Announcing Agent Bricks Custom Agents and Agent Evaluation
Costruisci App di Agenti e Generazione Aumentata da Recupero di Qualità per la Produzione
di Eric Peter, Akhil Gupta, Mani Parkhe, Alkis Polyzotis, Chenen Liang, Maheswaran Venkatachalam, Michael Carbin e Niall Turbitt
Databricks ha annunciato l'anteprima pubblica di Agent Bricks Custom Agents e Agent Evaluation insieme al nostro Generative AI Cookbook al Data + AI Summit 2024.
Questi strumenti sono progettati per aiutare gli sviluppatori a creare e distribuire applicazioni Agentic e Retrieval Augmented Generation (RAG) di alta qualità all'interno della Databricks Data Intelligence Platform.
Sfide nella creazione di applicazioni Generative AI di alta qualità
Sebbene la creazione di un proof of concept per la tua applicazione GenAI sia relativamente semplice, fornire un'applicazione di alta qualità si è rivelato impegnativo per un gran numero di clienti. Per soddisfare lo standard di qualità richiesto per le applicazioni rivolte ai clienti, l'output dell'IA deve essere accurato, sicuro e governato. Per raggiungere questo livello di qualità, gli sviluppatori faticano a
- Scegliere le metriche giuste per valutare la qualità dell'applicazione
- Raccogliere in modo efficiente il feedback umano per misurare la qualità dell'applicazione
- Identificare la causa principale dei problemi di qualità
- Iterare rapidamente per migliorare la qualità dell'applicazione prima di distribuirla in produzione
Presentazione di Agent Bricks Custom Agents e Agent Evaluation
Sviluppati in collaborazione con il team di ricerca AI di Databricks, Agent Framework e Agent Evaluation forniscono diverse funzionalità create specificamente per affrontare queste sfide:
Ottieni rapidamente feedback umano - Agent Evaluation ti consente di definire come dovrebbero essere le risposte di alta qualità per la tua applicazione GenAI, invitando esperti di materia della tua organizzazione a rivedere la tua applicazione e fornire feedback sulla qualità delle risposte, anche se non sono utenti Databricks.
Valutazione semplice della tua applicazione GenAI - Agent Evaluation fornisce una suite di metriche, sviluppate in collaborazione con Databricks AI Research, per misurare la qualità della tua applicazione. Registra automaticamente le risposte e il feedback degli esseri umani in una tabella di valutazione e ti consente di analizzare rapidamente i risultati per identificare potenziali problemi di qualità. I nostri giudici AI forniti dal sistema valutano queste risposte in base a criteri comuni come accuratezza, allucinazione, dannosità e utilità, identificando le cause principali di eventuali problemi di qualità. Questi giudici sono calibrati utilizzando il feedback dei tuoi esperti di materia, ma possono anche misurare la qualità senza alcuna etichetta umana.
