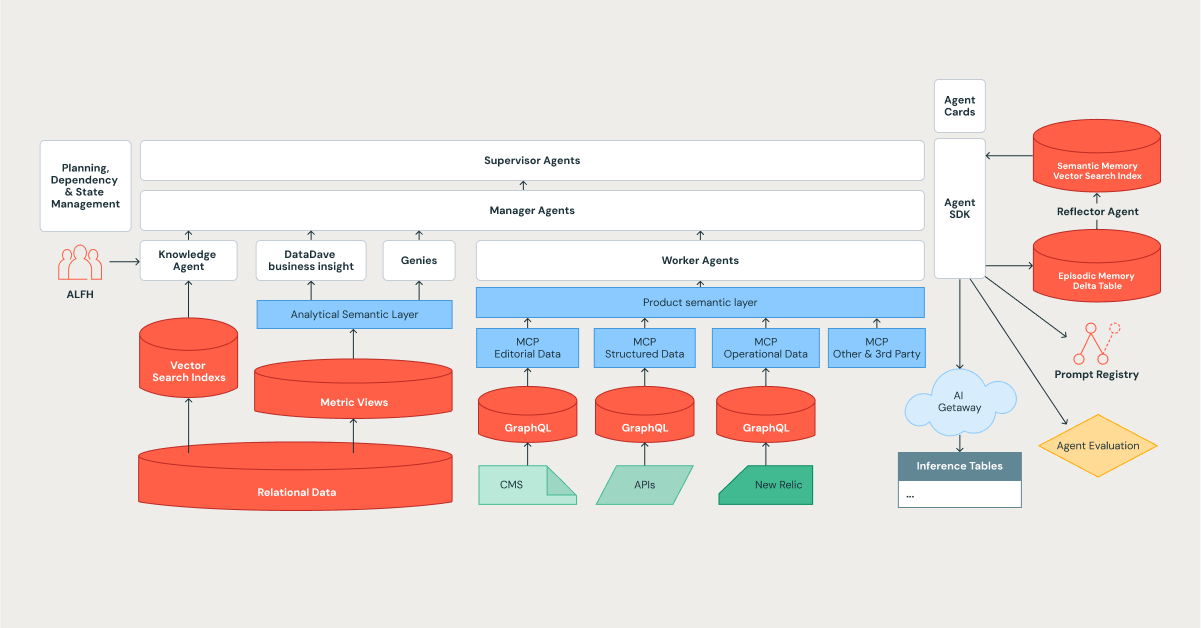
L'architettura di Edmunds Mind è un sistema cognitivo gerarchico progettato per complessità, apprendimento e scalabilità, con la piattaforma Databricks che funge da base.
La gerarchia degli agenti: un'organizzazione di specialisti digitali
Abbiamo progettato il nostro sistema per rispecchiare un'organizzazione efficiente, utilizzando una struttura a livelli in cui le attività vengono scomposte e delegate. Questo si allinea perfettamente con i pattern di orchestrazione nei framework moderni, come Databricks Agent Bricks.
- Agenti Supervisor: I leader strategici. Eseguono la pianificazione a lungo termine, gestiscono le dipendenze e orchestrano attività complesse e multifase.
- Agenti Manager: I team leader. Coordinano un team di agenti specializzati per raggiungere un obiettivo specifico e ben definito.
- Agenti Worker e specializzati: Sono i singoli contributori che forniscono competenze specialistiche. Rappresentano il motore del sistema e includono un elenco crescente di specialisti, come il Knowledge Assistant, DataDave e vari Genies.
La comunicazione tra agenti è regolata da un protocollo standardizzato, che garantisce che le deleghe delle attività e i passaggi di dati siano strutturati, tipizzati e verificabili, il che è fondamentale per mantenere l'affidabilità su scala.
La gerarchia è inoltre progettata per una gestione controllata dei guasti (graceful failure). Quando un Agente Manager stabilisce che il suo team di specialisti non può risolvere un'attività, inoltra l'intero contesto dell'attività al Supervisor, inclusi i tentativi falliti memorizzati nella sua memoria episodica. Il Supervisor può quindi ripianificare con una strategia diversa o, cosa fondamentale, segnalare questo problema come nuovo, richiedendo l'intervento umano per sviluppare una nuova funzionalità. Ciò rende il sistema robusto e uno strumento di apprendimento che ci aiuta a identificare i limiti della sua competenza.
