Best practice per la valutazione tramite LLM di applicazioni RAG
Un case study sul bot della documentazione di Databricks
I chatbot sono il caso d'uso più diffuso per sfruttare le potenti capacità di chat e ragionamento dei modelli linguistici di grandi dimensioni (LLM). L'architettura RAG (retrieval-augmented generation) sta rapidamente diventando lo standard di settore per lo sviluppo di chatbot perché combina i vantaggi di una base di conoscenza (tramite un vector store) e di modelli generativi (ad es. GPT-3.5 e GPT-4) per ridurre le allucinazioni, mantenere informazioni aggiornate e sfruttare la conoscenza specifica del dominio. Tuttavia, la valutazione della qualità delle risposte dei chatbot rimane oggi un problema irrisolto. In assenza di standard di settore definiti, le organizzazioni ricorrono alla valutazione umana (etichettatura), un processo che richiede molto tempo ed è difficile da scalare.
Abbiamo applicato la teoria alla pratica per contribuire a definire le best practice per la valutazione automatizzata degli LLM, in modo da poter implementare applicazioni RAG in produzione rapidamente e con sicurezza. Questo blog è il primo di una serie di approfondimenti che stiamo conducendo in Databricks per fornire informazioni sulla valutazione degli LLM. Tutte le ricerche in questo post sono state condotte da Quinn Leng, Senior Software Engineer presso Databricks e creatore del Databricks Documentation AI Assistant.
Sfide con l'autovalutazione nella pratica
Recentemente, la community LLM ha iniziato a esplorare l'uso di "LLM come giudice" per la valutazione automatizzata e in molti utilizzano potenti LLM come GPT-4 per valutare i propri output LLM. L'articolo di ricerca del gruppo lmsys esplora la fattibilità e i pro e i contro dell'utilizzo di vari LLM (GPT-4, ClaudeV1, GPT-3.5) come giudici per attività di scrittura, matematica e conoscenza generale.
Nonostante tutta questa ottima ricerca, ci sono ancora molte domande senza risposta su come applicare i giudici LLM in pratica:
- Allineamento con la valutazione umana: Nello specifico per un chatbot Q&A su documenti, quanto bene la valutazione di un LLM valutatore riflette l'effettiva preferenza umana in termini di correttezza, leggibilità e completezza delle risposte?
- Accuratezza tramite esempi: qual è l'efficacia di fornire alcuni esempi di valutazione al giudice LLM e di quanto aumenta l'affidabilità e la riutilizzabilità del giudice LLM su metriche diverse?
- Scale di valutazione appropriate: Quale scala di valutazione è raccomandata, dato che framework diversi utilizzano scale di valutazione diverse (ad es. AzureML usa una scala da 0 a 100, mentre langchain usa scale binarie)?
- Applicabilità a diversi casi d'uso: con la stessa metrica di valutazione (ad es. correttezza), in che misura la metrica di valutazione può essere riutilizzata in diversi casi d'uso (ad es. chat informale, riepilogo dei contenuti, generazione aumentata da recupero)?
Applicazione di un'autovalutazione efficace per le applicazioni RAG
Abbiamo esplorato le possibili opzioni per le domande descritte sopra nel contesto della nostra applicazione chatbot in Databricks. Riteniamo che i nostri risultati siano generalizzabili e possano quindi aiutare il tuo team a valutare in modo efficace i chatbot basati su RAG a un costo inferiore e con maggiore velocità:
- L'LLM come giudice concorda con la valutazione umana in oltre l'80% dei giudizi. L'utilizzo di LLM come giudici per la valutazione del nostro chatbot basato su documenti si è rivelato efficace quanto i giudici umani, corrispondendo al punteggio esatto in oltre l'80% dei giudizi e rientrando in una distanza di 1 punto (su una scala da 0 a 3) in oltre il 95% dei giudizi.
- Risparmia sui costi utilizzando GPT-3.5 con esempi. GPT-3.5 può essere utilizzato come giudice LLM se fornisci esempi per ogni punteggio di valutazione. A causa del limite della dimensione del contesto, è pratico solo utilizzare una scala di valutazione a bassa precisione. L'utilizzo di GPT-3.5 con esempi invece di GPT-4 riduce di 10 volte il costo del giudice LLM e migliora la velocità di oltre 3 volte.
- Utilizzare scale di valutazione a bassa precisione per una più facile interpretazione. Abbiamo riscontrato che i punteggi di valutazione a precisione inferiore, come 0, 1, 2, 3 o anche binari (0, 1), possono mantenere in gran parte la precisione rispetto a scale di precisione più elevate, come da 0 a 10,0 o da 0 a 100,0, rendendo al contempo molto più semplice fornire rubriche di valutazione sia agli annotatori umani che ai giudici LLM. L'uso di una scala di precisione inferiore consente inoltre la coerenza delle scale di valutazione tra diversi giudici LLM (ad esempio tra GPT-4 e claude2).
- Le applicazioni RAG richiedono i propri benchmark. Un modello potrebbe avere buone prestazioni in un benchmark specializzato pubblicato (ad esempio, chat informale, matematica o scrittura creativa), ma questo non garantisce buone prestazioni in altre attività (ad esempio, rispondere a domande da un determinato contesto). I benchmark dovrebbero essere utilizzati solo se il caso d'uso corrisponde, cioè un'applicazione RAG dovrebbe essere valutata solo con un benchmark RAG.
Sulla base della nostra ricerca, raccomandiamo la seguente procedura quando si utilizza un giudice LLM:
- Utilizza una scala di valutazione da 1 a 5
- Usa GPT-4 come giudice LLM senza esempi per comprendere le regole di valutazione
- Passa a GPT-3.5 come giudice LLM con un esempio per punteggio.
La nostra metodologia per stabilire le best practice
Il resto di questo post illustrerà la serie di esperimenti che abbiamo condotto per definire queste best practice.