Puoi quindi sperimentare e ottimizzare varie configurazioni della tua applicazione utilizzando Agent Framework per affrontare questi problemi di qualità, misurando l'impatto di ogni modifica sulla qualità della tua app. Una volta raggiunto il tuo livello di qualità, puoi utilizzare le metriche di costo e latenza di Agent Evaluation per determinare il compromesso ottimale tra qualità/costo/latenza.
Flusso di lavoro di sviluppo veloce e end-to-end - Agent Framework è integrato con MLflow e consente agli sviluppatori di utilizzare le API MLflow standard come log_model e mlflow.evaluate per registrare un'applicazione GenAI e valutarne la qualità. Una volta soddisfatti della qualità, gli sviluppatori possono utilizzare MLflow per distribuire queste applicazioni in produzione e ottenere feedback dagli utenti per migliorare ulteriormente la qualità. Agent Framework e Agent Evaluation si integrano con MLflow e la Data Intelligence Platform per fornire un percorso completamente definito per creare e distribuire applicazioni GenAI.
Gestione del ciclo di vita dell'app - Agent Framework fornisce un SDK semplificato per la gestione del ciclo di vita delle applicazioni agentiche, dalla gestione delle autorizzazioni alla distribuzione con Databricks Model Serving.
Per aiutarti a iniziare a creare applicazioni di alta qualità utilizzando Agent Framework e Agent Evaluation, Generative AI Cookbook è una guida definitiva che dimostra ogni passaggio per portare la tua app da POC a produzione, spiegando le opzioni e gli approcci di configurazione più importanti che possono aumentare la qualità dell'applicazione.
Creazione di un agente RAG di alta qualità
Per comprendere queste nuove funzionalità, esaminiamo un esempio di creazione di un'applicazione agentica di alta qualità utilizzando Agent Framework e miglioramento della sua qualità utilizzando Agent Evaluation. Puoi trovare il codice completo per questo esempio e altri esempi avanzati nel Generative AI Cookbook qui.
In questo esempio, creeremo e distribuiremo una semplice applicazione RAG che recupera chunk pertinenti da un indice vettoriale pre-creato e li riassume come risposta a una query. Puoi creare l'applicazione RAG utilizzando qualsiasi framework, incluso il codice Python nativo, ma in questo esempio utilizziamo Langchain.
La prima cosa che vogliamo fare è sfruttare MLflow per abilitare i trace e distribuire l'applicazione. Questo può essere fatto aggiungendo tre semplici righe nel codice dell'applicazione (sopra) che consentono ad Agent Framework di fornire trace e un modo semplice per osservare e debuggare l'applicazione.
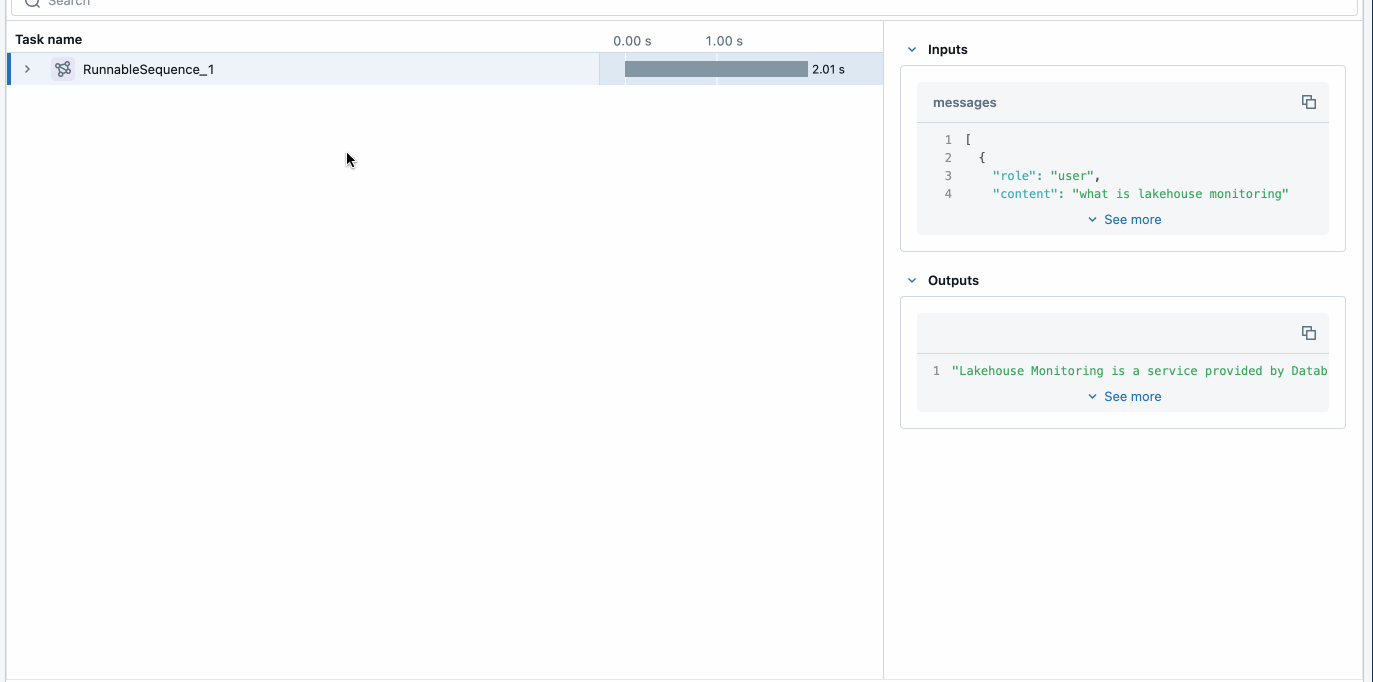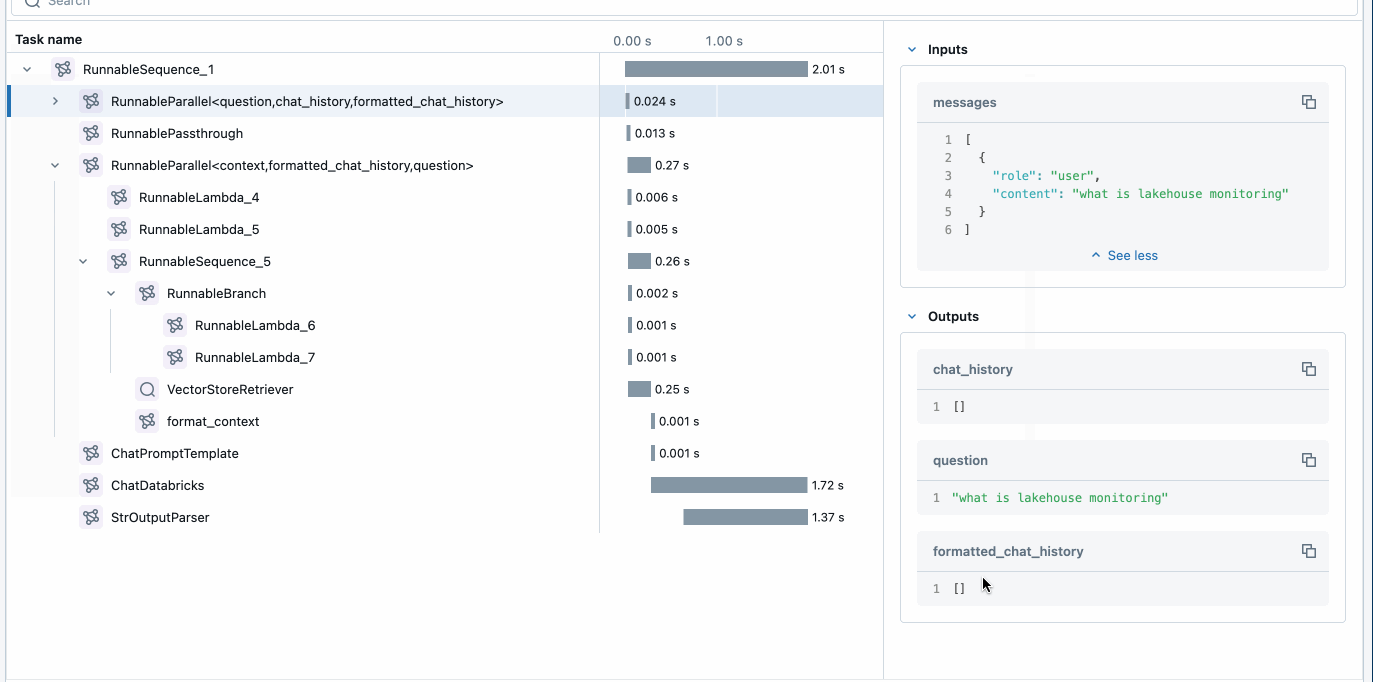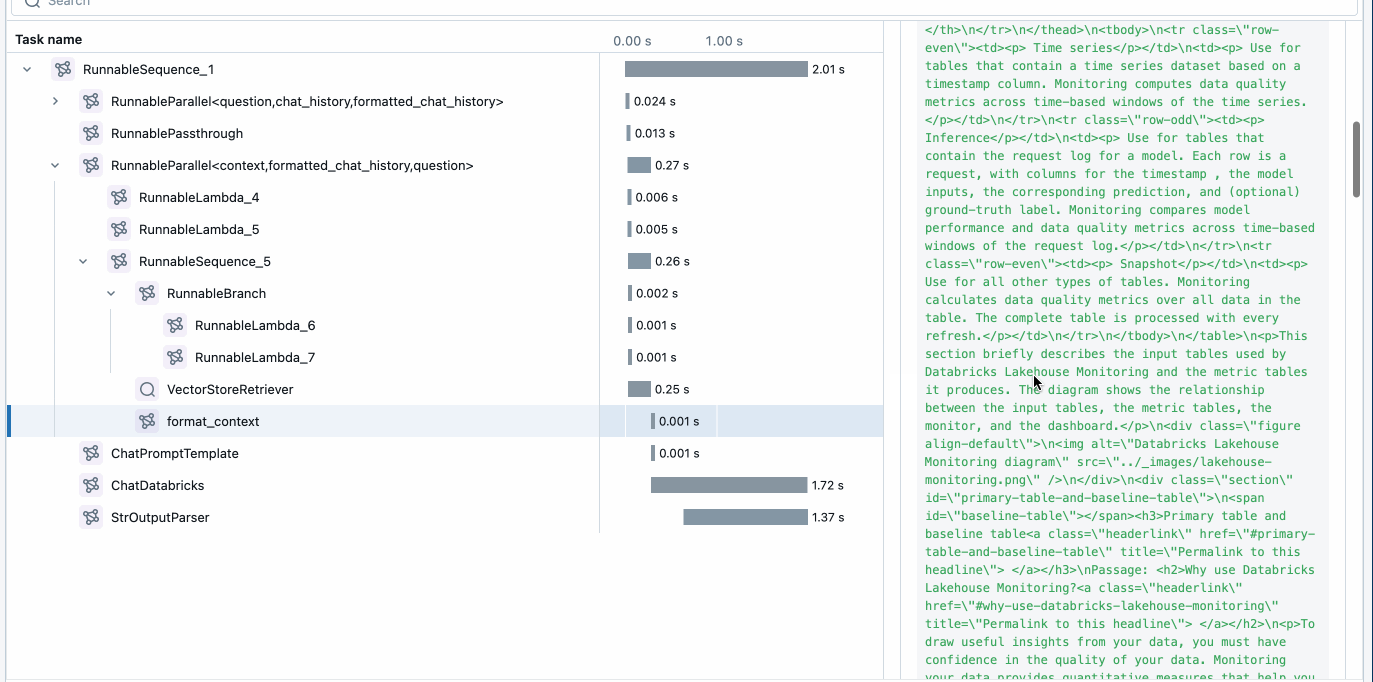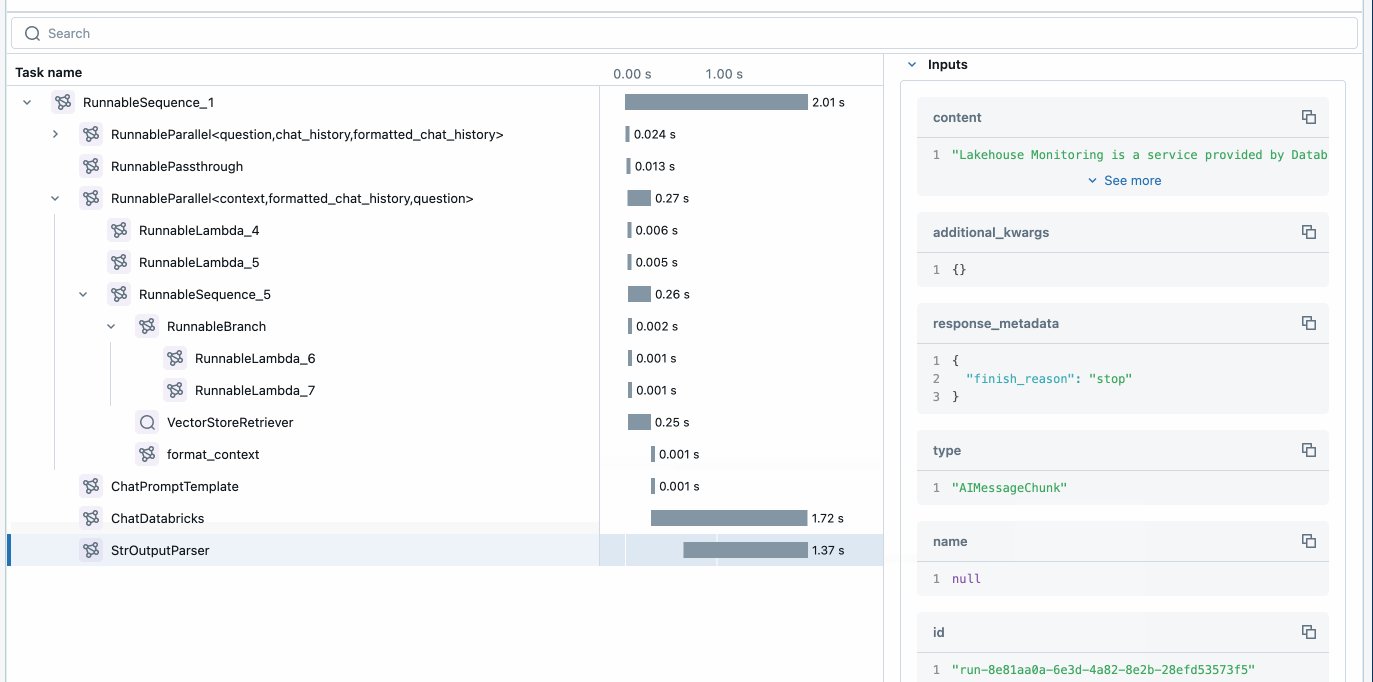
MLflow Tracing fornisce osservabilità nella tua applicazione durante lo sviluppo e la produzione
Il passo successivo è registrare l'applicazione GenAI in Unity Catalog e distribuirla come proof of concept per ottenere feedback dagli stakeholder utilizzando l'applicazione di revisione di Agent Evaluation.
