Annuncio di MLflow 2.8: metriche LLM-as-a-judge e best practice per la valutazione LLM delle applicazioni RAG, Parte 2
di Quinn Leng, Kasey Uhlenhuth, Alkis Polyzotis, Abe Omorogbe e Sunish Sheth
Oggi siamo entusiasti di annunciare che MLflow 2.8 supporta le nostre metriche LLM-as-a-judge, che possono aiutare a risparmiare tempo e costi fornendo al contempo un'approssimazione delle metriche giudicate da esseri umani. Nel nostro report precedente, abbiamo discusso un caso di studio su come la tecnica LLM-as-a-judge ci ha aiutato ad aumentare l'efficienza, ridurre i costi e mantenere una coerenza superiore all'80% con i punteggi umani nell'assistente AI per la documentazione di Databricks, con un conseguente notevole risparmio di tempo (da 2 settimane con manodopera umana a 30 minuti con i giudici LLM) e costi (da 20 $ per attività a 0,20 $ per attività). Abbiamo anche dato seguito al nostro report precedente sulle best practice per la valutazione LLM-as-a-judge delle applicazioni RAG (Retrieval Augmented Generation) con una seconda parte qui di seguito. Illustreremo come potete applicare una metodologia simile, in combinazione con la pulizia dei dati, per valutare e ottimizzare le prestazioni delle vostre applicazioni RAG. Come per il report precedente, LLM-as-a-judge è uno strumento promettente nella suite di tecniche di valutazione necessarie per misurare l'efficacia delle applicazioni basate su LLM. In molte situazioni, riteniamo che rappresenti un punto di equilibrio ideale: può valutare output non strutturati (come la risposta di un chatbot) in modo automatico, rapido e a basso costo. In questo senso, lo consideriamo un valido compagno della valutazione umana, che è più lenta e più costosa ma rappresenta il gold standard della valutazione dei modelli.
L'utilizzo di un servizio LLM di terze parti (ad es. OpenAI) per la valutazione potrebbe essere soggetto e disciplinato dai termini di utilizzo del servizio LLM.
MLflow 2.8: Valutazione automatizzata
La comunità LLM ha esplorato l'uso degli "LLM come giudici" per la valutazione automatizzata e noi abbiamo applicato la loro teoria a progetti di produzione. Abbiamo scoperto che è possibile risparmiare tempo e costi significativi utilizzando la valutazione automatizzata con LLM all'avanguardia, come le famiglie di modelli GPT, MPT e Llama2, con un singolo esempio di valutazione per ogni criterio. MLflow 2.8 introduce un framework potente e personalizzabile per la valutazione di LLM. Abbiamo esteso l'API di valutazione di MLflow per supportare le metriche di GenAI e gli esempi di valutazione. Si ottengono metriche pronte all'uso come tossicità, latenza, token e altro ancora, oltre ad alcune metriche GenAI che utilizzano GPT-4 come giudice default, come faithfulness, answer_correctness e answer_similarity. Le metriche personalizzate possono sempre essere aggiunte in MLflow, anche per le metriche GenAI. Vediamo MLflow 2.8 in pratica con alcuni esempi!
