Creare applicazioni RAG di alta qualità con Databricks
Una nuova suite di strumenti per portare in produzione le applicazioni di AI generativa
La Retrieval-Augmented-Generation (RAG) si è rapidamente affermata come un modo potente per integrare dati proprietari e in tempo reale nelle applicazioni basate su Large Language Model (LLM). Oggi siamo entusiasti di lanciare una suite di strumenti RAG per aiutare gli utenti di Databricks a creare app LLM di alta qualità e pronte per la produzione utilizzando i loro dati aziendali.
Gli LLM hanno rappresentato una svolta epocale nella capacità di prototipare rapidamente nuove applicazioni. Tuttavia, dopo aver lavorato con migliaia di aziende che creano applicazioni RAG, abbiamo riscontrato che la loro sfida più grande è portare queste applicazioni a una qualità di produzione. Per soddisfare gli standard di qualità richiesti dalle applicazioni rivolte ai clienti, l'output dell'AI deve essere accurato, aggiornato, sicuro e consapevole del contesto aziendale.
Per ottenere un'alta qualità con le applicazioni RAG, gli sviluppatori hanno bisogno di strumenti avanzati per comprendere la qualità dei loro dati e degli output dei modelli, insieme a una piattaforma sottostante che consenta loro di combinare e ottimizzare tutti gli aspetti del processo RAG. Il RAG coinvolge molti componenti, come la preparazione dei dati, i modelli di recupero, i modelli linguistici (SaaS o open source), le pipeline di classificazione e post-elaborazione, l'ingegneria dei prompt e l'addestramento di modelli su dati aziendali personalizzati. Databricks si è sempre concentrata sulla combinazione dei vostri dati con le tecniche di ML più all'avanguardia. Con la release di oggi, estendiamo questa filosofia per consentire ai clienti di sfruttare i loro dati nella creazione di applicazioni di IA di alta qualità.
La release di oggi include l'Anteprima Pubblica di:
- Un servizio di ricerca vettoriale per potenziare la ricerca semantica sulle tabelle esistenti nel tuo lakehouse.
- Serving online di feature e funzioni per rendere disponibile un contesto strutturato per le app RAG.
- Modelli di base completamente gestiti che forniscono LLM di base con pagamento per token.
- Un'interfaccia flessibile di monitoraggio della qualità per osservare le prestazioni in produzione delle app RAG.
- Un set di strumenti di sviluppo per LLM per confrontare e valutare diversi LLM.
Queste funzionalità sono progettate per affrontare le tre sfide principali che abbiamo riscontrato nella creazione di applicazioni RAG di produzione:
Sfida n. 1 - Serving di dati in tempo reale per la tua app RAG
Le applicazioni RAG combinano i dati strutturati e non strutturati più recenti per generare risposte della massima qualità e più personalizzate. Tuttavia, la manutenzione dell'infrastruttura di data serving online può essere molto difficile e le aziende hanno storicamente dovuto mettere insieme più sistemi e mantenere pipeline di dati complesse per caricare i dati da data lake centrali in layer di serving personalizzati. La protezione di set di dati importanti è inoltre molto difficile quando le copie sono distribuite su diversi stack di infrastruttura.
