Rendere Unity Catalog open source
Creazione del catalogo universale del settore per dati e AI
di Matei Zaharia, Ali Ghodsi, Reynold Xin, Arsalan Tavakoli-Shiraji e Patrick Wendell
Siamo entusiasti di annunciare che stiamo rilasciando Unity Catalog come open source, il primo catalogo open source del settore per la governance dei dati e dell'IA tra cloud, formati di dati e piattaforme dati. Ecco i pilastri più importanti della visione di Unity Catalog:
- API e implementazione open source: È basato sulla specifica OpenAPI e su un'implementazione server open source con licenza Apache 2.0. È inoltre compatibile con l'API metastore di Apache Hive e l'API REST catalog di Apache Iceberg.
- Supporto multi-formato: È estensibile e supporta Delta Lake, Apache Iceberg tramite UniForm, Apache Parquet, CSV e tutti i formati esistenti.
- Supporto multi-engine: Con le sue API aperte, i dati catalogati in Unity possono essere letti da quasi tutti i motori di calcolo.
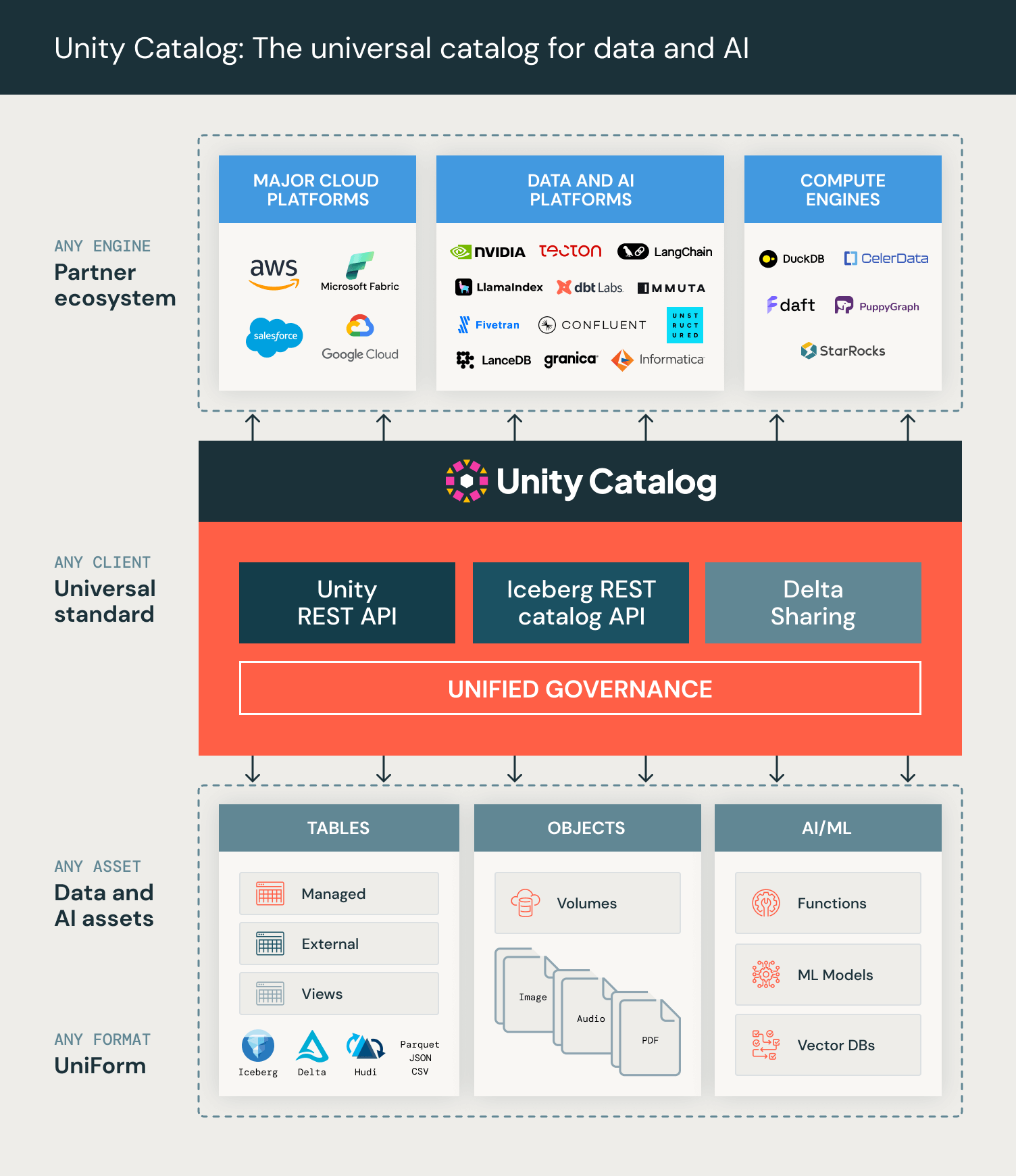
- Multimodale: Supporta tutti i tuoi asset di dati e IA, inclusi tabelle, file, funzioni, modelli di IA.
