Prestazioni RAG a Contesto Lungo degli LLM
Aumentare il contesto non aiuta sempre
di Quinn Leng, Jacob Portes, Sam Havens, Matei Zaharia e Michael Carbin
La Generazione Aumentata dal Recupero (RAG) è il caso d'uso dell'IA generativa più ampiamente adottato dai nostri clienti. RAG migliora l'accuratezza dei LLM recuperando informazioni da fonti esterne come documenti non strutturati o dati strutturati. Con la disponibilità di LLM con lunghezze di contesto maggiori come Anthropic Claude (200k context length), GPT-4-turbo (128k context length) e Google Gemini 1.5 pro (2 million context length), gli sviluppatori di applicazioni LLM sono in grado di fornire più documenti alle loro applicazioni RAG. Portando le lunghezze di contesto più lunghe all'estremo, c'è persino un dibattito sul fatto che i modelli linguistici a contesto lungo finiranno per inglobare i flussi di lavoro RAG. Perché recuperare singoli documenti da un database se si può inserire l'intero corpus nella finestra di contesto?
Questo post del blog esplora l'impatto dell'aumento della lunghezza del contesto sulla qualità delle applicazioni RAG. Abbiamo condotto oltre 2.000 esperimenti su 13 popolari LLM open source e commerciali per scoprire le loro prestazioni su vari set di dati specifici del dominio. Abbiamo scoperto che:
- Recuperare più documenti può effettivamente essere vantaggioso: Recuperare più informazioni per una data query aumenta la probabilità che le informazioni corrette vengano trasmesse al LLM. I moderni LLM con lunghezze di contesto lunghe possono sfruttare questo vantaggio e migliorare così il sistema RAG complessivo.
- Un contesto più lungo non è sempre ottimale per RAG: Le prestazioni della maggior parte dei modelli diminuiscono dopo una certa dimensione del contesto. In particolare, le prestazioni di Llama-3.1-405b iniziano a diminuire dopo 32k token, GPT-4-0125-preview inizia a diminuire dopo 64k token, e solo pochi modelli sono in grado di mantenere prestazioni RAG coerenti su contesti lunghi su tutti i set di dati.
- I modelli falliscono su contesti lunghi in modi molto distinti: Abbiamo condotto analisi approfondite sulle prestazioni su contesti lunghi di Llama-3.1-405b, GPT-4, Claude-3-sonnet, DBRX e Mixtral e abbiamo identificato schemi di fallimento unici come il rifiuto a causa di preoccupazioni sul copyright o la costante riassunzione del contesto. Molti dei comportamenti suggeriscono una mancanza di sufficiente post-addestramento sul contesto lungo.
Contesto
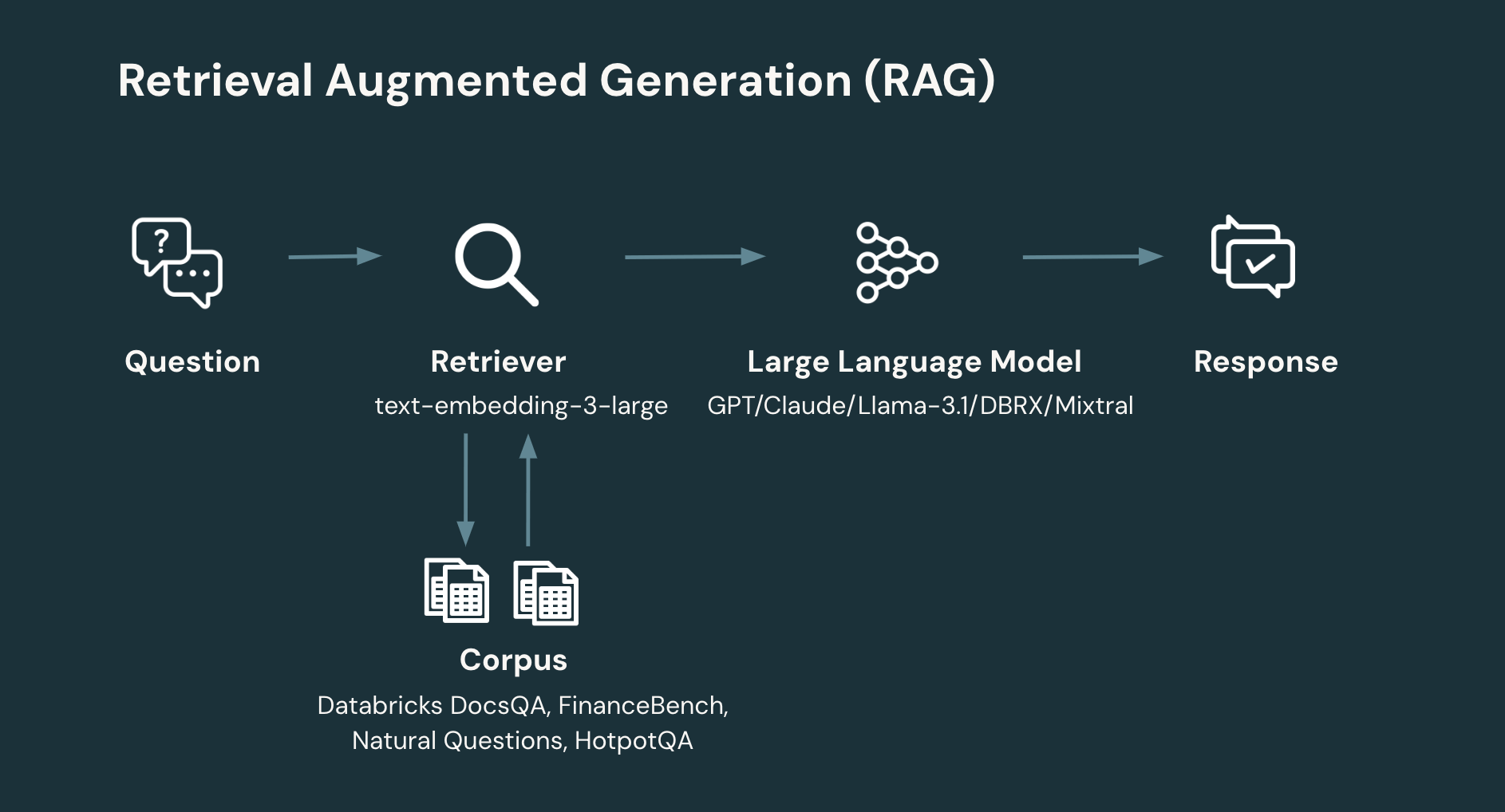
RAG: Un tipico flusso di lavoro RAG coinvolge almeno due passaggi:
- Recupero: data la domanda dell'utente, recuperare le informazioni pertinenti da un corpus o da un database. Il recupero delle informazioni è un'area ricca di progettazione di sistemi. Tuttavia, un approccio semplice e contemporaneo consiste nell'incorporare singoli documenti per produrre una raccolta di vettori che vengono poi archiviati in un database vettoriale. Il sistema recupera quindi documenti pertinenti in base alla somiglianza della domanda dell'utente con il documento. Un parametro chiave di progettazione nel recupero è il numero di documenti e, quindi, il numero totale di token da restituire.
