Plotting Nativo in PySpark
Crea visualizzazioni direttamente dai DataFrame PySpark con facilità
- Introduzione al Plotting Nativo PySpark: Questo blog spiega la necessità di funzionalità di visualizzazione integrate in PySpark, in linea con la funzionalità che gli utenti si aspettano da Pandas API su Spark e dai DataFrame pandas nativi.
- Funzionalità e Capacità Chiave: Spieghiamo vari tipi di grafici supportati, come il plotting PySpark sfrutta strategie efficienti di elaborazione dei dati (ad es. campionamento, metriche globali) e l'integrazione con Plotly per le visualizzazioni.
- Esempio Pratico: Dimostriamo il plotting PySpark con un esempio pratico, guidando i lettori attraverso la creazione e la personalizzazione delle visualizzazioni ed evidenziando le intuizioni attuabili derivate dai grafici.
Introduzione
Siamo entusiasti di presentare il plotting nativo in PySpark con Databricks Runtime 17.0 (note di rilascio), un entusiasmante passo avanti per la visualizzazione dei dati. Non è più necessario passare da uno strumento all'altro solo per visualizzare i tuoi dati; ora puoi creare grafici belli e intuitivi direttamente dai tuoi DataFrame PySpark. È veloce, fluido e integrato. Questa funzionalità a lungo attesa rende l'esplorazione dei tuoi dati più facile e potente che mai.
Lavorare con big data in PySpark è sempre stato potente, specialmente quando si tratta di trasformare e analizzare set di dati su larga scala. Mentre i DataFrame PySpark sono costruiti per scalabilità e prestazioni, gli utenti in precedenza dovevano convertirli in DataFrame Pandas API su Apache Spark™ per generare grafici. Ma questo passaggio aggiuntivo rendeva i flussi di lavoro di visualizzazione più complicati del necessario. La differenza nella struttura tra PySpark e DataFrame in stile pandas spesso portava a attriti, rallentando il processo di esplorazione dei dati visivamente.
Esempio
Ecco un esempio di utilizzo del plotting PySpark per analizzare Vendite, Profitto e Margini di Profitto in varie categorie di prodotti.
Iniziamo con un DataFrame contenente dati di vendite e profitti per diverse categorie di prodotti, come mostrato di seguito:
Il nostro obiettivo è visualizzare la relazione tra Vendite e Profitto, incorporando anche il Margine di Profitto come dimensione visiva aggiuntiva per rendere l'analisi più significativa. Ecco il codice per creare il grafico:
Nota che “fig” è di tipo “plotly.graph_objs._figure.Figure”. Possiamo migliorarne l'aspetto aggiornando il layout utilizzando le funzionalità Plotly esistenti. La figura modificata appare così:
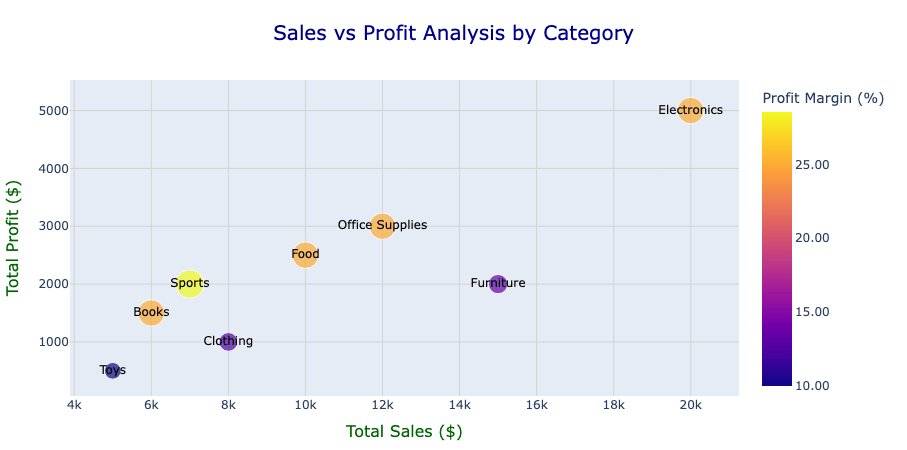
Dalla figura, possiamo osservare chiare relazioni tra vendite e profitti in diverse categorie. Ad esempio, l'elettronica mostra vendite e profitti elevati con un margine di profitto relativamente moderato, indicando una forte generazione di ricavi ma spazio per migliorare l'efficienza.