Approfondimento 1: Flusso di lavoro automatizzato per l'arricchimento dei dati
In passato, la risoluzione delle imprecisioni nei dati dei veicoli, come i colori errati su una Vehicle Detail Page, era un processo laborioso che richiedeva il coordinamento manuale tra più team. Oggi, l'ecosistema AI di Edmunds Mind automatizza e risolve queste sfide quasi in tempo reale. Questa efficienza operativa viene raggiunta attraverso il nostro Model Serving centralizzato, che consolida le diverse funzionalità dei nostri agenti AI in un unico ambiente coeso che si ridimensiona automaticamente in base alla domanda. Questa architettura libera i nostri team dal sovraccarico operativo, consentendo loro di concentrarsi sulla rapida fornitura di valore ai nostri utenti.
Il processo di risoluzione viene eseguito attraverso un flusso di lavoro multi-agente governato. Quando un utente o un monitor automatico segnala una potenziale discrepanza nei dati, un Agente Supervisor esegue immediatamente il triage dell'evento. Valuta il problema, lo indirizza al team specializzato appropriato e convalida le autorizzazioni dell'attività tramite Unity Catalog per una solida governance dei dati. Un Agente Manager dedicato orchestra quindi una sequenza di Agenti Worker specializzati per eseguire attività che vanno dalla decodifica del VIN e il recupero delle immagini all'analisi del colore basata sull'AI e agli aggiornamenti finali del database. I data steward umani rimangono parte integrante per la revisione critica, spostando la loro attenzione dall'intervento manuale alla fase di approvazione ad alto valore. Ogni interazione e decisione viene sistematicamente registrata, creando una base completa per l'apprendimento continuo e la futura ottimizzazione dei processi.
Questo esempio illustra come l'intero ecosistema gestisce un'attività reale di qualità e arricchimento dei dati dall'inizio alla fine.
- Trigger dell'evento: Un reclamo dell'utente o un monitor automatico segnala un potenziale problema di qualità dei dati (ad esempio, il colore errato di un veicolo) su una Vehicle Description Page.
- Triage e orchestrazione: Un Agente Supervisor acquisisce l'evento, crea un'attività tracciabile e ne valuta la priorità in base a regole aziendali predefinite.
- Delega al Manager: Il Supervisor delega l'attività all'Agente Vehicle Data Manager dopo aver confermato le sue autorizzazioni per accedere e modificare i dati dei veicoli in Unity Catalog.
- Esecuzione coordinata delle attività: L'Agente Manager orchestra una sequenza di Agenti Worker specializzati per risolvere il problema: un Agente di decodifica VIN, un Agente di recupero immagini per estrarre foto dalla nostra libreria multimediale, un Agente di analisi del colore basato sull'AI per determinare il colore corretto dalle immagini e un Agente di correzione dei dati per aggiornare il database di build del veicolo.
- Revisione Human-in-the-Loop: Prima che la modifica diventi attiva, l'Agente Manager segnala la modifica automatizzata e notifica un data steward umano tramite un'integrazione Slack per la convalida finale.
- Apprendimento e chiusura: Una volta che lo steward approva l'attività, il Supervisor la contrassegna come completata. L'intera interazione, inclusa l'approvazione umana finale, viene tracciata e registrata nella memoria a lungo termine per l'apprendimento e l'auditing futuri.
Approfondimento 2: Knowledge Assistant: risposte in tempo reale, voce del brand affidabile
Laddove un tempo i clienti navigavano tra più dashboard di Edmunds o contattavano il supporto Edmunds per ottenere risposte, il Knowledge Assistant ora fornisce risposte istantanee e conversazionali attingendo all'intero spettro dei dati di Edmunds. Questo agente RAG è sintonizzato sulla voce del brand Edmunds, unendo insight provenienti da recensioni di esperti e consumatori, specifiche dei veicoli, contenuti multimediali e prezzi in tempo reale. Di conseguenza, i clienti sperimentano interazioni più rapide e soddisfacenti e il personale di supporto dedica meno tempo a rispondere a richieste di base.