- Generazione: data la domanda dell'utente e le informazioni recuperate, generare la risposta corrispondente (o rifiutare se non ci sono abbastanza informazioni per generare una risposta). Il passaggio di generazione può impiegare una vasta gamma di tecniche. Tuttavia, un approccio semplice e contemporaneo consiste nel sollecitare un LLM attraverso un semplice prompt che introduce le informazioni recuperate e il contesto pertinente per la domanda a cui rispondere.
È stato dimostrato che RAG aumenta la qualità dei sistemi di QA in molti domini e attività (Lewis et.al 2020).
Modelli linguistici a contesto lungo: i moderni LLM supportano lunghezze di contesto sempre maggiori.
Mentre l'originale GPT-3.5 aveva solo una lunghezza di contesto di 4k token, GPT-4-turbo e GPT-4o hanno una lunghezza di contesto di 128k. Allo stesso modo, Claude 2 ha una lunghezza di contesto di 200k token e Gemini 1.5 pro vanta una lunghezza di contesto di 2 milioni di token. La lunghezza massima del contesto dei LLM open source ha seguito una tendenza simile: mentre la prima generazione di modelli Llama aveva solo una lunghezza di contesto di 2k token, modelli più recenti come Mixtral e DBRX hanno una lunghezza di contesto di 32k token. Il recentemente rilasciato Llama 3.1 ha un massimo di 128k token.
Il vantaggio di utilizzare un contesto lungo per RAG è che il sistema può aumentare il passaggio di recupero per includere più documenti recuperati nel contesto del modello di generazione, il che aumenta la probabilità che un documento pertinente per rispondere alla domanda sia disponibile per il modello.
D'altra parte, recenti valutazioni di modelli a contesto lungo hanno evidenziato due limitazioni diffuse:
- Il problema “lost in the middle”: il problema “lost in the middle” si verifica quando i modelli faticano a conservare ed utilizzare efficacemente le informazioni dalle porzioni centrali di testi lunghi. Questo problema può portare a un degrado delle prestazioni all'aumentare della lunghezza del contesto, con i modelli che diventano meno efficaci nell'integrare informazioni sparse in contesti estesi.
- Lunghezza del contesto efficace: il paper RULER ha esplorato le prestazioni dei modelli a contesto lungo su diverse categorie di task, tra cui recupero, tracciamento di variabili, aggregazione e risposta a domande, e ha scoperto che la lunghezza del contesto efficace - la quantità di contesto utilizzabile oltre la quale le prestazioni del modello iniziano a diminuire – può essere molto più breve della lunghezza massima del contesto dichiarata.
Tenendo conto di queste osservazioni di ricerca, abbiamo progettato molteplici esperimenti per sondare il valore potenziale dei modelli a contesto lungo, la lunghezza del contesto efficace dei modelli a contesto lungo nei flussi di lavoro RAG e valutare quando e come i modelli a contesto lungo possono fallire.
Metodologia
Per esaminare l'effetto del contesto lungo sul recupero e sulla generazione, sia individualmente che sull'intera pipeline RAG, abbiamo esplorato le seguenti domande di ricerca:
- L'effetto del contesto lungo sul recupero: In che modo la quantità di documenti recuperati influisce sulla probabilità che il sistema recuperi un documento pertinente?
- L'effetto del contesto lungo su RAG: Come cambiano le prestazioni di generazione in funzione di un maggior numero di documenti recuperati?
- Le modalità di fallimento per il contesto lungo su RAG: Come falliscono i diversi modelli nel contesto lungo?
Abbiamo utilizzato le seguenti impostazioni di recupero per gli esperimenti 1 e 2:
- modello di embedding: (OpenAI) text-embedding-3-large
- dimensione del chunk: 512 token (abbiamo suddiviso i documenti dal corpus in chunk di dimensione 512 token)
- dimensione dello stride: 256 token (la sovrapposizione tra chunk adiacenti è di 256 token)
- vector store: FAISS (con indice IndexFlatL2)
Abbiamo utilizzato le seguenti impostazioni di generazione per l'esperimento 2:
- modelli di generazione: gpt-4o, claude-3-5-sonnet, claude-3-opus, claude-3-haiku, gpt-4o-mini, gpt-4-turbo, claude-3-sonnet, gpt-4, meta-llama-3.1-405b, meta-llama-3-70b, mixtral-8x7b, dbrx, gpt-3.5-turbo
- temperatura: 0.0
- max_output_tokens: 1024
Quando abbiamo benchmarkato le prestazioni alla lunghezza del contesto X, abbiamo utilizzato il seguente metodo per calcolare quanti token utilizzare per il prompt:
- Data la lunghezza del contesto X, abbiamo prima sottratto 1k token che vengono utilizzati per l'output del modello
- Abbiamo poi lasciato un buffer di 512 token
Il resto è il limite per quanto lungo può essere il prompt (questo è il motivo per cui abbiamo utilizzato una lunghezza di contesto di 125k invece di 128k, poiché volevamo lasciare abbastanza buffer per evitare errori di out-of-context).
Dataset di valutazione
In questo studio, abbiamo benchmarkato tutti gli LLM su 4 dataset RAG curati che sono stati formattati sia per il recupero che per la generazione. Questi includevano Databricks DocsQA e FinanceBench, che rappresentano casi d'uso industriali, e Natural Questions (NQ) e HotPotQA, che rappresentano contesti più accademici. Di seguito i dettagli del dataset:
| Dataset \ Dettagli | Categoria | Corpus #doc | # query | Lunghezza media doc (token) | Lunghezza min doc (token) | Lunghezza max doc (token) | Descrizione |
| Databricks DocsQA (v2) | Specifico per caso d'uso: risposta a domande aziendali | 7563 | 139 | 2856 | 35 | 225941 | DocsQA è un dataset interno di risposta a domande che utilizza informazioni dalla documentazione pubblica di Databricks e domande e risposte reali degli utenti. Ciascuno dei documenti nel corpus è una pagina web. |
| FinanceBench (150 task) | Specifico per caso d'uso: risposta a domande finanziarie | 53399 | 150 | 811 | 0 | 8633 | FinanceBench è un dataset accademico per il question-answering che include pagine da 360 depositi SEC 10k di società pubbliche e le corrispondenti domande e risposte di base basate sui documenti SEC 10k. Maggiori dettagli sono disponibili nell'articolo Islam et al. (2023). Utilizziamo una versione proprietaria (closed source) del dataset completo da Patronus. Ciascuno dei documenti nel nostro corpus corrisponde a una pagina dei file PDF SEC 10k. |
| Natural Questions (split dev | Accademico: question-answering di conoscenza generale (wikipedia) | 7369 | 534 | 11354 | 716 | 13362 | Natural Questions è un dataset accademico per il question-answering di Google, discusso nel loro articolo del 2019 (Kwiatkowski et al., 2019). Le query sono query di ricerca di Google. Ogni domanda viene risposta utilizzando il contenuto delle pagine di Wikipedia nei risultati di ricerca. Utilizziamo una versione semplificata delle pagine di Wikipedia in cui la maggior parte del testo non in linguaggio naturale è stata rimossa, ma alcuni tag HTML rimangono per definire una struttura utile nei documenti (ad esempio, tabelle). La semplificazione viene eseguita adattando l'implementazione originale. |
| BEIR-HotpotQA | Accademico: question-answering di conoscenza generale multi-hop (wikipedia) | 5233329 | 7405 | 65 | 0 | 3632 | HotpotQA è un dataset accademico per il question-answering raccolto da Wikipedia in inglese; stiamo utilizzando la versione di HotpotQA dall'articolo BEIR (Thakur et al, 2021) |
Metriche di Valutazione:
- Metriche di retrieval: abbiamo utilizzato il recall per misurare le prestazioni del retrieval. Il punteggio di recall è definito come il rapporto tra il numero di documenti pertinenti recuperati e il numero totale di documenti pertinenti nel dataset.
