Integrazione di dati multimodali: Architetture di produzione per l'AI sanitaria
La maggior parte degli sforzi di AI multimodale in ambito sanitario si blocca prima della produzione. Ecco un progetto pratico per unificare genomica, imaging, note cliniche e dispositivi indossabili con governance, pipeline e strategie di fusione che...
- Costruire una base multimodale governata: Inserire dati genomici, caratteristiche di imaging, entità da note cliniche e flussi da dispositivi indossabili in Delta Lake con controlli di accesso, audit, lineage e tag governati di Unity Catalog.
- Scegliere una fusione che resista alla realtà della produzione: Utilizzare la fusione precoce/intermedia/tardiva/basata sull'attenzione in base alla disponibilità della modalità, alla dimensionalità e al tempo, progettata per modalità mancanti, non per coorti perfette.
- Rendere operativo end-to-end: Utilizzare Lakeflow SDP per lo streaming + finestre di funzionalità, la ricerca vettoriale per similarità/raggruppamento in coorti e pipeline riproducibili (controllo versione/time travel + CI/CD + MLflow) per passare dal POC alla produzione.
I casi d'uso di IA più preziosi nel settore sanitario raramente risiedono in un unico set di dati. L'integrazione di dati multimodali – che combina genomica, imaging, note cliniche e dispositivi indossabili – è essenziale per l'oncologia di precisione e la diagnosi precoce, eppure molte iniziative si bloccano prima della produzione.
L'oncologia di precisione richiede la comprensione sia dei fattori molecolari derivanti dalla profilazione genomica sia del contesto anatomico derivante dall'imaging. La diagnosi precoce migliora quando i segnali di rischio ereditari incontrano i dati longitudinali dei dispositivi indossabili. E molti dei dettagli sul “perché” – sintomi, risposta, motivazioni – risiedono ancora nelle note cliniche.
Nonostante i reali progressi nella ricerca, molte iniziative multimodali si bloccano prima della produzione – non perché la modellazione sia impossibile, ma perché i dati e il modello operativo non sono pronti per la realtà clinica. Il limite non è la sofisticazione del modello, ma l'architettura: stack separati per modalità creano pipeline fragili, governance duplicata e costosi movimenti di dati che si interrompono sotto le esigenze di implementazione clinica.
Questo post delinea un modello lakehouse orientato alla produzione per la medicina di precisione multimodale: come far confluire ogni modalità in tabelle Delta governate, creare funzionalità cross-modali e scegliere strategie di fusione che resistano alla realtà dei dati mancanti.
Architettura di riferimento
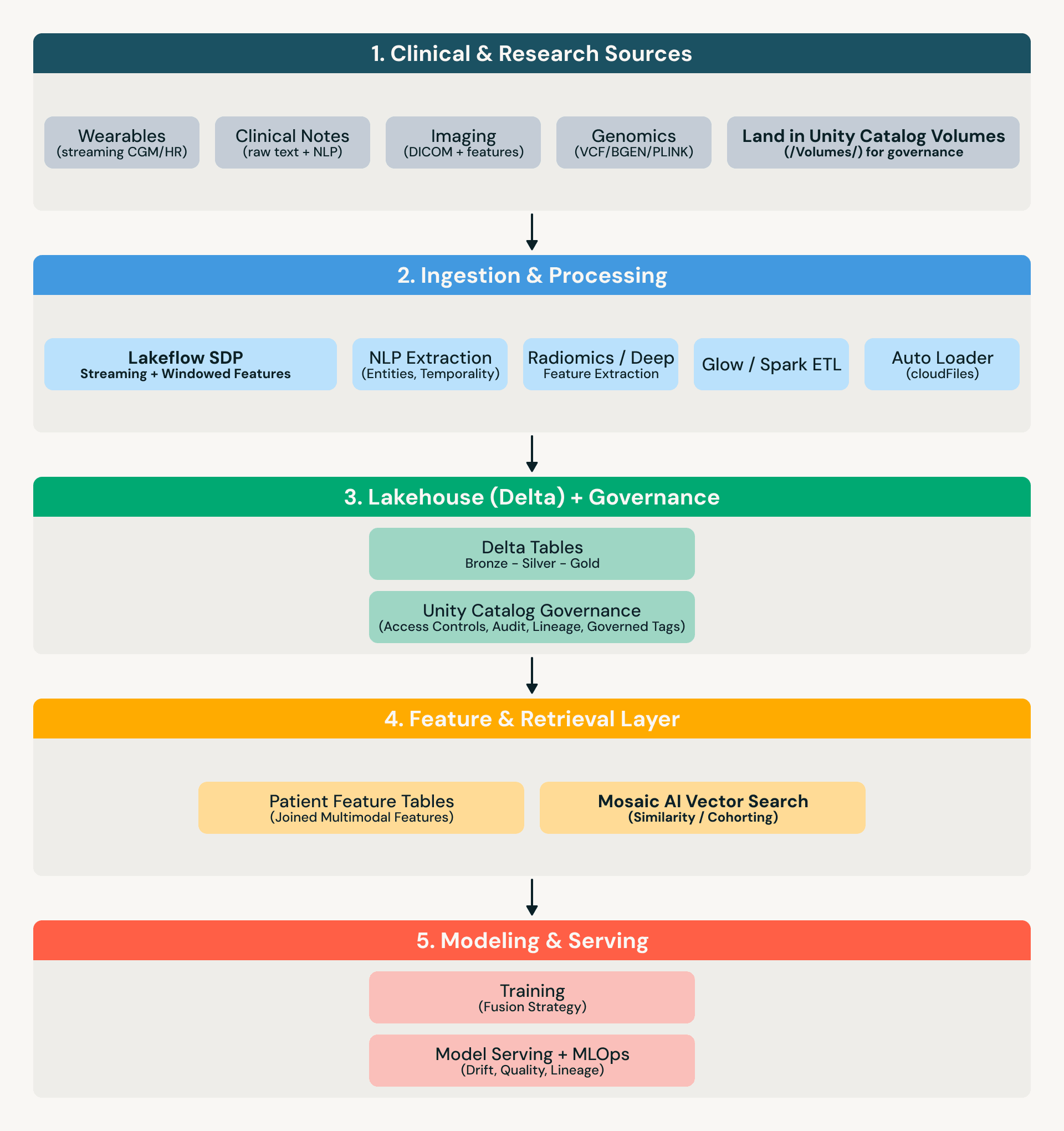
Cosa significa “governato” nella pratica