- Ecosistema vivace: Questo è uno sforzo comunitario e siamo estremamente entusiasti di essere supportati da Amazon Web Services, Microsoft Azure, Google Cloud, Nvidia, Salesforce, DuckDB, LangChain, dbt Labs, Fivetran, Confluent, Unstructured, Onehouse, Immuta, Informatica e molti altri.
Il progetto è disponibile su GitHub oggi come primo passo nel nostro percorso verso la trasformazione della visione di Unity in open source. Unity Catalog è ospitato presso LF AI & Data, una fondazione ombrello della Linux Foundation che supporta l'innovazione open source nell'intelligenza artificiale (IA) e nei dati, dove siamo entusiasti di collaborare con le community open source negli anni a venire per realizzare questa visione.
Perché open source?
Con la diffusa adozione di Unity Catalog, potresti chiederti perché lo stiamo rilasciando come open source e perché proprio ora. È perché abbiamo costantemente sentito dalle organizzazioni che necessitano di una base aperta per le loro applicazioni di dati e IA, non solo per oggi, ma per le innovazioni dei prossimi decenni.
Purtroppo, la maggior parte delle piattaforme dati odierne sono giardini recintati. Molti data warehouse cloud utilizzano "tabelle native" che non sono in formati aperti. Altre piattaforme richiedono ai clienti di pagare per un calcolo sempre attivo anche quando leggono dati da motori esterni. E molte piattaforme limitano i formati di dati e i client supportati.
Ciò si traduce in dati isolati e governance frammentata tra gli asset. E senza un'interfaccia multimodale tra dati tabulari, per non parlare degli asset di IA, le organizzazioni devono unire più soluzioni disgiunte. Databricks ha già preso una forte posizione nel settore essendo l'unica piattaforma principale in cui tutte le tabelle sono in formati aperti per impostazione predefinita, e aprendo le tabelle Delta ai client Iceberg con UniForm l'anno scorso. Rilasciando Unity Catalog come open source, stiamo fornendo alle organizzazioni una base aperta per i loro carichi di lavoro attuali e futuri.
Perché un catalogo dati e IA multimodale?
In questa era di rapidi progressi nell'IA, ogni azienda ha capito che dovrà governare insieme dati e asset di IA, sia che si tratti di gestire dati non strutturati per sistemi di IA complessi, sia che si tratti di creare un catalogo di strumenti per applicazioni LLM agentive. In Databricks, abbiamo visto presto questa esigenza di un'infrastruttura dati e IA integrata e abbiamo lanciato Unity Catalog tre anni fa per unire questi due mondi in un modello di governance coerente. Oggi, vediamo migliaia di clienti sfruttare la governance unificata, tra cui:
- Un singolo namespace per organizzare e condividere tabelle, dati non strutturati e asset di IA
- Log di audit centralizzati di tutte le attività di dati e IA
- Lineage unificato tra carichi di lavoro di dati e IA
- Collaborazione inter-organizzazione tramite il protocollo open source Delta Sharing.
I nostri ultimi lanci nell'IA, come il concetto di Tool Catalog per agenti di IA generativa, sono progettati anche per adattarsi a questo modello di governance unificata.
Rilascio 0.1 di Unity Catalog
Oggi rilasciamo la versione 0.1 di Unity Catalog open source. Sebbene alcune delle nostre API e funzionalità siano ancora in evoluzione, questo rilascio mostra diverse capacità importanti di Unity Catalog:
- Tabelle, Volumi (dati non strutturati) e Strumenti/Funzioni IA possono essere gestiti insieme.