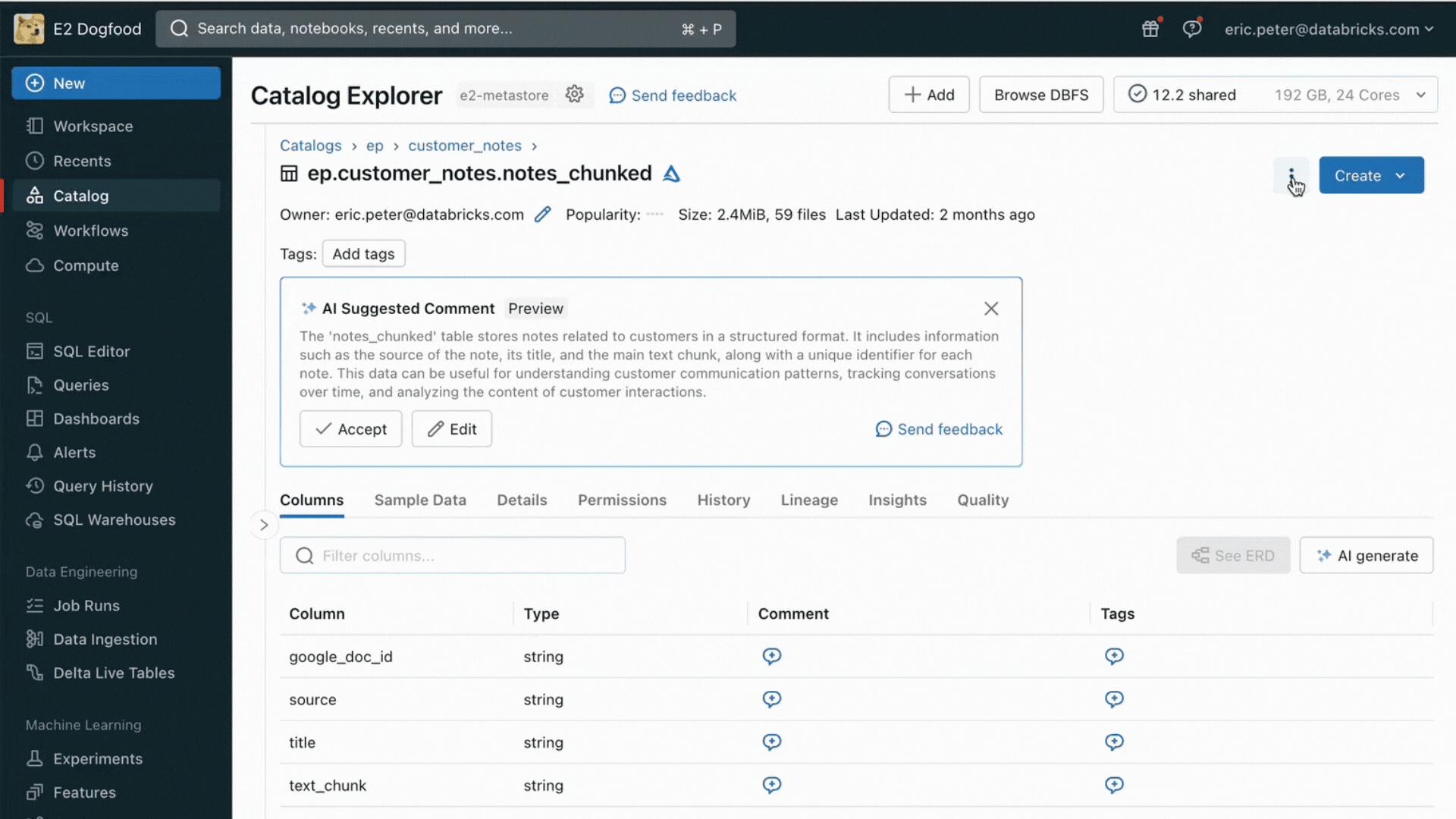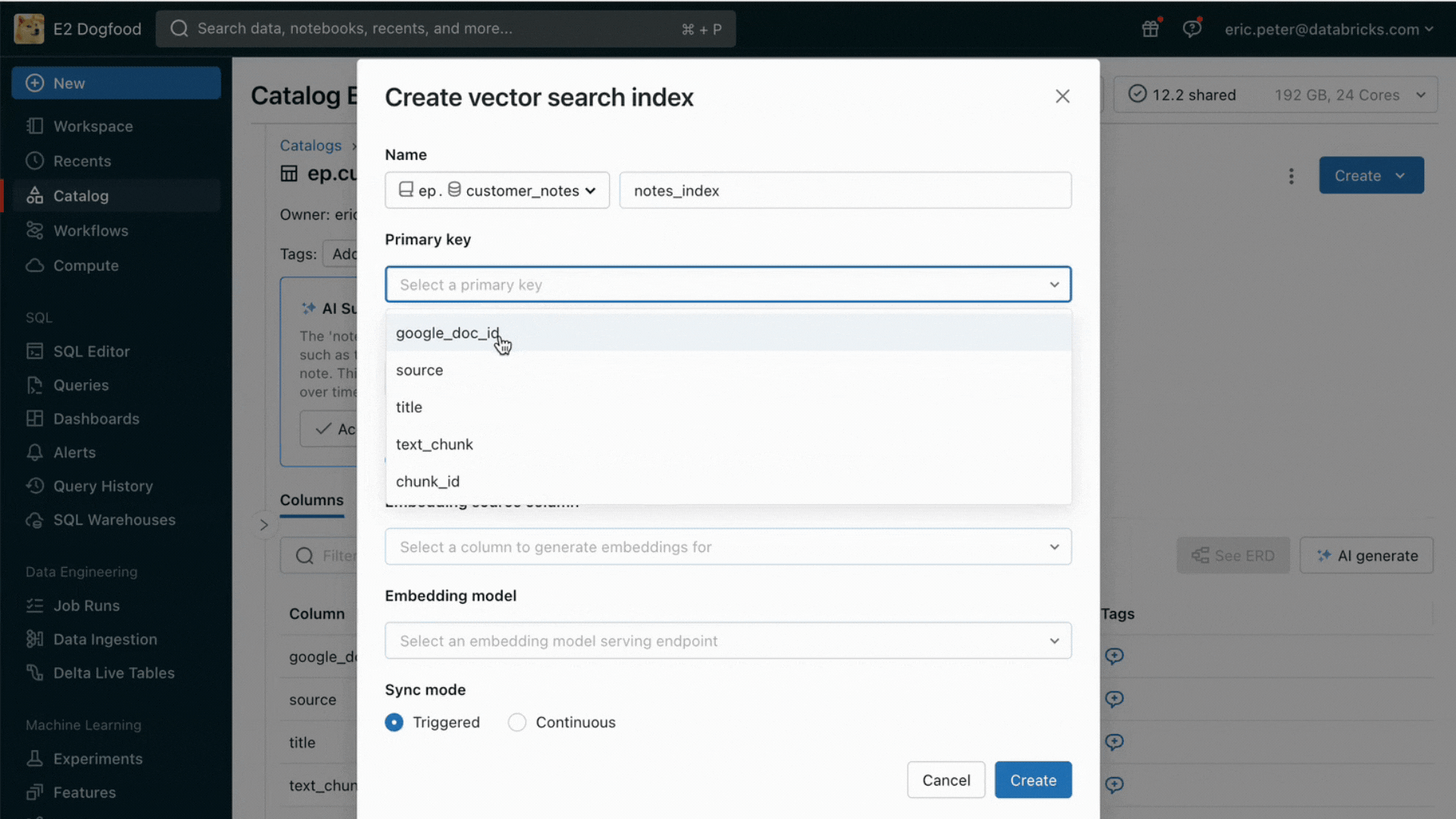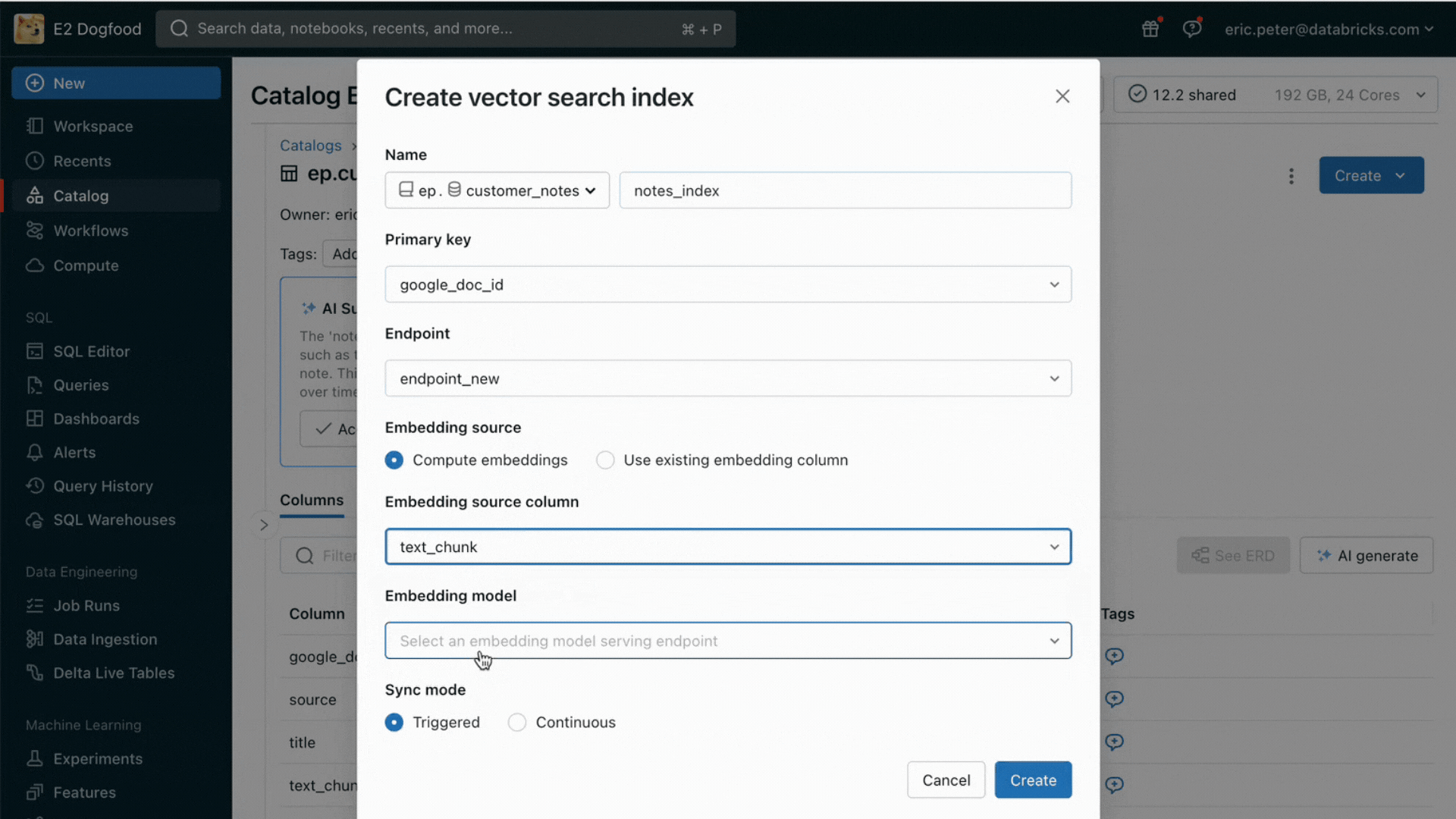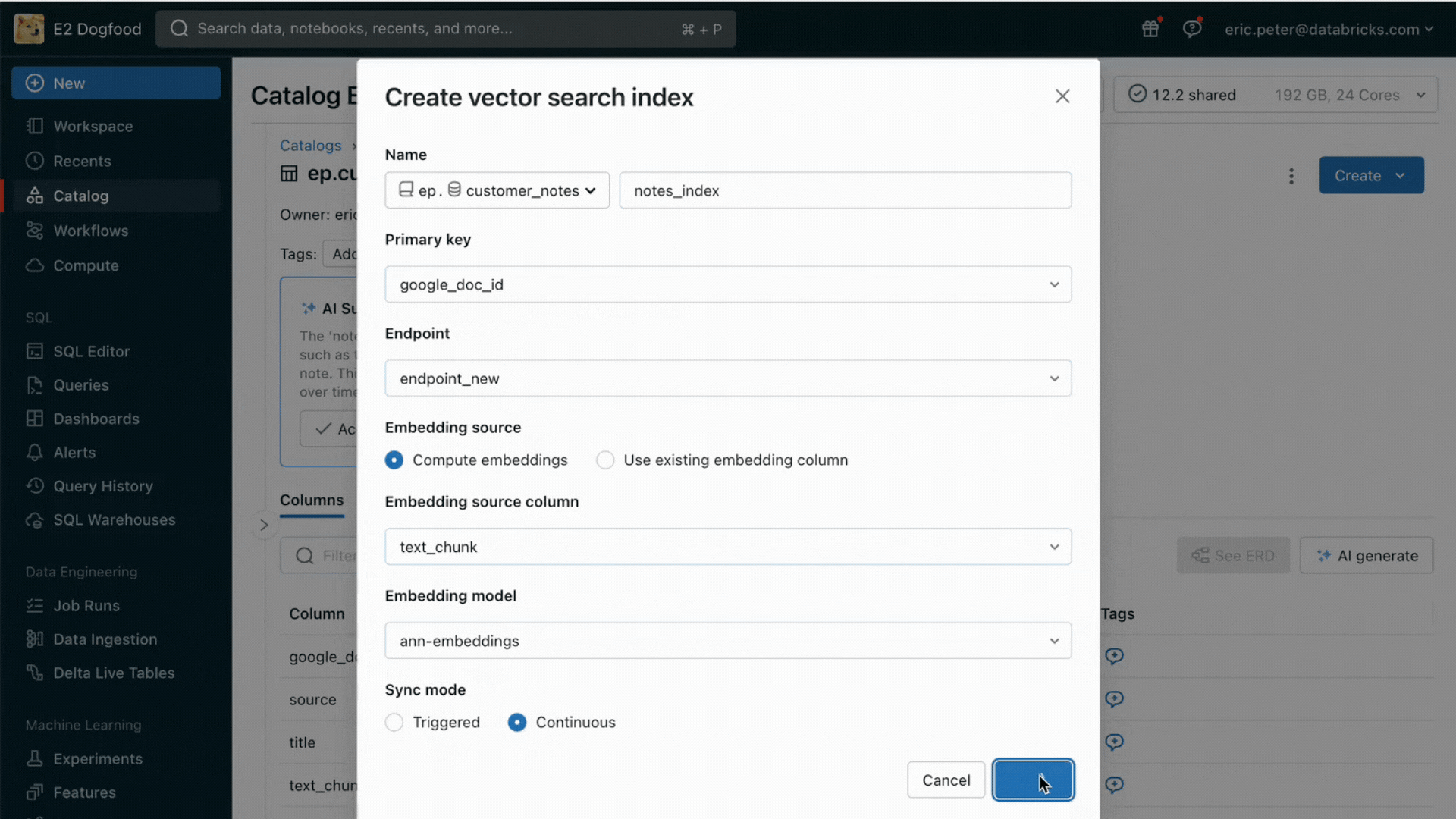
Con questa release, Databricks supporta in modo nativo il serving e l'indicizzazione dei dati per il recupero online. Per i dati non strutturati (testo, immagini e video), AI Search eseguirà automaticamente l'indicizzazione e la distribuzione dei dati dalle tabelle Delta, rendendoli accessibili tramite la ricerca per somiglianza semantica per le applicazioni RAG. Dietro le quinte, AI Search gestisce errori e nuovi tentativi