Spingere i confini per gli agenti di dati con Genie
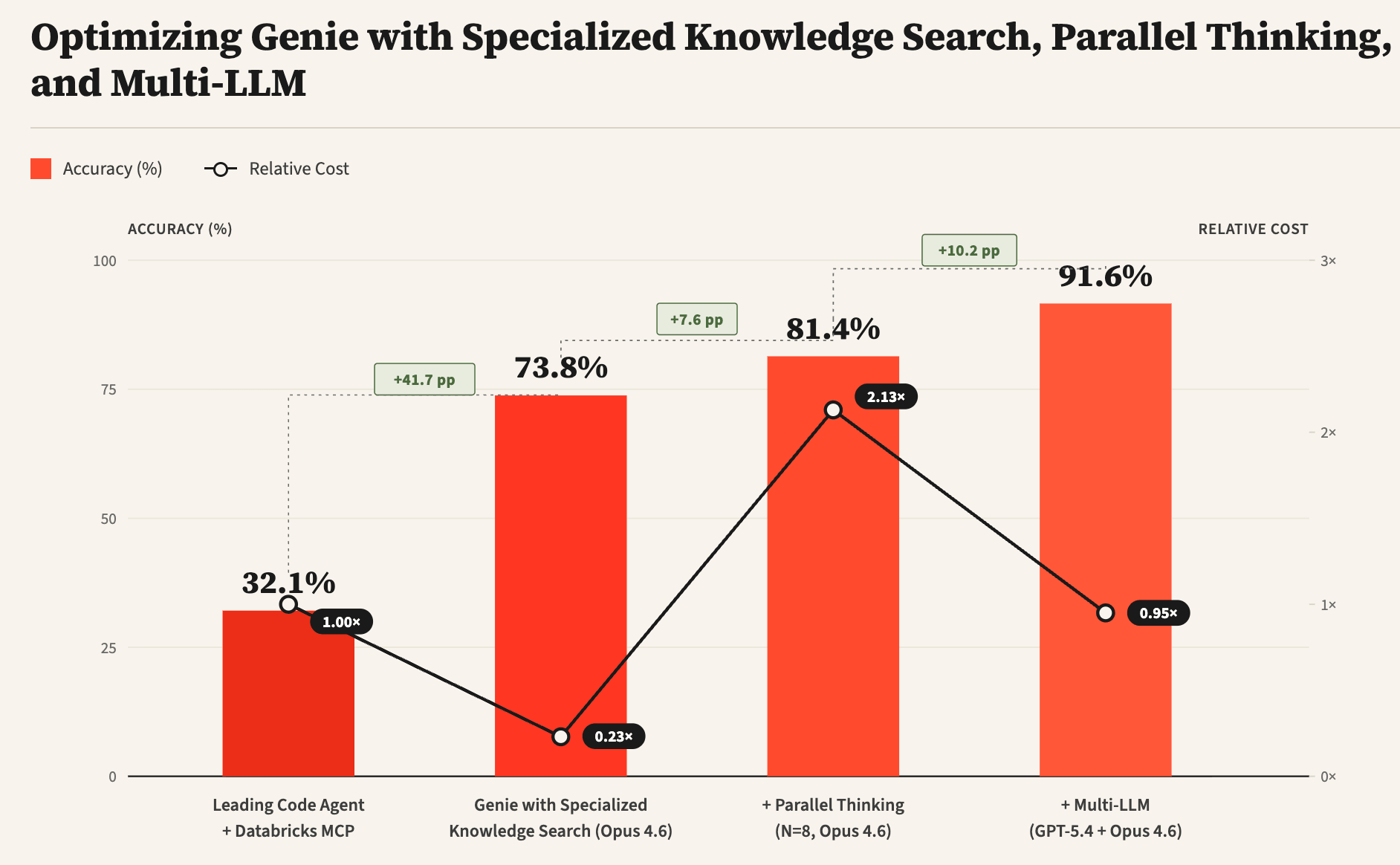
Genie è l'agente dati all'avanguardia di Databricks, progettato per rispondere a domande complesse sui dati aziendali, che comprendono sia fonti di dati strutturate (tabelle, dashboard, notebook, ecc.) sia non strutturate (file dell'area di lavoro, Google Drive, Sharepoint, ecc.). Questo post descrive alcune delle sfide uniche affrontate dagli agenti dati e introduce tecniche per affrontarle, tra cui l'uso della ricerca di conoscenza specializzata, il pensiero parallelo e i design Multi-LLM. Dai nostri esperimenti su un benchmark interno di attività di analisi dati reali, osserviamo che queste tecniche possono migliorare significativamente l'accuratezza complessiva di Genie rispetto a un agente di codifica leader (dal 32% a oltre il 90%), riducendo al contempo significativamente i costi e la latenza.