In questo post, “tabelle governate” significa che i dati sono protetti e operazionalizzati utilizzando Unity Catalog (o controlli equivalenti), inclusi:
Classificazione dei dati con tag governati: PHI/PII/28 CFR Parte 202/StudyID/…
- Controlli di accesso granulari: permessi di catalogo/schema/tabella/volume, più controlli a livello di riga/colonna dove necessario per PHI.
- Tracciabilità: chi ha avuto accesso a cosa, quando (critico per ambienti regolamentati).
- Lignaggio: tracciare le funzionalità e gli input del modello fino ai dataset di origine.
- Condivisione controllata: confini di policy coerenti tra team e strumenti.
Riproducibilità: versioning e time travel per i dataset, CI/CD per pipeline/job e MLflow per il tracciamento delle versioni di esperimenti e modelli.
Questo collega l'architettura tecnica ai risultati di business: meno copie di dati sensibili, analisi riproducibili e approvazioni più rapide per la messa in produzione.
Perché il multimodale sta diventando la norma
I modelli a singola modalità incontrano limiti reali in contesti clinici complessi. L'imaging può essere potente, ma molte previsioni complesse beneficiano del contesto molecolare + longitudinale. La genomica cattura i fattori scatenanti, ma non il fenotipo, l'ambiente o la fisiologia quotidiana. Note e dispositivi indossabili aggiungono i segnali “tra le righe” che i dati strutturati spesso non colgono.
La realtà del volume conta: Databricks rileva che circa l'80% dei dati medici è non strutturato (ad esempio, testo e immagini). Ecco perché l'integrazione di dati multimodali deve gestire note non strutturate e imaging su larga scala, non solo campi EHR strutturati.
Il punto chiave pratico: ogni modalità è incompleta da sola. I sistemi multimodali funzionano quando sono progettati per:
- Preservare il segnale specifico della modalità.
- Mantenere la robustezza quando alcuni input sono mancanti.
Quattro strategie di fusione (e quando ciascuna sopravvive alla produzione)
La scelta della fusione è raramente l'unica ragione del fallimento dei team, ma spesso spiega perché i progetti pilota non si traducono in produzione: i dati sono scarsi, le modalità arrivano in tempi diversi e i requisiti di governance differiscono per tipo di dato.
1) Fusione precoce (Concatenare gli input grezzi prima dell'addestramento.)
- Utilizzare quando: coorti piccole e strettamente controllate con disponibilità di modalità coerente.
- Compromesso: si adatta male a genomica ad alta dimensionalità e a grandi set di funzionalità.
2) Fusione intermedia (Codificare ogni modalità separatamente, quindi unire le rappresentazioni nascoste.)
- Utilizzare quando: si combinano omiche ad alta dimensionalità con funzionalità EHR/cliniche a bassa dimensionalità.
- Compromesso: richiede un attento apprendimento della rappresentazione per modalità e una valutazione disciplinata.
