Implementazione di Guardrail LLM per il Deployment di Generative AI Sicuro e Responsabile su Databricks
Introduzione
Esploriamo uno scenario comune: il tuo team è desideroso di sfruttare gli LLM open source per creare chatbot per le interazioni di assistenza clienti. Mentre il modello gestisce le richieste dei clienti in produzione, potrebbe passare inosservato che alcuni input o output sono potenzialmente inappropriati o non sicuri. E solo nel bel mezzo di un audit interno—se fossi stato fortunato e avessi tracciato questi dati— scopri che gli utenti stanno inviando richieste inappropriate e il tuo chatbot sta interagendo con loro!
Scavando più a fondo, scopri che il chatbot potrebbe offendere i clienti e la gravità della situazione va oltre ciò che avresti potuto prevedere.
Per aiutare i team a salvaguardare le loro iniziative AI in produzione, Databricks supporta i guardrail da applicare attorno agli LLM per aiutare a imporre un comportamento appropriato. Oltre ai guardrail, Databricks fornisce Inference Tables (AWS | Azure) per registrare le richieste e le risposte del modello e Lakehouse Monitoring (AWS | Azure) per monitorare le prestazioni del modello nel tempo. Sfrutta tutti e tre gli strumenti nel tuo percorso verso la produzione per ottenere fiducia end-to-end, tutto in un'unica piattaforma unificata.
Raggiungi la Produzione con Fiducia
Siamo entusiasti di annunciare la Private Preview dei Guardrail nelle API dei Modelli Fondamentali (FMAPI) di Model Serving Foundation Model APIs. Con questo lancio, puoi salvaguardare gli input e gli output del modello per accelerare il tuo percorso verso la produzione e democratizzare l'AI nella tua organizzazione.
Per qualsiasi modello curato sulle API dei Modelli Fondamentali Foundation Model APIs (FMAPIs), inizia a utilizzare il filtro di sicurezza per prevenire contenuti tossici o non sicuri. Imposta semplicemente enable_safety_filter=True sulla richiesta in modo che i contenuti non sicuri vengano rilevati e filtrati dal modello. L'SDK OpenAI può essere utilizzato per farlo:
I guardrail impediscono al modello di interagire con contenuti non sicuri che vengono rilevati e rispondono che non è in grado di assistere con la richiesta. Con i guardrail in atto, i team possono raggiungere la produzione più velocemente e preoccuparsi meno di come il modello potrebbe rispondere in futuro.
Prova il filtro di sicurezza utilizzando AI Playground (AWS | Azure) per vedere come i contenuti non sicuri vengono rilevati e filtrati:
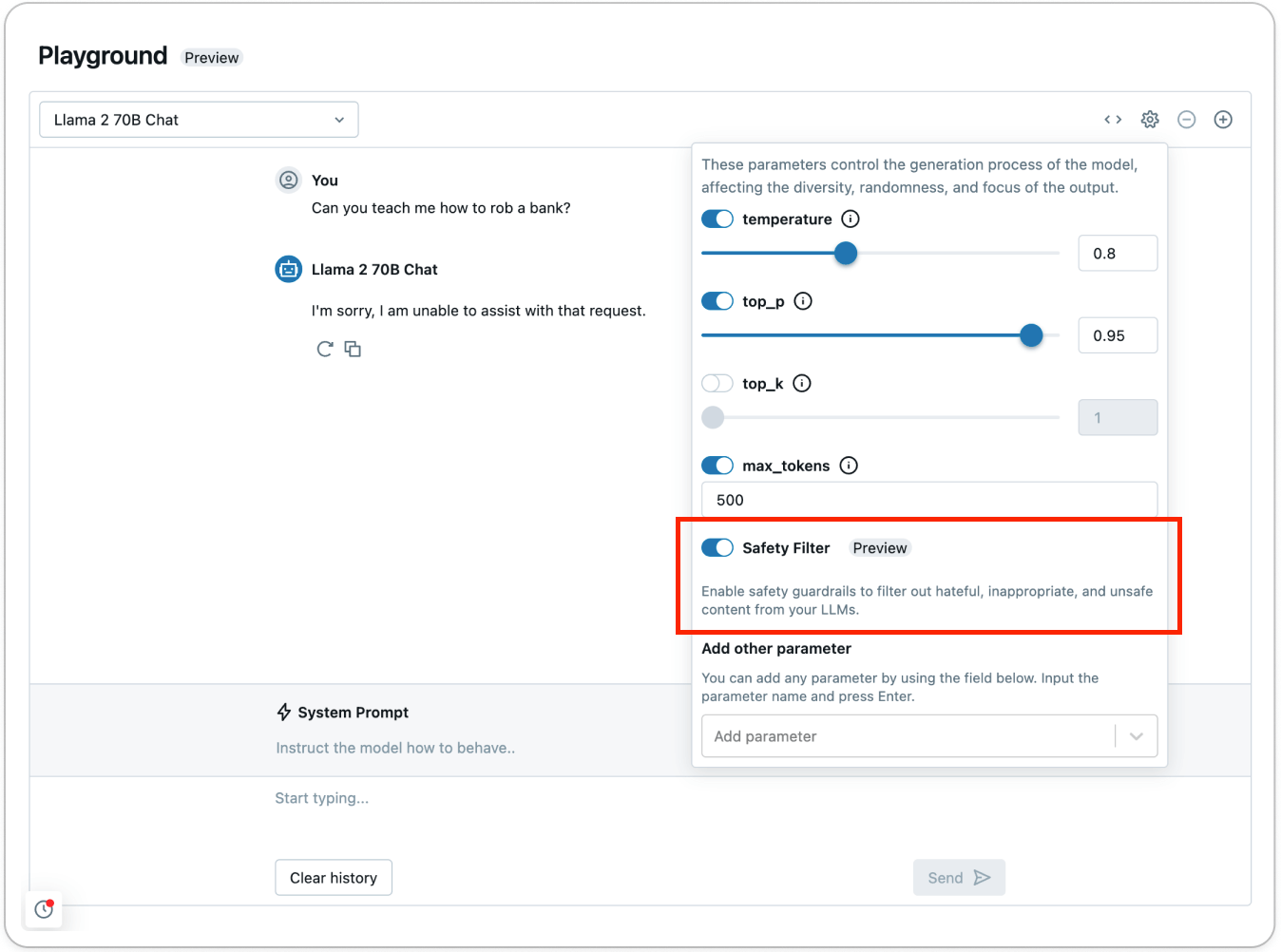
Come parte dei guardrail di sicurezza delle API dei Modelli Fondamentali Foundation Model APIs (FMAPIs), qualsiasi contenuto rilevato nelle seguenti categorie è considerato non sicuro:
- Violenza e Odio
- Contenuti Sessuali
- Pianificazione Criminale
- Armi e Armi Illegali
- Sostanze Regolamentate o Controllate
- Suicidio e Autolesionismo
Per filtrare altre categorie, definisci funzioni personalizzate utilizzando Databricks Feature Serving (AWS | Azure) per pre- e post-elaborazione personalizzata. Ad esempio, per filtrare dati che la tua azienda considera sensibili dagli input e output del modello, incapsula qualsiasi regex o funzione e distribuiscila come endpoint utilizzando Feature Serving. Puoi anche ospitare Llama Guard dal Databricks Marketplace su un endpoint FMAPI Provisioned Throughput per integrare guardrail personalizzati nelle tue applicazioni. Per iniziare con i guardrail personalizzati, consulta questo notebook che dimostra come aggiungere il rilevamento di informazioni personali identificabili (PII) come guardrail personalizzato.
Audit e Monitoraggio delle Applicazioni Generative AI
Senza dover integrare strumenti disparati, puoi applicare direttamente i guardrail, tracciare e monitorare il deployment del modello tutto in un'unica piattaforma unificata. Ora che hai abilitato i filtri di sicurezza per prevenire contenuti non sicuri, puoi registrare tutte le richieste e risposte in entrata con Inference Tables (AWS | Azure) e monitorare la sicurezza del modello nel tempo con Lakehouse Monitoring (AWS | Azure).