Le funzionalità chiave includono:
- Personificazione della Brand Voice: L'agente è ottimizzato meticolosamente per comunicare con la voce vivace, utile e fidata che i clienti di Edmunds conoscono da decenni.
- Sintesi dei dati in tempo reale: In una singola query, l'Assistant può recuperare, sintetizzare e presentare informazioni provenienti dalle nostre diverse fonti di dati in tempo reale, tra cui recensioni di esperti e consumatori, specifiche dei veicoli, contenuti video trascritti e gli ultimi prezzi e incentivi.
- Funzionalità RAG avanzate: Stiamo lavorando attivamente con Databricks utilizzando AI Search per superare i limiti della nostra implementazione RAG. Ci concentriamo sul miglioramento della priorità della freschezza dei contenuti e su un filtraggio sofisticato dei metadati per garantire che le informazioni più rilevanti e tempestive vengano sempre mostrate per prime.
Approfondimento 3: Il workflow "Generate-and-Critique" di DataDave
DataDave ora gestisce analisi complesse che in precedenza dipendevano da un lavoro manuale dispendioso in termini di tempo. Questo agente coordina un workflow rigoroso, in cui ogni fase viene valutata da un agente specializzato, per offrire un'accuratezza del 95% sulle query più impegnative. DataDave può identificare proattivamente le opportunità (come la segnalazione di concessionarie poco servite al team vendite di Edmunds) sintetizzando il traffico del sito web e i dati demografici. Ciò consente alla leadership di Edmunds di passare con sicurezza dal report di "cosa è successo" alla decisione su "cosa dovremmo fare dopo".
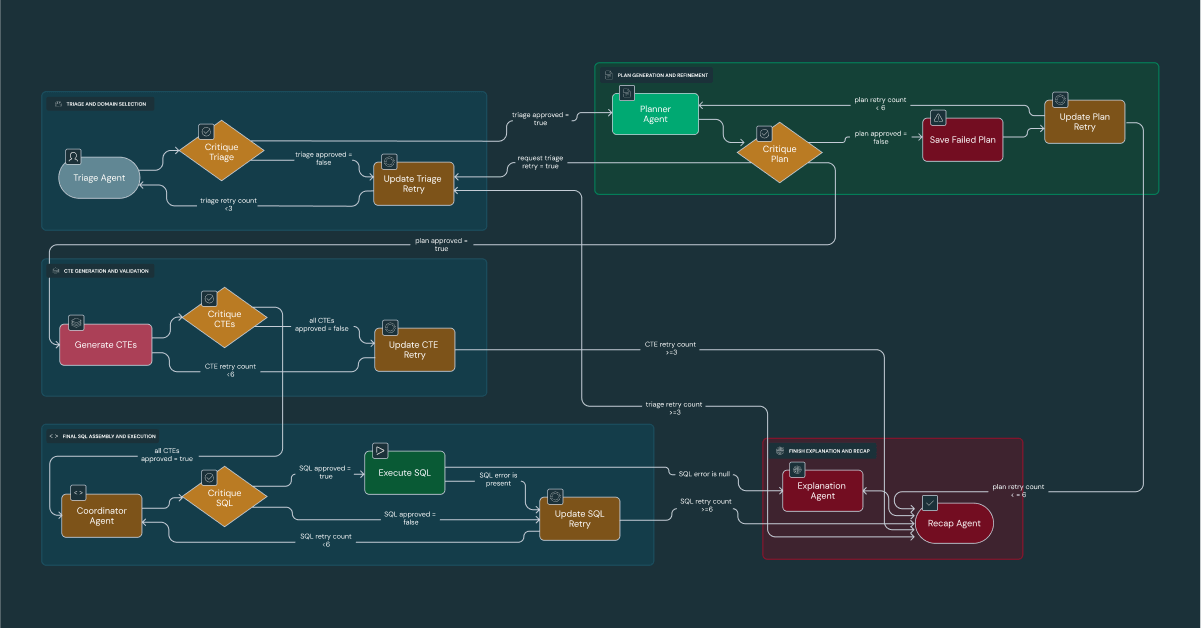
Il workflow interno è un processo in cinque fasi (Triage, Pianificazione, Generazione di codice, Esecuzione e Sintesi), con un agente di Critique dedicato che convalida l'output di ciascuna fase. Oltre a analizzare semplicemente le metriche interne, il vero potere di DataDave risiede nella sua capacità di sintetizzare i nostri dati proprietari con la conoscenza generale del mondo per generare raccomandazioni strategiche. Ad esempio, correlando i dati sul traffico del sito web di Edmunds con i dati geografici e demografici, DataDave può identificare le concessionarie nelle aree meno servite e consigliarle proattivamente al nostro team di vendita come opportunità facilmente accessibili.