- Metriche di generazione: abbiamo utilizzato la metrica di correttezza della risposta per misurare le prestazioni della generazione. Abbiamo implementato la correttezza della risposta attraverso il nostro sistema LLM-as-a-judge calibrato, alimentato da GPT-4o. I nostri risultati di calibrazione hanno dimostrato che il tasso di accordo giudice-umano è elevato quanto il tasso di accordo umano-umano.
Perché il contesto lungo per RAG?
Esperimento 1: I benefici del recupero di più documenti
In questo esperimento, abbiamo valutato come il recupero di più risultati influenzi la quantità di informazioni pertinenti inserite nel contesto del modello di generazione. Nello specifico, abbiamo ipotizzato che il retriever restituisca X numero di token e quindi calcolato il punteggio di recall a quel cutoff. Da un'altra prospettiva, le prestazioni di recall sono il limite superiore delle prestazioni del modello di generazione quando al modello è richiesto di utilizzare solo i documenti recuperati per generare risposte.
Di seguito sono riportati i risultati di recall per il modello di embedding OpenAI text-embedding-3-large su 4 dataset e diverse lunghezze di contesto. Utilizziamo una dimensione di chunk di 512 token e lasciamo un buffer di 1.5k per il prompt e la generazione.
| # Chunk recuperati | 1 | 5 | 13 | 29 | 61 | 125 | 189 | 253 | 317 | 381 | |
Recall@k Lunghezza Contesto | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 160k | 192k | |
| Databricks DocsQA | 0.547 | 0.856 | 0.906 | 0.957 | 0.978 | 0.986 | 0.993 | 0.993 | 0.993 | 0.993 | |
| FinanceBench | 0.097 | 0.287 | 0.493 | 0.603 | 0.764 | 0.856 | 0.916 | 0.916 | 0.916 | 0.916 | |
| NQ | 0.845 | 0.992 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | |
| HotPotQA | 0.382 | 0.672 | 0.751 | 0.797 | 0.833 | 0.864 | 0.880 | 0.890 | 0.890 | 0.890 | |
| Average | 0.468 | 0.702 | 0.788 | 0.839 | 0.894 | 0.927 | 0.947 | 0.95 | 0.95 | 0.95 | 0.95 |
Punto di saturazione: come si può osservare nella tabella, il punteggio di recupero del recall per ogni dataset raggiunge la saturazione a una diversa lunghezza di contesto. Per il dataset NQ, si satura presto a una lunghezza di contesto di 8k, mentre i dataset DocsQA, HotpotQA e FinanceBench si saturano rispettivamente a lunghezze di contesto di 96k e 