3) Fusione tardiva (Addestrare modelli per modalità, quindi combinare le previsioni.)
- Utilizzare quando: implementazioni in produzione in cui le modalità mancanti sono comuni.
- Beneficio: degrada elegantemente quando una o più modalità sono assenti.
4) Fusione basata sull'attenzione (Apprendere la ponderazione dinamica tra modalità e tempo.)
- Utilizzare quando: il tempo è importante (dispositivi indossabili + note longitudinali, imaging ripetuto) e le interazioni sono complesse.
- Compromesso: più difficile da validare; richiede controlli attenti per evitare correlazioni spurie.
Framework decisionale: abbinare la fusione alla realtà della vostra implementazione: modelli di disponibilità delle modalità, equilibrio della dimensionalità e dinamiche temporali.
Il lakehouse come substrato multimodale
Un approccio lakehouse riduce il movimento dei dati tra le modalità: tabelle genomiche, metadati/funzionalità di imaging, entità derivate dal testo e dispositivi indossabili in streaming possono essere governati e interrogati in un unico luogo, senza dover ricostruire le pipeline per ogni team.
Elaborazione genomica (Glow + Delta)
Glow abilita l'elaborazione genomica distribuita su Spark su formati comuni (ad esempio, VCF/BGEN/PLINK), con output derivati archiviati come tabelle Delta che possono essere unite a funzionalità cliniche.
Somiglianza di imaging (funzionalità derivate + ricerca vettoriale)
Per l'imaging, il modello è: (1) derivare funzionalità/embedding a monte (radiomica o output di modelli profondi), (2) archiviare le funzionalità come tabelle Delta governate (protette tramite Unity Catalog) e (3) utilizzare la ricerca vettoriale per query di somiglianza (ad esempio, “trovare fenotipi simili all'interno del glioblastoma”).
Ciò consente la scoperta di coorti e confronti retrospettivi senza esportare i dati in sistemi separati.
Note cliniche (NLP a funzionalità governate)
Le note spesso contengono contesto mancante: tempistiche, sintomi, risposta, motivazioni. Un approccio pratico consiste nell'estrarre entità + temporalità in tabelle (cambiamenti di farmaci, sintomi, procedure, anamnesi familiare, tempistiche), mantenere il testo grezzo sotto stretta governance (Unity Catalog + controlli di accesso) e unire le funzionalità derivate dalle note all'imaging e all'omica per la modellazione e la creazione di coorti.
Dati da dispositivi indossabili (Lakeflow SDP per streaming + finestre di funzionalità)
I flussi di dati da dispositivi indossabili introducono requisiti operativi: evoluzione dello schema, eventi in arrivo in ritardo e aggregazione continua. Lakeflow Spark Declarative Pipelines (SDP) fornisce un robusto modello di ingestione-a-funzionalità per tabelle in streaming e viste materializzate. Per chiarezza, di seguito ci riferiamo ad esso come Lakeflow SDP.
Nota sulla sintassi: il modulo pyspark.pipelines (importato come dp) con i decoratori @dp.table e @dp.materialized_view segue la semantica Python attuale di Databricks Lakeflow SDP.
Perché il modello unificato di storage + governance è importante
Il vantaggio operativo è la coerenza:
Una modalità di fallimento comune nelle implementazioni cloud è l'approccio “store specializzato per modalità” (ad esempio: un FHIR store, un omics store separato, un imaging store separato e un feature o vector store separato). In pratica, ciò significa spesso governance duplicata e pipeline tra store fragili, rendendo il lignaggio, la riproducibilità e le unioni multimodali molto più difficili da operazionalizzare.
- Riproducibilità: ACID + time travel per set di addestramento coerenti e rianalisi.
- Tracciabilità: log di accesso + lineage (quali dati hanno prodotto quali feature/modelli).
- Sicurezza: confini di policy coerenti tra le modalità (PHI-safe-by-design).
- Velocità: meno passaggi di consegne e meno copie di dati tra i team.
Questo è ciò che trasforma un prototipo multimodale in qualcosa che puoi eseguire, monitorare e difendere in produzione.
Risolvere il problema della modalità mancante
Le implementazioni reali si confrontano con dati incompleti. Non tutti i pazienti ricevono un profilo genomico completo. Gli studi di imaging potrebbero non essere disponibili. I dispositivi indossabili esistono solo per le popolazioni arruolate. La mancanza di dati non è un caso limite, è la norma.
I progetti di produzione dovrebbero prevedere la scarsità di dati e pianificarla:
- Mascheramento delle modalità durante l'addestramento: rimuovere gli input durante lo sviluppo per simulare la realtà dell'implementazione.