Setup dell'Experiment
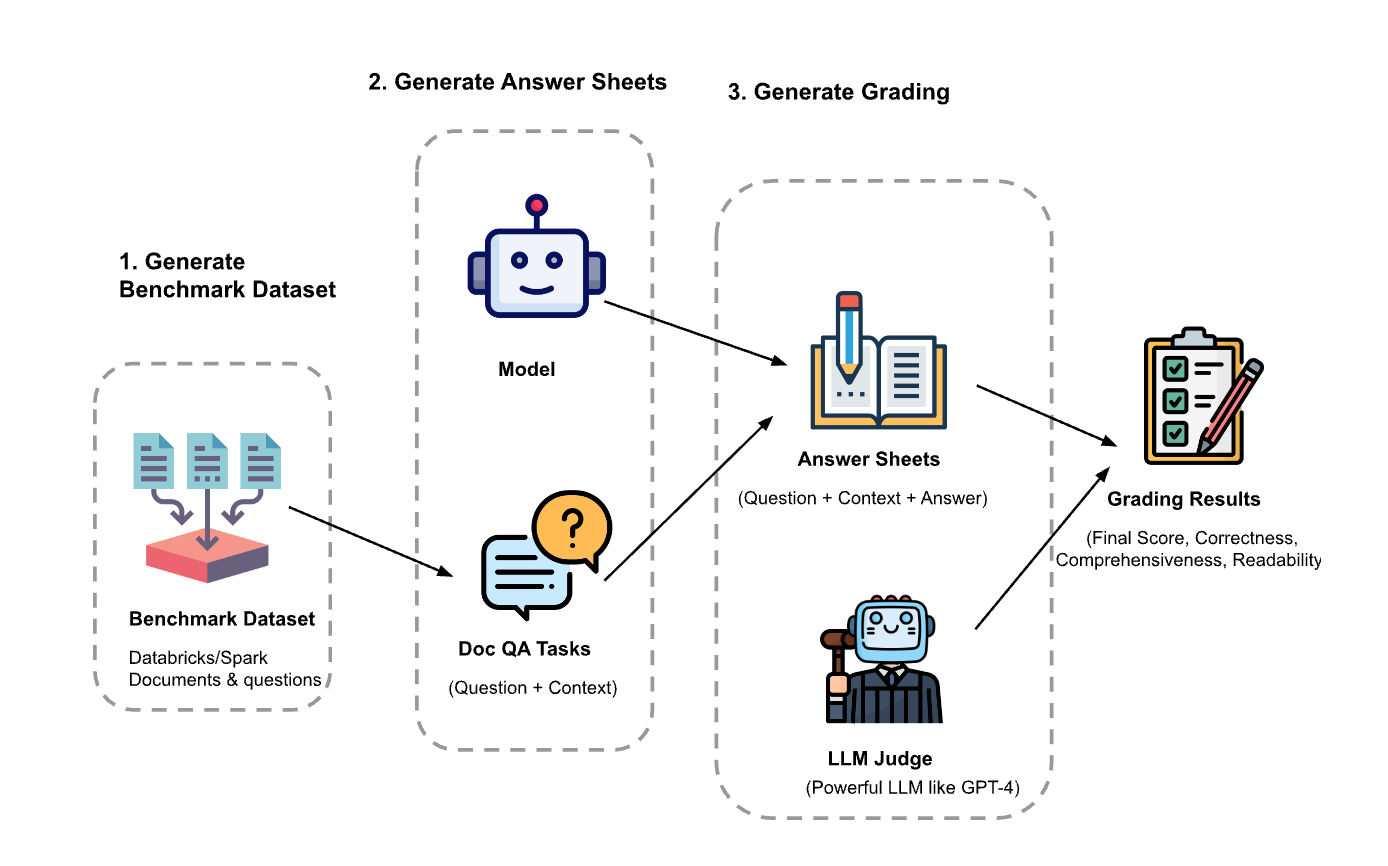
L'esperimento prevedeva tre passaggi:
Generare il set di dati di valutazione: abbiamo creato un set di dati a partire da 100 domande e contesti dai documenti di Databricks. Il contesto rappresenta (parti di) documenti pertinenti alla domanda.

- Genera fogli di risposte: utilizzando il set di dati di valutazione, abbiamo richiesto a diversi modelli linguistici di generare risposte e abbiamo archiviato le coppie domanda-contesto-risposta in un set di dati chiamato "fogli di risposte". In questa indagine, abbiamo utilizzato GPT-4, GPT-3.5, Claude-v1, Llama2-70b-chat, Vicuna-33b e mpt-30b-chat.
- Genera voti: dati i fogli delle risposte, abbiamo utilizzato vari LLM per generare i voti e le relative motivazioni. I voti sono un punteggio composito di Correttezza (ponderata al 60%), Completezza (ponderata al 20%) e Leggibilità (ponderata al 20%). Abbiamo scelto questo schema di ponderazione per riflettere la nostra preferenza per la correttezza nelle risposte generate. Altre applicazioni possono regolare questi pesi in modo diverso, ma ci aspettiamo che la Correttezza rimanga un fattore dominante.
Inoltre, sono state utilizzate le seguenti tecniche per evitare il bias posizionale e migliorare l'affidabilità:
- Bassa temperatura (temperatura 0.1) per garantire la riproducibilità.
- Valutazione a risposta singola invece del confronto a coppie.
- Catena di pensieri per consentire all'LLM di ragionare sul processo di valutazione prima di fornire il punteggio finale.
- Generazione few-shot in cui all'LLM vengono forniti diversi esempi nella rubrica di valutazione per ogni valore di punteggio per ciascun fattore (Correttezza, Completezza, Leggibilità).
Esperimento 1: allineamento con la valutazione umana
Per confermare il grado di accordo tra gli annotatori umani e i giudici LLM, abbiamo inviato le schede di risposta (scala di valutazione 0-3) di gpt-3.5-turbo e vicuna-33b a una società di etichettatura per raccogliere etichette umane e abbiamo quindi confrontato il risultato con l'output di valutazione di GPT-4. Di seguito sono riportati i risultati:
I giudici umani e GPT-4 possono raggiungere un accordo superiore all'80% sul punteggio di correttezza e leggibilità. E se abbassiamo il requisito a una differenza di punteggio minore o uguale a 1, il livello di accordo può superare il 95%.