Sfide chiave per gli agenti dati
Gli agenti di codifica hanno dimostrato che un potente LLM può fare cose incredibili autonomamente se dotato di strumenti che lo aiutano a comprendere il contesto del codice. Mentre gli agenti di codifica operano efficacemente in ambienti statici e deterministici come il file system di un disco, gli agenti dati introducono un paradigma completamente nuovo. Gli agenti dati operano all'interno di un data lakehouse dinamico e in continua evoluzione che comprende una ricchezza di contesto semantico attraverso centinaia di migliaia di tabelle, notebook, dashboard e documenti.
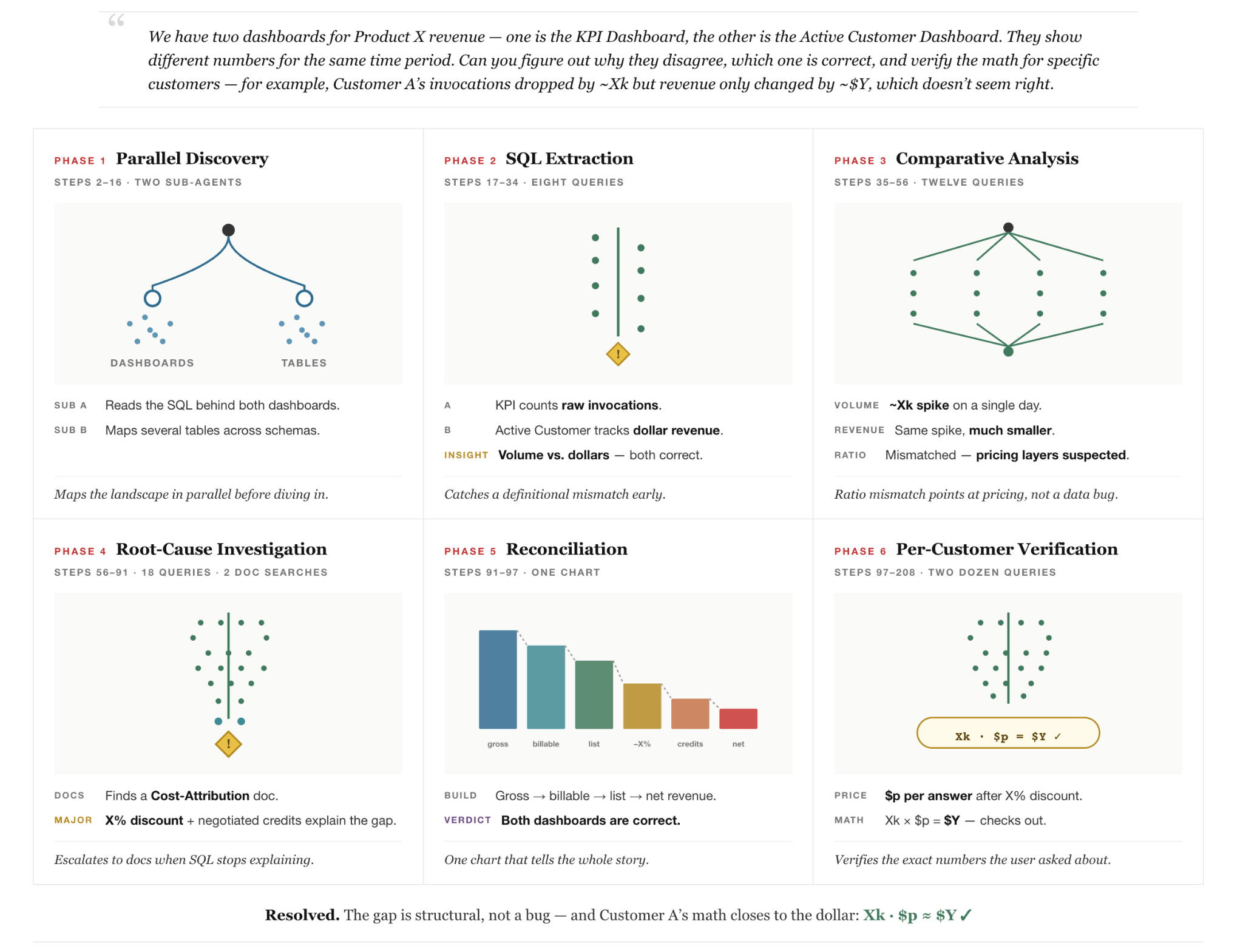
Ad esempio, considera una query reale (anonimizzata) posta da un utente interno nella Figura 2: l'utente nota che due dashboard aziendali che riportano le entrate dello stesso prodotto mostrano picchi contraddittori in date diverse e chiede all'agente di spiegare perché. Questa domanda ragionevole è ingannevolmente difficile perché nessuna singola fonte dati contiene la risposta e la risoluzione della domanda richiede la scoperta cross-system attraverso tabelle, documenti interni e dashboard, e il ragionamento su come vengono impostati i report multi-giorno. Inoltre, richiede all'agente di approfondire i dettagli sui prezzi aziendali