- Le tabelle possono essere in più formati, inclusi Delta Lake, Iceberg tramite UniForm, Parquet, CSV e JSON.
- Unity Catalog implementa l'API REST Catalog di Iceberg per l'accesso dall'ecosistema del motore Iceberg, sfruttando l'esperienza di Tabular.
- L'API supporta la distribuzione di credenziali per controllare l'accesso dei client allo storage cloud sottostante per tabelle e volumi, centralizzando la governance nel server del catalogo.
Cosa significa questo per i clienti Databricks
Se sei già un cliente Databricks, non devi fare nulla di diverso. Le distribuzioni Unity Catalog esistenti dei clienti implementano le stesse API aperte, consentendo ai client esterni di leggere da tutte le tabelle (incluse tabelle gestite ed esterne), volumi e funzioni in Unity Catalog ospitato dal Giorno 1, con i tuoi controlli di accesso esistenti. Questo cambiamento significa semplicemente che un ecosistema più ampio di client funzionerà con il tuo catalogo esistente.
Le API REST di Unity consentono ai nostri partner e alla community open source di creare potenti integrazioni che permetteranno ai clienti di lavorare sulle loro tabelle, dati non strutturati e strumenti/funzioni IA da diverse applicazioni, senza costi di accesso esterni.
"AT&T si impegna a rendere i nostri dati interoperabili con le nostre piattaforme. Con l'annuncio del rilascio open source di Unity Catalog, siamo incoraggiati dal passo di Databricks per rendere possibile la governance del lakehouse e la gestione dei metadati attraverso standard aperti. La flessibilità di utilizzare strumenti interoperabili con i nostri asset di dati e IA, con una governance coerente è fondamentale per la strategia della piattaforma dati di AT&T."
— Matt Dugan, Vice President Data Platforms, AT&T
![]()
"Nasdaq è orgogliosa di sfruttare Unity Catalog di Databricks come parte della nostra strategia olistica di gestione dei dati. La decisione di Databricks di rilasciare Unity Catalog come open source fornisce una soluzione che aiuta a eliminare i silos di dati e non vediamo l'ora di scalare ulteriormente la nostra piattaforma, migliorare la nostra governance e modernizzare le nostre applicazioni dati mentre continuiamo a fornire risultati ai nostri clienti."
— Lenny Rosenfeld, Vice President, Capital Access Platforms, Nasdaq
![]()
"In Rivian, l'adozione della Databricks Platform ci ha dato la capacità di utilizzare dati e IA nella costruzione dei nostri EAV di prossima generazione. Siamo entusiasti del rilascio open source di Unity Catalog da parte di Databricks e del rilascio di API aperte per portare interoperabilità nel nostro panorama dati senza alcuna preoccupazione di vendor lock-in. Combinato con il supporto per tutti i nostri asset di dati — dati strutturati e non strutturati, modelli ML e strumenti Gen AI — è stata una decisione facile standardizzare su Unity Catalog."
