Decisioning in tempo reale per agenti AI: perché prima hai bisogno di un livello di contesto del cliente
Una prospettiva Snowplow su "The New Martech Stack for the AI Age" di Scott Brinker
di Alex Dean
- Scott Brinker ha recentemente pubblicato un report di ricerca con Databricks, "The New Martech “Stack” for the AI Age", che ha delineato un passaggio da stack rigidi a una "fluid composable canvas" per l'architettura di marketing nell'arco di 3-5 anni.
- Alex Dean, Co-Founder e CEO di Snowplow, condivide la sua prospettiva su come il "customer context layer" cattura dati comportamentali in tempo reale che gli agenti AI utilizzano per decisioni "in-the-moment".
- Il "feedback loop" degli agenti trasforma il marketing in un "flywheel": raccoglie e unifica il comportamento umano e AI in tempo reale, lo attiva per il "decisioning", quindi chiude il cerchio in modo che gli agenti imparino e migliorino continuamente in base ai risultati.
Il nuovo report di Scott Brinker con Databricks articola qualcosa che osservo da anni: lo "stack" martech, la familiare disposizione a Tetris di caselle, sta iniziando a dissolversi. Ciò che emerge al suo posto è ciò che Scott chiama una tela componibile: un'architettura fluida e incentrata sui dati in cui agenti AI e software personalizzati operano su dati condivisi anziché combattere attraverso pipeline di integrazione.
Leggendolo, mi sono ritrovato ad annuire più di una volta. Non perché sia una tesi facile da sostenere (è in realtà una riformulazione piuttosto radicale di come le aziende pensano alla tecnologia di marketing), ma perché descrive una direzione architetturale a cui noi di Snowplow ci siamo impegnati molto tempo fa, spesso prima che ci fosse un vocabolario condiviso per definirla.
Volevo condividere alcune reazioni: dove il report risuona fortemente, come pensiamo che Snowplow si inserisca nell'architettura che descrive e una dimensione che aggiungerei al modello che ritengo diventi più importante man mano che gli agenti AI assumono un ruolo più ampio nelle interazioni con i clienti.
La piattaforma dati è ora il centro di gravità per il processo decisionale in tempo reale
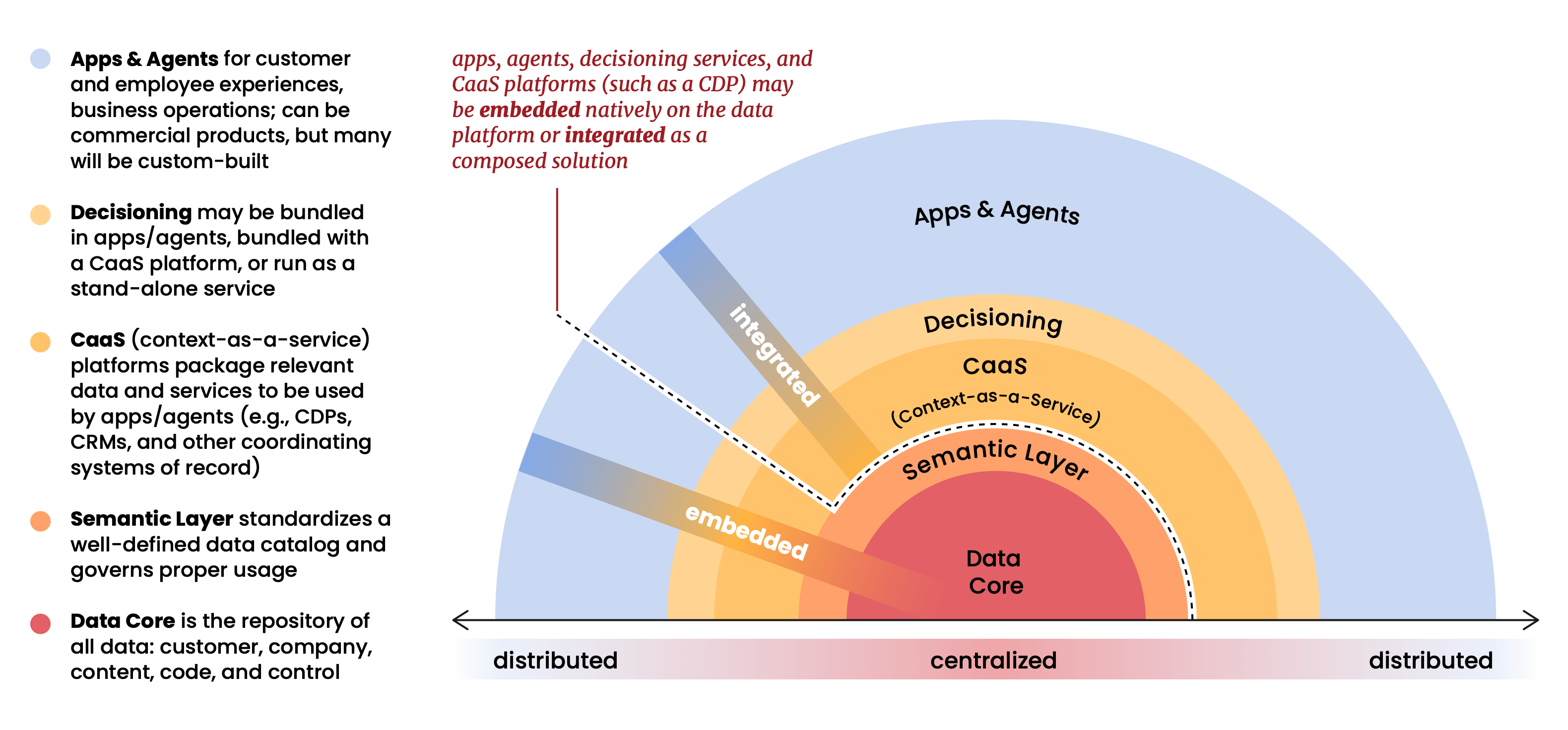
L'argomento strutturale centrale del report è che la piattaforma dati (Databricks, Snowflake, BigQuery, ecc.) è diventata il centro gravitazionale dell'intero stack martech. Applicazioni, agenti e analisi non siedono più sopra i dati; operano al loro interno. La piattaforma dati non è più un repository in fondo allo stack. È lo stack.