Approfondimento 4: Specializzazione nel pricing
In Edmunds, operiamo in base a un principio fondamentale: un prezzo non è solo un numero; è una conclusione che richiede contesto e giustificazione per essere considerata affidabile. Sfruttando la nostra reputazione per il pricing più accurato sul mercato statunitense, la nostra architettura ad agenti è progettata per offrire questa sicurezza su scala.
La nostra esperienza nel far evolvere un "Pricing Expert" monolitico in un team coordinato di specialists dimostra questo principio. Questo team — orchestrato da un Manager Agent e composto da esperti come un True Market Value Agent, un Depreciation Agent e un Deal Rating Agent — produce molto più di un semplice prezzo di listino. L'output finale è una storia di pricing completa e contestualizzata che spiega perché un veicolo viene valutato in un certo modo.
Questo trasforma il ruolo dei nostri analisti di pricing dall'aggregazione manuale dei dati alla supervisione e guida strategica. Sfruttando Databricks Agent Bricks, i nostri statistici di pricing possono configurare questi team di agenti gerarchici con una codifica limitata, aumentando drasticamente la loro produttività e riducendo i costi di manutenzione. Ciò consente loro di concentrarsi su ciò che conta davvero: il "perché" dietro i numeri.
Il nucleo cognitivo: un'architettura per un'intelligenza cumulativa
Il nostro viaggio verso un ecosistema di AI veramente intelligente è iniziato con una sfida pratica. Durante l'implementazione di agenti specializzati come DataDave per la business analytics, abbiamo scoperto che stavano portando alla luce verità aziendali critiche e urgenti che rimanevano isolate all'interno del loro contesto operativo. Ad esempio, un agente potrebbe rilevare una tendenza al ribasso anomala in un canale di marketing chiave, ma questa intuizione vitale deve essere comunicata in modo efficace ad altre entità, sia agenti che umani, per avviare una risposta coordinata. Ciò ha evidenziato un'esigenza fondamentale: un sistema di memoria condivisa in grado di catturare questi apprendimenti emergenti e renderli accessibili come input per l'intero sistema di agenti. Abbiamo immaginato un livello cognitivo in cui questa conoscenza potesse accumularsi, crescere ed essere sfruttata per rendere il nostro intero ecosistema progressivamente più intelligente. Di conseguenza, il nostro pensiero e design più recenti sono i seguenti.
- Memoria episodica ("Cosa è successo"): Un registro ad alta fedeltà di ogni azione e osservazione dell'agente, che funge da ground truth del sistema.
- Memoria semantica ("Cosa è stato appreso"): Un indice vettoriale contenente insight generalizzati e strategie di successo sintetizzate da eventi episodici. Questa sarà la libreria di conoscenze fruibili.
- Consolidamento automatico della memoria: Un agente "Reflector" in background esamina periodicamente la memoria episodica per identificare e consolidare gli apprendimenti chiave nella memoria semantica.
- Accesso gerarchico alla memoria: Gli agenti di livello superiore possono accedere alle memorie dei loro subordinati, consentendo a un Manager Agent di analizzare le prestazioni del team e ottimizzare le strategie future. Questo ciclo di feedback è fondamentale per l'antifragilità del nostro sistema; ogni nuovo errore segnalato dalla gerarchia non è solo un problema da risolvere, ma un segnale che addestra l'intero ecosistema, rendendolo progressivamente più intelligente e resiliente.