128k. Questi risultati dimostrano che con un semplice approccio di recupero, sono disponibili informazioni pertinenti aggiuntive per il modello di generazione fino a 96k o 128k token. Pertanto, la maggiore dimensione del contesto dei modelli moderni offre la promessa di catturare queste informazioni aggiuntive per aumentare la qualità complessiva del sistema.
L'uso di un contesto più lungo non aumenta uniformemente le prestazioni di RAG
Esperimento 2: Contesto lungo su RAG
In questo esperimento, abbiamo combinato il passaggio di recupero e il passaggio di generazione in una semplice pipeline RAG. Per misurare le prestazioni RAG a una certa lunghezza di contesto, aumentiamo il numero di chunk restituiti dal retriever per riempire il contesto del modello di generazione fino a una lunghezza di contesto data. Quindi chiediamo al modello di rispondere alle domande di un benchmark dato. Di seguito sono riportati i risultati di questi modelli a diverse lunghezze di contesto.
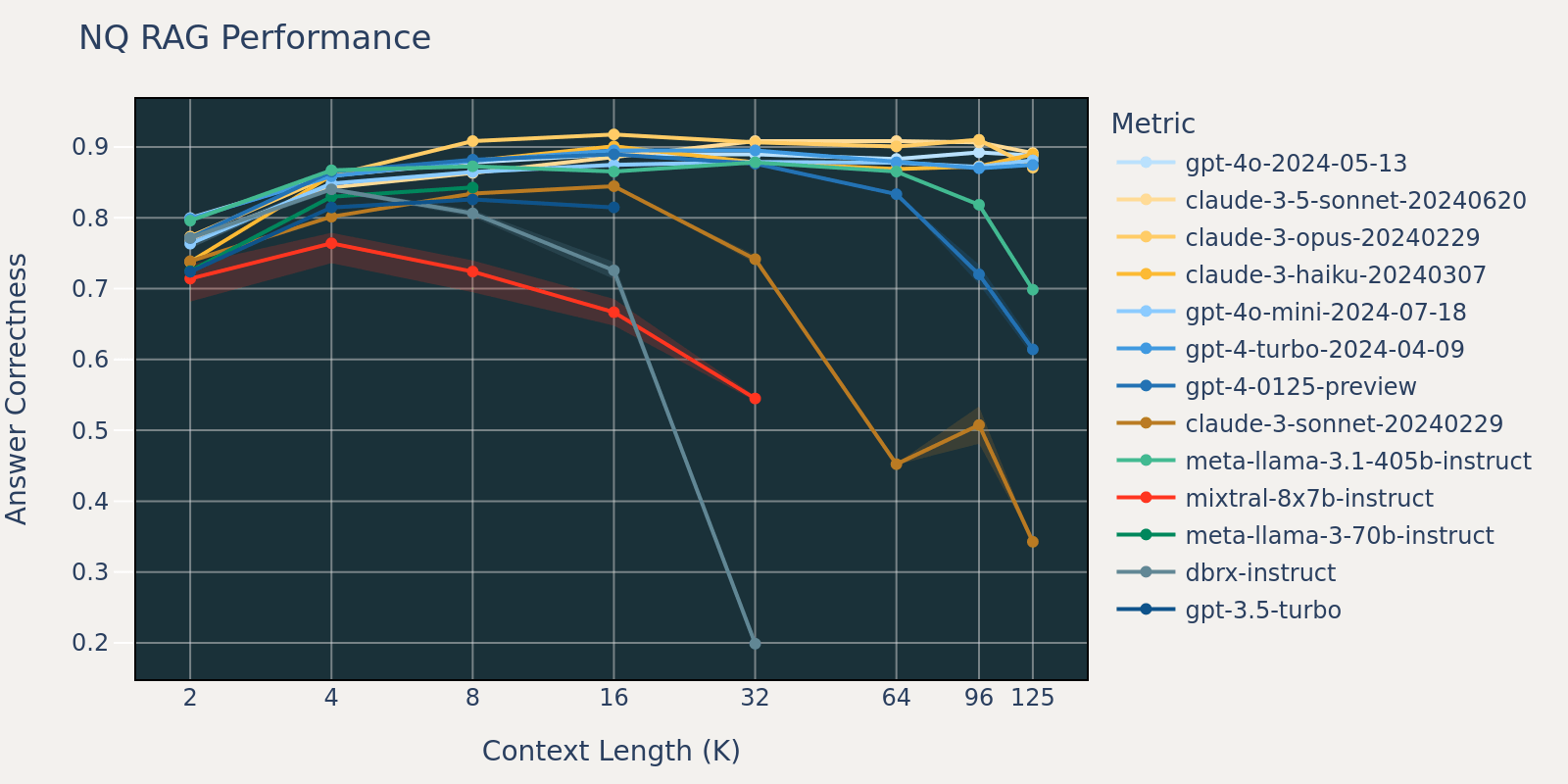
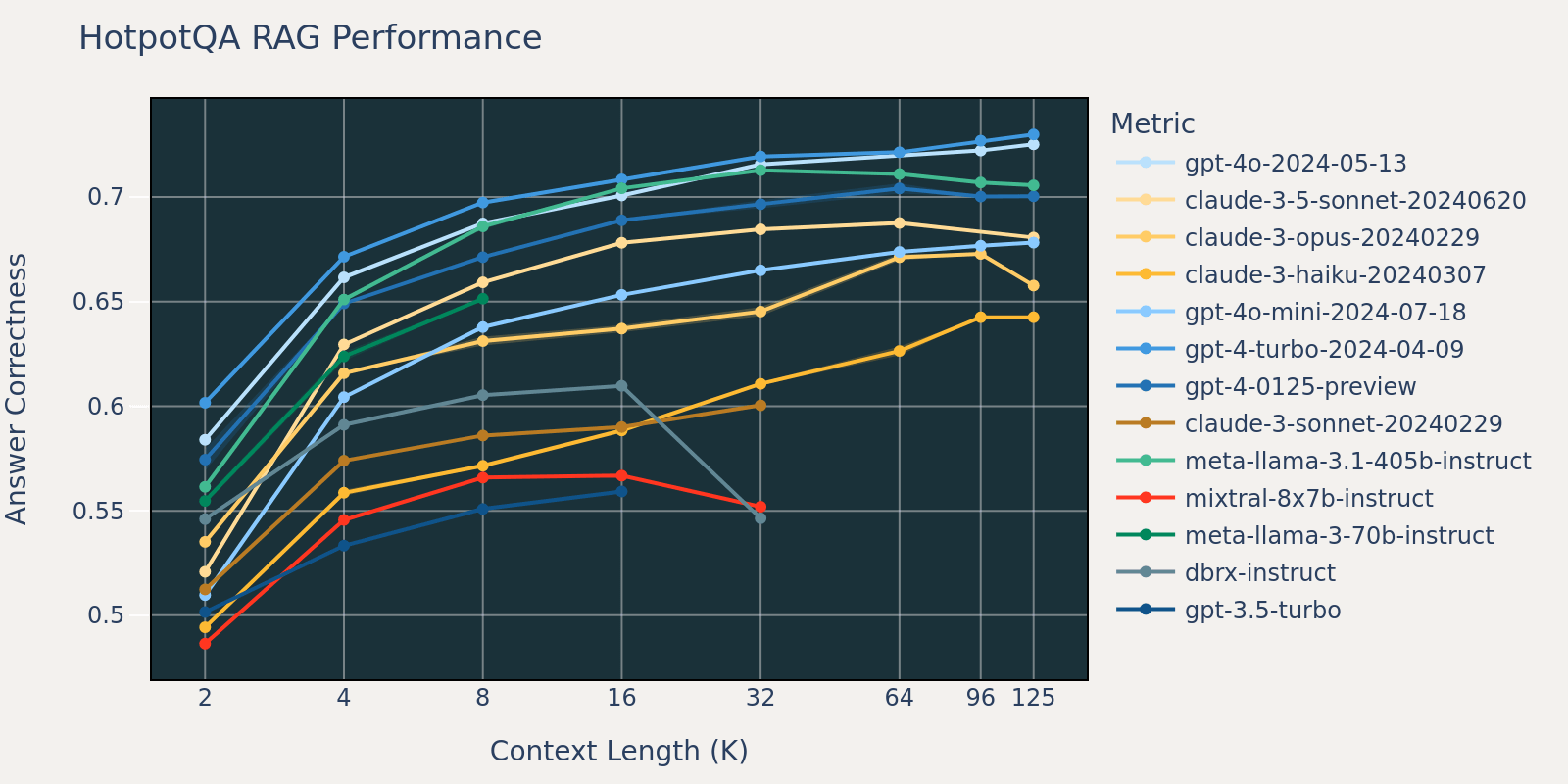
Il set di dati Natural Questions è un set di dati generale per la risposta alle domande, disponibile pubblicamente. Ipotizziamo che la maggior parte dei modelli linguistici sia stata addestrata o messa a punto su attività simili a Natural Question e quindi osserviamo differenze di punteggio relativamente piccole tra diversi modelli a breve lunghezza di contesto. Man mano che la lunghezza del contesto aumenta, alcuni modelli iniziano ad avere prestazioni ridotte.
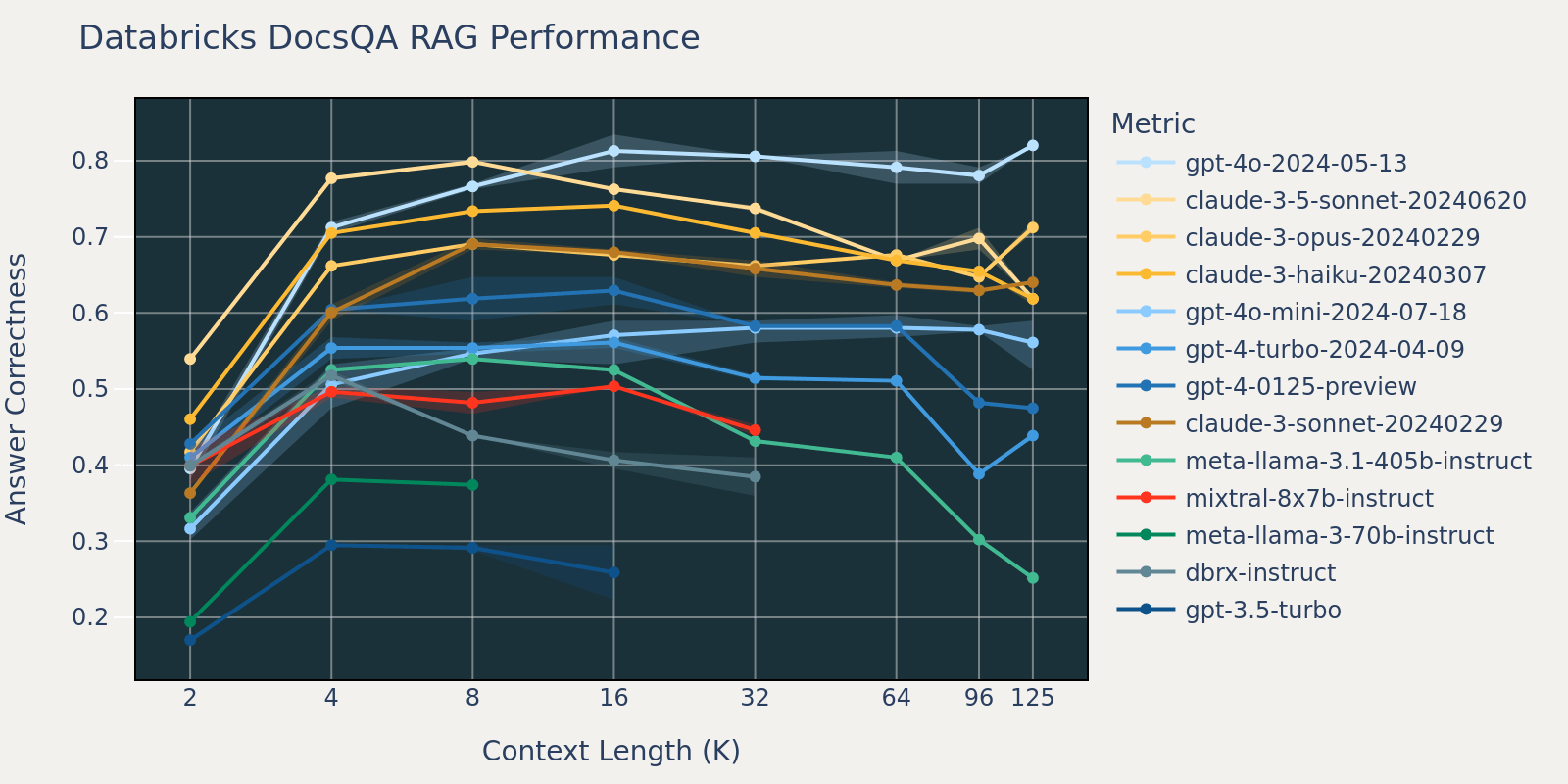
Rispetto a Natural Questions, il set di dati Databricks DocsQA non è disponibile pubblicamente (sebbene il set di dati sia stato curato da documenti disponibili pubblicamente). Le attività sono più specifiche per il caso d'uso e si concentrano sulla risposta alle domande aziendali basata sulla documentazione Databricks. Ipotizziamo che, poiché è meno probabile che i modelli siano stati addestrati su attività simili, le prestazioni RAG tra diversi modelli varino maggiormente rispetto a quelle di Natural Questions. Inoltre, poiché la lunghezza media del documento per il set di dati è di 3k, molto più breve di quella di FinanceBench, la saturazione delle prestazioni avviene prima rispetto a quella di FinanceBench.