per trovare le tariffe contrattuali. Infine, richiede all'agente la capacità di correggersi automaticamente quando i calcoli intermedi rivelano presupposti iniziali errati. La figura mostra come l'agente sia in grado di risolvere con successo il compito procedendo in diverse fasi: (1) scoperta parallela multi-agente dei dati, (2) indagine sui dati, (3) ciclo di autocorreggimento e (4) verifica.
Rispetto agli agenti di codifica, gli agenti dati presentano tre sfide uniche chiave:
- Scala della scoperta dei dati: Trovare le giuste fonti di dati per rispondere alla query dell'utente è una delle maggiori sfide per i clienti aziendali che dispongono di milioni di origini strutturate e non strutturate (come tabelle, dashboard e documenti), una scala che interrompe i metodi di ricerca convenzionali.
- Determinazione della conoscenza aziendale "Fonte di Verità": Rispondere a domande aziendali richiede una conoscenza approfondita e specifica tratta da molte fonti (ad es. metadati delle tabelle, documenti aziendali, messaggi interni) che sono spesso obsolete, contraddittorie o superate, costringendo l'agente a determinare le informazioni più autorevoli.
- Mancanza di test verificabili: A differenza degli agenti di codifica che possono utilizzare test deterministici e verificabili per perfezionare iterativamente il codice, gli agenti dati non hanno test corrispondenti perché la "specifica" è solo la query utente di alto livello senza una nozione della risposta corretta attesa. Inoltre, le query potrebbero non essere sempre rispondibili a causa di incompletezza dei dati, ed è importante che gli agenti dati siano in grado di identificare tali casi e comunicarli agli utenti.
Principali progressi tecnici
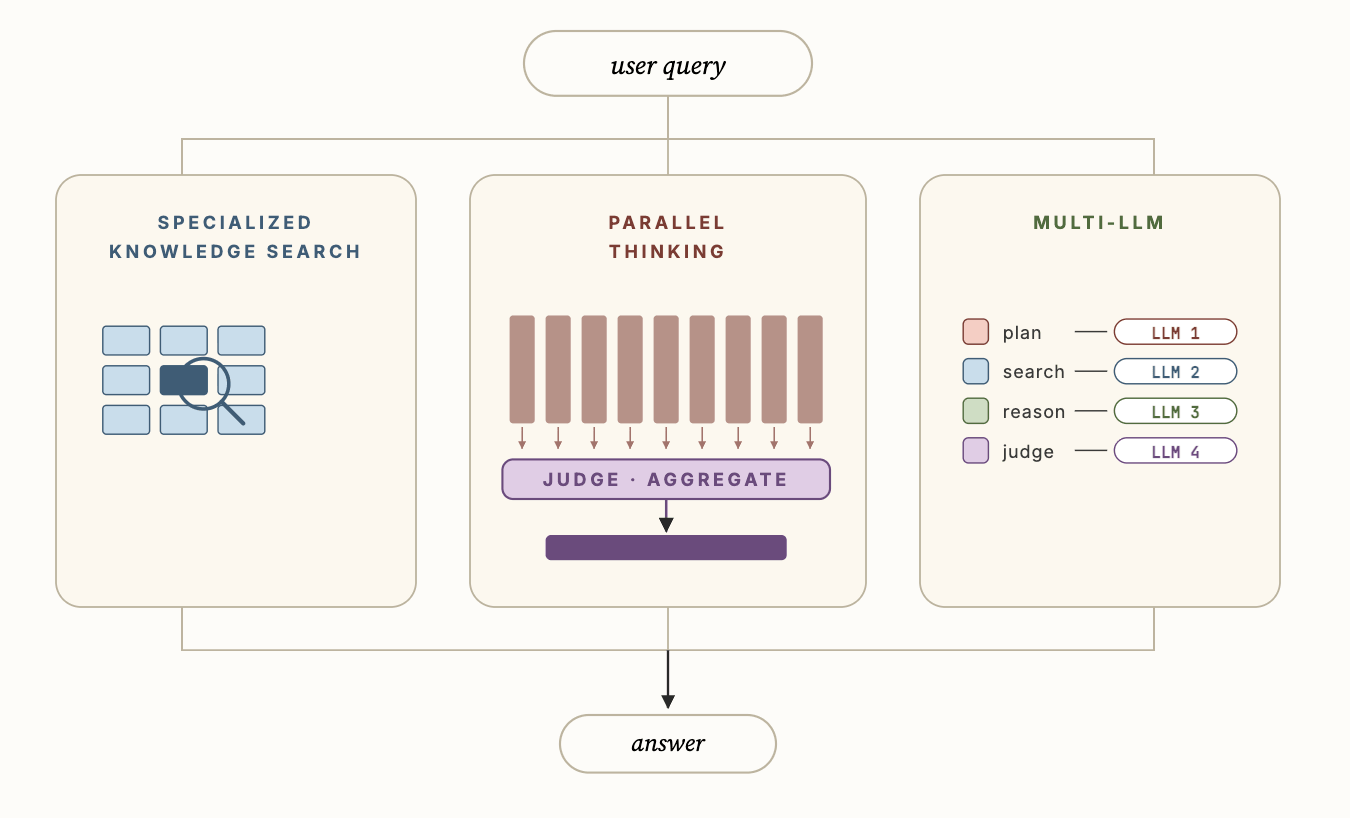
La Figura 3 mostra alcune delle principali innovazioni tecniche in Genie che gli consentono di ottenere prestazioni significativamente migliori rispetto agli agenti di codifica generici, ovvero: i) Ricerca di conoscenza specializzata, ii) Pensiero parallelo e iii) Multi-LLM. La ricerca di conoscenza specializzata utilizza dati contestuali semantici per fondare i sotto-agenti di scoperta degli asset e migliorare significativamente la qualità della ricerca. Il pensiero parallelo consente all'agente di campionare più traiettorie diverse e quindi aggregare i risultati tra le traiettorie per calcolare la risposta finale. Infine, Multi-LLM consente all'agente di utilizzare diversi LLM per ciascuno dei diversi sotto-agenti insieme ai loro prompt ottimizzati per migliorare ulteriormente l'accuratezza complessiva e la latenza.