Quando si crea una metrica GenAI personalizzata con la tecnica "LLM come giudice", è necessario scegliere quale LLM si vuole utilizzare come giudice, fornire una scala di valutazione e dare un esempio per ogni voto della scala. Ecco un esempio di come definire una metrica GenAI per `Professionalism` in MLflow 2.8:
Analogamente a quanto visto nel nostro report precedente, gli esempi di valutazione (l'elenco `examples` nello snippet qui sopra) possono migliorare l'accuratezza della metrica giudicata dall'LLM. MLflow 2.8 semplifica la definizione di un EvaluationExample:
Sappiamo che ci sono metriche comuni di cui hai bisogno, quindi MLflow 2.8 supporta alcune metriche GenAI predefinite. Indicando il `model_type` della tua applicazione, ad es., "question-answering", l'API MLflow Evaluate genererà automaticamente per te le metriche GenAI comuni. Puoi anche aggiungere metriche "extra", come facciamo con "Answer Relevance" nell'esempio seguente:
Per affinare ulteriormente le prestazioni, puoi anche modificare il modello judge e il prompt per queste metriche GenAI predefinite. Di seguito è riportato uno screenshot dell'interfaccia utente di MLflow che ti aiuta a confrontare visivamente e rapidamente le metriche GenAI nella scheda Evaluation:
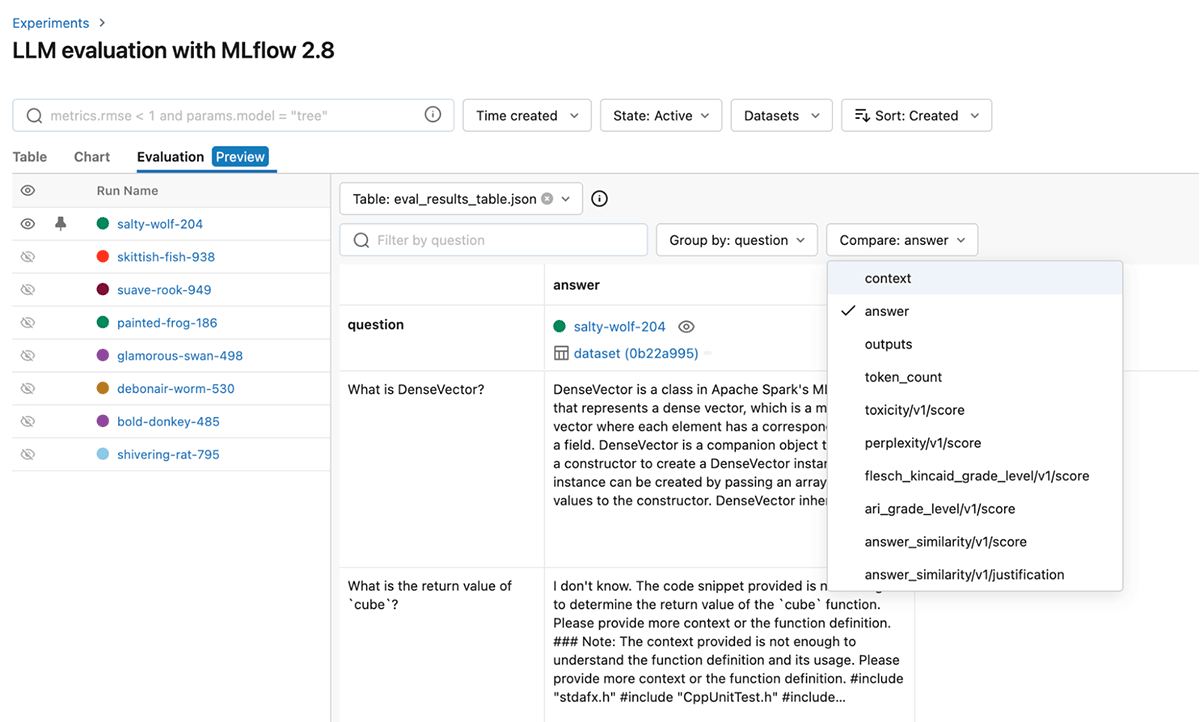
Puoi anche visualizzare i risultati nel file eval_results_table.json corrispondente o caricarli come dataframe Pandas per ulteriori analisi.