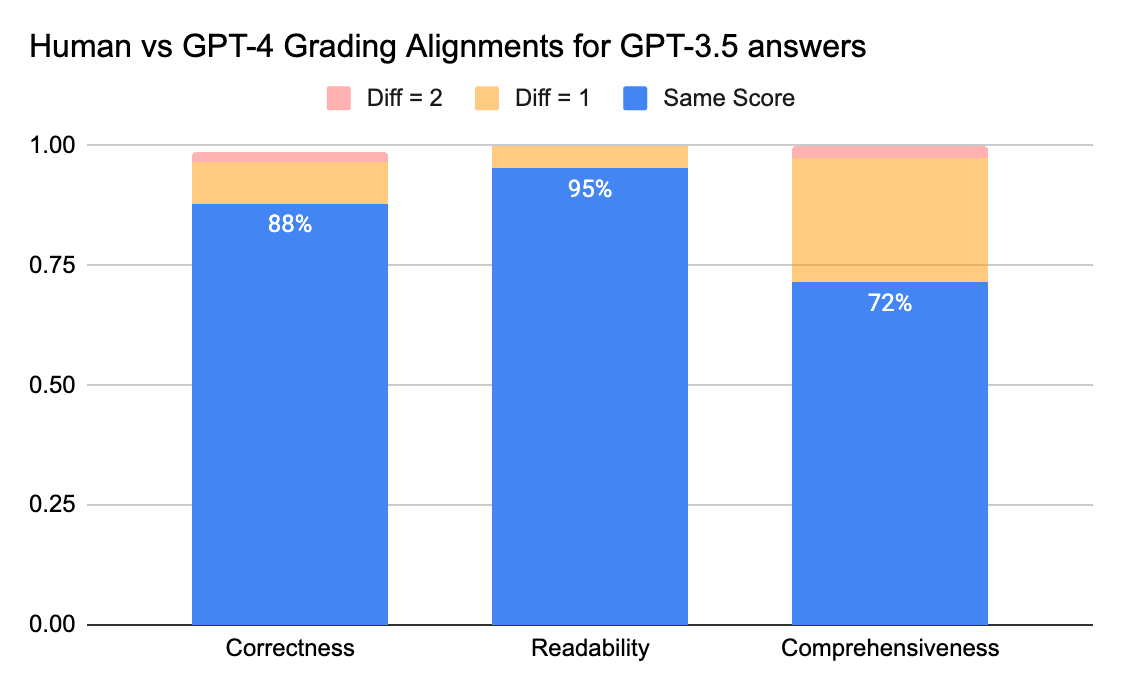
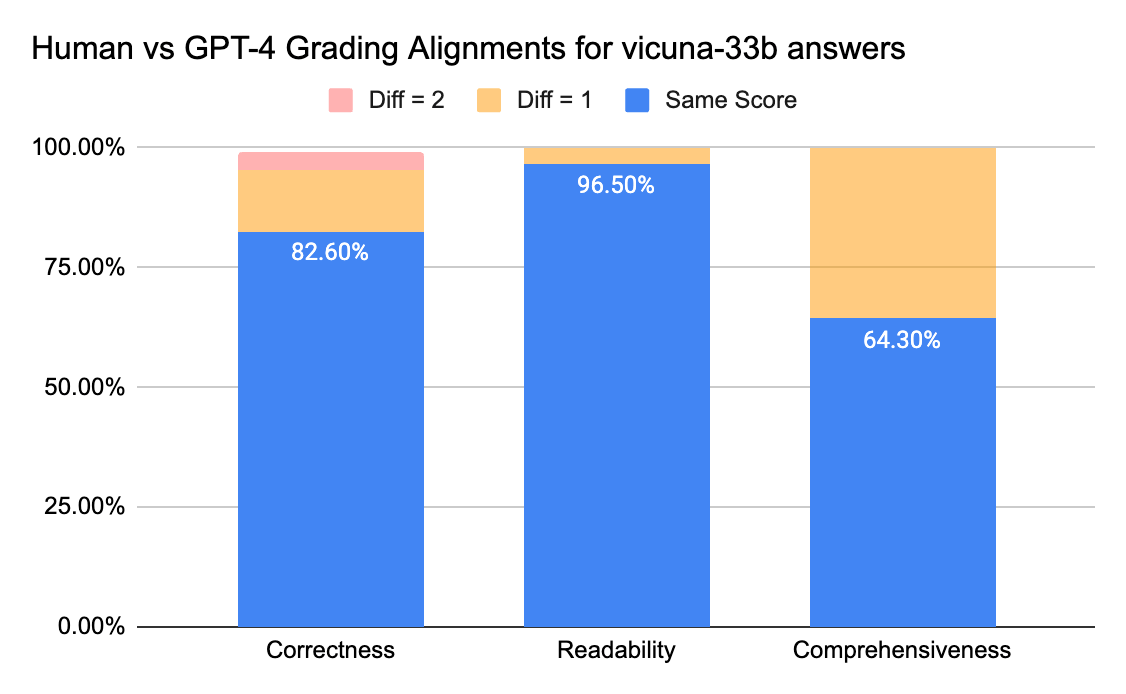
La metrica Completezza ha meno allineamento, il che corrisponde a quanto abbiamo sentito dagli stakeholder aziendali, i quali hanno condiviso che "completo" sembra più soggettivo rispetto a metriche come Correttezza o Leggibilità.
Esperimento 2: accuratezza tramite esempi
Il paper di lmsys utilizza questo prompt per istruire il giudice LLM a valutare in base a utilità, pertinenza, accuratezza, profondità, creatività e livello di dettaglio della risposta. Tuttavia, il paper non fornisce dettagli specifici sulla rubrica di valutazione. Dalla nostra ricerca, abbiamo scoperto che molti fattori possono influenzare in modo significativo il punteggio finale, ad esempio:
- L'importanza di diversi fattori: Utilità, Pertinenza, Accuratezza, Profondità, Creatività
- L'interpretazione di fattori come l'utilità è ambigua
- Se diversi fattori sono in conflitto tra loro, laddove una risposta è utile ma non accurata
Abbiamo sviluppato una rubrica per istruire un giudice LLM per una determinata scala di valutazione, provando quanto segue:
- Prompt originale: Di seguito è riportato il prompt originale utilizzato nel paper lmsys:
|
Abbiamo adattato il prompt originale del paper lmsys per emettere le nostre metriche su correttezza, completezza e leggibilità e anche per chiedere al giudice di fornire una giustificazione di una riga prima di assegnare ogni punteggio (per beneficiare del ragionamento chain-of-thought). Di seguito sono riportate la versione zero-shot del prompt, che non fornisce alcun esempio, e la versione few-shot del prompt, che fornisce un esempio per ogni punteggio. Quindi abbiamo utilizzato gli stessi fogli di risposta come input e confrontato i risultati valutati dei due tipi di prompt.
- Apprendimento zero-shot: richiedere al giudice LLM di emettere le nostre metriche su correttezza, completezza e leggibilità e chiedere anche al giudice di fornire una giustificazione di una riga per ogni punteggio.