Implementazione: mem0 + Databricks
La nostra implementazione sarà supportata da Databricks AI Search utilizzando un Delta Sync Index, che è completamente compatibile con l'interfaccia mem0. Dato che mem0 interagisce con i database vettoriali, innoveremo memorizzando sia le memorie episodiche che quelle semantiche all'interno di un unico, potente backend. Gli eventi grezzi e non riassunti ("cosa è successo") e gli apprendimenti sintetizzati ("cosa è stato appreso") coesisteranno come tipi di vettori distinti all'interno della stessa tabella Delta di origine, che poi popolerà in modo automatico e trasparente l'indice di AI Search.
Questa architettura unificata crea un workflow efficiente. L'agente Reflector può interrogare l'indice per trovare voci episodiche recenti, eseguire la sintesi e riscrivere i nuovi vettori semantici generalizzati nella tabella Delta di origine. Il Delta Sync Index acquisisce quindi automaticamente questi nuovi apprendimenti, rendendoli disponibili per le query. Sfruttando la tabella Delta di origine come unico punto di ingresso, eliminiamo la complessità della pipeline di dati e otteniamo la base scalabile, serverless e a bassa latenza richiesta per un sistema di agenti veramente intelligente.
Esempio di workflow con Edmunds Pulse
- Log: L'agente 'DataDave' rileva un'anomalia nelle vendite e registra l'evento nella sua memoria episodica tramite l'API mem0. Questa azione scrive una nuova voce vettoriale nella nostra tabella Delta di origine.
- Sintesi: L'agente Reflector elabora questo evento, genera un insight generalizzato (ad es. "le vendite del Prodotto X calano nei fine settimana") e lo converte in un embedding vettoriale.
- Indice: Il nuovo insight viene riscritto nella tabella Delta di origine, ma contrassegnato come apprendimento sintetizzato. Databricks AI Search sincronizza automaticamente questa nuova voce, indicizzandone il contenuto nella memoria semantica.
- Distribuzione: Infine, un agente Edmunds Pulse dedicato, che monitora costantemente la memoria semantica alla ricerca di informazioni ad alta priorità, fornisce proattivamente questo risultato sintetizzato a uno stakeholder umano. Facendo un parallelo con il rilascio di ChatGPT Pulse, che mira a fornire un assistente AI più integrato nel contesto e consapevole, il nostro Edmunds Pulse fungerà da "battito" in tempo reale dell'azienda, garantendo che gli insight critici non vengano solo memorizzati, ma comunicati attivamente per guidare azioni tempestive e intelligenti.
Il livello di dati e conoscenza: una base di verità governata
Gli agenti AI si affidano alla qualità dei loro dati. Il livello di dati di Edmunds è creato appositamente per garantire coerenza, governance e flessibilità, con Unity Catalog che funge da pietra angolare per assicurare che tutte le informazioni rimangano accurate e ben gestite.
Approfondimento 5: Accesso ai dati GraphQL e pattern di interattività
Il framework Model Context Protocol (MCP) di Edmunds connette in modo sicuro gli agenti AI al contesto in tempo reale proveniente da tutte le principali fonti di dati, come specifiche dei veicoli, recensioni, inventario e metriche operative da sistemi come New Relic. Ciò si ottiene attraverso un gateway API GraphQL unificato, che astrae la complessità sottostante e offre uno schema fortemente tipizzato e autodocumentante.
Invece di costringere agenti o ingegneri a lottare con dati frammentati, schemi non corrispondenti o una risoluzione dei problemi lenta, il sistema ora supporta tre pattern di interattività principali, ciascuno ottimizzato per un caso d'uso diverso:
- Introspezione dinamica dello schema: gli agenti possono esplorare dinamicamente query nuove o sconosciute analizzando direttamente lo schema GraphQL. Quando un cliente pone una domanda unica (ad esempio, se il valore di un'auto è influenzato da recenti richiami di sicurezza), l'agente può scoprire nuovi tipi di dati al volo e creare query precise per recuperare le risposte pertinenti. Questa flessibilità consente all'organizzazione di adattarsi rapidamente ai nuovi requisiti aziendali senza richiedere modifiche manuali alle API.
