Lakehouse Monitoring: una soluzione unificata per la qualità dei dati e dell'AI
Introduzione
Databricks Data Quality Monitoring ti permette di monitorare tutte le pipeline di dati (dai dati alle funzioni, fino ai modelli di ML) senza strumenti e complessità aggiuntivi. Poiché è integrato in Unity Catalog, puoi tracciare la qualità parallelamente alla governance e ottenere informazioni approfondite sulle prestazioni dei tuoi asset di dati e di IA. Lakehouse Monitoring è completamente serverless, quindi non dovrai mai preoccuparti dell'infrastruttura o dell'ottimizzazione della configurazione di calcolo.
Il nostro approccio unico e unificato al monitoraggio semplifica il tracciamento della qualità, la diagnosi degli errori e la ricerca di soluzioni direttamente nella Databricks Data Intelligence Platform. Continua a leggere per scoprire come tu e il tuo team potete ottenere il massimo da Lakehouse Monitoring.
Perché Lakehouse Monitoring?
Ecco uno scenario: la tua pipeline di dati sembra funzionare senza problemi, per poi scoprire che la qualità dei dati si è silenziosamente degradata nel tempo. È un problema comune tra i data engineer: tutto sembra a posto finché qualcuno non si lamenta che i dati sono inutilizzabili.
Per chi addestra modelli di ML, monitorare le prestazioni dei modelli in produzione e confrontare le diverse versioni è una sfida continua. Di conseguenza, i team devono gestire modelli che diventano obsoleti in produzione e hanno il compito di eseguirne il rollback.
L'illusione di pipeline funzionali che mascherano una qualità dei dati in deterioramento rende difficile per i team di dati e AI rispettare gli SLA di consegna e qualità. Lakehouse Monitoring può aiutarti a individuare in modo proattivo i problemi di qualità prima che i processi a valle ne risentano. Puoi anticipare i potenziali problemi, garantendo che le pipeline funzionino senza intoppi e che i modelli di machine learning rimangano efficaci nel tempo. Niente più settimane perse a fare debug e ad annullare le modifiche!
Come funziona