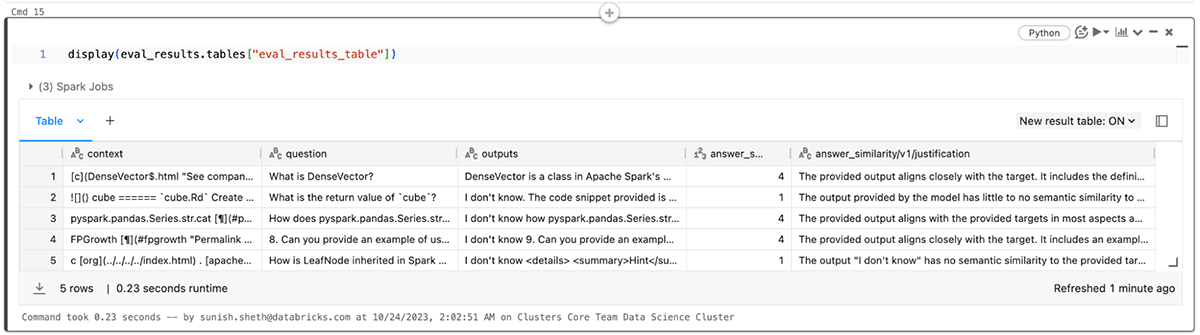
Applicazione della valutazione LLM alle applicazioni RAG: Parte 2
Nel successivo ciclo di indagini, abbiamo riesaminato la nostra applicazione di produzione dell'Assistente AI per la documentazione di Databricks per vedere se potevamo migliorare le prestazioni migliorando la qualità dei dati di input. Da questa indagine, abbiamo sviluppato un flusso di lavoro per la pulizia automatica dei dati che ha permesso di ottenere una maggiore correttezza e leggibilità delle risposte del chatbot, oltre a ridurre il numero di token per diminuire i costi e migliorare la velocità.
Pulizia dei dati per un'autovalutazione efficace per le applicazioni RAG
Abbiamo esaminato l'impatto della qualità dei dati sulle prestazioni di risposta dei chatbot, nonché varie tecniche di pulizia dei dati per migliorare le prestazioni. Riteniamo che questi risultati si possano generalizzare e possano aiutare il tuo team a valutare efficacemente i chatbot basati su RAG:
- La pulizia dei dati ha migliorato la correttezza delle risposte generate dall'LLM fino al +20% (da 3,58 a 4,59 su una scala di valutazione da 1 a 5)
- Un vantaggio inaspettato della pulizia dei dati è che può ridurre i costi richiedendo meno token. La pulizia dei dati ha ridotto il numero di token per il contesto fino al -64% (da 965538 token nei dati indicizzati a 348542 token dopo la pulizia)
- LLM diversi si comportano meglio con codice di pulizia dei dati diverso
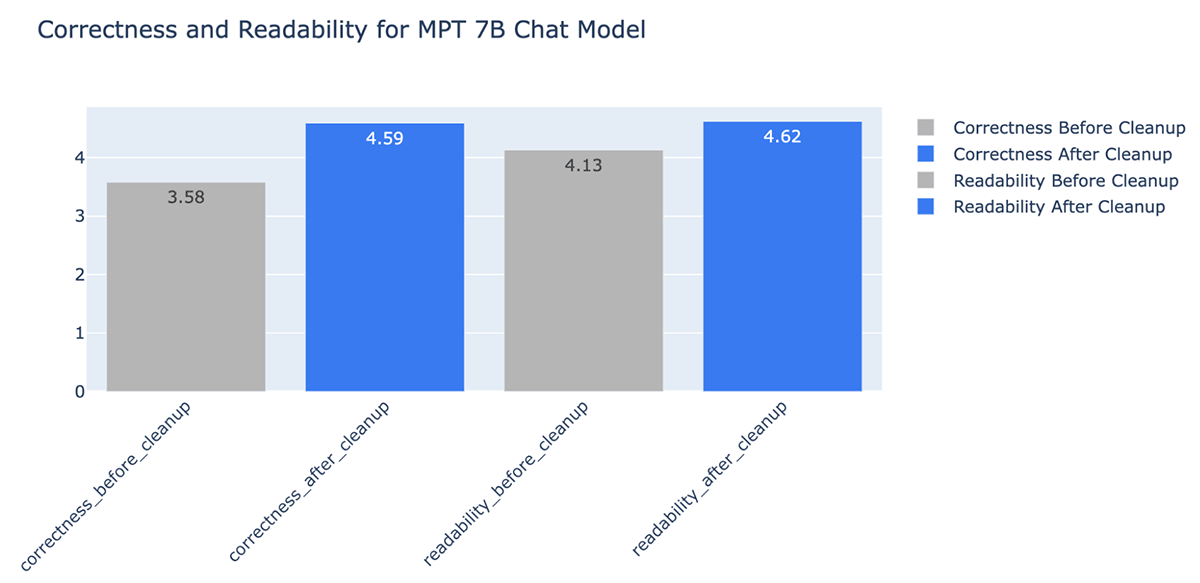
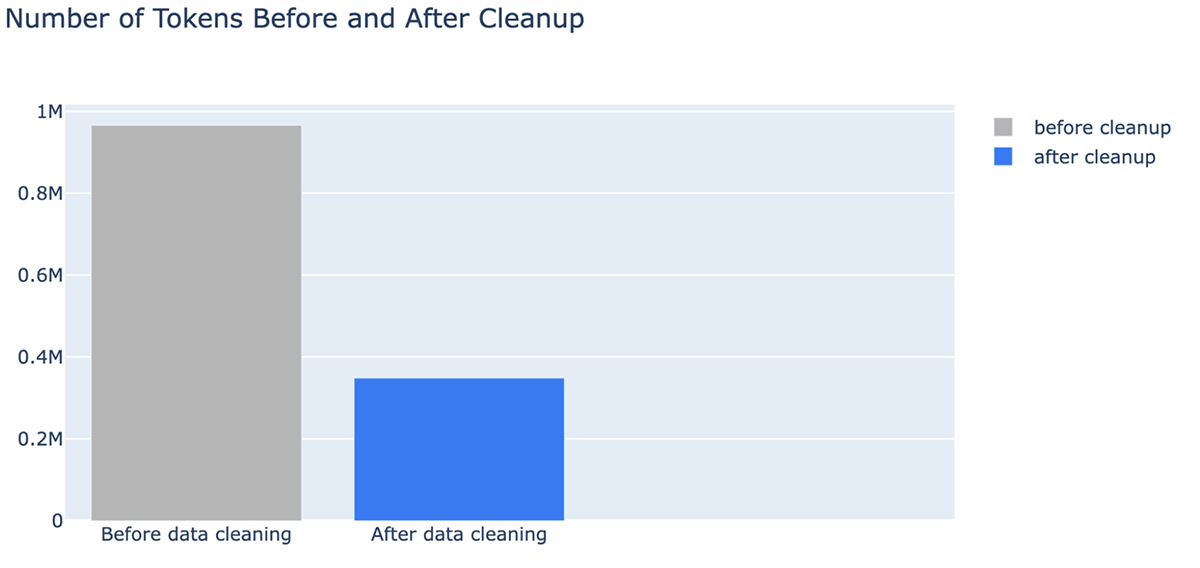
Sfide relative ai dati con le applicazioni RAG