- Strumenti mappati granulari: ogni strumento dell'agente è mappato direttamente su una query o mutazione GraphQL specifica per le operazioni di routine. Ad esempio, aggiornare il colore di un veicolo è semplice come estrarre il VIN e il nuovo colore, con l'agente che gestisce la mutazione. Questo approccio aumenta l'affidabilità e riduce l'intervento manuale, semplificando le attività quotidiane del team.
- Query persistenti: le funzioni ad alto traffico e critiche per le prestazioni, come le dashboard dell'inventario in tempo reale, sfruttano query preregistrate per la massima efficienza. L'agente invia un hash leggero e le variabili, e il sistema restituisce istantaneamente i risultati con una larghezza di banda ridotta e una maggiore sicurezza.
Edmunds ha migliorato drasticamente la velocità, la flessibilità e l'affidabilità delle operazioni sui dati nelle funzioni di prodotto e supporto, fornendo agli agenti AI un accesso strutturato a tutti i dati aziendali attraverso un unico e solido layer API. Le attività che in prevenzione richiedevano uno sviluppo personalizzato o il debug tra diversi team vengono ora gestite in tempo reale, consentendo ai clienti e ai team interni di beneficiare di insight più ricchi e risposte più agili.
Deep Dive 6: i layer semantici e di conoscenza
Questo layer cruciale funge da ponte tra i dati grezzi e la comprensione dell'agente. Astrae la complessità dei data store sottostanti. Arricchisce i dati con il contesto aziendale, garantendo che gli agenti operino su una vista coerente, governata e comprensibile dell'universo Edmunds.
- Unity Catalog: la spina dorsale della governance: al centro del nostro ecosistema di dati, Unity Catalog fornisce governance centralizzata, sicurezza e lineage per tutti gli asset di dati e AI. Garantisce che ogni dato a cui accede un agente sia soggetto a controlli di accesso granulari e che il suo percorso sia completamente tracciabile, costituendo la base non negoziabile per una piattaforma AI sicura e conforme.
- Layer semantico del prodotto: contesto aziendale in tempo reale: questo layer fornisce agli agenti una vista orientata agli oggetti e in tempo reale delle nostre entità di prodotto principali (ad es. veicoli, concessionari, recensioni). Aspetto fondamentale, proviene direttamente dagli stessi schemi GraphQL che alimentano il sito web di Edmunds. Ciò garantisce un'assoluta coerenza: quando un agente parla di un "veicolo", fa riferimento allo stesso modello di dati e alla stessa logica aziendale che un consumatore vede sul sito web, eliminando qualsiasi rischio di data drift tra i nostri prodotti esterni e la nostra AI interna.
- Layer semantico analitico: l'unica fonte di verità per i KPI: questo layer fornisce una vista coerente e affidabile di tutte le metriche di performance aziendali. Proviene direttamente dalle nostre Delta Metric Views curate, che sono la stessa fonte che alimenta tutte le dashboard esecutive e operative. Questo allineamento garantisce che quando DataDave o altri agenti generano report sui KPI aziendali (come il traffico delle sessioni, i lead o i tassi di valutazione), utilizzino definizioni e fonti di dati identiche a quelle dei nostri strumenti di business intelligence consolidati, garantendo un'unica fonte di verità in tutta l'organizzazione.
- Databricks AI Search - Il motore per la RAG: questo componente è il motore di recupero ad alte prestazioni per i nostri dati non strutturati e semistrutturati. Convertendo il nostro vasto corpus di recensioni, articoli e contenuti trascritti in embedding vettoriali, consentiamo ad agenti come il Knowledge Assistant di eseguire ricerche semantiche fulminee, recuperando il contesto più pertinente per rispondere alle query degli utenti in un pattern RAG (Retrieval-Augmented Generation).