e ottimizza le dimensioni dei batch per offrirti il meglio in termini di prestazioni, produttività e costi. Per i dati strutturati, Feature and Function Serving fornisce con tempi di risposta nell'ordine dei millisecondi query quei dati contestuali, ad esempio dati dell'utente o dell'account, che le aziende spesso vogliono inserire nei prompt per personalizzarli in base alle informazioni dell'utente.
Unity Catalog traccia automaticamente il lineage tra le copie offline e online dei set di dati serviti, rendendo molto più semplice il debug dei problemi di qualità dei dati. Inoltre, applica in modo coerente le impostazioni di controllo degli accessi tra i set di dati online e offline, il che significa che le aziende possono verificare e controllare meglio chi visualizza le informazioni proprietarie sensibili.
Sfida n. 2: confronto, ottimizzazione e serving dei Foundation Model
Un fattore determinante per la qualità di un'applicazione RAG è la scelta del modello LLM di base. Confrontare i modelli può essere difficile perché i modelli variano in base a diverse dimensioni, come la capacità di ragionamento, la propensione alle allucinazioni, la dimensione della finestra di contesto e il costo di serving. Alcuni modelli possono anche essere sottoposti a fine-tuning per applicazioni specifiche, il che può migliorare ulteriormente le prestazioni e potenzialmente ridurre i costi. Con il rilascio di nuovi modelli quasi ogni settimana, confrontare le permutazioni del modello di base per trovare la scelta migliore per una particolare applicazione può essere estremamente oneroso. A complicare ulteriormente le cose, i fornitori di modelli hanno spesso API diverse, rendendo molto difficile il confronto rapido o il future-proofing delle applicazioni RAG.