- Apprendimento Few-Shot: Abbiamo adattato il prompt zero-shot per fornire esempi espliciti per ogni punteggio della scala. Il nuovo prompt:
Da questo esperimento abbiamo imparato diverse cose:
- L'utilizzo del prompt Few Shots con GPT-4 non ha prodotto una differenza evidente nella coerenza dei risultati. Quando abbiamo incluso la rubrica di valutazione dettagliata con esempi, non abbiamo riscontrato un miglioramento evidente nei risultati di valutazione di GPT-4 su diversi modelli LLM. Curiosamente, ha causato una leggera varianza nell'intervallo dei punteggi.
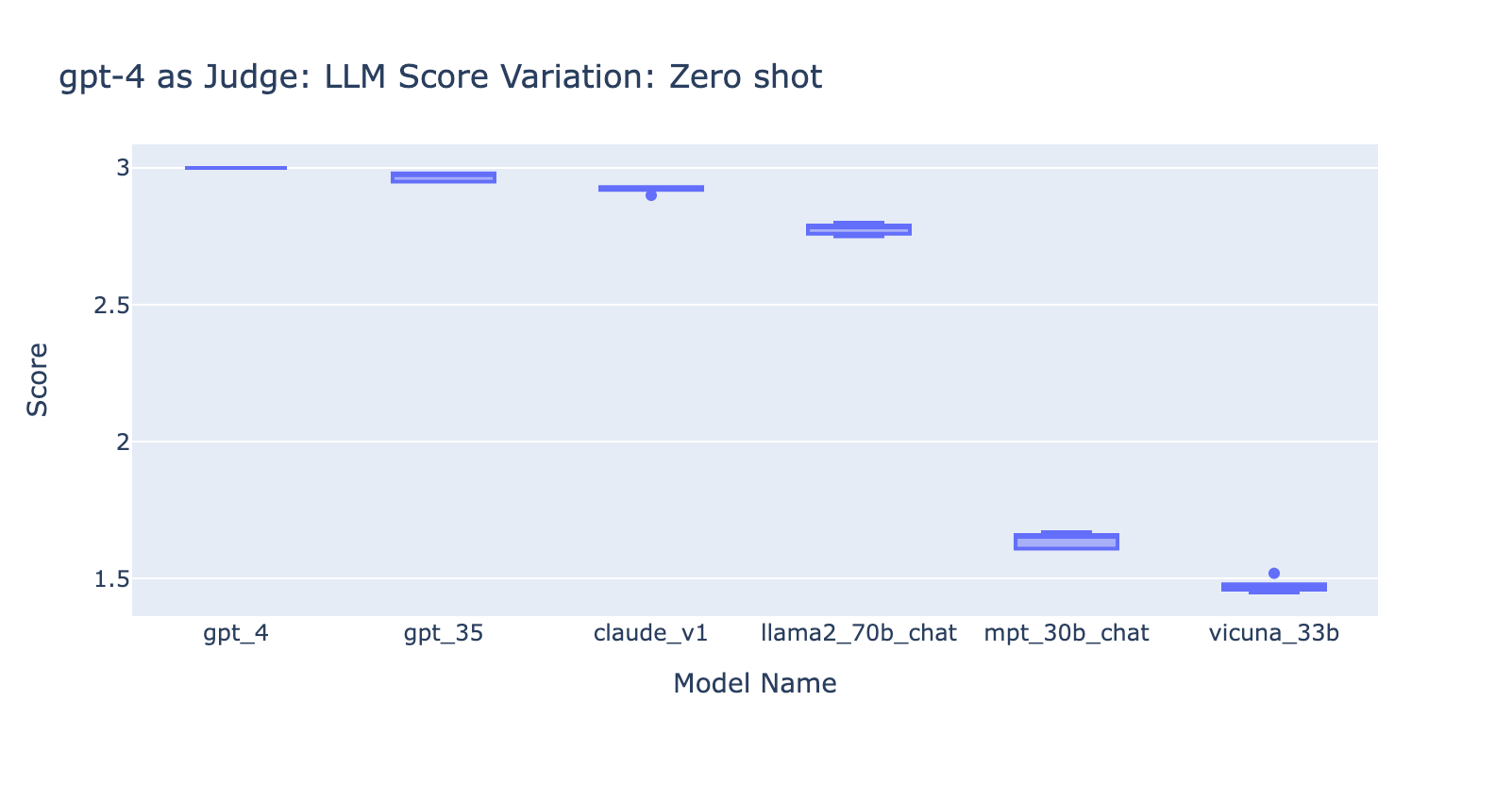
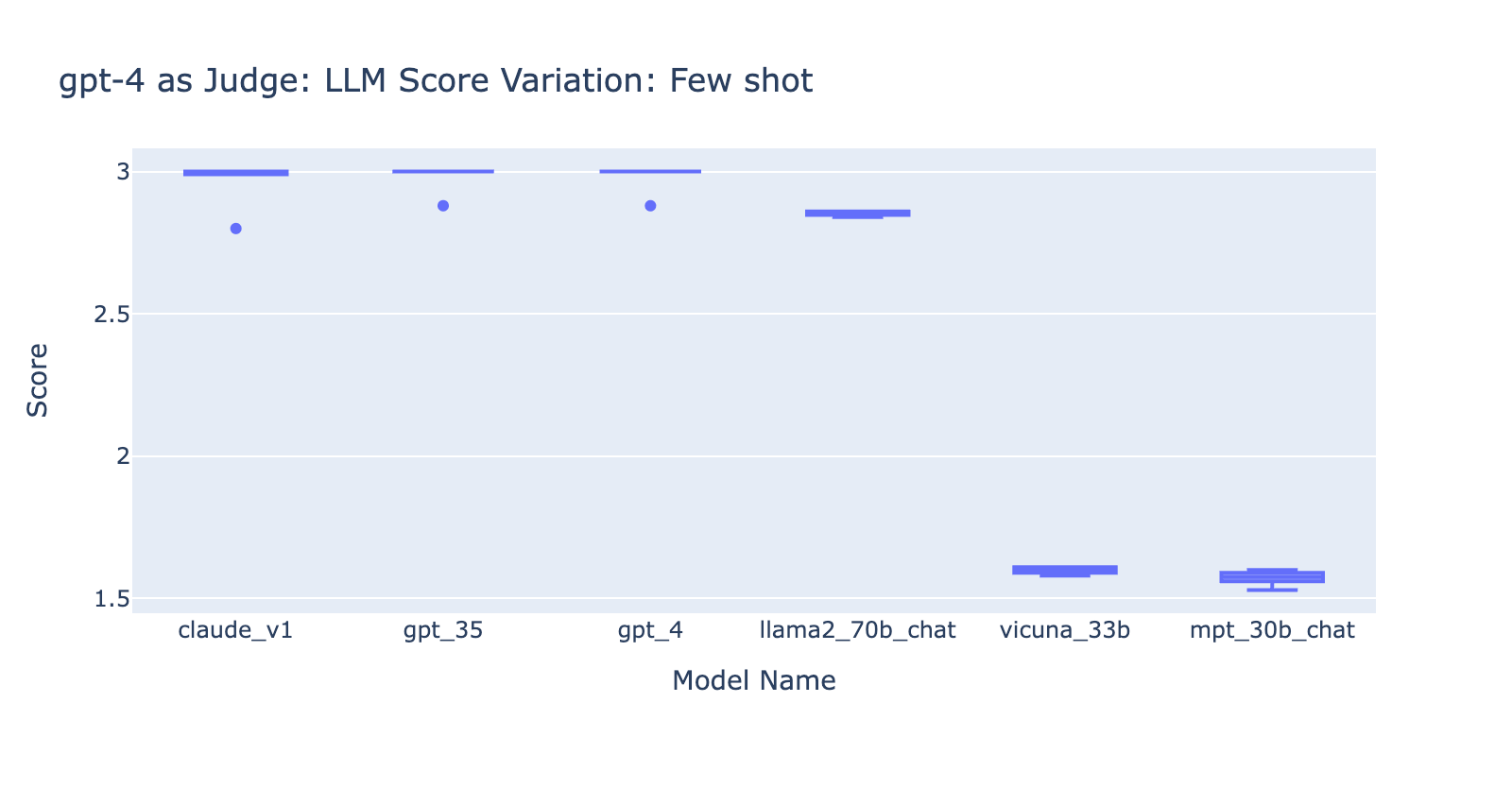
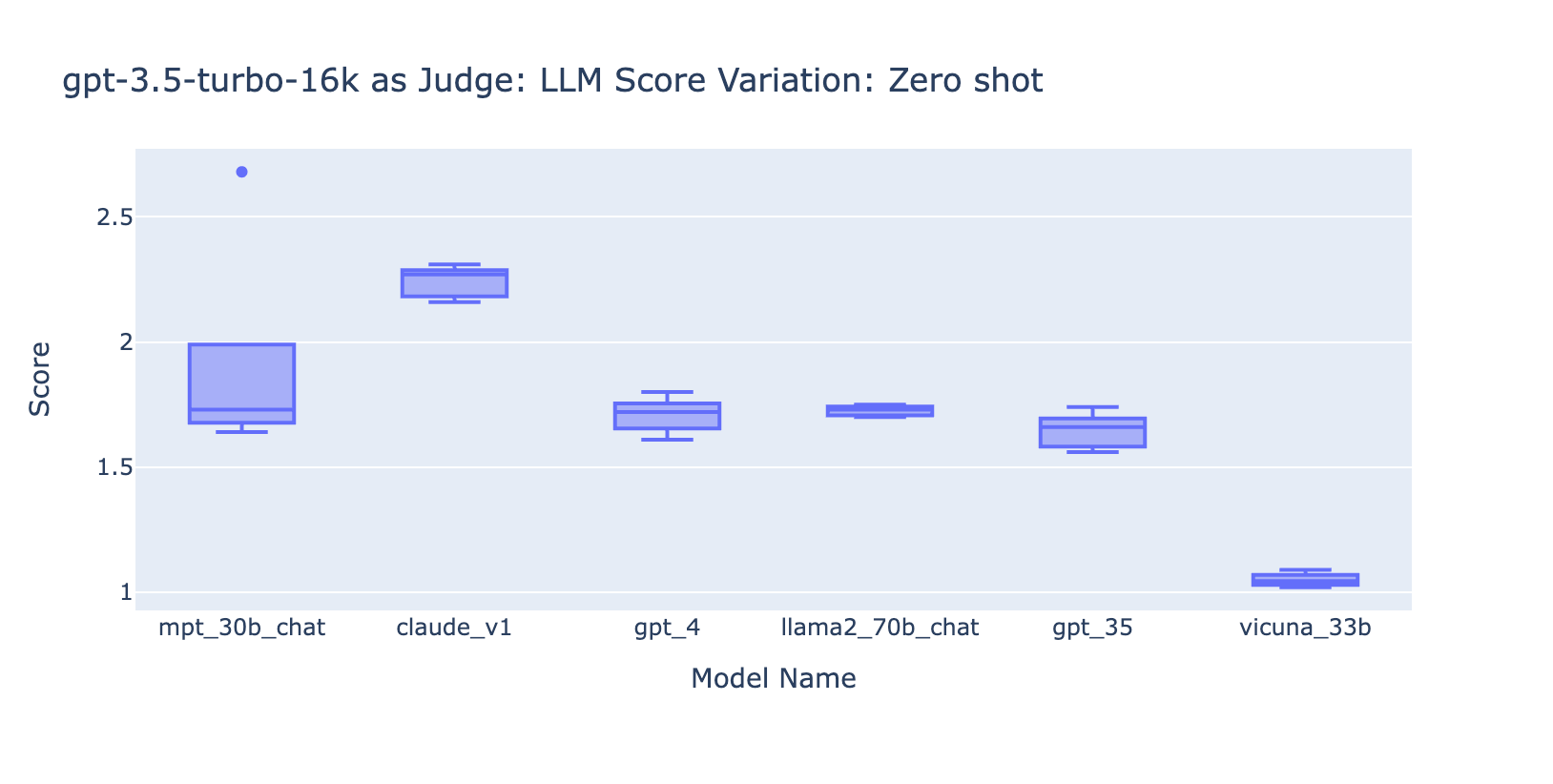
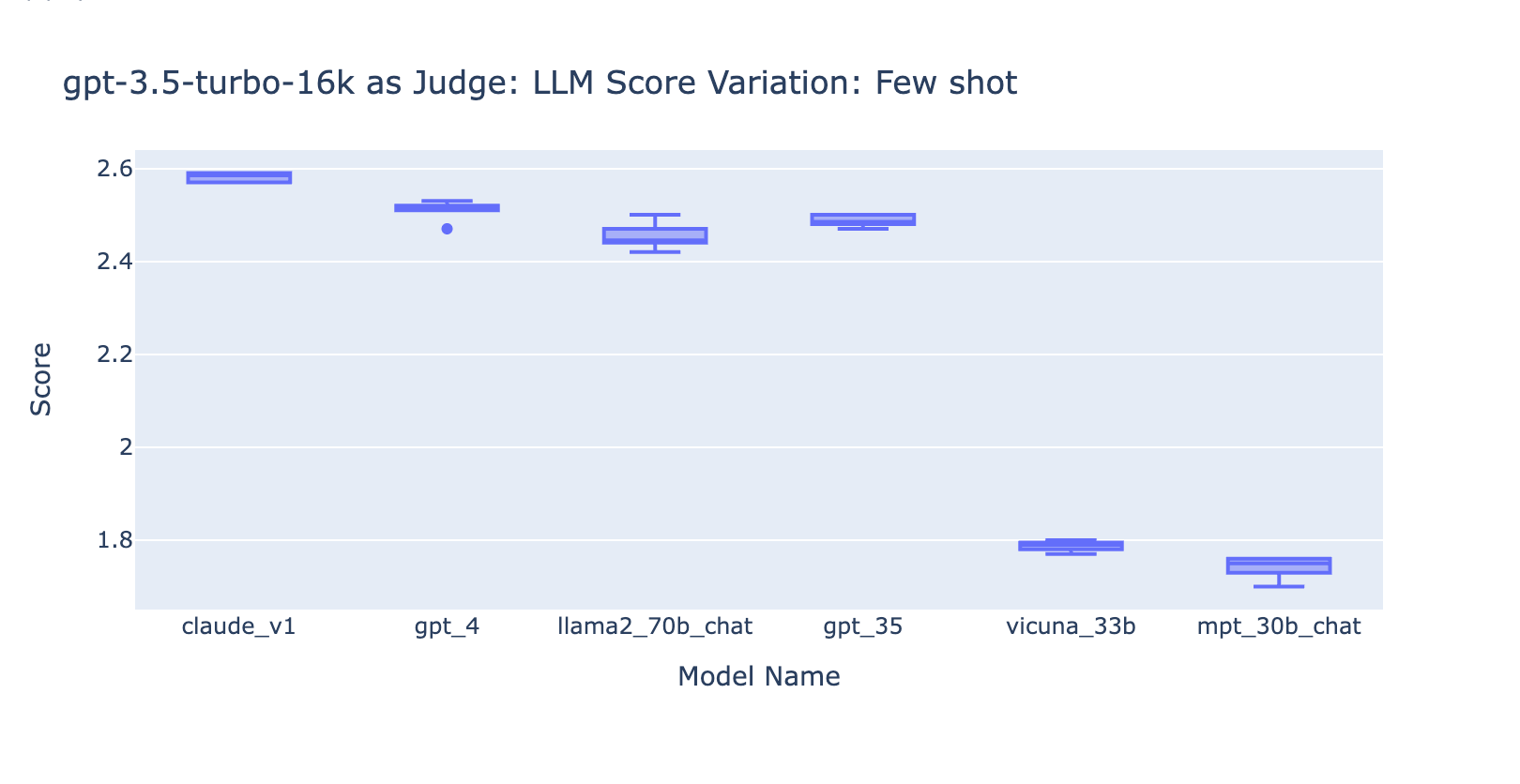
- L'inclusione di alcuni esempi per GPT-3.5-turbo-16k migliora in modo significativo la coerenza dei punteggi e rende il risultato utilizzabile. L'inclusione di una griglia/esempi di valutazione dettagliati comporta un miglioramento molto evidente sul risultato della valutazione da