Funzionalità del Plotting PySpark
Interfaccia Utente
L'utente interagisce con il plotting PySpark chiamando la proprietà plot su un DataFrame PySpark e specificando il tipo di grafico desiderato come sottometodo o impostando il parametro “kind”. Ad esempio:
o equivalentemente:Questo design è in linea con le interfacce di Pandas API su Apache Spark e pandas nativo, offrendo un'esperienza coerente e intuitiva per gli utenti già familiari con il plotting pandas.
Tipi di Grafico Supportati
Il plotting PySpark supporta una varietà di tipi di grafico comuni, come grafici a linee, a barre (inclusi quelli orizzontali), ad area, a dispersione, a torta, a scatola, istogrammi e grafici di densità/KDE. Ciò consente agli utenti di visualizzare tendenze, distribuzioni, confronti e relazioni direttamente dai DataFrame PySpark.
Interni
La funzionalità è alimentata da Plotly (versione 4.8 o successiva) come backend di visualizzazione predefinito, offrendo funzionalità di plotting ricche e interattive, mentre pandas nativo (pandas) viene utilizzato internamente per elaborare i dati per la maggior parte dei grafici.
A seconda del tipo di grafico, l'elaborazione dei dati nel plotting PySpark viene gestita attraverso una delle tre strategie:
- Top N Righe: Il processo di plotting utilizza un numero limitato di righe dal DataFrame (predefinito: 1000). Questo può essere configurato utilizzando l'opzione “spark.sql.pyspark.plotting.max_rows”, rendendolo efficiente per rapide intuizioni. Questo si applica ai grafici a barre, ai grafici a barre orizzontali e ai grafici a torta.
- Campionamento: Il campionamento casuale rappresenta efficacemente la distribuzione generale senza elaborare l'intero set di dati. Ciò garantisce la scalabilità mantenendo la rappresentatività. Questo si applica ai grafici ad area, ai grafici a linee e ai grafici a dispersione.
- Metriche Globali: Per grafici a scatola, istogrammi e grafici di densità/KDE, i calcoli vengono eseguiti sull'intero set di dati. Ciò consente una rappresentazione accurata delle distribuzioni dei dati, garantendo la correttezza statistica.
Questo approccio rispetta le strategie di plotting di Pandas API su Apache Spark per ciascun tipo di grafico, con ulteriori miglioramenti delle prestazioni:
- Campionamento: In precedenza, erano necessari due passaggi sull'intero set di dati: uno per calcolare il rapporto di campionamento e un altro per eseguire il campionamento effettivo. Abbiamo implementato un nuovo metodo basato sul campionamento per reservoir, riducendolo a un singolo passaggio.
- Sottografici: Nei casi in cui ogni colonna corrisponde a un sottografico, ora calcoliamo le metriche per tutte le colonne insieme, migliorando l'efficienza.
- Grafici basati su ML: Abbiamo introdotto espressioni SQL interne dedicate per questi grafici, abilitando ottimizzazioni lato SQL come la generazione di codice.
Conclusione
Il plotting nativo PySpark colma il divario tra PySpark e la visualizzazione intuitiva dei dati. Questa funzionalità consente agli utenti PySpark di creare grafici di alta qualità direttamente dai loro DataFrame PySpark, rendendo l'analisi dei dati più veloce e accessibile che mai. Sentiti libero di provare questa funzionalità su Databricks Runtime 17.0 per migliorare la tua esperienza di visualizzazione dei dati!
Pronto per esplorare di più? Dai un'occhiata alla documentazione dell'API PySpark per guide ed esempi dettagliati.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.