Ricerca di conoscenza specializzata
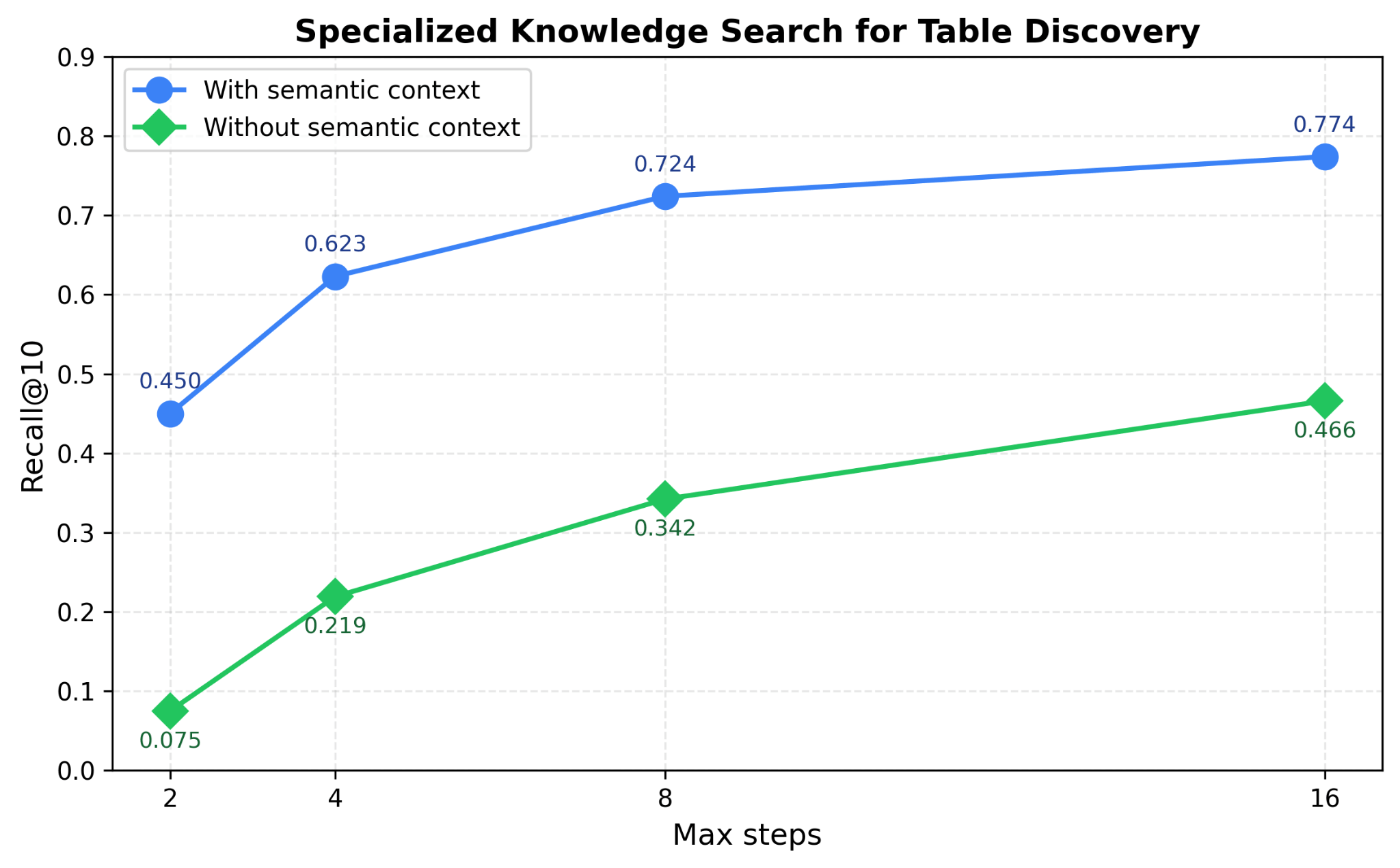
Genie utilizza gli asset di dati esistenti come tabelle dell'area di lavoro, notebook, dashboard, documenti e file per derivare un ricco contesto aziendale semantico e quindi utilizza questo contesto per costruire un indice di ricerca. Utilizza più indici di ricerca in parallelo insieme a ricchi segnali di metadati per scoprire in modo efficiente gli asset più pertinenti per una query utente. La Figura 4 dimostra come l'utilizzo della ricerca di conoscenza specializzata aiuti Genie a migliorare le prestazioni di ricerca delle tabelle fino al 40% nei nostri benchmark di scoperta delle tabelle.