parte di GPT-3.5 (grafico a destra). Sebbene il valore effettivo del punteggio medio sia leggermente diverso tra GPT-4 e GPT-3.5 (punteggio 3.0 contro 2.6), la classificazione e la precisione rimangono abbastanza coerenti.
- Al contrario, (screenshot a sinistra) l'uso di GPT-3.5 senza una rubrica di valutazione ottiene risultati molto incoerenti ed è completamente inutilizzabile
- Si noti che stiamo utilizzando GPT-3.5-turbo-16k invece di GPT-3.5-turbo poiché il prompt può superare i 4k token.
Esperimento 3: Scale di valutazione appropriate
Il paper LLM-as-judge utilizza una scala non intera da 0 a 10 (ovvero float) per la scala di valutazione; in altre parole, utilizza una rubrica ad alta precisione per il punteggio finale. Abbiamo riscontrato che queste scale ad alta precisione causano problemi a valle con quanto segue:
- Coerenza: i valutatori, sia umani che LLM, hanno faticato a mantenere lo stesso standard per lo stesso punteggio durante la valutazione ad alta precisione. Di conseguenza, abbiamo riscontrato che i punteggi di output sono meno coerenti tra i giudici se si passa da scale a bassa precisione a scale ad alta precisione.
- Spiegabilità: Inoltre, se vogliamo eseguire la convalida incrociata dei risultati giudicati dall'LLM con i risultati giudicati da persone, dobbiamo fornire istruzioni su come valutare le risposte. È molto difficile fornire istruzioni accurate per ogni "punteggio" in una scala di valutazione ad alta precisione; ad esempio, qual è un buon esempio per una risposta con un punteggio di 5,1 rispetto a 5,6?
Abbiamo sperimentato varie scale di valutazione a bassa precisione per fornire una guida sulla "migliore" da utilizzare; in definitiva, raccomandiamo una scala intera da 0 a 3 o da 0 a 4 (se si desidera attenersi alla scala Likert). Abbiamo provato 0-10, 1-5, 0-3 e 0-1 e abbiamo imparato:
- La valutazione binaria funziona per metriche semplici come "usabilità" o "buono/cattivo".
- Per le scale come 0-10 è difficile definire criteri di distinzione tra tutti i punteggi.