— Jason Shiverick, Director of AI Platforms, Rivian
![]()
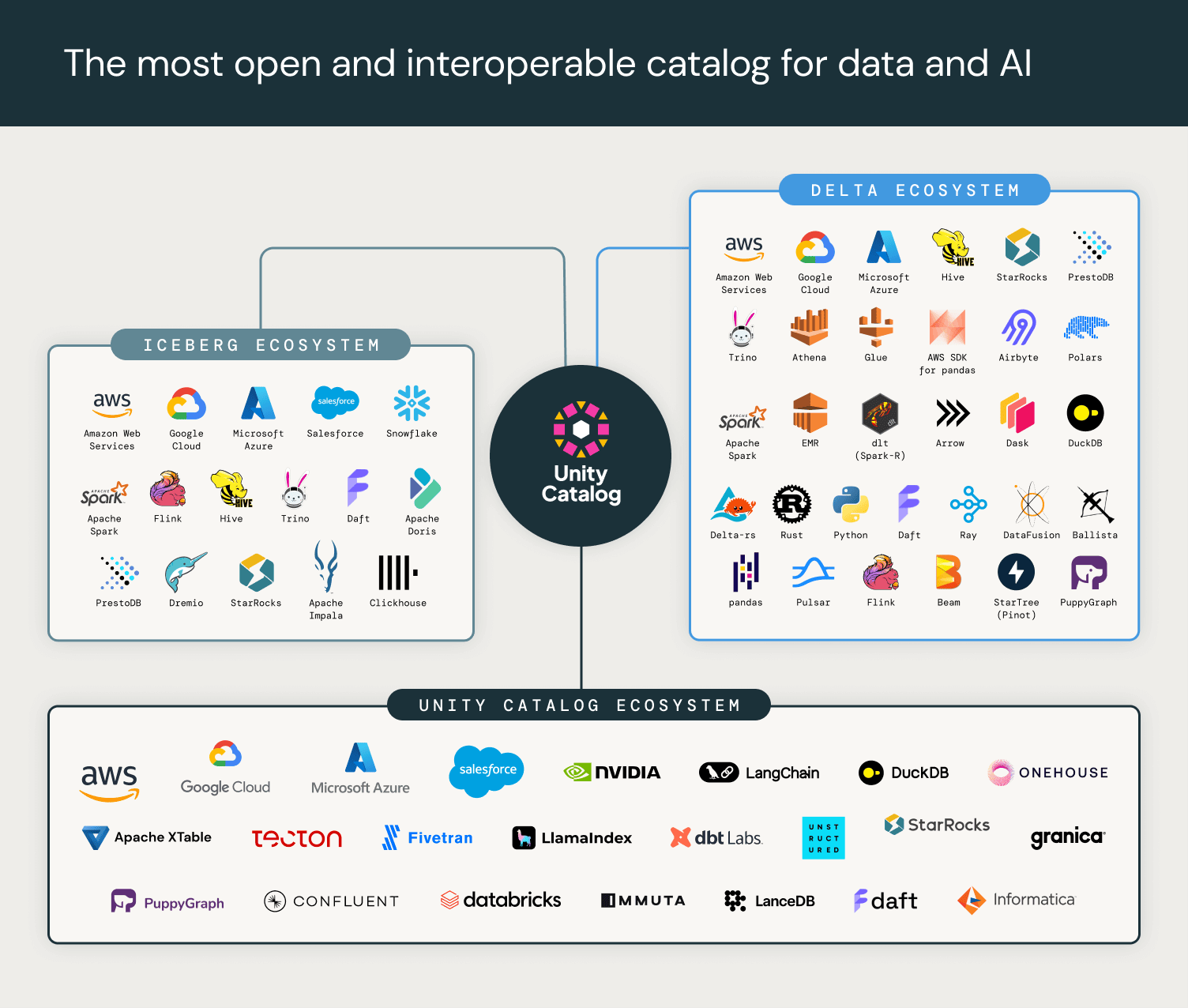
Ecosistema Open Source
Siamo entusiasti di collaborare con i principali provider cloud, piattaforme dati e IA, e motori di calcolo per promuovere lo standard Unity Catalog nei prossimi mesi. Includono i principali fornitori di software e progetti open source in IA, analisi dati, dati non strutturati e governance, che saranno in grado di connettersi facilmente ai server open source di Unity Catalog e a Databricks.
"AWS accoglie con favore la mossa di Databricks di rilasciare Unity Catalog come open source. AWS si impegna a collaborare con il settore su soluzioni open source che consentano ai clienti scelta e interoperabilità."
— Chris Grusz, Managing Director of Technology Partnerships, AWS
![]()
"Microsoft è impegnata nella community open-source e nell'offrire ai clienti la possibilità di scegliere. Databricks è un partner strategico da anni ed è fantastico vedere che stanno rilasciando Unity Catalog come open source. Crediamo che standard veramente aperti con un'ampia partecipazione del settore siano nel migliore interesse dei clienti. La nostra collaborazione con Databricks continua a elevare Microsoft Azure come la scelta migliore per i carichi di lavoro di dati e IA."
— Jessica Hawk, CVP Data, AI and Digital Applications, Microsoft
![]()
"Google è impegnata in soluzioni aperte e flessibili che consentono ai clienti di massimizzare il valore dei propri dati. La strategia di Databricks di aprire lo standard Unity Catalog per dati e IA si allinea molto bene con la nostra strategia."