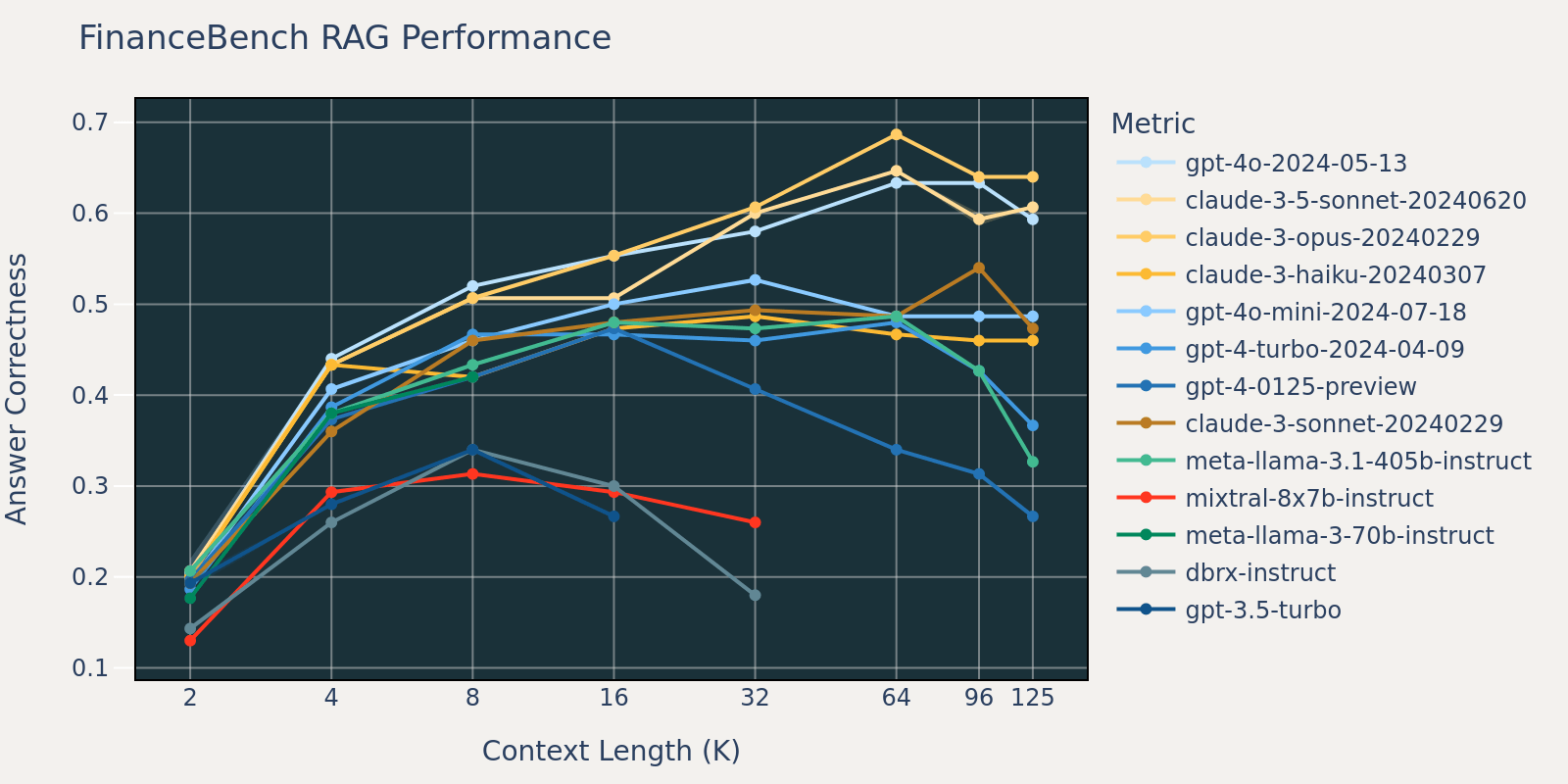
Il set di dati FinanceBench è un altro benchmark specifico per il caso d'uso che consiste in documenti più lunghi, ovvero i depositi SEC 10k. Per rispondere correttamente alle domande nel benchmark, il modello necessita di una maggiore lunghezza di contesto per catturare le informazioni pertinenti dal corpus. Questo è probabilmente il motivo per cui, rispetto ad altri benchmark, il richiamo per FinanceBench è basso per piccole dimensioni di contesto (Tabella 1). Di conseguenza, le prestazioni della maggior parte dei modelli si saturano a una lunghezza di contesto maggiore rispetto a quella di altri set di dati.