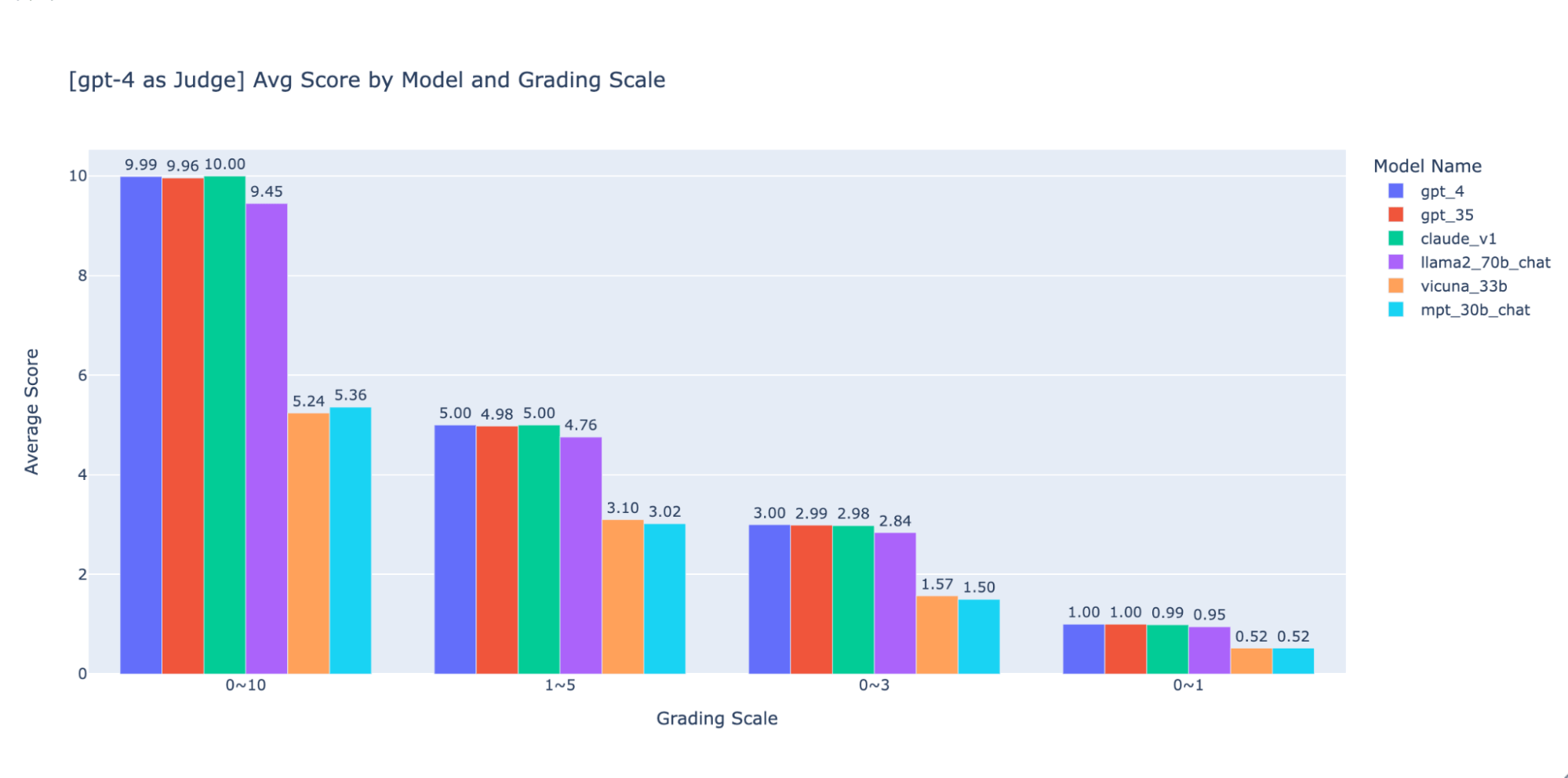
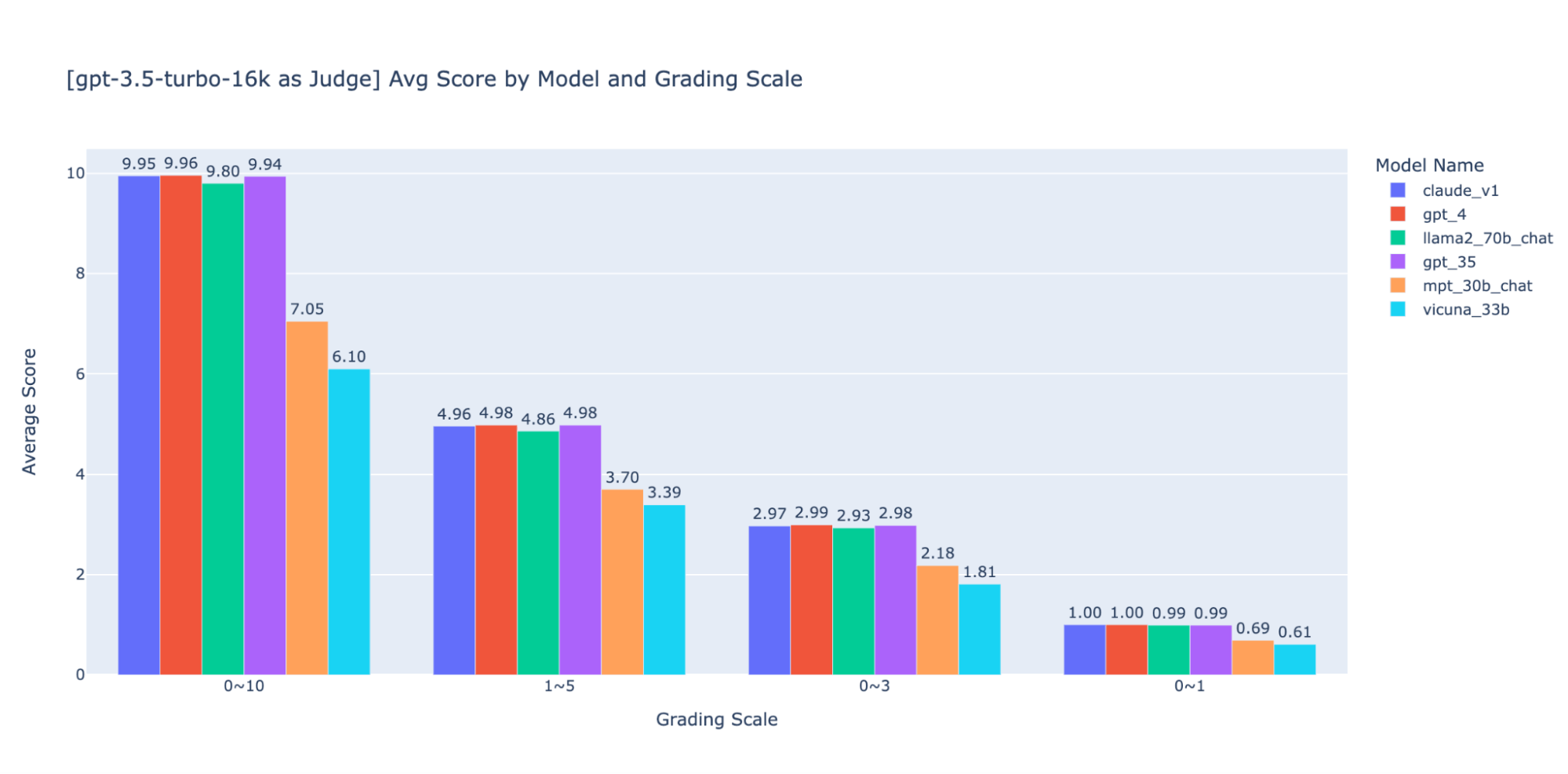
Come mostrato nei grafici precedenti, sia GPT-4 che GPT-3.5 possono mantenere una classificazione coerente dei risultati utilizzando diverse scale di valutazione a bassa precisione, pertanto l'utilizzo di una scala di valutazione più bassa come 0~3 o 1~5 può bilanciare la precisione con la spiegabilità)
Pertanto consigliamo una scala di valutazione da 0 a 3 o da 1 a 5 per facilitare l'allineamento con le etichette umane, il ragionamento sui criteri di punteggio e la fornitura di esempi per ogni punteggio nell'intervallo.