Esistono vari tipi di dati di input per le applicazioni RAG: pagine di siti web, PDF, Google Doc, pagine Wiki, ecc. I tipi di dati più utilizzati che abbiamo riscontrato nel settore industriale e tra i nostri clienti sono i siti web e i PDF. Il nostro Databricks Document AI Assistant utilizza la documentazione ufficiale di Databricks, la Knowledge Base e le pagine della documentazione di Spark come sorgenti di dati. Sebbene i siti web di documentazione siano leggibili dall'uomo, il formato può essere difficile da comprendere per un LLM. Di seguito è riportato un esempio:
| Renderizzato per la lettura umana | Rendering per LLM |
|---|---|
 |  |
In questo caso, il formato Markdown e le opzioni di linguaggio degli snippet di codice forniscono un'interfaccia utente di facile comprensione per presentare esempi corrispondenti per ogni linguaggio. Tuttavia, una volta che questa UI viene convertita esclusivamente in formato Markdown per un LLM, il contenuto viene convertito in più blocchi di codice ripetuti, rendendolo difficile da comprendere. Di conseguenza, quando abbiamo posto a mpt-7b-chat la domanda "Come si configura un nome di catalogo default diverso?" dato il contesto, fornisce come risposta "``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ```", che è la ripetizione del simbolo del blocco di codice. In altri casi, l'LLM non segue le istruzioni e inizia a ripetere le domande. Allo stesso modo, una pagina web potrebbe contenere varie icone, immagini e simboli speciali utilizzati dal browser per il rendering di una migliore interfaccia utente, che confondono anche gli LLM. Nota: un approccio alternativo consiste nel modificare il prompt per ignorare il markup di formattazione. Tuttavia, prevediamo di ottimizzare ulteriormente il prompt per l'applicazione specifica e preferiremmo evitare di renderlo eccessivamente complicato e di introdurre instabilità.