— Ritika Suri, Director, Data and AI Technology Partnerships, Google Cloud
![]()
Roadmap futura
Questo è solo il punto di partenza per il progetto open source Unity Catalog. Unity Catalog serve migliaia di clienti in produzione ed è il risultato di anni di ingegneria, quindi stiamo portando questa funzionalità nel progetto open source in fasi, dando priorità all'accesso e all'interoperabilità dei client per iniziare.
Nei prossimi mesi, aggiungeremo un supporto avanzato per le API critiche per i tuoi carichi di lavoro di dati e AI, tra cui:
- API di scrittura di tabelle indipendenti dal formato
- Viste
- Delta Sharing
- Modelli (con integrazione MLflow)
- Funzioni remote
- API di controllo degli accessi
- E altro ancora
Inizia oggi stesso
Puoi unirti alla community open source di Unity Catalog su unitycatalog.io. Per i clienti Databricks, resta sintonizzato per il rapido avanzamento dell'ecosistema di strumenti per dati e AI che si integrano con Unity Catalog.
"Salesforce Data Cloud è costruito da zero su standard aperti con Apache Parquet e Apache Iceberg. Le nostre innovazioni a copia zero consentono ai clienti di sbloccare dati, ottenere insight e orchestrare azioni su tutto il Customer 360. L'adozione di Apache Iceberg da parte di Databricks tramite UniForm e Unity Catalog affronta le principali sfide di interoperabilità tra Delta Lake e Iceberg. Siamo entusiasti di avere Databricks come membro della nostra Zero Copy Partner Network e attendiamo con impazienza innovazioni congiunte con il nuovo Unity Catalog open, offrendo un valore convincente ai clienti in dati strutturati, dati non strutturati e modelli AI."
— Ravi Loganathan, Vicepresidente esecutivo di ingegneria del software, Salesforce
![]()
"I dati aziendali sono essenziali per lo sviluppo di accurate applicazioni generative AI. NVIDIA lavora a stretto contatto con il nostro ecosistema di partner per supportare offerte open-source come Unity Catalog, che può aiutare i clienti a curare pipeline di sviluppo efficienti e potenti."
— Pat Lee, VP of Strategic Enterprise Partnerships, NVIDIA
![]()
"Delta Kernel ha semplificato notevolmente la creazione dell'estensione DuckDB Delta, consentendo un facile accesso a Delta Lake da DuckDB. Siamo entusiasti di collaborare con Databricks su Delta Kernel e sullo standard aperto Unity Catalog per dati e AI. Questa collaborazione rappresenta un passo avanti significativo nell'innovazione open source e nello sviluppo di data lakehouse aperti."
— Hannes Mühleisen, CEO, DuckDB Labs
![]()
"La decisione di Databricks di rendere open source Unity Catalog è uno sviluppo entusiasmante per la community di dati e AI. Siamo entusiasti di collaborare con Databricks per integrare Unity Catalog con LangChain, che consente ai nostri utenti condivisi di creare agenti avanzati utilizzando le funzioni di Unity Catalog come strumenti."
— Harrison Chase, CEO e fondatore, LangChain
![]()
"Unstructured è la soluzione ETL leader per dati non strutturati per LLM, che aiuta le organizzazioni a trasformare i propri dati da grezzi a pronti per RAG. La nostra integrazione con Unity Catalog ha perfettamente senso, poiché abbattiamo i silos di dati e acceleriamo lo sviluppo AI/ML nelle imprese. Siamo entusiasti di collaborare con Databricks per sviluppare questo standard aperto per casi d'uso AI e per standardizzare i metadati per i dati non strutturati, aiutando i nostri clienti a operare all'avanguardia dell'AI."
— Brian Raymond, CEO e fondatore, UnstructuredIO
![]()
"In Eventual, abbiamo costruito Daft, il motore di query distribuito open source leader per dati multimodali. Crediamo che unificare il calcolo per dati tabulari e non strutturati non sia sufficiente e che un catalogo multimodale sia cruciale per costruire data lakehouse GenAI. Siamo entusiasti di collaborare con Databricks e altri innovatori AI per sviluppare lo standard aperto Unity Catalog per i moderni carichi di lavoro data+AI."