Puoi condividere il link del browser con gli stakeholder e iniziare subito a ricevere feedback! Il feedback viene archiviato come tabelle delta nel tuo Unity Catalog e può essere utilizzato per creare un set di dati di valutazione.
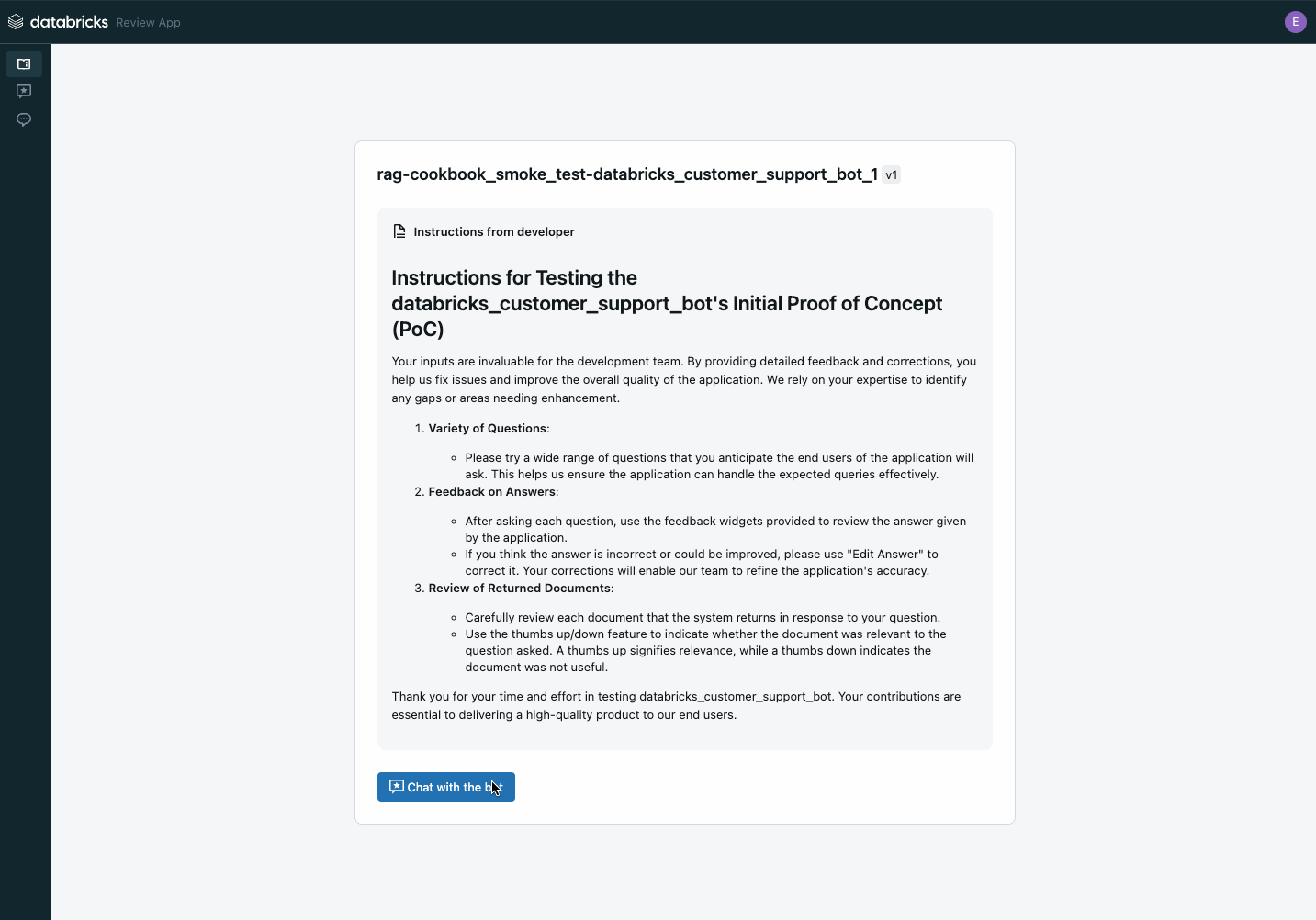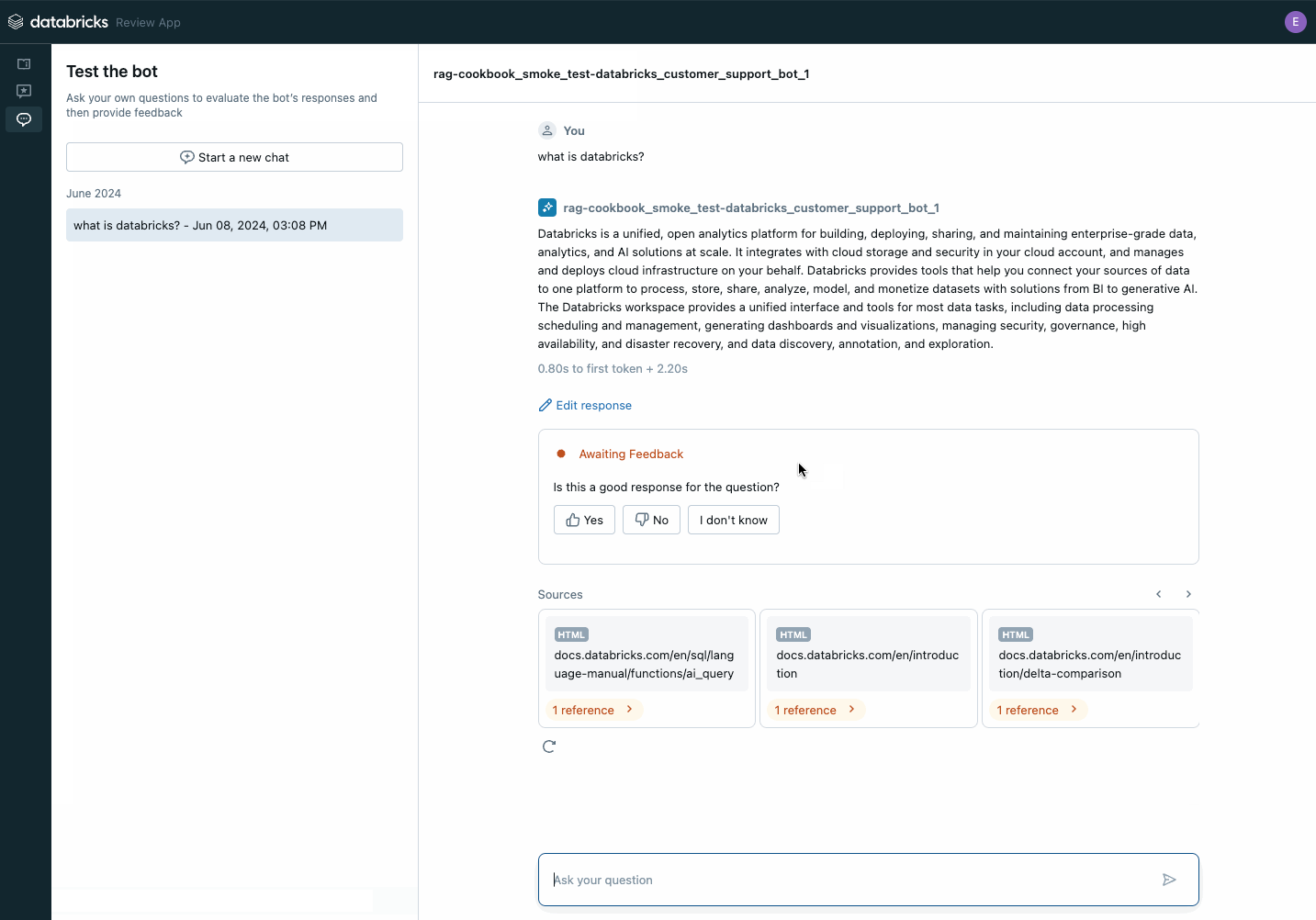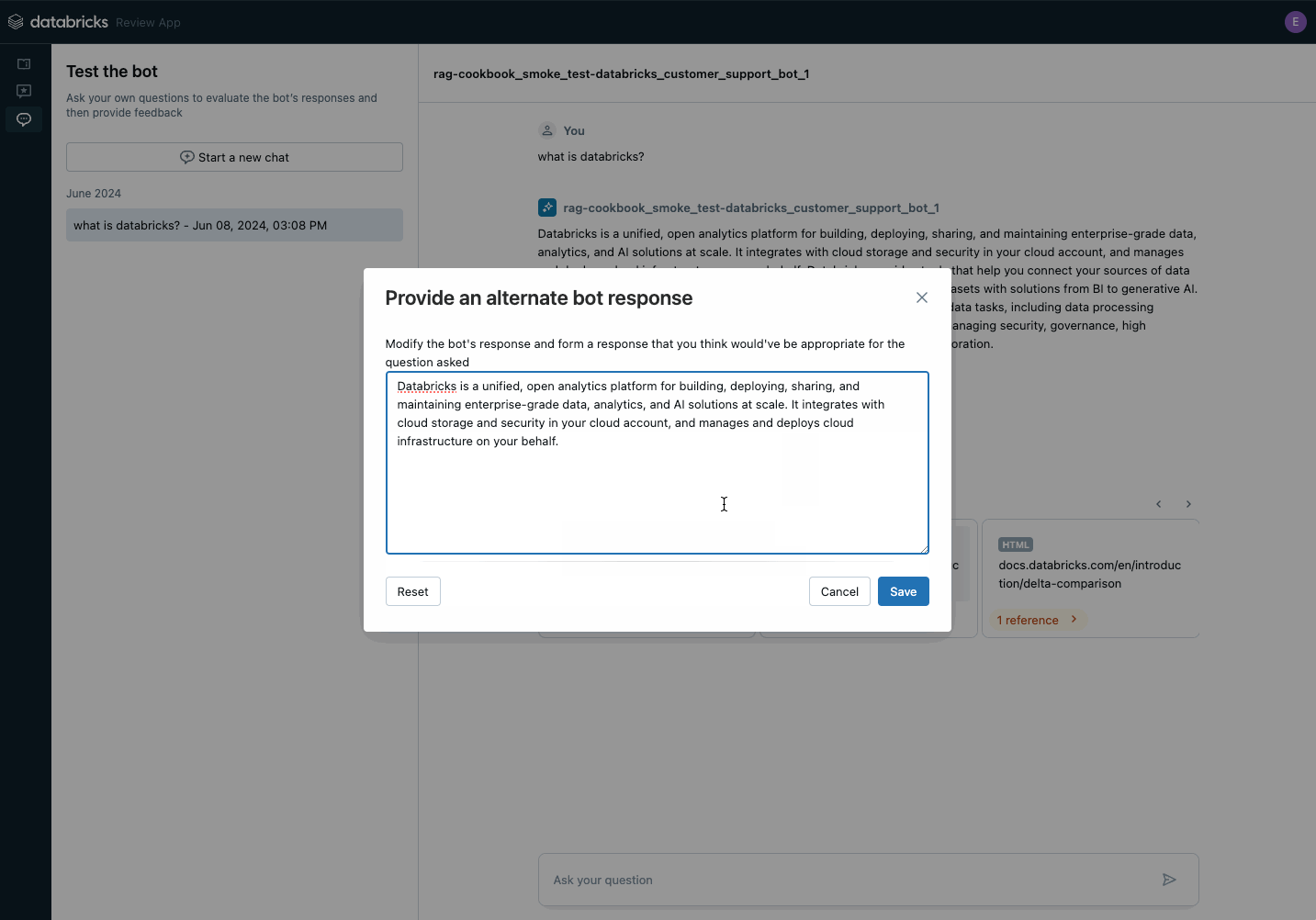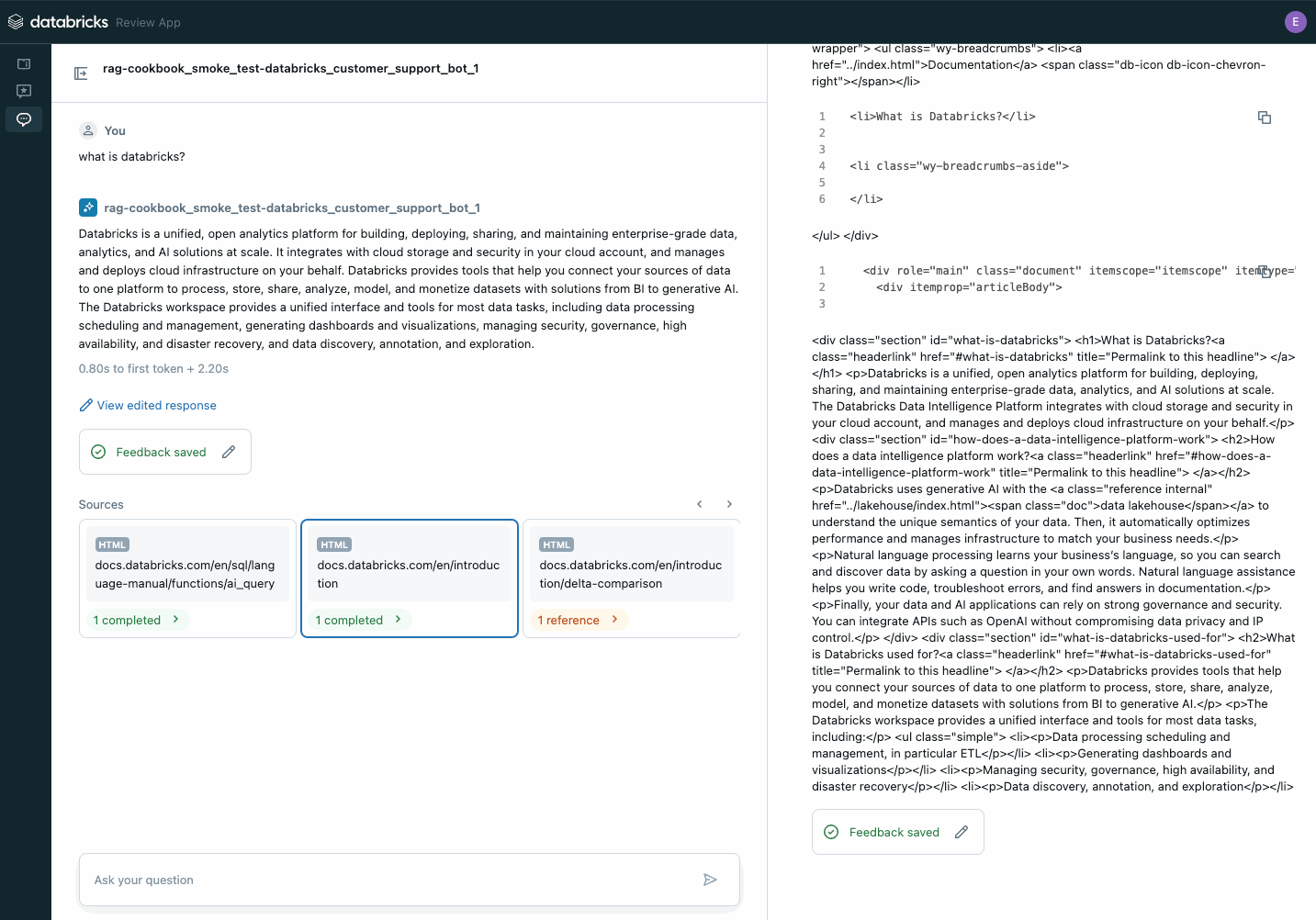
Utilizza l'applicazione di revisione per raccogliere il feedback degli stakeholder sul tuo POC
Corning è un'azienda di scienza dei materiali - le nostre tecnologie di vetro e ceramica sono utilizzate in molte applicazioni industriali e scientifiche, quindi comprendere e agire sui nostri dati è essenziale. Abbiamo creato un assistente di ricerca AI utilizzando Databricks Agent Bricks Custom Agents per indicizzare centinaia di migliaia di documenti, inclusi dati dell'ufficio brevetti statunitense. Avere il nostro assistente basato su LLM che risponde alle domande con alta precisione era estremamente importante per noi - in questo modo, i nostri ricercatori potevano trovare e portare avanti i compiti su cui stavano lavorando. Per implementare questo, abbiamo utilizzato Databricks Agent Bricks Custom Agents per costruire una soluzione Hi Hello Generative AI aumentata con i dati dell'ufficio brevetti statunitense. Sfruttando la Databricks Data Intelligence Platform, abbiamo migliorato significativamente la velocità di recupero, la qualità delle risposte e la precisione. —Denis Kamotsky, Principal Software Engineer, Corning
Una volta che inizi a ricevere feedback per creare il tuo set di dati di valutazione, puoi utilizzare Agent Evaluation e i giudici AI integrati per rivedere ogni risposta rispetto a una serie di criteri di qualità utilizzando metriche predefinite:
- Correttezza della risposta - la risposta dell'app è accurata?
- Groundness - la risposta dell'app è basata sui dati recuperati o l'app sta allucinando?
- Pertinenza del recupero - i dati recuperati sono pertinenti alla domanda dell'utente?
- Pertinenza della risposta - la risposta dell'app è pertinente alla domanda dell'utente?
- Sicurezza - la risposta dell'app contiene contenuti dannosi?
