Pubblica su più cataloghi e schemi da un'unica pipeline DLT
Semplifica la sintassi, ottimizza i costi e riduci la complessità operativa
- Supporto Multi-Schema e Cataloghi: Pubblica su più schemi e cataloghi da un'unica pipeline DLT.
- Sintassi Semplificata e Costi Ridotti: Elimina la parola chiave LIVE e riduci l'overhead dell'infrastruttura.
- Migliore Osservabilità: Pubblica i log degli eventi su Unity Catalog e gestisci i dati tra diverse posizioni con SQL e Python.
DLT offre una piattaforma robusta per creare pipeline di elaborazione dati affidabili, manutenibili e testabili all'interno di Databricks. Sfruttando il suo framework dichiarativo e il provisioning automatico di risorse di calcolo serverless ottimali, DLT semplifica le complessità dello streaming, della trasformazione e della gestione dei dati, offrendo scalabilità ed efficienza per i moderni flussi di lavoro dei dati.
Siamo entusiasti di annunciare un miglioramento molto atteso: la possibilità di pubblicare tabelle in più schemi e cataloghi all'interno di una singola pipeline DLT. Questa funzionalità riduce la complessità operativa, abbassa i costi e semplifica la gestione dei dati consentendo di consolidare l'architettura medallion (Bronze, Silver, Gold) in un'unica pipeline, mantenendo al contempo le best practice organizzative e di governance.
Con questo miglioramento, puoi:
- Semplificare la sintassi della pipeline – Non è più necessaria la sintassi
LIVEper indicare le dipendenze tra le tabelle. Sono supportati nomi di tabelle completi e parzialmente qualificati, insieme ai comandiUSE SCHEMAeUSE CATALOG, proprio come in SQL standard. - Ridurre la complessità operativa – Elabora e pubblica tutte le tabelle all'interno di una pipeline DLT unificata, eliminando la necessità di pipeline separate per schema o catalogo.
- Abbassare i costi – Minimizza l'overhead dell'infrastruttura consolidando più carichi di lavoro in un'unica pipeline.
- Migliorare l'osservabilità – Pubblica il tuo log degli eventi come tabella standard nel metastore di Unity Catalog per un monitoraggio e una governance migliorati.
“La possibilità di pubblicare su più cataloghi e schemi da un'unica pipeline DLT – e non richiedere più la parola chiave LIVE – ci ha aiutato a standardizzare le best practice delle pipeline, a semplificare i nostri sforzi di sviluppo e a facilitare la transizione dei team da carichi di lavoro non-DLT a DLT come parte della nostra adozione su larga scala dello strumento da parte dell'azienda.” —Ron DeFreitas, Principal Data Engineer, HealthVerity

Come iniziare
Creazione di una pipeline
Tutte le pipeline create dall'interfaccia utente ora supportano per impostazione predefinita più cataloghi e schemi. Puoi impostare un catalogo e uno schema predefiniti a livello di pipeline tramite l'interfaccia utente, l'API o Databricks Asset Bundles (DAB).
Dall'interfaccia utente:
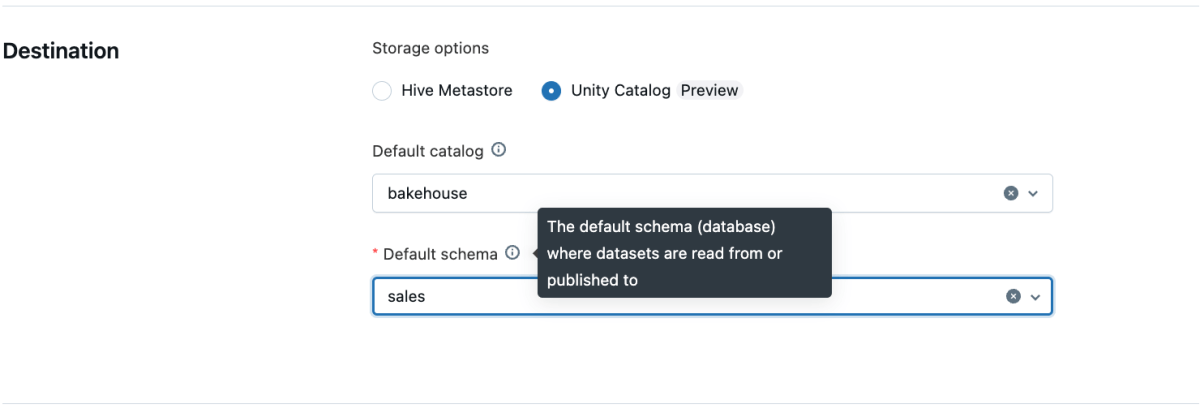
- Crea una nuova pipeline come al solito.