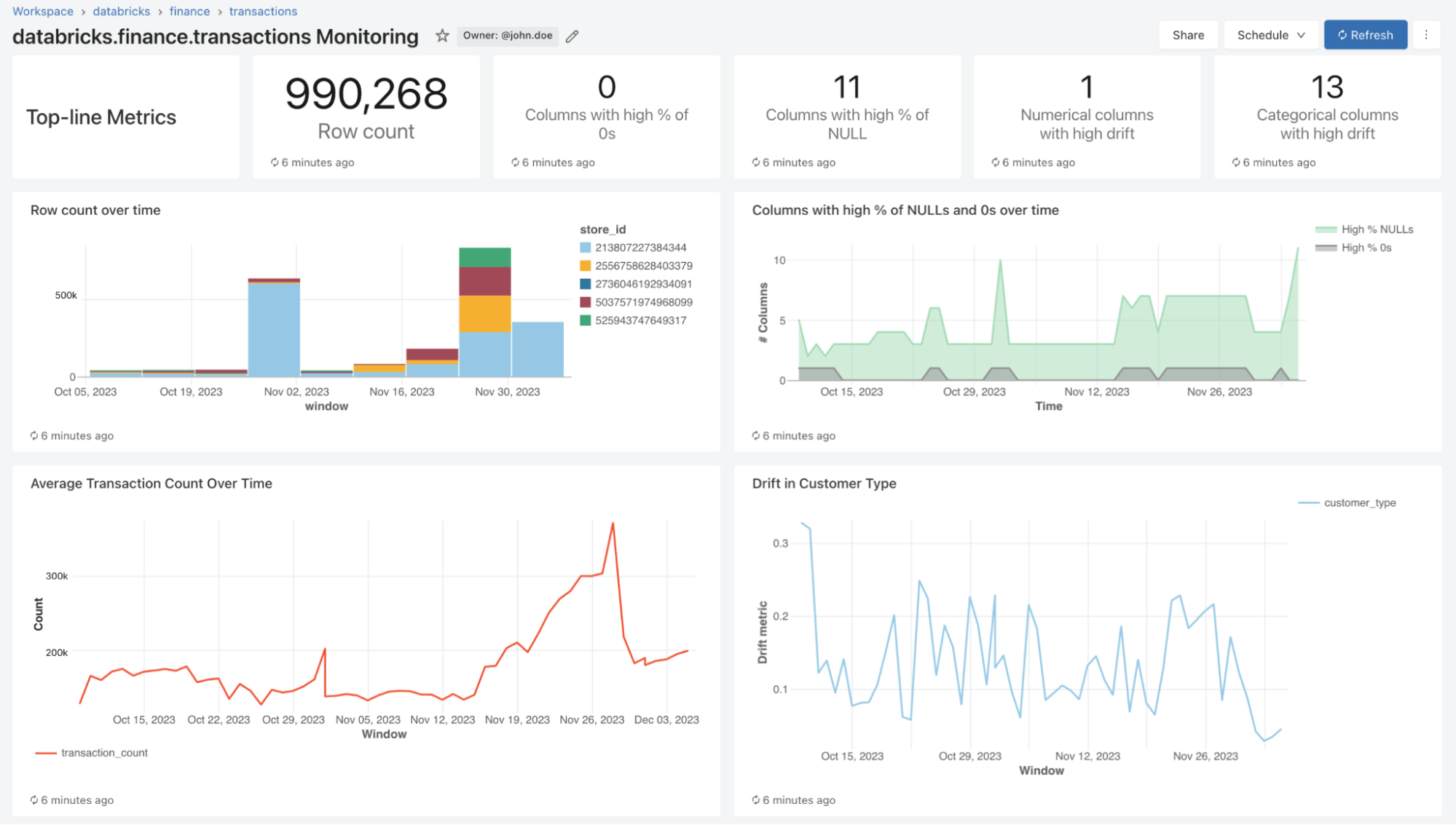
Con Lakehouse Monitoring puoi monitorare le proprietà statistiche e la qualità di tutte le tue tabelle con un solo clic. Generiamo automaticamente una dashboard che visualizza la qualità dei dati per qualsiasi tabella Delta in Unity Catalog. Il nostro prodotto computa di serie un ricco set di metriche. Ad esempio, se stai monitorando una tabella di inferenza, forniamo metriche sulle prestazioni del modello, come R-quadrato, accuratezza, ecc. In alternativa, per chi monitora le tabelle di data ingegneria, forniamo metriche di distribuzione tra cui media, min/max, ecc. Oltre alle metriche integrate, puoi anche configurare metriche personalizzate (specifiche per il business) che vuoi che calcoliamo. Lakehouse Monitoring aggiorna le metriche e mantiene aggiornata la dashboard in base alla pianificazione specificata. Tutte le metriche vengono memorizzate in tabelle Delta per consentire analisi ad hoc, visualizzazioni personalizzate e avvisi.
Configura il monitoraggio
È possibile impostare il monitoraggio su qualsiasi tabella di cui si è proprietari utilizzando l'interfaccia utente di Databricks (AWS | Azure) o l'API (AWS | Azure). Selezionare il tipo di profilo di monitoraggio desiderato per le pipeline di dati o i modelli:
- Profilo snapshot: se si desidera monitorare l'intera tabella nel tempo o confrontare i dati attuali con le versioni precedenti o con una baseline nota, un profilo snapshot è la soluzione migliore. Calcoleremo quindi le metriche su tutti i dati della tabella e le aggiorneremo ogni volta che il monitoraggio viene aggiornato.
- Profilo serie temporale: Se la tabella contiene timestamp di eventi e si desidera confrontare le distribuzioni dei dati su finestre temporali (orarie, giornaliere, settimanali, ...), un profilo Serie temporale è la soluzione migliore. Si consiglia di attivare Change Data Feed (AWS | Azure) per ottenere l'elaborazione incrementale a ogni aggiornamento del monitoraggio. Nota: per configurare questo profilo è necessaria una colonna di timestamp.