Le metriche aggregate e la valutazione di ogni domanda nel set di valutazione vengono registrate in MLflow. Ogni giudizio basato su LLM è supportato da una spiegazione scritta del perché. I risultati di questa valutazione possono essere utilizzati per identificare le cause principali dei problemi di qualità. Fare riferimento alle sezioni del Cookbook Valuta la qualità del POC e Identifica la causa principale dei problemi di qualità per una guida dettagliata.
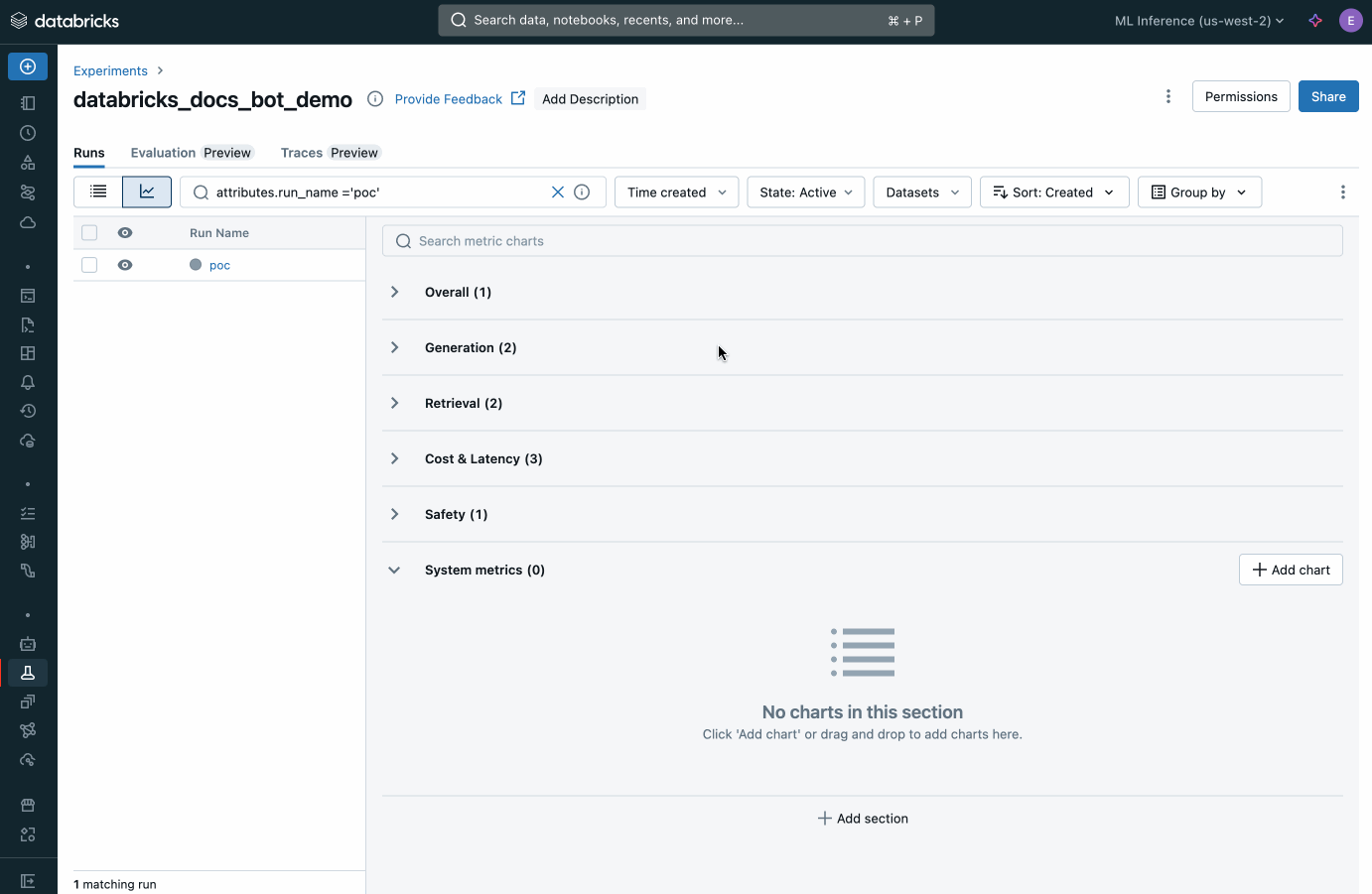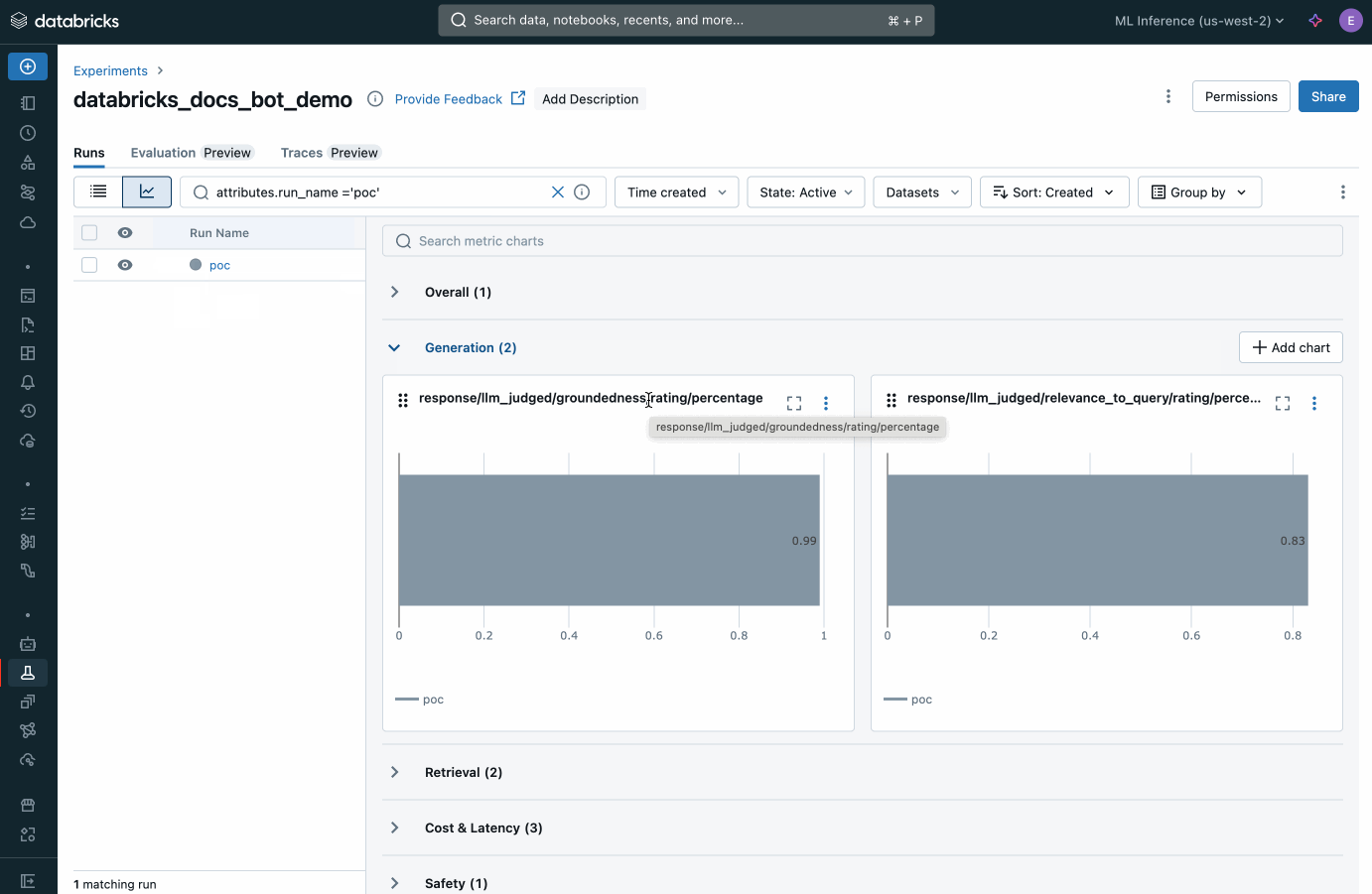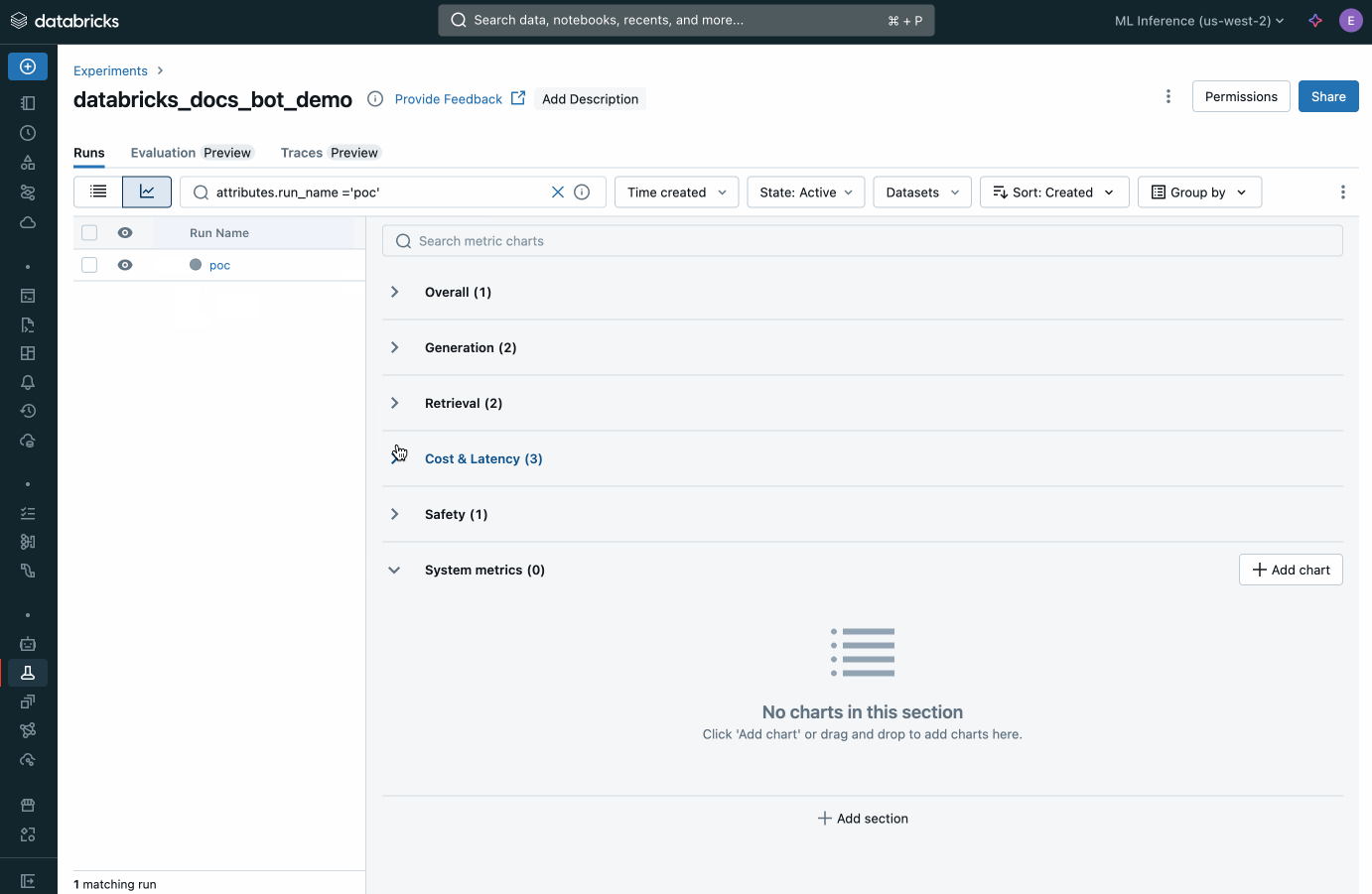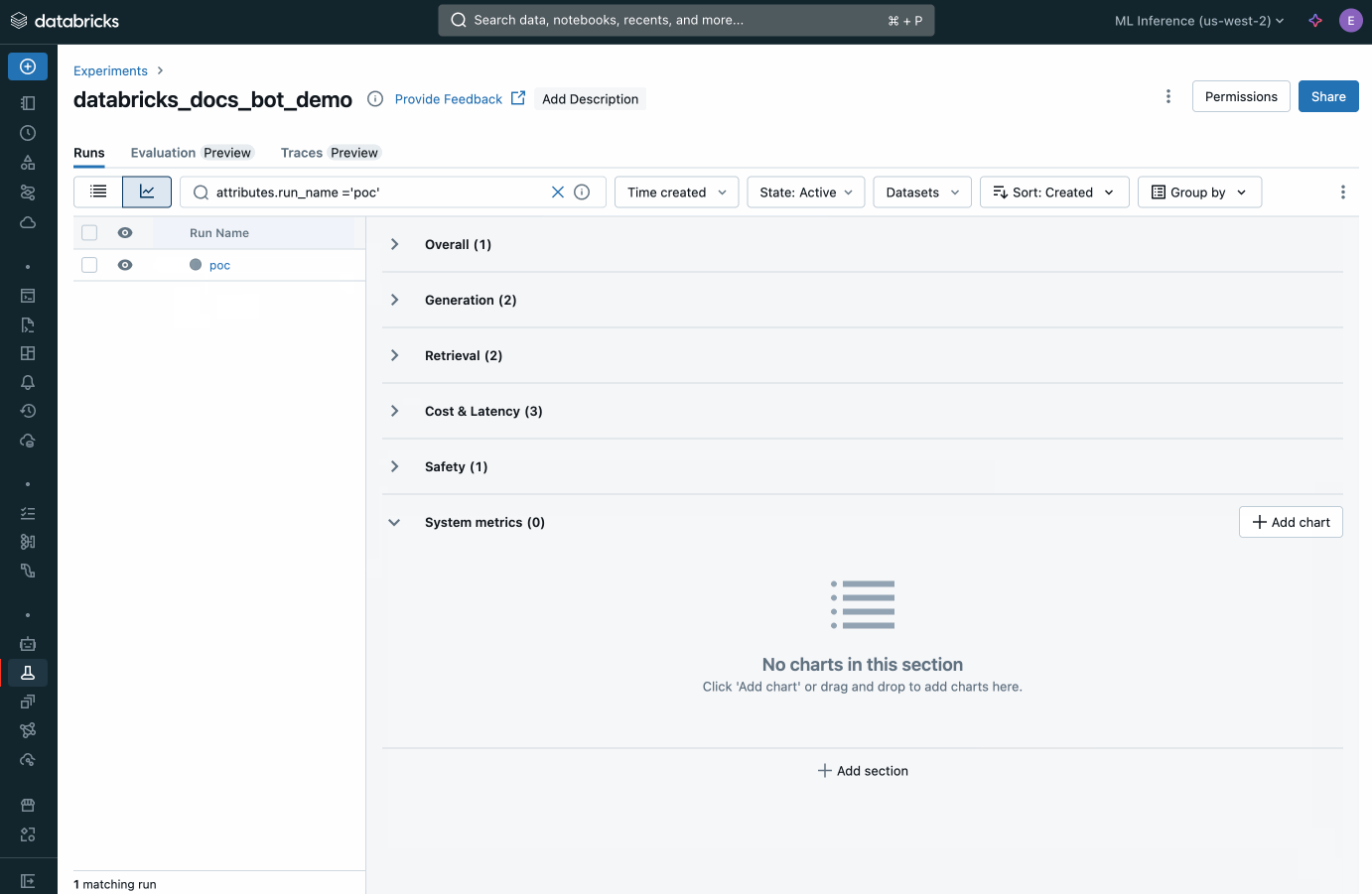
Visualizza le metriche aggregate da Agent Evaluation all'interno di MLflow
In qualità di produttore leader a livello mondiale, Lippert sfrutta dati e AI per costruire prodotti altamente ingegnerizzati, soluzioni personalizzate e le migliori esperienze possibili. Agent Bricks Custom Agents è stato un punto di svolta per noi perché ci ha permesso di valutare i risultati delle nostre applicazioni GenAI e dimostrare l'accuratezza dei nostri output mantenendo il controllo completo sulle nostre fonti di dati. Grazie alla Databricks Data Intelligence Platform, sono sicuro di poter distribuire in produzione. —Kenan Colson, VP Data & AI, Lippert
Puoi anche ispezionare ogni singolo record nel tuo set di dati di valutazione per comprendere meglio cosa sta succedendo o utilizzare MLflow trace per identificare potenziali problemi di qualità.