Con questa release, Databricks offre ora un ambiente unificato per lo sviluppo e la valutazione degli LLM, fornendo un set di strumenti coerente per tutte le famiglie di modelli su una piattaforma cloud-agnostic. Gli utenti di Databricks possono accedere ai modelli principali di Azure OpenAI Service, AWS Bedrock e Anthropic, a modelli open source come Llama 2 e MPT o ai modelli dei clienti ottimizzati e completamente personalizzati. Il nuovo AI Playground interattivo consente di chattare facilmente con questi modelli, mentre la nostra toolchain integrata con MLflow permette confronti approfonditi monitorando metriche chiave come la tossicità, la latenza e il conteggio dei token. Il confronto affiancato dei modelli nel Playground o in MLflow permette ai clienti di identificare il miglior modello candidato per ogni caso d'uso, supportando anche la valutazione del componente retriever.
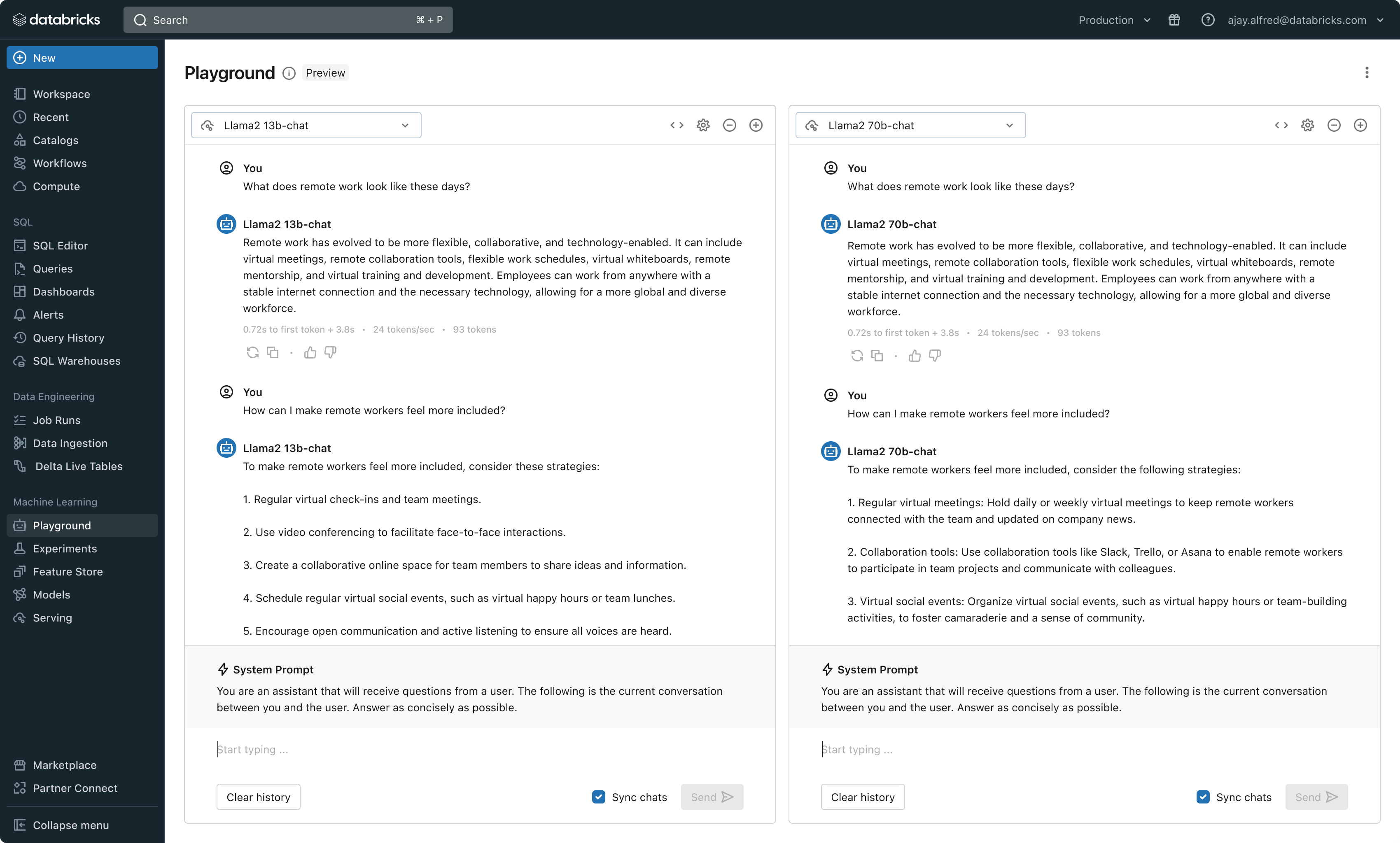
Databricks rilascia anche le API dei modelli di base, un set completamente gestito di modelli LLM che include le popolari famiglie di modelli Llama e MPT. Le API dei modelli di base possono essere utilizzate su base pay-per-token, riducendo drasticamente i costi e aumentando la flessibilità. Poiché le API dei Foundation Model sono servite dall'infrastruttura di Databricks, i dati sensibili non devono transitare verso servizi di terze parti.