- Profilo del log di inferenza: se si desidera confrontare le prestazioni del modello nel tempo o monitorare come gli input e le previsioni del modello cambiano nel tempo, un profilo di inferenza è la soluzione migliore. Sarà necessaria una tabella di inferenza (AWS | Azure) che contenga input e output di un modello di classificazione o regressione ML. È anche possibile includere facoltativamente etichette di ground truth per calcolare la deriva (drift) e altri metadati, come le informazioni demografiche, per ottenere metriche di equità e bias.
Puoi scegliere la frequenza con cui desideri che il nostro servizio di monitoraggio venga eseguito. Molti clienti scelgono una pianificazione giornaliera o oraria per garantire l'attualità e la pertinenza dei loro dati. Se desideri che il monitoraggio venga eseguito automaticamente al termine dell'esecuzione della pipeline di dati, puoi anche chiamare l'API per aggiornare il monitoraggio direttamente nel tuo flusso di lavoro.
Per personalizzare ulteriormente il monitoraggio, è possibile impostare espressioni di slicing per monitorare i sottoinsiemi di funzionalità della tabella oltre alla tabella nel suo complesso. È possibile eseguire lo slicing di qualsiasi colonna specifica, ad esempio etnia, genere, per generare metriche di equità e bias. È anche possibile definire metriche personalizzate basate sulle colonne della tabella principale o su metriche predefinite. Per maggiori dettagli, vedere come usare le metriche personalizzate (AWS | Azure).
Visualizza la qualità
Nell'ambito di un refresh, eseguiremo la scansione delle tue tabelle e dei tuoi modelli per generare metriche che monitorano la qualità nel tempo. Calcoliamo due tipi di metriche che archiviamo per te in tabelle Delta:
- Metriche del profilo: forniscono statistiche di riepilogo dei dati. Ad esempio, è possibile tenere traccia del numero di valori nulli e zero nella tabella o delle metriche di accuratezza del modello. Per maggiori informazioni, vedere lo schema della tabella delle metriche del profilo (AWS | Azure).
- Metriche di drift: Forniscono metriche di drift statistiche che consentono di confrontare i dati con le tabelle di riferimento. Consulta lo schema della tabella delle metriche di drift (AWS | Azure) per maggiori informazioni.
Per visualizzare tutte queste metriche, Lakehouse Monitoring fornisce una dashboard pronta all'uso e completamente personalizzabile. Puoi anche creare avvisi Databricks SQL (AWS | Azure) per ricevere notifiche su violazioni delle soglie, modifiche alla distribuzione dei dati e drift dalla tabella di riferimento.
