I vincoli Primary Key e Foreign Key sono GA e ora abilitano query più veloci
Databricks è entusiasta di annunciare la disponibilità generale (GA) dei vincoli di Primary Key (PK) e Foreign Key (FK), a partire da Databricks Runtime 15.2 e Databricks SQL 2024.30. Questa release segue un'anteprima pubblica di grande successo, adottata da centinaia di clienti attivi settimanalmente, e rappresenta un'ulteriore pietra miliare significativa nel migliorare l'integrità dei dati e la gestione dei dati relazionali all'interno del Lakehouse.
Inoltre, Databricks può ora utilizzare questi vincoli per ottimizzare le query ed eliminare operazioni non necessarie dal piano di query, offrendo prestazioni molto più rapide.
Vincoli di Primary Key e Foreign Key
Le Primary Key (PK) e le Foreign Key (FK) sono elementi essenziali nei database relazionali, fungendo da blocchi fondamentali per la modellazione dei dati. Forniscono informazioni sulle relazioni dei dati nello schema a utenti, strumenti e applicazioni; e abilitano ottimizzazioni che sfruttano i vincoli per velocizzare le query. Le chiavi primarie e le chiavi esterne sono ora generalmente disponibili per le tue tabelle Delta Lake ospitate in Unity Catalog.
Linguaggio SQL
Puoi definire i vincoli quando crei una tabella:
Nell'esempio sopra, definiamo un vincolo di chiave primaria sulla colonna UserID. Databricks supporta anche vincoli su gruppi di colonne.
Puoi anche modificare le tabelle Delta esistenti per aggiungere o rimuovere vincoli:
Qui creiamo la chiave primaria denominata products_pk sulla colonna non nulla ProductID in una tabella esistente. Per eseguire correttamente questa operazione, devi essere il proprietario della tabella. Nota che i nomi dei vincoli devono essere univoci all'interno dello schema.
Il comando successivo rimuove la chiave primaria specificando il nome.
Lo stesso processo si applica alle chiavi esterne. La seguente tabella definisce due chiavi esterne al momento della creazione della tabella:
Fai riferimento alla documentazione sulle istruzioni CREATE TABLE e ALTER TABLE per maggiori dettagli sulla sintassi e sulle operazioni relative ai vincoli.
I vincoli di chiave primaria e chiave esterna non sono applicati nel motore Databricks, ma possono essere utili per indicare una relazione di integrità dei dati che si intende rispettare. Databricks può invece applicare i vincoli di chiave primaria a monte come parte della pipeline di ingestione. Vedi Gestione della qualità dei dati con Delta Live Tables per maggiori informazioni sui vincoli applicati. Databricks supporta anche vincoli NOT NULL e CHECK applicati (vedi la documentazione sui vincoli per maggiori informazioni).
Ecosistema Partner
Strumenti e applicazioni come le ultime versioni di Tableau e PowerBI possono importare e utilizzare automaticamente le tue relazioni di chiave primaria e chiave esterna da Databricks tramite connettori JDBC e ODBC.
Visualizza i vincoli
Ci sono diversi modi per visualizzare i vincoli di chiave primaria e chiave esterna definiti nella tabella. Puoi anche semplicemente usare comandi SQL per visualizzare le informazioni sui vincoli con il comando DESCRIBE TABLE EXTENDED:
Catalog Explorer e Entity Relationship Diagram
Puoi anche visualizzare le informazioni sui vincoli tramite il Catalog Explorer:
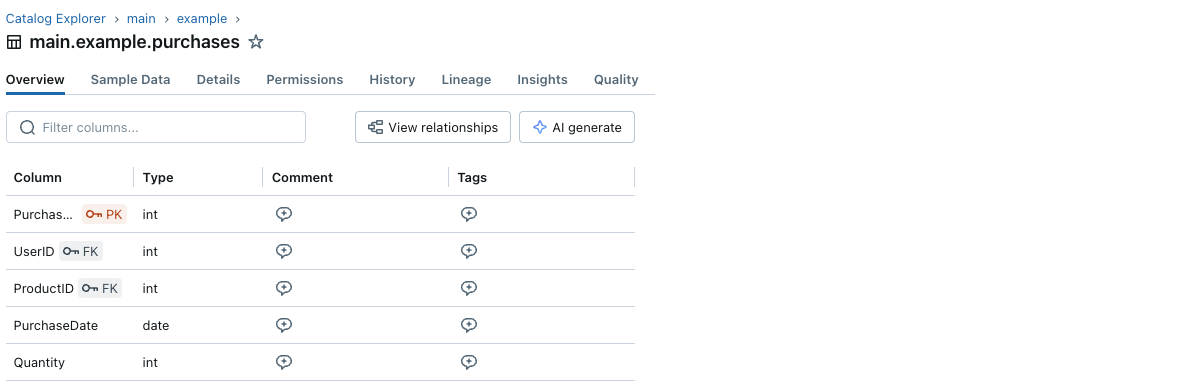
Ogni colonna di chiave primaria e chiave esterna ha una piccola icona a forma di chiave accanto al suo nome.