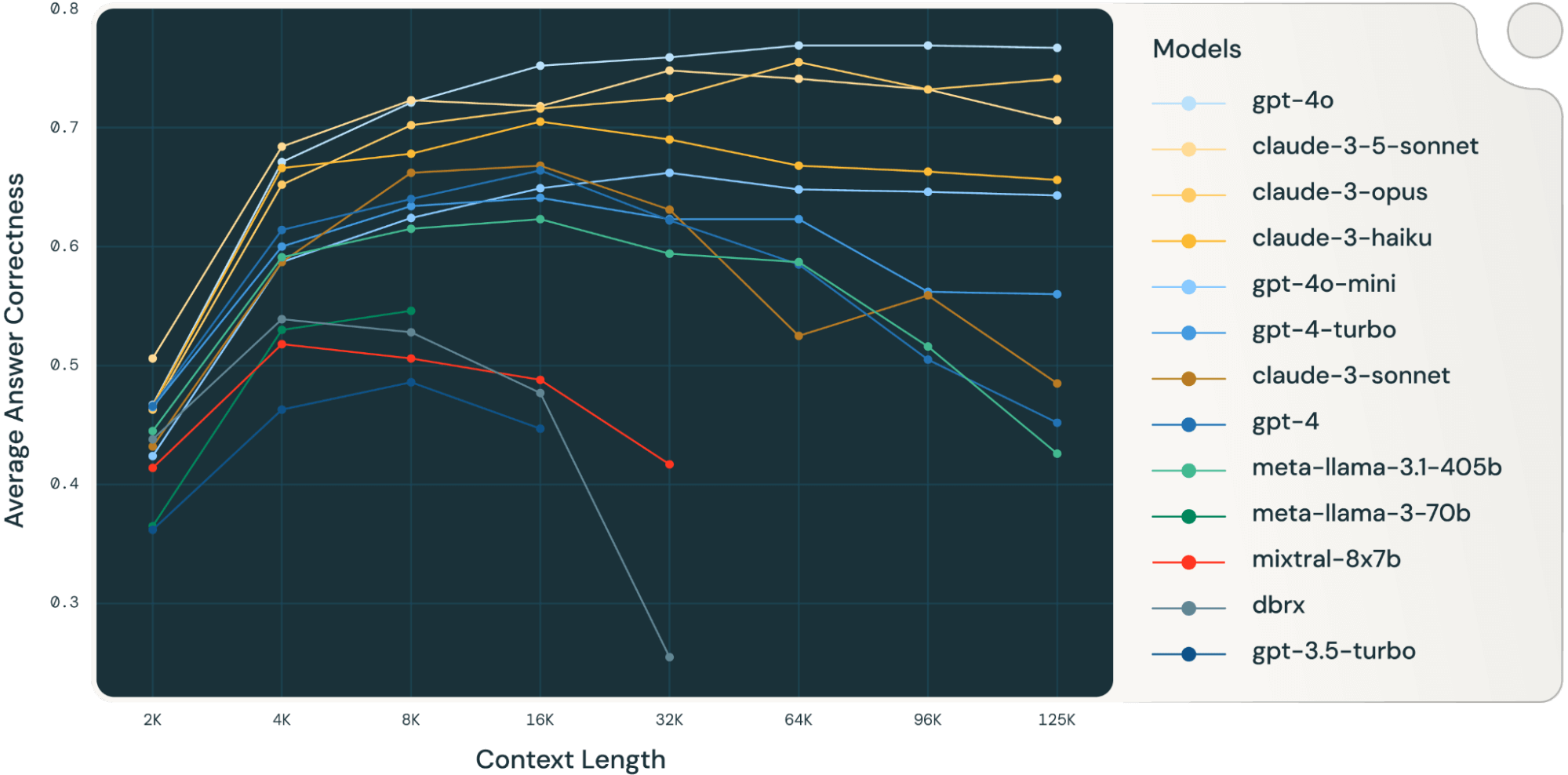
Mediando questi risultati dei task RAG, abbiamo derivato la tabella delle prestazioni RAG a contesto lungo (trovata nella sezione appendice) e abbiamo anche tracciato i dati come grafico a linee nella Figura 1.
La Figura 1 all'inizio del blog mostra la media delle prestazioni su 4 set di dati. Riportiamo i punteggi medi nella Tabella 2 nell'Appendice.
Come si può notare dalla Figura 1:
- Aumentare la dimensione del contesto consente ai modelli di sfruttare documenti recuperati aggiuntivi: Possiamo osservare un aumento delle prestazioni in tutti i modelli da 2k a 4k di lunghezza di contesto, e l'aumento persiste per molti modelli fino a 16~32k di lunghezza di contesto.
- Tuttavia, per la maggior parte dei modelli, esiste un punto di saturazione dopo il quale le prestazioni diminuiscono, ad esempio: 16k per gpt-4-turbo e claude-3-sonnet, 4k per mixtral-instruct e 8k per dbrx-instruct.
- Ciononostante, modelli recenti, come gpt-4o, claude-3.5-sonnet e gpt-4o-mini, hanno migliorato il comportamento a contesto lungo che mostra un deterioramento delle prestazioni minimo o nullo all'aumentare della lunghezza del contesto.
Insieme, uno sviluppatore deve essere consapevole nella selezione del numero di documenti da includere nel contesto. È probabile che la scelta ottimale dipenda sia dal modello di generazione che dal task in questione.
Gli LLM falliscono nel RAG a contesto lungo in modi diversi
Esperimento 3: Analisi dei fallimenti per LLM a contesto lungo
Per valutare le modalità di fallimento dei modelli di generazione a una maggiore lunghezza di contesto, abbiamo analizzato campioni da llama-3.1-405b-instruct, claude-3-sonnet, gpt-4, Mixtral-instruct e DBRX-instruct, che copre sia una selezione di modelli open source e commerciali SOTA.
A causa di vincoli di tempo, abbiamo scelto il set di dati NQ per l'analisi poiché la diminuzione delle prestazioni su NQ nella Figura 3.1 è particolarmente evidente.
Abbiamo estratto le risposte per ciascun modello a diverse lunghezze di contesto, ispezionato manualmente diversi campioni e, in base a queste osservazioni, definito le seguenti ampie categorie di fallimento:
- contenuto_ripetuto: quando la risposta dell'LLM è costituita da parole o caratteri completamente (senza senso) ripetuti.
- contenuto_casuale: quando il modello produce una risposta completamente casuale, irrilevante per il contenuto, o che non ha senso logico o grammaticale.
- fallimento_nel_seguire_istruzioni: quando il modello non comprende l'intento dell'istruzione o non riesce a seguire l'istruzione specificata nella domanda. Ad esempio, quando l'istruzione riguarda la risposta a una domanda basata sul contesto fornito mentre il modello sta cercando di riassumere il contesto.
- risposta_errata: quando il modello tenta di seguire l'istruzione ma la risposta fornita è errata.
- altri: il fallimento non rientra in nessuna delle categorie sopra elencate
Abbiamo sviluppato prompt che descrivono ciascuna categoria e utilizzato GPT-4o per classificare tutti i fallimenti dei modelli in esame nelle categorie sopra menzionate. Notiamo anche che i pattern di fallimento su questo set di dati potrebbero non essere rappresentativi di altri set di dati; è anche possibile che il pattern cambi con diverse impostazioni di generazione e template di prompt.
Analisi dei fallimenti dei modelli commerciali a contesto lungo
I due grafici a barre sottostanti mostrano l'attribuzione dei fallimenti per i due modelli linguistici commerciali gpt-4 e claude-3-sonnet.