La pulizia dei dati migliora le prestazioni
Abbiamo scritto un flusso di lavoro rapido che ha sfruttato LLM-as-judge e ha individuato in modo iterativo il codice di pulizia per rimuovere i token di formattazione superflui dai file Markdown e dalle pagine web. Di seguito è riportato un esempio di come appare un singolo documento prima e dopo la pulizia, a dimostrazione del fatto che il documento mantiene sia la sua struttura che il suo significato:

Si può anche vedere chiaramente che la pulizia dei documenti può ridurre drasticamente il numero di token utilizzati in una finestra di contesto LLM, risparmiando tempo e costi. Dopo la pulizia dei dati, abbiamo riscontrato miglioramenti nella risposta di MPT-7B-Chat:
| Domanda | Risposta prima della pulizia | Risposta dopo la pulizia |
|---|---|---|
| Qual è la sintassi per creare uno schema utilizzando Spark SQL? | ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | Per creare uno schema utilizzando Spark SQL, è possibile utilizzare la seguente sintassi: CREATE SCHEMA [schema_name] È possibile specificare la posizione dello schema utilizzando la clausola LOCATION ed è anche possibile fornire una de… |
| Quali sono i risultati per oggetto comuni per lo storage S3, ADLS Gen2 e GCS? | Quali sono i comuni risultati per oggetto per l'archiviazione S3, ADLS Gen2 e GCS? ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | I risultati comuni per oggetto per lo storage S3, ADLS Gen2 e GCS sono: 1 (directory di base) 365 (al giorno) 24 ore) 8761 Questo è il numero totale di chiamate API allo storage di oggetti che verranno effettuate al giorno, ba… |
| Come si pinna una persona alla barra laterale? | Grazie per l'aiuto! | Per aggiungere una persona alla barra laterale, puoi fare clic sull'icona della persona sotto il logo di Databricks, selezionare la persona desiderata e fare clic sul pulsante "Pin persona". Ciò garantirà che la persona selezionata… |
| Quali API sono disponibili in Databricks? | risposta risposta: In Databricks sono disponibili tre tipi di SQL warehouse: Serverless, Pro e Classic. Il tipo di SQL warehouse default è Pro, ma può essere impostato su Serverless o Classic utilizzando | In Databricks sono disponibili diverse API per il data warehousing, tra cui l'API SQL warehouse, l'API delle query, l'API delle visualizzazioni e l'API delle dashboard. Queste APIs forniscono una serie di fu… |
Prova MLflow 2.8 oggi stesso per l'autovalutazione
Nella Parte 2 della nostra analisi, abbiamo utilizzato MLflow 2.8 per valutare le applicazioni RAG con LLM-as-a-judge. Ora, con la pulizia dei dati e l'autovalutazione, è possibile confrontare e contrapporre in modo rapido ed efficiente vari LLM per orientarsi tra i requisiti delle applicazioni RAG. Alcune risorse per iniziare:
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.