E puoi visualizzare le informazioni sulle chiavi primarie ed esterne e le relazioni tra le tabelle con l'Entity Relationship Diagram in Catalog Explorer. Di seguito un esempio di una tabella purchases che fa riferimento a due tabelle, users e products:

INFORMATION SCHEMA
Le seguenti tabelle di INFORMATION_SCHEMA forniscono anche informazioni sui vincoli:
TABLE_CONSTRAINTS: Descrive i metadati per tutti i vincoli di chiave primaria ed esterna all'interno del catalogo.KEY_COLUMN_USAGE: Elenca le colonne dei vincoli di chiave primaria o esterna all'interno del catalogo.CONSTRAINT_TABLE_USAGE: Descrive le tabelle di riferimento dei vincoli nel catalogo.CONSTRAINT_COLUMN_USAGE: Descrive le colonne di riferimento dei vincoli nel catalogo.REFERENTIAL_CONSTRAINTS: Descrive i vincoli referenziali (chiave esterna) definiti nel catalogo.
Usa l'opzione RELY per abilitare le ottimizzazioni
Se sai che il vincolo di chiave primaria è valido (ad esempio, perché la tua pipeline di dati o il tuo job ETL lo applicano), puoi abilitare le ottimizzazioni basate sul vincolo specificandolo con l'opzione RELY, come:
L'uso dell'opzione RELY consente a Databricks di ottimizzare le query in modi che dipendono dalla validità del vincolo, poiché garantisci che l'integrità dei dati sia mantenuta. Usa cautela qui perché se un vincolo è contrassegnato come RELY ma i dati violano il vincolo, le tue query potrebbero restituire risultati errati.
Quando non specifichi l'opzione RELY per un vincolo, l'impostazione predefinita è NORELY, nel qual caso i vincoli possono ancora essere utilizzati per scopi informativi o statistici, ma le query non si baseranno su di essi per funzionare correttamente.
L'opzione RELY e le ottimizzazioni che la utilizzano sono attualmente disponibili per le chiavi primarie e saranno presto disponibili anche per le chiavi esterne.
Puoi modificare la chiave primaria di una tabella per cambiare se è RELY o NORELY usando ALTER TABLE, ad esempio:
Accelera le tue query eliminando aggregazioni non necessarie
Una semplice ottimizzazione che possiamo fare con i vincoli di chiave primaria RELY è l'eliminazione di aggregazioni non necessarie. Ad esempio, in una query che applica un'operazione distinct su una tabella con una chiave primaria che utilizza RELY:
Possiamo rimuovere l'operazione DISTINCT non necessaria:
Come puoi vedere, questa query si basa sulla validità del vincolo di chiave primaria RELY - se ci sono ID cliente duplicati nella tabella cliente, la query trasformata restituirà risultati duplicati errati. Sei responsabile dell'applicazione della validità del vincolo se imposti l'opzione RELY.
Se la chiave primaria è NORELY (l'impostazione predefinita), l'ottimizzatore non rimuoverà l'operazione DISTINCT dalla query. In questo modo, potrebbe essere più lenta ma restituisce sempre risultati corretti anche in presenza di duplicati. Se la chiave primaria è RELY, Databricks può rimuovere l'operazione DISTINCT, velocizzando notevolmente la query, circa 2 volte più velocemente nell'esempio precedente.
Accelera le tue query eliminando join non necessari
Un'altra ottimizzazione molto utile che possiamo eseguire con le chiavi primarie RELY è l'eliminazione dei join non necessari. Se una query unisce una tabella che non è referenziata altrove se non nella condizione di join, l'ottimizzatore può determinare che il join non è necessario e rimuoverlo dal piano di query.
Per fare un esempio, supponiamo di avere una query che unisce due tabelle, store_sales e customer, unite sulla chiave primaria della tabella cliente PRIMARY KEY (c_customer_sk) RELY.
Se non avessimo la chiave primaria, ogni riga di store_sales potrebbe potenzialmente corrispondere a più righe in customer, e avremmo bisogno di eseguire il join per calcolare il valore SUM corretto. Ma poiché la tabella customer è unita sulla sua chiave primaria, sappiamo che il join produrrà una riga per ogni riga di store_sales.