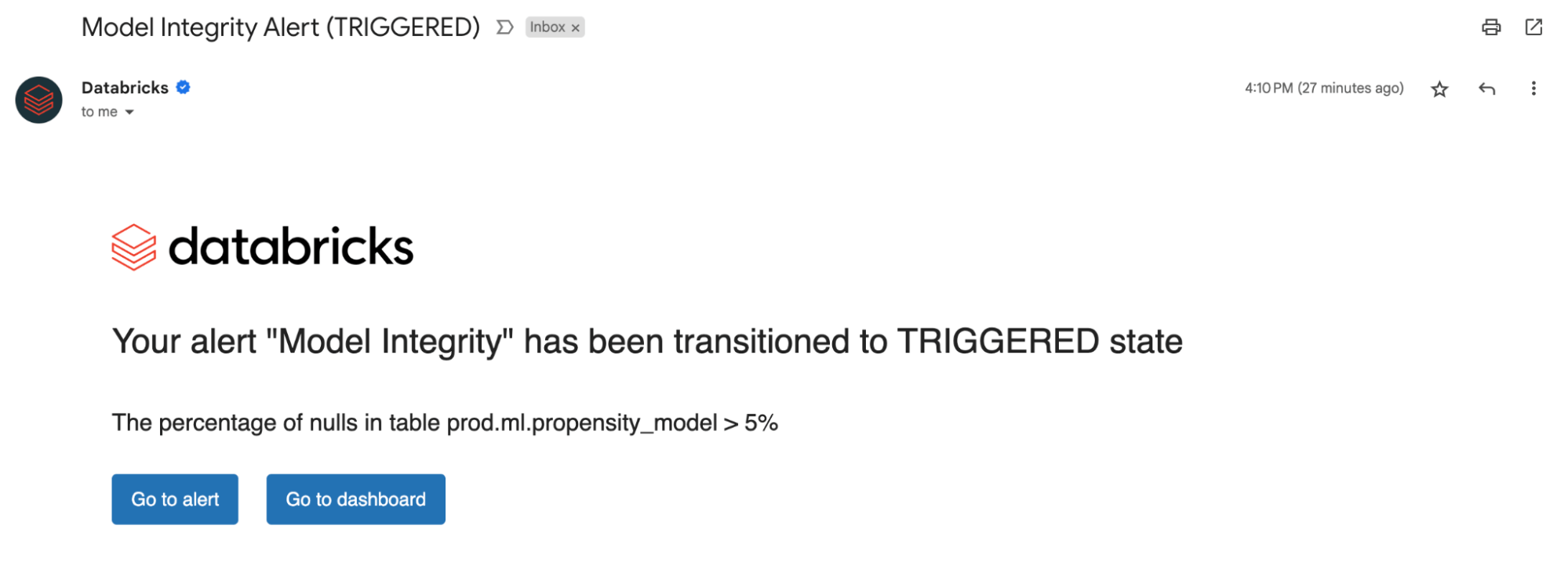
Impostazione degli avvisi
Sia che si tratti del monitoraggio di tabelle di dati o modelli, l'impostazione di avvisi sulle nostre metriche calcolate ti notifica potenziali errori e aiuta a prevenire rischi a valle.
È possibile ricevere avvisi se la percentuale di valori nulli e zero supera una determinata soglia o subisce modifiche nel tempo. Se si monitorano modelli, è possibile ricevere avvisi qualora le metriche delle prestazioni del modello, come la tossicità o il drift, scendano al di sotto di determinate soglie di qualità.
Ora, con le informazioni dettagliate derivate dai nostri avvisi, puoi identificare se un modello necessita di un riaddestramento o se ci sono potenziali problemi con i dati di origine. Dopo aver risolto i problemi, puoi chiamare manualmente l'API di refresh per ottenere le metriche più recenti per la tua pipeline aggiornata. Lakehouse Monitoring ti aiuta ad agire in modo proattivo per mantenere lo stato di integrità e l'affidabilità complessivi dei tuoi dati e modelli.
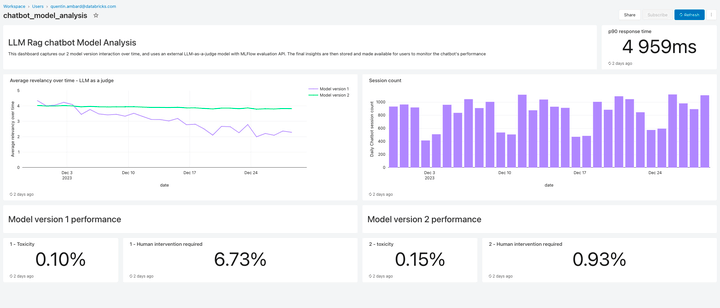
Monitora la qualità degli LLM
Lakehouse Monitoring offre una soluzione di qualità completamente gestita per le applicazioni di Retrieval Augmented Generation (RAG). Analizza gli output delle applicazioni per rilevare contenuti tossici o altrimenti non sicuri. Puoi diagnosticare rapidamente errori relativi ad esempio a pipeline di dati obsolete o comportamenti imprevisti del modello. Lakehouse Monitoring gestisce completamente le pipeline di monitoraggio, consentendo agli sviluppatori di concentrarsi sulle proprie applicazioni.
Quali sono le prossime novità?
Siamo entusiasti per il futuro di Lakehouse Monitoring e non vediamo l'ora di aggiungere il supporto per:
- Classificazione dei dati/Rilevamento PII – Iscriviti alla nostra Private Preview qui!
- Aspettative per applicare automaticamente le regole sulla qualità dei dati e orchestrare le pipeline
- Una vista olistica dei monitor per riepilogare la qualità e l'integrità di tutte le tabelle
Per saperne di più sul monitoraggio di lakehouse e iniziare subito, visitare la documentazione del nostro prodotto (AWS | Azure). Inoltre, è possibile leggere i recenti annunci sulla creazione di applicazioni RAG di alta qualità e partecipare al nostro webinar su GenAI.
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.