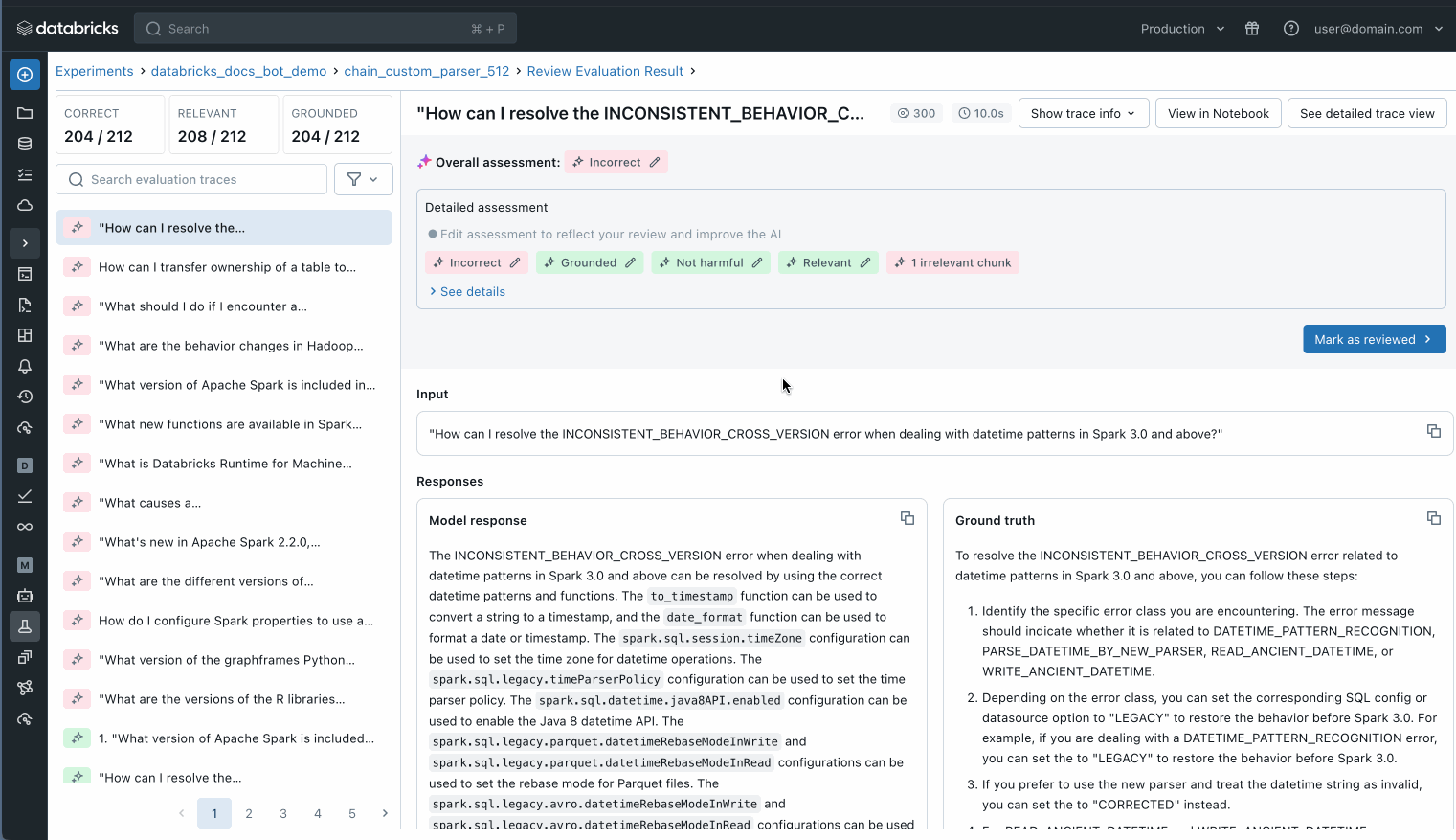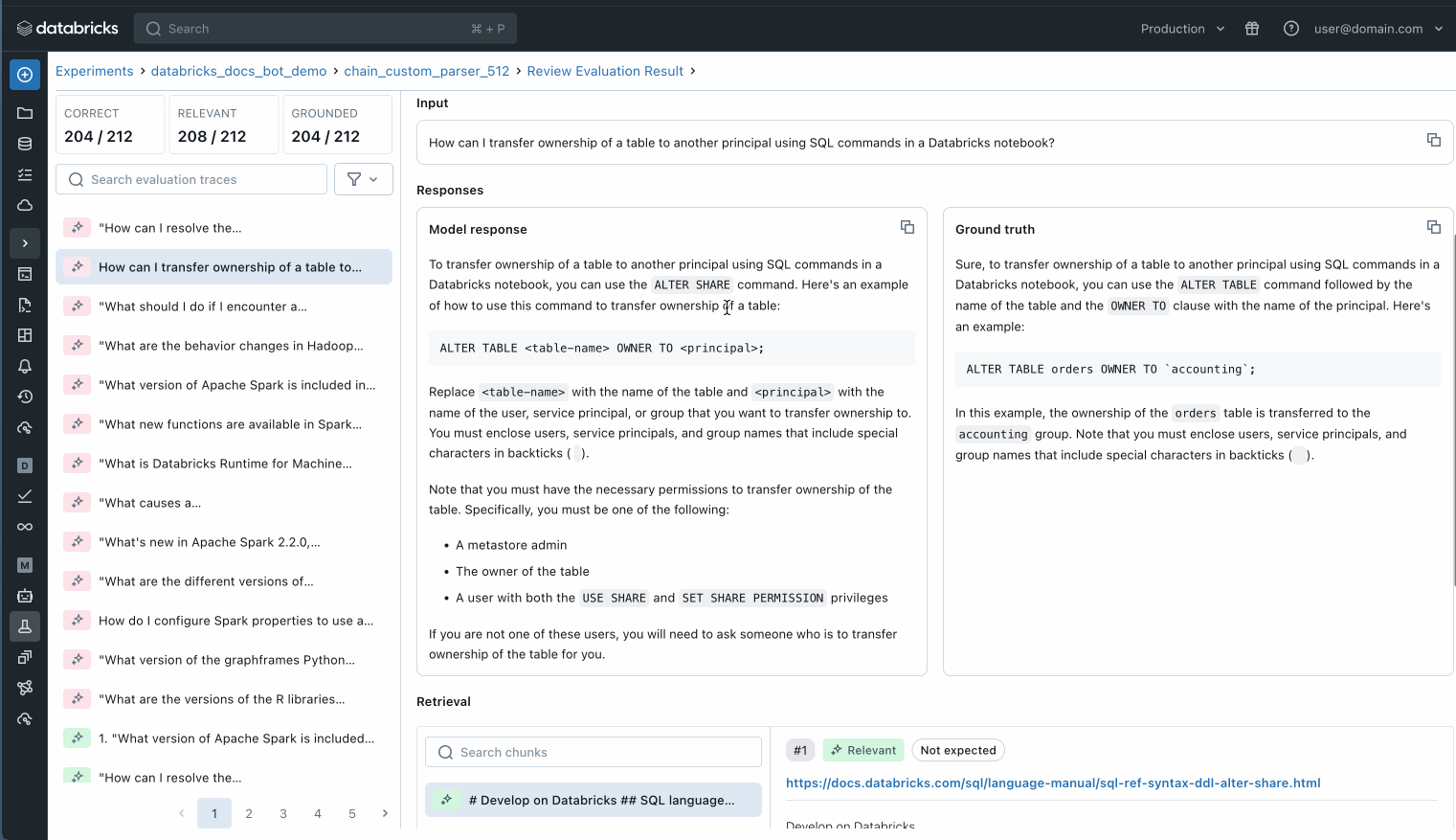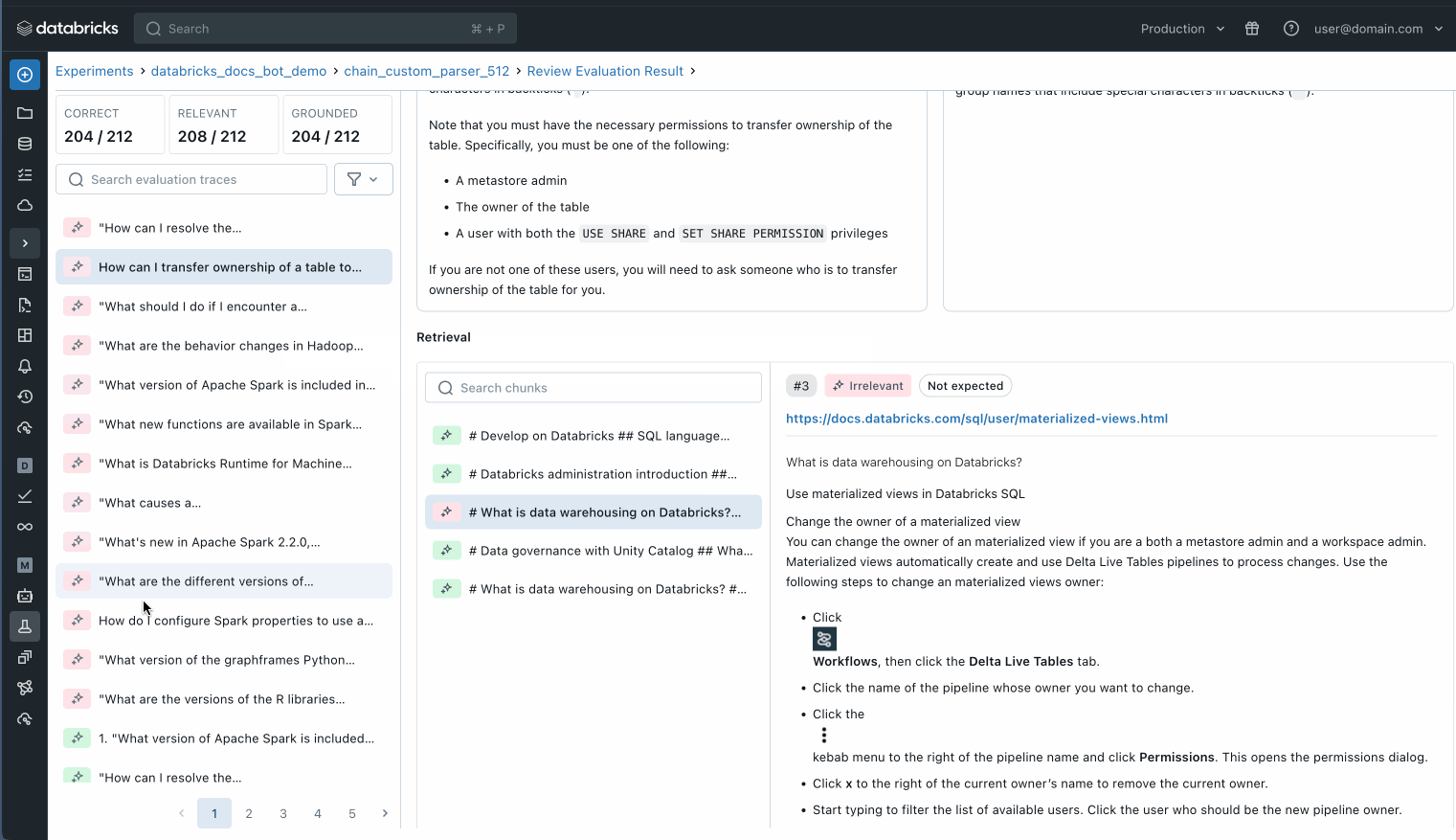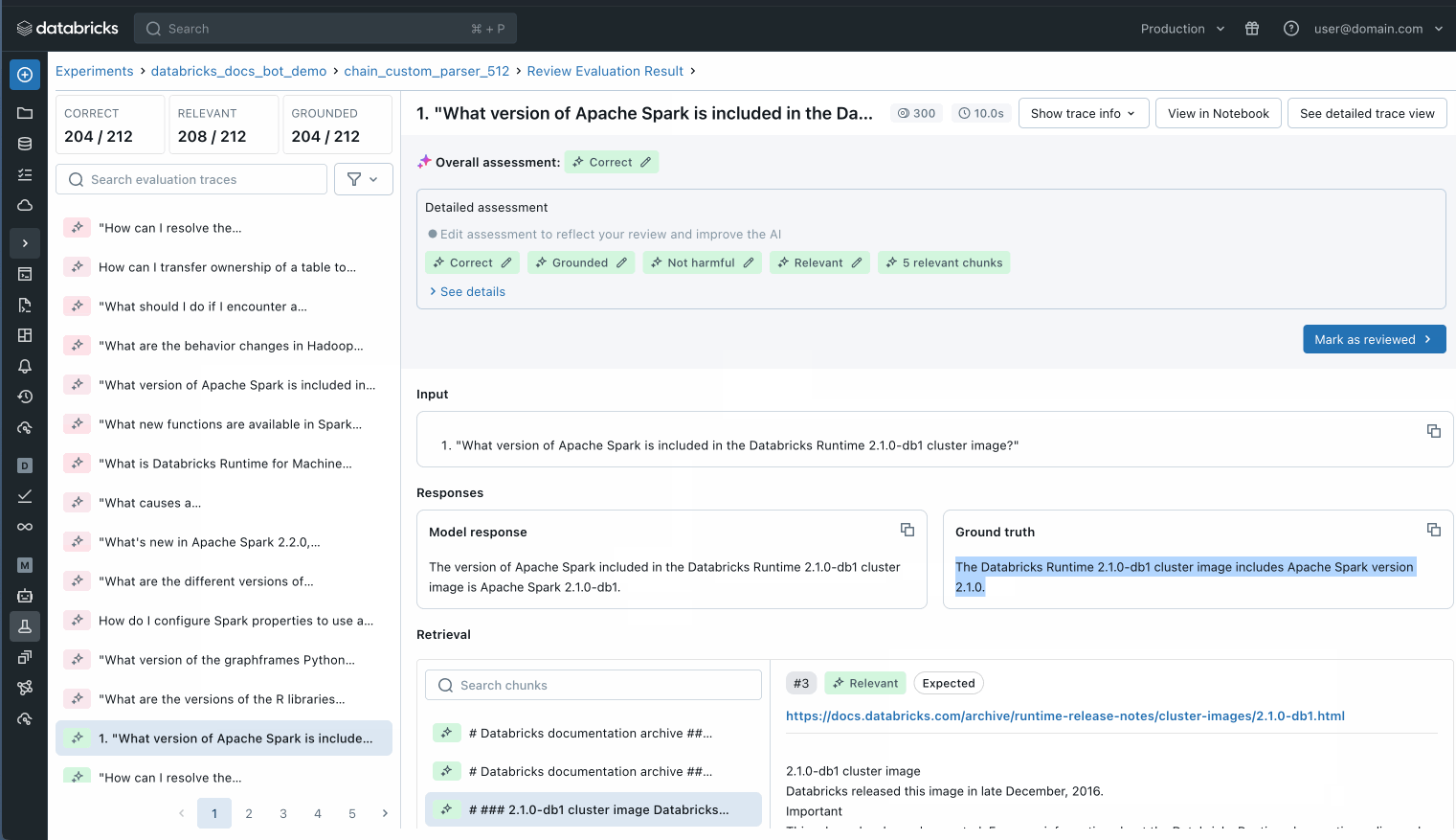
Ispeziona ogni singolo record nel tuo set di valutazione per capire cosa sta succedendo
Una volta che hai iterato sulla qualità e sei soddisfatto, puoi distribuire l'applicazione nel tuo spazio di lavoro di produzione con uno sforzo minimo poiché l'applicazione è già registrata in Unity Catalog.
Agent Bricks Custom Agents ci ha permesso di sperimentare rapidamente con LLM aumentati, con la sicurezza di sapere che qualsiasi dato privato rimane sotto il nostro controllo. L'integrazione fluida con MLflow e Model Serving garantisce che il nostro team di ML Engineering possa scalare da POC a produzione con complessità minima. —Ben Halsall, Analytics Director, Burberry
Queste capacità sono strettamente integrate con Unity Catalog per fornire governance, MLflow per fornire lineage e gestione dei metadati, e LLM Guardrails per fornire sicurezza.
Ford Direct è all'avanguardia nella trasformazione digitale dell'industria automobilistica. Siamo l'hub dati per le concessionarie Ford e Lincoln e avevamo bisogno di creare un chatbot unificato per aiutare i nostri concessionari a valutare le loro prestazioni, l'inventario, le tendenze e le metriche di coinvolgimento dei clienti. Databricks Agent Bricks Custom Agents ci ha permesso di integrare i nostri dati proprietari e la documentazione nella nostra soluzione di Generative AI che utilizza RAG. L'integrazione di Databricks con Databricks Delta Tables e Unity Catalog ha reso semplice aggiornare i nostri indici vettoriali in tempo reale man mano che i nostri dati sorgente vengono aggiornati, senza dover toccare il nostro modello distribuito. —Tom Thomas, VP of Analytics, FordDirect