Quindi la query ha effettivamente bisogno solo della colonna ss_quantity dalla tabella dei fatti store_sales. Pertanto, l'ottimizzatore di query può eliminare completamente il join dalla query, trasformandola in:
Questo viene eseguito molto più velocemente evitando l'intero join - in questo esempio osserviamo l'ottimizzazione che accelera la query da 1,5 minuti a 6 secondi!. E i vantaggi possono essere ancora maggiori quando il join coinvolge molte tabelle che possono essere eliminate!
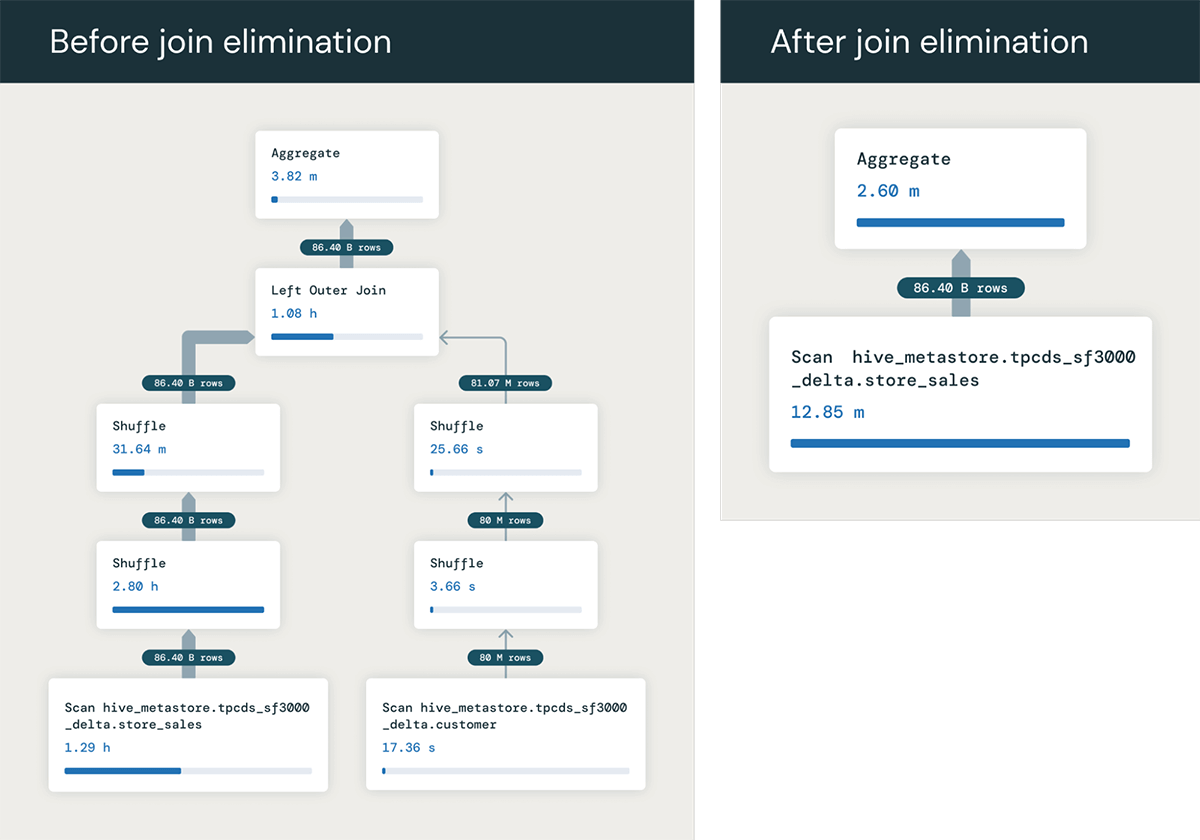
Potresti chiederti perché qualcuno eseguirebbe una query del genere. In realtà è molto più comune di quanto si pensi! Una ragione comune è che gli utenti creano viste che uniscono diverse tabelle, come l'unione di molte tabelle di fatti e dimensioni. Scrivono query su queste viste che spesso utilizzano colonne solo da alcune delle tabelle, non da tutte - e quindi l'ottimizzatore può eliminare i join con le tabelle non necessarie in ogni query. Questo schema è comune anche in molti strumenti di Business Intelligence (BI), che spesso generano query unendo molte tabelle in uno schema anche quando una query utilizza colonne solo da alcune delle tabelle.
Conclusione
Fin dalla sua anteprima pubblica, oltre 2600 clienti Databricks hanno utilizzato i vincoli di chiave primaria e chiave esterna. Oggi, siamo entusiasti di annunciare la disponibilità generale di questa funzionalità, segnando una nuova fase nel nostro impegno per migliorare la gestione e l'integrità dei dati in Databricks.
Inoltre, Databricks sfrutta ora i vincoli di chiave con l'opzione RELY per ottimizzare le query, ad esempio eliminando aggregazioni e join non necessari, con conseguente miglioramento delle prestazioni delle query.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.