Da centro di costo a motore di valore: misurare il ROI della nostra AI
Un'architettura visionaria è valida solo nella misura in cui lo è la sua esecuzione. Il nostro approccio si basa su una roadmap a fasi e su un profondo impegno nel trattare il nostro ecosistema di AI come un motore centrale che genera valore. Raggiungiamo questo obiettivo collegando direttamente il nostro framework tecnico per l'osservabilità, la governance e l'etica ai principali risultati aziendali. Il nostro obiettivo non è solo creare una potente AI, ma quantificare il suo impatto sui nostri profitti.
Accelerare la velocità aziendale
Abbiamo creato un sistema olistico per misurare entrambi i lati dell'equazione del ROI. Dal lato dei rendimenti, il nostro framework collega le prestazioni dell'AI direttamente ai KPI aziendali. Ad esempio:
- Il nostro agente DataDave fornisce analisi complesse e fruibili in pochi minuti, un'attività che in precedenza richiedeva ore di lavoro agli analisti umani di Edmunds. Ciò accelera notevolmente il processo decisionale basato sui dati.
- I nostri agenti di determinazione dei prezzi rispondono all'istante alle richieste, eliminando ore di ricerca manuale e liberando i nostri team per concentrarsi su attività strategiche e ad alto valore.
Sebbene stiamo ancora quantificando l'impatto preciso su metriche come i tassi di conversione delle campagne, questo framework fornisce i dati in tempo reale necessari per delineare tali correlazioni.
Ottimizzazione dei costi
Pratichiamo una governance economica intelligente attraverso il nostro AI Gateway. Gli agenti ad alto rischio come DataDave vengono indirizzati ai nostri modelli più potenti per garantire l'accuratezza, mentre le attività di routine vengono assegnate automaticamente a modelli più convenienti. Questa strategia di suddivisione in livelli dei modelli ci consente di gestire con precisione la spesa per LLM e computazione, garantendo che ogni dollaro investito sia allineato al valore aziendale creato.
“Databricks ci consente di eseguire il modello giusto per l'attività giusta, in modo sicuro e su scala. Questa flessibilità alimenta i nostri agenti e offre esperienze di acquisto dell'auto più intelligenti.” —Greg Rokita, VP of Technology, Edmunds
Abilitazione organizzativa: responsabilizzare ogni dipendente
Per dare vita a questa visione, stiamo promuovendo una cultura dell'innovazione in tutta Edmunds. Puntiamo a supportare uno spettro completo di interazione uomo-AI, da attività completamente autonome a revisioni human-in-the-loop e alla risoluzione collaborativa dei problemi.
Per supportare questo obiettivo, forniamo un solido Agent SDK per gli ingegneri e promuoviamo un movimento "Citizen Developer" attraverso la nostra piattaforma Agent Bricks. Questa iniziativa è stata avviata con la nostra conferenza tecnologica aziendale "AI Agents @ Edmunds" ed è alimentata da un'attiva LLM Agents Guild, garantendo che ogni dipendente disponga degli strumenti e del supporto per contribuire al nostro futuro guidato dall'AI.
La strada da percorrere: dall'intelligenza proattiva alla vera autonomia
Il nostro viaggio per diventare un'organizzazione veramente AI-native è una maratona, non uno sprint. L'architettura "Edmunds Mind" funge da modello per questo percorso e il suo prossimo passo evolutivo consiste nello sviluppare agenti proattivi che non solo rispondano alle domande, ma anticipino anche le esigenze aziendali. Immaginiamo un futuro in cui i nostri agenti identifichino le opportunità di mercato dai flussi di dati in tempo reale e forniscano insight strategici agli stakeholder prima ancora che li richiedano.
In definitiva, la nostra roadmap porta a un sistema in cui gli agenti possono auto-ottimizzarsi, proponendo nuovi strumenti, perfezionando i meccanismi di critica e persino suggerendo miglioramenti architetturali. Ciò segna il passaggio da un sistema che semplicemente gestiamo a un vero partner cognitivo, evolvendo i nostri ruoli da operatori a supervisori, eticisti e strateghi di una nuova forza lavoro intelligente.
Scopri di più su come Edmunds sta creando un'esperienza di acquisto dell'auto guidata dall'AI con l'aiuto di Databricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.