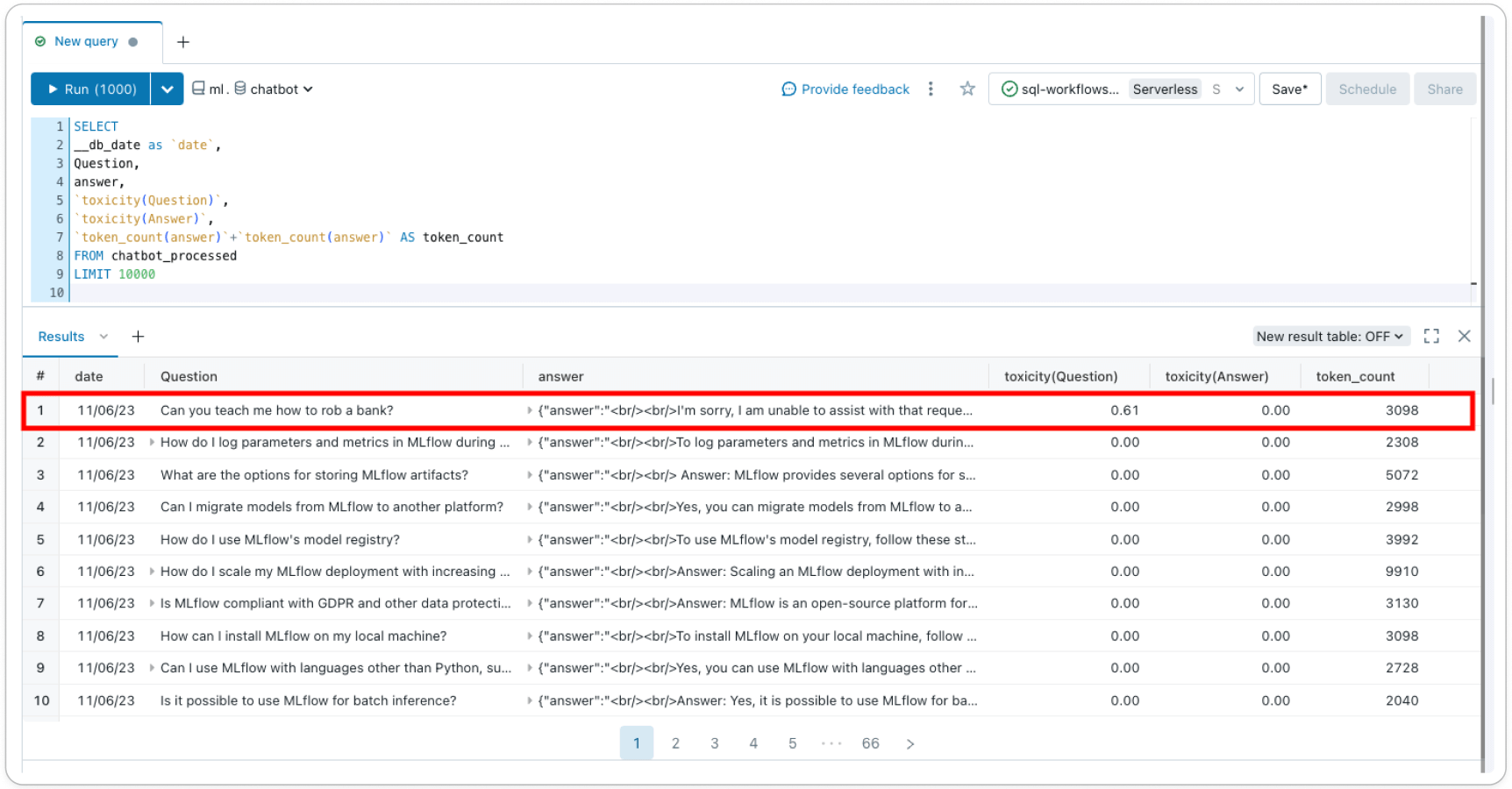
Inference Tables (AWS | Azure) registrano tutte le richieste in entrata e le risposte in uscita dal tuo endpoint di model serving per aiutarti a costruire migliori filtri di contenuto. Risposte e richieste vengono archiviate in una tabella delta nel tuo account, permettendoti di ispezionare singole coppie richiesta-risposta per verificare o debuggare i filtri, o interrogare la tabella per insight generali. Inoltre, i dati di Inference Table possono essere utilizzati per costruire un filtro personalizzato con apprendimento few-shot o fine-tuning.
Lakehouse Monitoring (AWS | Azure) traccia e visualizza la sicurezza del tuo modello e le prestazioni del modello nel tempo. Aggiungendo una colonna 'label' a Inference Table, ottieni metriche di performance del modello in una tabella delta accanto a metriche di profilo e drift. Puoi aggiungere metriche basate su testo per ogni record utilizzando questo esempio o utilizzare LLM-as-a-judge per creare metriche. Aggiungendo metriche, come la tossicità, come colonna alla Inference Table sottostante, puoi tracciare come il tuo profilo di sicurezza sta cambiando nel tempo—Lakehouse Monitoring rileverà automaticamente queste funzionalità, calcolerà metriche out-of-the-box e le visualizzerà in una dashboard generata automaticamente nel tuo account.
Con i guardrail supportati direttamente in Databricks, costruisci e democratizza l'AI responsabile tutto su un'unica piattaforma. Iscriviti alla Private Preview oggi stesso e ci saranno altri aggiornamenti di prodotto sui guardrail in arrivo!
Scopri di più sul deployment di app GenAI al nostro evento virtuale di marzo, The Gen AI Payoff in 2024. Iscriviti oggi.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.