— Sammy Sidhu, CEO e fondatore, Eventual Computing
![]()
"In Granica, promuoviamo la democratizzazione dei dati e la libertà dal vendor lock-in. La nostra tecnologia Safe Room garantisce privacy, fiducia e sicurezza nei flussi di lavoro di AI generativa, supportando al contempo standard aperti come Unity Catalog, Delta Lake e Apache Iceberg. L'architettura neutrale rispetto al fornitore di Unity Catalog e le robuste soluzioni di governance si allineano alla nostra visione di fornire ai clienti flessibilità e controllo sui propri dati. Siamo entusiasti di contribuire a questo ecosistema aperto, promuovendo l'innovazione e consentendo ai clienti di lavorare senza problemi con i propri dati su piattaforme best-of-breed."
— Rahul Ponnala, CEO e Co-fondatore, Granica
![]()
"Aprire Unity Catalog è un passo fondamentale verso un ecosistema di dati più collaborativo e innovativo. Rendendo questa tecnologia accessibile, Databricks sta promuovendo un ambiente in cui l'intera community può contribuire e beneficiare di capacità migliorate di governance e gestione dei dati. Questa mossa si allinea alla nostra visione in Onehouse e Apache XTable (Incubating) di supportare l'interoperabilità dei formati aperti che guida il progresso e l'innovazione per tutti."
— Vinoth Chandar, CEO e Co-fondatore, Onehouse
![]()
"La missione di Confluent è mettere i dati in movimento e consentire alle organizzazioni di sfruttare i propri dati ovunque. Siamo entusiasti di vedere Databricks dare un contributo significativo a un ecosistema di dati aperto con Unity Catalog reso open source. Tableflow su Confluent Cloud consentirà una facile consegna di dati in tempo reale in luoghi come un data lake trasformando i flussi di dati in tabelle Iceberg con un clic. Combinando le nostre capacità di streaming leader del settore con le robuste soluzioni di gestione dei dati di Databricks, i clienti saranno in grado di sfruttare i propri dati in modo più efficace che mai."
— Shaun Clowes, CPO, Confluent
![]()
"Insieme, Databricks e dbt Cloud aiutano gli utenti a rompere i silos di dati per collaborare efficacemente, semplificare l'ETL per ridurre il TCO con Delta Lake e unificare la governance con Unity Catalog. Siamo entusiasti di annunciare il nostro supporto per Unity Catalog e le API aperte. Questa partnership sottolinea il nostro impegno a fornire un'esperienza dati unificata, consentendo alla nostra community di ottenere maggiori insight e promuovere l'innovazione."
— Mark Porter, CTO dbt Labs
![]()
"Siamo entusiasti di vedere Databricks rendere open source Unity Catalog come standard aperto per dati e AI. Questa mossa offrirà ai nostri clienti maggiore scelta e flessibilità nel loro ecosistema di dati, garantendo un'integrazione senza interruzioni e massimizzando l'interoperabilità con la piattaforma Fivetran mentre ingeriscono dati critici in Databricks."
— Anjan Kundavaram, CPO, Fivetran
![]()
"L'esposizione di pattern di accesso nativi all'interno di Unity Catalog ha trasformato il modo in cui la nostra azienda è in grado di semplificare l'accesso ai dati e applicare regole di governance su larga scala, senza impatti sulle prestazioni. Il continuo investimento di Databricks in una community per accelerare i servizi volti a semplificare la creazione di controlli sui dati consente ai nostri clienti di governare con maggiore facilità e gestire l'enorme volume di nuovi consumatori di dati che vengono integrati nell'era dell'AI."
— Matthew Carroll, CEO, Immuta
![]()
"Siamo entusiasti di vedere l'opportunità per i nostri clienti congiunti poiché Databricks rende open source Unity Catalog come standard aperto per dati e AI. Con Unity Catalog e l'Informatica Intelligent Data Management Cloud, i clienti possono ottenere maggiore scelta, flessibilità e interoperabilità nei loro ecosistemi di dati."
— Brett Roscoe, GM e SVP Cloud Data Governance e Cloud Operations, Informatica
![]()
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.