- Imposta il catalogo e lo schema predefiniti nelle impostazioni della pipeline.
Dall'API:
Se stai creando una pipeline a livello di codice, puoi abilitare questa funzionalità specificando il campo schema in PipelineSettings. Questo sostituisce il campo target esistente, garantendo che i dataset possano essere pubblicati su più cataloghi e schemi.
Per creare una pipeline con questa funzionalità tramite API, puoi seguire questo esempio di codice (Nota: l'autenticazione Personal Access Token deve essere abilitata per il workspace):
Impostando il campo schema, la pipeline supporterà automaticamente la pubblicazione di tabelle su più cataloghi e schemi senza richiedere la parola chiave LIVE.
Dal DAB
- Assicurati che la tua Databricks CLI abbia la versione v0.230.0 o superiore. In caso contrario, aggiorna la CLI seguendo la documentazione.
- Configura l'ambiente Databricks Asset Bundle (DAB) seguendo la documentazione. Seguendo questi passaggi, dovresti avere una directory DAB generata dalla Databricks CLI che contiene tutti i file di configurazione e codice sorgente.
- Trova il file YAML che definisce la pipeline DLT sotto:
<tuo dab folder>/<resource>/<pipeline_name>_pipeline.yml - Imposta il campo
schemanel file YAML della pipeline e rimuovi il campotargetse esiste. - Esegui “
databricks bundle validate“ per convalidare che la configurazione DAB sia valida. - Esegui “
databricks bundle deploy -t <environment>“ per distribuire la tua prima pipeline DPM!
“La funzionalità funziona esattamente come ci aspettavamo! Sono stato in grado di suddividere i diversi dataset all'interno di DLT nei nostri schemi stage, core e UDM (fondamentalmente una configurazione bronze, silver, gold) all'interno di un'unica pipeline.” —Florian Duhme, Expert Data Software Developer, Arvato

Pubblicazione di tabelle su più cataloghi e schemi
Una volta configurata la pipeline, puoi definire le tabelle utilizzando nomi completi o parzialmente qualificati sia in SQL che in Python.
Esempio SQL
Esempio Python
Lettura di dataset
Puoi fare riferimento ai dataset utilizzando nomi completi o parzialmente qualificati, con la parola chiave LIVE opzionale per la retrocompatibilità.
Esempio SQL
Esempio Python
Cambiamenti nel comportamento dell'API
Con questa nuova funzionalità, i metodi API chiave sono stati aggiornati per supportare più cataloghi e schemi in modo più fluido:
dlt.read() e dlt.read_stream()
In precedenza, questi metodi potevano fare riferimento solo a dataset definiti all'interno della pipeline corrente. Ora, possono fare riferimento a dataset in più cataloghi e schemi, tracciando automaticamente le dipendenze secondo necessità. Ciò semplifica la creazione di pipeline che integrano dati da diverse posizioni senza configurazioni manuali aggiuntive.
spark.read() e spark.readStream()
In passato, questi metodi richiedevano riferimenti espliciti a dataset esterni, rendendo le query cross-catalog più complicate. Con il nuovo aggiornamento, le dipendenze vengono ora tracciate automaticamente e lo schema LIVE non è più necessario. Ciò semplifica il processo di lettura dei dati da più origini all'interno di una singola pipeline.
Utilizzo di USE CATALOG e USE SCHEMA
La sintassi di Databricks SQL ora supporta l'impostazione dinamica di cataloghi e schemi attivi, semplificando la gestione dei dati in più posizioni.
Esempio SQL
Esempio Python
Gestione dei log degli eventi in Unity Catalog
Questa funzionalità consente inoltre ai proprietari delle pipeline di pubblicare i log degli eventi nel metastore di Unity Catalog per una migliore osservabilità. Per abilitare questa opzione, specificare il campo event_log nel JSON delle impostazioni della pipeline. Ad esempio:
Con questo, ora è possibile emettere GRANTS sulla tabella dei log degli eventi come qualsiasi tabella normale:
È anche possibile creare una vista sulla tabella dei log degli eventi:
Oltre a tutto quanto sopra, è anche possibile eseguire lo streaming dalla tabella dei log degli eventi:
Prossimi passi
Guardando al futuro, questi miglioramenti diventeranno l'impostazione predefinita per tutte le pipeline appena create, sia che vengano create tramite UI, API o Databricks Asset Bundles. Inoltre, uno strumento di migrazione sarà presto disponibile per aiutare a trasferire le pipeline esistenti al nuovo modello di pubblicazione.
Leggi di più nella documentazione qui.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.