In pratica, ottenere un'alta qualità spesso significa combinare modelli di base diversi a seconda dei requisiti specifici di ogni applicazione. L'architettura Model Serving di Databricks fornisce ora un'interfaccia unificata per distribuire, governare e interrogare qualsiasi tipo di LLM, che si tratti di un modello completamente personalizzato, di un modello gestito da Databricks o di un foundation model di terze parti. Questa flessibilità consente ai clienti di scegliere il modello giusto per il job giusto e di essere a prova di futuro di fronte ai futuri progressi nel set di modelli disponibili.
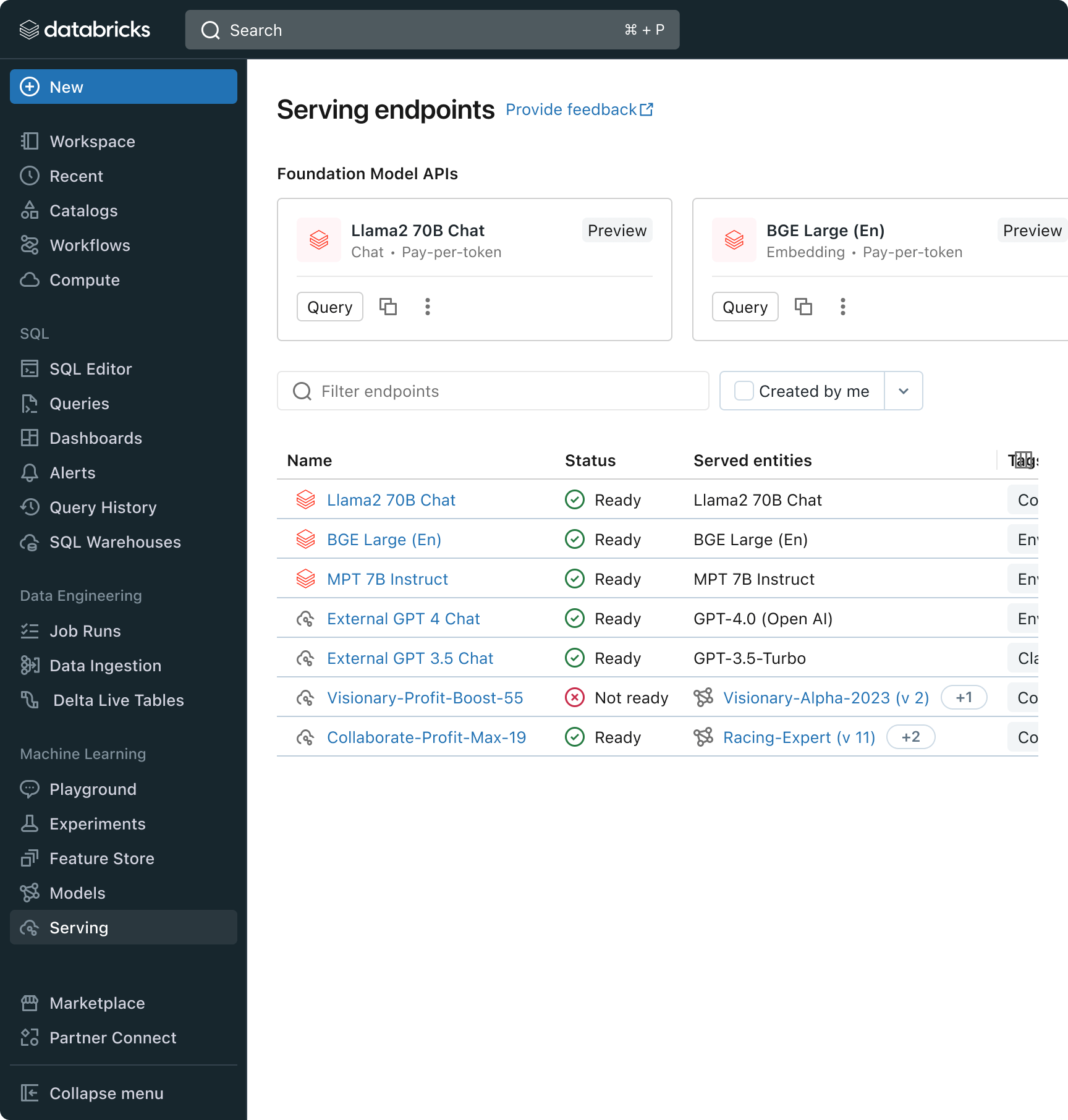
Sfida n. 3 - Garantire qualità e sicurezza in produzione
Una volta distribuita un'applicazione LLM, può essere difficile sapere quanto bene funzioni. A differenza del software tradizionale, le applicazioni basate sul linguaggio non hanno un'unica risposta corretta o condizioni di "errore" evidenti. Ciò significa che capire la qualità (quanto bene funziona?) o cosa costituisce un output anomalo, non sicuro o tossico (questa cosa è sicura?) non è banale. In Databricks abbiamo visto molti clienti esitare a implementare le applicazioni RAG, perché non sono sicuri se la qualità osservata in un piccolo prototipo interno si manterrà per la loro base di utenti su larga scala.
Incluso in questa versione, Lakehouse Monitoring fornisce una soluzione di monitoraggio della qualità completamente gestita per le applicazioni RAG. Lakehouse Monitoring analizza automaticamente gli output delle applicazioni alla ricerca di contenuti tossici, allucinati o comunque non sicuri. Questi dati possono poi alimentare dashboard, avvisi o altre pipeline di dati a valle e servire da base