Pensiero parallelo
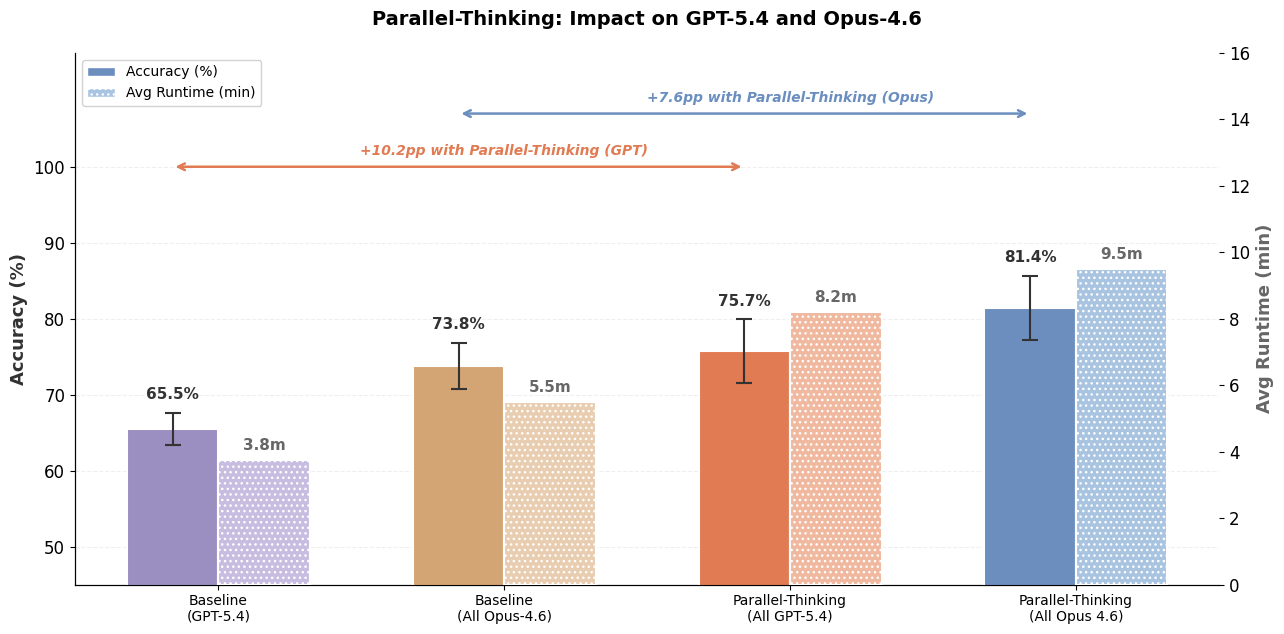
A differenza dei compiti di ingegneria del software, dove gli agenti di codifica possono prima scrivere test per verificare la funzionalità desiderata e quindi iterare sulla generazione del codice finché i test non superano, le query di dati aperte non hanno test unitari corrispondenti. In assenza di test, diventa difficile per gli agenti dati sapere se la risposta generata è corretta o necessita di ulteriori perfezionamenti. Per affrontare questa sfida, sfruttiamo il pensiero parallelo campionando più traiettorie e aggregando informazioni pertinenti tra le traiettorie per calcolare la risposta finale. La Figura 5 mostra come il pensiero parallelo possa migliorare significativamente l'accuratezza della risposta, sebbene con una latenza e costi di token aggiuntivi. Inoltre, come mostrato nella Figura 1, la combinazione di Multi-LLM e ulteriori ottimizzazioni può ridurre ulteriormente in modo significativo i costi e la latenza.
Multi-LLM
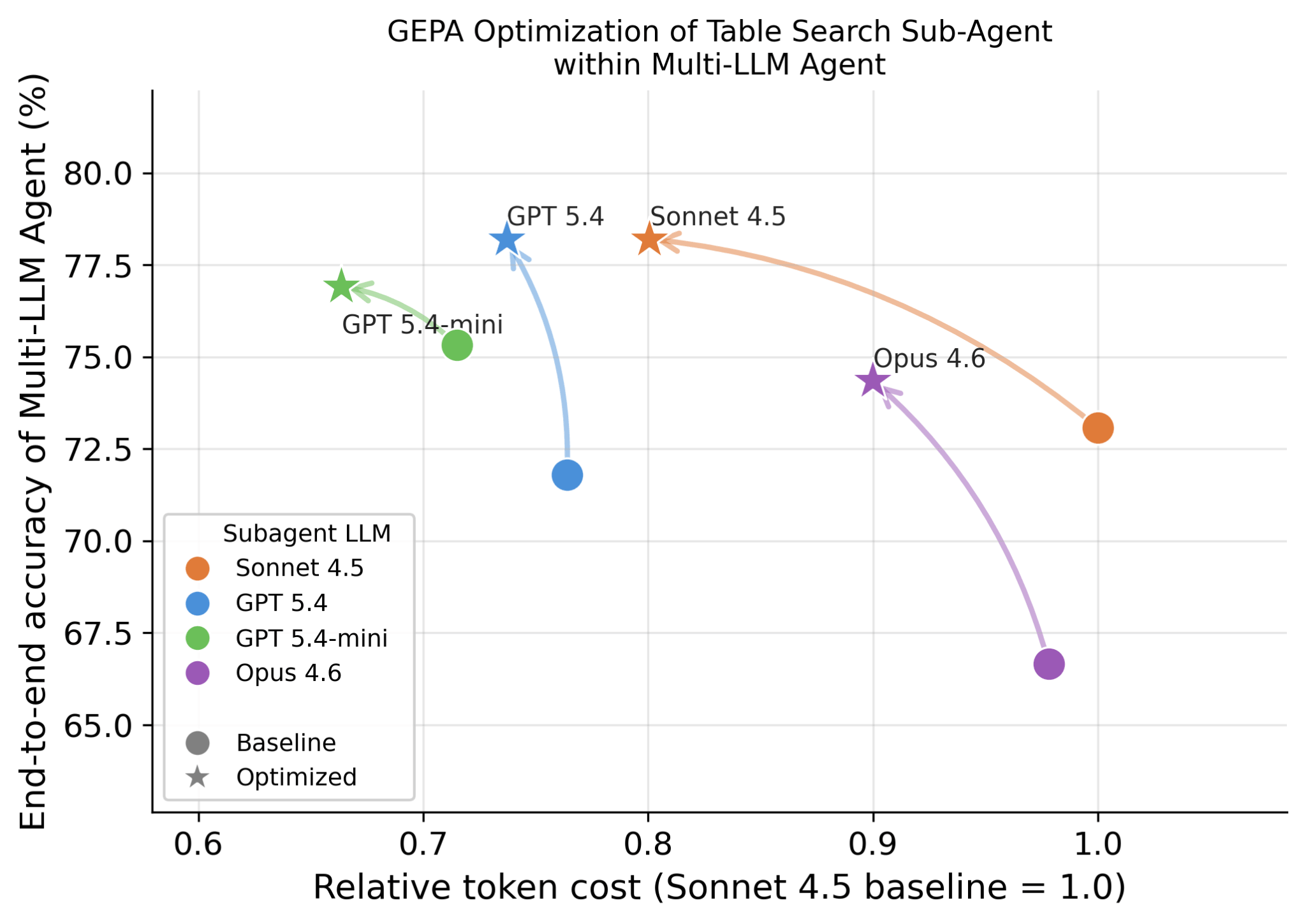
Uno dei principali progressi tecnici in Genie è la capacità di sfruttare diversi LLM per diversi sotto-agenti, poiché osserviamo che diversi LLM sono bravi in capacità complementari. Ad esempio, può utilizzare un LLM diverso per la fase di pianificazione, un LLM diverso per i vari sotto-agenti di ricerca, un altro per la generazione di codice e i giudici. Con la piattaforma Databricks, è semplice provare qualsiasi modello all'avanguardia (inclusi Opus, GPT e Gemini), modelli