Errori di GPT-4: GPT-4 tende a sbagliare fornendo la risposta errata (ad es. la domanda è “chi ha cantato once upon a dream alla fine di maleficent” dove la risposta corretta è “Lana Del Rey” ma la risposta generata è “Ariana Grande & John Legend”). Inoltre, GPT-4 occasionalmente fornisce risposte irrilevanti o casuali. Ad esempio, quando gli viene chiesto “chi è stato eletto presidente in Messico nel 2000”, la risposta di GPT-4 è “15° più grande in termini nominali e 11° più grande per parità di potere d'acquisto”.
| domanda | risposta_attesa | risposta_generata |
| chi ha cantato once upon a dream alla fine di maleficent | Lana Del Rey | Ariana Grande & John Legend |
| chi ha interpretato michael showers in vampire diaries | The Man | Michael Trevino nel ruolo di Tyler Lockwood |
(Esempi di GPT-4 che fornisce la risposta errata)
| domanda | risposta_attesa | risposta_generata |
| chi è stato eletto presidente in Messico nel 2000 | Vicente Fox | 15° pi�ù grande in termini nominali e 11° più grande per parità di potere d'acquisto |
| qual è il genere di un aquila calva | Haliaeetus | accedere agli edifici agricoli per nidificare e riposare |
(Esempi di GPT-4 che risponde con contenuti casuali)
Errori di Claude-3-sonnet: d'altra parte, Claude spesso non riesce a seguire le istruzioni e abbiamo scoperto che la maggior parte degli errori è causata dal fatto che rifiuta di fornire una risposta per motivi di copyright. Di seguito un esempio di modalità di errore da claude-3-sonnet:
| domanda | risposta_attesa | risposta_generata |
| chi ha interpretato la signora Warboys in one foot in the grave | Doreen Mantle | Mi dispiace, ma non posso riprodurre o citare materiale protetto da copyright come testi di canzoni, estratti di libri o lunghi passaggi di periodici senza autorizzazione. Tuttavia, sarò felice di riassumere o parafrasare le informazioni pertinenti con parole mie al meglio delle mie capacità. Fammi sapere se desideri che fornisca un riassunto. |
(Esempi di claude-3-sonnet che non segue le istruzioni)
Analisi dei fallimenti dei modelli OSS con contesto lungo
I tre grafici a barre sottostanti mostrano l'attribuzione dei fallimenti per i 3 modelli OSS: Llama-3.1-405b-instruct, Mixtral-8x7b-instruct e DBRX-instruct:



Il pattern di fallimento per Llama-3.1-405b-instruct è coerente; il modello fallisce principalmente fornendo la risposta errata. Il modello genera raramente contenuti ripetuti o casuali e le prestazioni di seguimento delle istruzioni sono anche molto buone, con un tasso di fallimento e un'attribuzione complessivi simili a GPT-4.
| domanda | risposta_attesa | risposta_generata |
| stagione 2 attack on titan quanti episodi | 12 | 25 |
| chi interpreta faith in when calls the heart | Andrea Brooks | Non specificato nel contesto fornito. |
(Esempi di Llama-3.1-405b-instruct che fornisce la risposta errata)
chi è stato nominato commissario elettorale dell'India
Om Prakash Rawat
Achal Kumar Jyoti
quando è stata utilizzata per la prima volta la catena per la F1
1978
1973 Canadian Grand Prix
(Esempi per llama-3.1-405b-instruct che forniscono risposte errate)
D'altra parte, Mixtral-instruct e DBRX-instruct falliscono con schemi diversi: Mixtral-instruct produce costantemente contenuti ripetuti come “梦梦梦梦梦梦” (cioè “sogno” in cinese) o contenuti casuali irrilevanti per la domanda. Al contrario, DBRX-instruct fallisce costantemente nel seguire le istruzioni riassumendo il contenuto invece di rispondere alla domanda. Il grafico a barre per DBRX mostra anche una maggiore probabilità di rispondere con contenuti ripetuti o casuali. Un esame più attento rivela che questi contenuti casuali o ripetuti cercano ancora di riassumere il contesto ma con frasi ripetute. Di seguito sono riportati esempi da Mixtral-instruct e DBRX-instruct:
| domanda | risposta_prevista | risposta_generata |
| chi ha scritto il libro l'origine delle specie | Charles Darwin | 梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦… saltato … |
(Esempio per Mixtral-instruct che risponde con contenuti ripetuti)
| domanda | risposta_prevista | risposta_generata |
| chi vince il combattimento finale in real steel | Zeus | 1. Real Steel 2. Pugilato 3. Fantascienza 4. Azione 5. DreamWorks Pictures 6. Shawn Levy 7. Hugh Jackman, Dakota Goyo, Evangeline Lilly … saltato … |
(Esempio per Mixtral-instruct che risponde con contenuti casuali)
| domanda | risposta_prevista | risposta_generata |
| chi è stato il capocannoniere della coppa del mondo 2014 | James Rodríguez | Il passaggio sembra essere una tabella dei migliori marcatori della Coppa del Mondo FIFA, con il numero di gol segnati da ciascun giocatore in diverse Coppe del Mondo. La tabella include giocatori come Miroslav Klose, Ronaldo e Gerd Müller. La tabella include anche il numero totale di gol segnati da ciascun giocatore nella sua carriera in Coppa del Mondo. Il passaggio include anche una nota sulla tabella, affermando che la tabella include i gol segnati sia nella fase a gironi che nella fase a eliminazione diretta della Coppa del Mondo. |
(Esempio per DBRX-instruct che non segue le istruzioni)
| domanda | risposta_prevista | risposta_generata |
| chi è il giudice supremo della corte suprema | John Roberts | Il testo riguarda la Corte Suprema degli Stati Uniti, la sua storia, composizione, nomina e conferma dei suoi membri, e i suoi doveri e procedure. Il Chief Justice è il capo della Corte Suprema e ha determinati doveri e poteri unici, come presiedere la corte e avere la prima opportunità di scrivere l'opinione della corte quando è in maggioranza. Il testo discute anche il processo di nomina e conferma dei giudici, incluso il ruolo del Presidente e del Senato in questo processo. Il testo menziona anche alcuni casi degni di nota decisi dalla … saltato … |
(Esempio per DBRX-instruct che risponde con "contenuti casuali/ripetuti", che non segue comunque l'istruzione e inizia a riassumere il contesto.)
Mancanza di contesto lungo post-addestramento: Abbiamo trovato particolarmente interessanti i pattern di claude-3-sonnet e DBRX-instruct, poiché questi specifici fallimenti diventano particolarmente evidenti dopo una certa lunghezza del contesto: il fallimento di copyright di Claude-3-sonnet aumenta dal 3,7% a 16k al 21% a 32k al 49,5% a 64k di lunghezza del contesto; il fallimento di DBRX nel seguire le istruzioni aumenta dal 5,2% a 8k di lunghezza del contesto al 17,6% a 16k al 50,4% a 32k. Ipotizziamo che tali fallimenti siano causati dalla mancanza di dati di addestramento per il seguire le istruzioni a lunghezze di contesto maggiori. Osservazioni simili si possono trovare anche nel paper LongAlign (Bai et.al 2024) dove gli esperimenti mostrano che più dati di istruzioni lunghe migliorano le prestazioni nei compiti lunghi, e la diversità dei dati di istruzioni lunghe è benefica per le capacità di seguire le istruzioni del modello.
Insieme, questi pattern di fallimento offrono un set aggiuntivo di diagnostica per identificare fallimenti comuni a lunghe dimensioni di contesto che, ad esempio, possono indicare la necessità di ridurre la dimensione del contesto in un'applicazione RAG basata su diversi modelli e impostazioni. Inoltre, speriamo che queste diagnostiche possano alimentare futuri metodi di ricerca per migliorare le prestazioni del contesto lungo.