ad azioni successive. Poiché il monitoraggio è integrato con il lineage di set di dati e modelli, gli sviluppatori possono diagnosticare rapidamente errori relativi ad es. pipeline di dati obsolete o modelli che hanno cambiato comportamento in modo imprevisto.
Il monitoraggio non riguarda solo la sicurezza, ma anche la qualità. Lakehouse Monitoring può integrare concetti a livello di applicazione come il feedback degli utenti basato su "pollice in su/pollice in giù" o anche metriche derivate come la "percentuale di accettazione dell'utente" (la frequenza con cui un utente finale accetta i suggerimenti generati dall'AI). Secondo la nostra esperienza, la misurazione delle metriche utente end-to-end rafforza notevolmente la fiducia delle aziende sul fatto che le applicazioni RAG funzionino bene in un contesto reale. Le pipeline di monitoraggio sono anch'esse completamente gestite da Databricks, così gli sviluppatori possono dedicare tempo alle loro applicazioni invece di gestire l'infrastruttura di osservabilità.
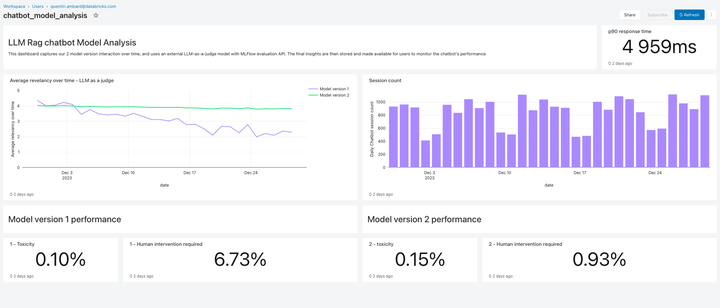
Le funzionalità di monitoraggio in questa release sono solo l'inizio. E non è finita qui!
Passaggi successivi
Abbiamo blog di approfondimento per tutta questa settimana e la prossima che illustrano in dettaglio le best practice di implementazione. Quindi tornate sul nostro blog Databricks, esplorate i nostri prodotti attraverso la nuova demo RAG, guardate il webinar on-demand sull'IA generativa di Databricks, seguite la formazione sull'IA generativa con il nostro percorso di apprendimento per Gen AI Engineer e date un'occhiata a una rapida demo video della suite di strumenti RAG in azione:
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.