open-source, nonché modelli addestrati personalizzati. Oltre all'accuratezza, osserviamo anche che diversi LLM comportano caratteristiche di latenza e costo molto diverse. La Figura 6 mostra come diversi LLM si comportano nelle attività di ricerca di tabelle e come l'accuratezza e il costo corrispondenti possano essere ulteriormente ottimizzati utilizzando metodi come GEPA.
Conclusione
Sebbene la codifica e l'analisi dei dati condividano molte somiglianze concettuali, la natura dinamica dei sistemi di dati aziendali crea alcune sfide uniche. Gli agenti di dati devono scoprire in modo efficiente le risorse giuste da un ampio contesto aziendale, determinare la "verità" in un ambiente ambiguo e scrivere codice e query efficienti per rispondere correttamente alle domande degli utenti. Abbiamo sviluppato diversi approcci innovativi per risolvere questi problemi, come la ricerca specializzata della conoscenza per sfruttare ricche informazioni semantiche e segnali di metadati multipli, Multi-LLM per sfruttare diversi LLM con prompt ottimizzati utilizzando GEPA e il pensiero parallelo per migliorare ulteriormente l'accuratezza complessiva. L'aggiunta di questi approcci a Genie lo aiuta a superare significativamente gli agenti di codifica leader nei compiti di benchmark. Ci sono ancora molte domande aperte e stimolanti da esplorare, e non è mai stato un momento più emozionante per esplorare la ricerca in quest'area di costruzione di agenti di dati all'avanguardia per le imprese.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.