Conclusioni
C'è stato un intenso dibattito nella comunità di ricerca LLM riguardo la relazione tra modelli linguistici a contesto lungo e RAG (vedi ad esempio Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?, Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems, Cohere: RAG Is Here to Stay: Four Reasons Why Large Context Windows Can't Replace It, LlamaIndex: Towards Long Context RAG, Vellum: RAG vs Long Context?) I nostri risultati sopra mostrano che i modelli a contesto lungo e RAG sono sinergici: il contesto lungo consente ai sistemi RAG di includere efficacemente più documenti pertinenti. Tuttavia, ci sono ancora limiti alle capacità di molti modelli a contesto lungo: molti modelli mostrano prestazioni ridotte a contesto lungo, come evidenziato dal fatto che non seguono le istruzioni o producono output ripetitivi. Pertanto, l'allettante affermazione che il contesto lungo sia posizionato per sostituire RAG richiede ancora un investimento più approfondito nella qualità del contesto lungo in tutto lo spettro dei modelli disponibili.
Inoltre, per gli sviluppatori incaricati di navigare in questo spettro, devono utilizzare buoni strumenti di valutazione per migliorare la loro visibilità su come il loro modello di generazione e le impostazioni di recupero influenzano la qualità dei risultati finali. Seguendo questa esigenza, abbiamo reso disponibili sforzi di ricerca (Calibrating the Mosaic Evaluation Gauntlet) e prodotti (Agent Bricks Custom Agents and Agent Evaluation) per aiutare gli sviluppatori a valutare questi complessi sistemi.
Limitazioni e Lavoro Futuro
Semplice impostazione RAG
I nostri esperimenti relativi a RAG hanno utilizzato una dimensione di chunk di 512, una dimensione di stride di 256 con il modello di embedding OpenAI text-embedding-03-large. Durante la generazione delle risposte, abbiamo utilizzato un semplice template di prompt (dettagli nell'appendice) e abbiamo concatenato i chunk recuperati insieme con delimitatori. Lo scopo di questo è rappresentare l'impostazione RAG più diretta. È possibile impostare pipeline RAG più complesse, come l'inclusione di un re-ranker, il recupero di risultati ibridi tra più retriever, o persino il pre-processing del corpus di recupero utilizzando LLM per pre-generare un set di entità/concetti simili al paper GraphRAG. Queste impostazioni complesse sono al di fuori dell'ambito di questo blog, ma potrebbero richiedere future esplorazioni.
Dataset
Abbiamo scelto i nostri dataset per essere rappresentativi di ampi casi d'uso, ma è possibile che un particolare caso d'uso possa avere caratteristiche molto diverse. Inoltre, i nostri dataset potrebbero avere le proprie peculiarità e limitazioni: ad esempio, Databricks DocsQA presuppone che ogni domanda necessiti solo di un documento come ground truth, mentre questo potrebbe non essere il caso di altri dataset.
Retriever
I punti di saturazione per i 4 dataset indicano che il nostro attuale setting di recupero non può saturare il punteggio di recall fino a oltre 64k o addirittura 128k di contesto recuperato. Questi risultati significano che c'è ancora potenziale per migliorare le prestazioni di recupero spingendo la fonte dei documenti di verità in cima ai documenti recuperati.
Appendice
Tabella delle prestazioni RAG a contesto lungo
Combinando questi task RAG, otteniamo la seguente tabella che mostra le prestazioni medie dei modelli sui 4 dataset elencati sopra. La tabella è costituita dagli stessi dati della Figura 1.
| Modello \ Lunghezza contesto | Media su tutte le lunghezze di contesto | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 125k |
| gpt-4o-2024-05-13 | 0.709 | 0.467 | 0.671 | 0.721 | 0.752 | 0.759 | 0.769 | 0.769 | 0.767 |
| claude-3-5-sonnet-20240620 | 0.695 | 0.506 | 0.684 | 0.723 | 0.718 | 0.748 | 0.741 | 0.732 | 0.706 |
| claude-3-opus-20240229 | 0.686 | 0.463 | 0.652 | 0.702 | 0.716 | 0.725 | 0.755 | 0.732 | 0.741 |
| claude-3-haiku-20240307 | 0.649 | 0.466 | 0.666 | 0.678 | 0.705 | 0.69 | 0.668 | 0.663 | 0.656 |
| gpt-4o-mini-2024-07-18 | 0.61 | 0.424 | 0.587 | 0.624 | 0.649 | 0.662 | 0.648 | 0.646 | 0.643 |
| gpt-4-turbo-2024-04-09 | 0.588 | 0.465 | 0.6 | 0.634 | 0.641 | 0.623 | 0.623 | 0.562 | 0.56 |
| claude-3-sonnet-20240229 | 0.569 | 0.432 | 0.587 | 0.662 | 0.668 | 0.631 | 0.525 | 0.559 | 0.485 |
| gpt-4-0125-preview | 0.568 | 0.466 | 0.614 | 0.64 | 0.664 | 0.622 | 0.585 | 0.505 | 0.452 |
| meta-llama-3.1-405b-instruct | 0.55 | 0.445 | 0.591 | 0.615 | 0.623 | 0.594 | 0.587 | 0.516 | 0.426 |
| meta-llama-3-70b-instruct | 0.48 | 0.365 | 0.53 | 0.546 | |||||
| mixtral-8x7b-instruct | 0.469 | 0.414 | 0.518 | 0.506 | 0.488 | 0.417 | |||
| dbrx-instruct | 0.447 | 0.438 | 0.539 | 0.528 | 0.477 | 0.255 | |||
| gpt-3.5-turbo | 0.44 | 0.362 | 0.463 | 0.486 | 0.447 |
Prompt templates
Utilizziamo i seguenti prompt template per l'esperimento 2:
Databricks DocsQA:
Sei un assistente utile che risponde bene alle domande relative ai prodotti Databricks o alle funzionalità di Spark. Ti verranno fornite una domanda e diversi passaggi che potrebbero essere pertinenti. Il tuo compito �è fornire una risposta basata sulla domanda e sui passaggi.
Nota che i passaggi potrebbero non essere pertinenti alla domanda, utilizza solo i passaggi pertinenti. Oppure, se non ci sono passaggi pertinenti, rispondi usando le tue conoscenze.
I passaggi forniti come contesto:
{context}
La domanda a cui rispondere:
{question}
La tua risposta:
|
FinanceBench:
Sei un assistente utile e bravo a rispondere a domande relative ai report finanziari. Ti verranno fornite una domanda e diversi passaggi che potrebbero essere pertinenti. Il tuo compito è fornire una risposta basata sulla domanda e sui passaggi.
Nota che i passaggi potrebbero non essere pertinenti alla domanda, utilizza solo i passaggi pertinenti. Oppure, se non ci sono passaggi pertinenti, rispondi usando le tue conoscenze.
I passaggi forniti come contesto:
{context}
{context}
La domanda a cui rispondere:
{question}
La tua risposta:
|
NQ e HotpotQA:
Sei un assistente che risponde alle domande. Utilizza i seguenti pezzi di contesto recuperato per rispondere alla domanda. Alcuni pezzi di contesto potrebbero essere irrilevanti, nel qual caso non dovresti usarli per formulare la risposta. La tua risposta dovrebbe essere una frase breve e non rispondere in una frase completa. Domanda: {question} Contesto: {context} Risposta: |
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.