Prezzi
- Agent Evaluation – prezzo per richiesta del giudice
- Databricks Model Serving – serve agenti; prezzo basato sulle tariffe di Databricks Model Serving
Per ulteriori dettagli fare riferimento al nostro sito dei prezzi.
Passi successivi
Agent Framework e Agent Evaluation sono i modi migliori per costruire applicazioni Agentic e Retrieval Augmented Generation di qualità di produzione. Siamo entusiasti di avere più clienti che lo provano e ci danno il loro feedback. Per iniziare, consulta le seguenti risorse:
- Pagina della documentazione di Agent Framework (AWS | Azure)
- Notebook demo di Agent Framework e Agent Evaluation demo notebook
- Generative AI Cookbook
- Repliche delle sessioni breakout dal Data and AI Summit
- Annunci GenAI dal Data and AI Summit
Per aiutarti a integrare queste capacità nella tua applicazione, il Generative AI Cookbook fornisce codice di esempio che dimostra come seguire un flusso di lavoro di sviluppo guidato dalla valutazione utilizzando Agent Framework e Agent Evaluation per portare la tua app da POC a produzione. Inoltre, il Cookbook delinea le opzioni e gli approcci di configurazione più pertinenti che possono aumentare la qualità dell'applicazione.
Prova oggi stesso Agent Framework & Agent Evaluation eseguendo il nostro demo notebook o seguendo il Cookbook per creare un'app con i tuoi dati.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.