- Attenzione sparsa / modelli consapevoli delle modalità: imparare a usare ciò che è disponibile senza fare eccessivo affidamento su una singola modalità.
- Strategie di transfer learning: addestrare su coorti più ricche e adattarsi a popolazioni cliniche sparse con un'attenta validazione.
Intuizione chiave: le architetture che presuppongono dati completi tendono a fallire in produzione. Le architetture progettate per la scarsità di dati generalizzano.
Modello di oncologia di precisione: dall'architettura al flusso di lavoro clinico
Un modello pratico di oncologia di precisione si presenta così:
- Profilazione genomica -> tabelle molecolari governate (Unity Catalog). Archiviare varianti, biomarcatori e annotazioni come tabelle interrogabili con lineage e accesso controllato.
- Feature derivate dall'imaging -> similarità + raggruppamento in coorti. Indicizzare i vettori di feature di imaging per “trovare casi simili” e correlazioni fenotipo-genotipo.
- Timeline derivate dalle note -> idoneità + contesto. Estrarre entità temporalmente consapevoli per supportare lo screening degli studi clinici e una comprensione longitudinale coerente.
- Livello di supporto per il tumor board (human-in-the-loop). Combinare prove multimodali in una vista di revisione coerente con la provenienza. L'obiettivo non è automatizzare le decisioni, ma ridurre il tempo del ciclo e migliorare la coerenza nella raccolta delle prove.
Impatto sul business: cosa cambia quando il multimodale diventa operativo
La crescita del mercato è una delle ragioni per cui questo è importante, ma il motore immediato è operativo:
- Assemblaggio e rianalisi più rapidi delle coorti quando arrivano nuove modalità.
- Meno copie di dati e meno pipeline una tantum.
- Cicli di iterazione più brevi (settimane vs. mesi) per i flussi di lavoro traslazionali.
L'analisi di similarità dei pazienti può anche abilitare un ragionamento pratico “N-of-1” identificando corrispondenze storiche con profili multimodali simili, particolarmente prezioso nelle malattie rare e nelle popolazioni oncologiche eterogenee.
Per iniziare: i primi 30 giorni pragmatici
- Scegli una decisione clinica (ad es. abbinamento a studi clinici, stratificazione del rischio) e definisci le metriche di successo.
- Inventaria le modalità + i dati mancanti (chi ha la genomica? l'imaging? i dispositivi indossabili longitudinali?).
- Configura tabelle bronze/silver/gold governate e protette tramite Unity Catalog.
- Scegli una baseline di fusione che tolleri la mancanza di dati (la fusione tardiva è spesso un buon punto di partenza).
- Rendi operativo: lineage, controlli di qualità dei dati, monitoraggio del drift, set di addestramento riproducibili.
- Pianifica la validazione: coorti di valutazione, controlli di bias, checkpoint del flusso di lavoro del clinico.
Parole chiave: AI multimodale, medicina di precisione, elaborazione genomica, AI per l'imaging medico, integrazione dei dati sanitari, strategie di fusione, architettura lakehouse
Alta priorità
Unity Catalog: https://www.databricks.com/product/unity-catalog
Sanità e Scienze della Vita: https://www.databricks.com/solutions/industries/healthcare-and-life-sciences
Piattaforma di Data Intelligence per la Sanità e le Scienze della Vita: https://www.databricks.com/resources/guide/data-intelligence-platform-for-healthcare-and-life-sciences
Media priorità
Documentazione di Databricks AI Search: https://docs.databricks.com/en/generative-ai/vector-search.html
Delta Lake su Databricks: https://www.databricks.com/product/delta-lake-on-databricks
Data Lakehouse (glossario): https://www.databricks.com/glossary/data-lakehouse
Altri blog correlati
Unisci i dati dei tuoi pazienti con RAG multimodale: https://www.databricks.com/blog/unite-your-patients-data-multi-modal-rag
Trasformare la gestione dei dati omici sulla Databricks Data Intelligence Platform: https://www.databricks.com/blog/transforming-omics-data-management-databricks-data-intelligence-platform
Presentazione di Glow (Genomica): https://www.databricks.com/blog/2019/10/18/introducing-glow-an-open-source-toolkit-for-large-scale-genomic-analysis.html
Elaborazione di immagini DICOM su larga scala con databricks.pixels: https://www.databricks.com/blog/2023/03/16/building-lakehouse-healthcare-and-life-sciences-processing-dicom-images.html
Acceleratori di Soluzioni per la Sanità e le Scienze della Vita: https://www.databricks.com/solutions/accelerators
Pronto a portare l'AI multimodale per la sanità dai progetti pilota alla produzione? Esplora le risorse Databricks per le architetture HLS, la governance con Unity Catalog e i modelli di implementazione end-to-end.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.