Experiment 4: applicabilità ai diversi casi d'uso
Il paper LLM-as-judge mostra che sia il giudizio dell'LLM che quello umano classificano il modello Vicuna-13B come un concorrente diretto di GPT-3.5:
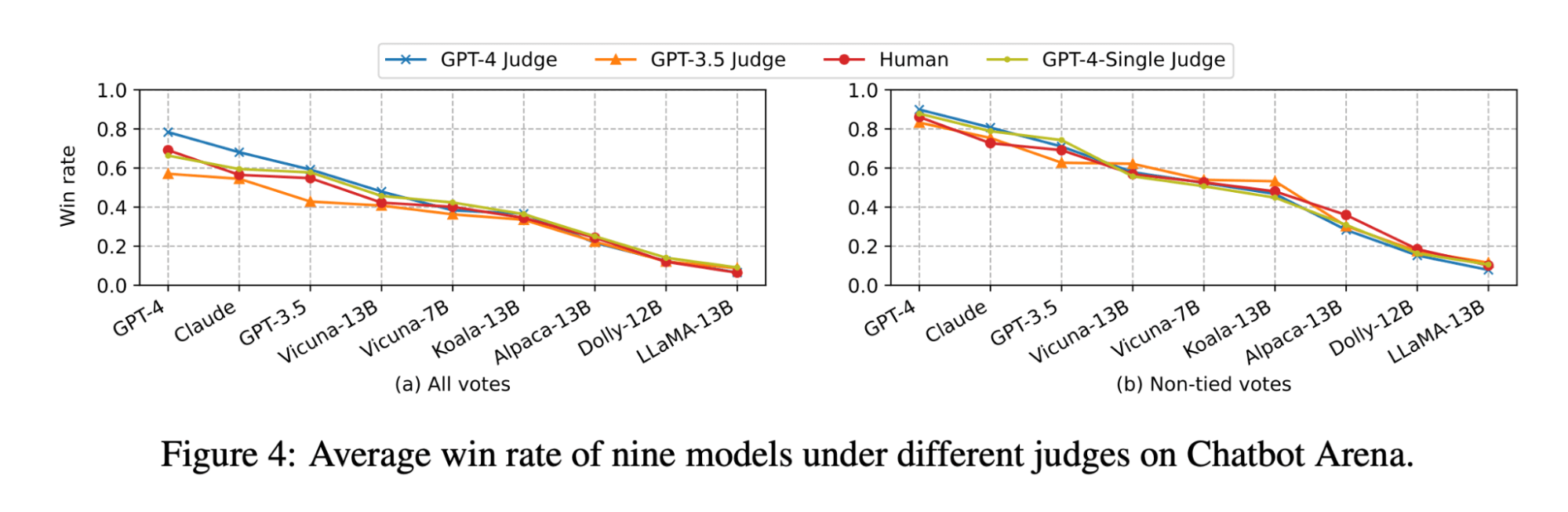
(La figura è tratta dalla Figura 4 del paper LLM-as-judge: https://arxiv.org/pdf/2306.05685.pdf )
Tuttavia, quando abbiamo eseguito il benchmark del set di modelli per i nostri casi d'uso di Q&A su documenti, abbiamo riscontrato che anche il modello Vicuna-33B, molto più grande, ha prestazioni notevolmente peggiori rispetto a GPT-3.5 nel rispondere a domande basate sul contesto. Questi risultati sono verificati anche da GPT-4, GPT-3.5 e da giudici umani (come menzionato nell'Esperimento 1), i quali concordano tutti sul fatto che Vicuna-33B ha prestazioni peggiori rispetto a GPT-3.5.
Abbiamo esaminato più da vicino il set di dati di benchmark proposto dall'articolo e abbiamo scoperto che le 3 categorie di attività (scrittura, matematica, conoscenza) non riflettono né contribuiscono direttamente alla capacità del modello di sintetizzare una risposta sulla base di un contesto. Invece, intuitivamente, i casi d'uso di Q&A su documenti richiedono benchmark sulla comprensione del testo e sul seguire le istruzioni. Pertanto, i risultati della valutazione non possono essere trasferiti tra i casi d'uso e dobbiamo creare benchmark specifici per i casi d'uso al fine di valutare correttamente in che misura un modello sia in grado di soddisfare le esigenze dei clienti.
Utilizza MLflow per sfruttare le nostre best practice
Con gli esperimenti di cui sopra, abbiamo esplorato come diversi fattori possano influire in modo significativo sulla valutazione di un chatbot e abbiamo confermato che un LLM come giudice può rispecchiare in gran parte le preferenze umane per il caso d'uso di Q&A sui documenti. In Databricks, stiamo evolvendo l'API di valutazione di MLflow per aiutare il tuo team a valutare in modo efficace le tue applicazioni LLM sulla base di questi risultati. MLflow 2.4 ha introdotto l'API di valutazione per LLM per confrontare fianco a fianco l'output di testo di vari modelli, MLflow 2.6 ha introdotto metriche di valutazione basate su LLM come tossicità e perplessità e stiamo lavorando per supportare LLM-as-a-judge nel prossimo futuro!
Nel frattempo, abbiamo compilato di seguito l'elenco delle risorse a cui abbiamo fatto riferimento nella nostra ricerca:
- Repository Doc_qa
- Il codice e i dati che abbiamo utilizzato per condurre gli esperimenti
- Articolo di ricerca LLM-as-Judge del gruppo lmsys
- L'articolo è la prima ricerca sull'uso dell'LLM come giudice per i casi d'uso di chat informali; ha esplorato a fondo la fattibilità e i pro e i contro dell'uso di LLM (GPT-4, ClaudeV1, GPT-3.5) come giudice per compiti di scrittura, matematica e conoscenza del mondo.
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.