Questa è una visione che abbiamo sostenuto in Snowplow per molto tempo, ed è una che ha plasmato molte decisioni iniziali su come abbiamo costruito il nostro prodotto. Quando stavamo mettendo insieme Snowplow nel 2012, il modello prevalente era quello di accumulare dati dei clienti all'interno dei sistemi dei fornitori e fornire un accesso gestito ad essi. Abbiamo adottato la posizione opposta: i tuoi dati appartengono alla tua infrastruttura, governati dalle tue regole, interrogabili da qualsiasi strumento tu scelga. All'epoca, sembrava una posizione architetturale di principio, forse anche leggermente controcorrente. Come rende chiaro questo report, ora è l'unica architettura che ha senso su larga scala.
Cos'è il Customer Context Layer? E perché il processo decisionale in tempo reale dipende da esso
Cos'è il customer context layer? Il customer context layer è l'infrastruttura comportamentale in tempo reale che si colloca tra la tua base dati e i tuoi sistemi rivolti al cliente. È collegata direttamente alle esperienze digitali in modo che gli agenti AI possano comprendere cosa sta facendo un cliente in questo momento, oltre al suo intero percorso storico.
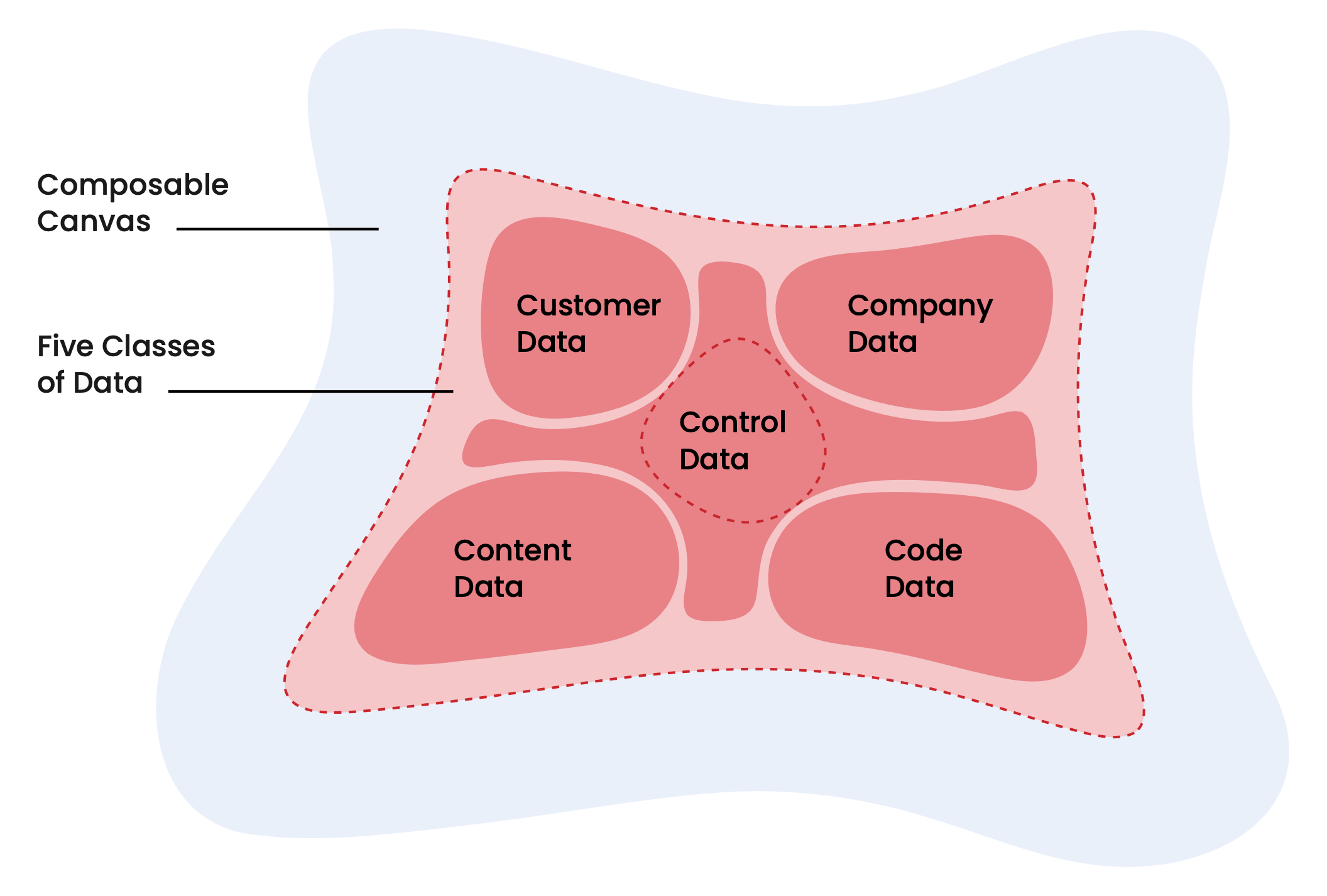
Il report descrive cinque classi di dati che convergono sulla fondazione unificata: dati del cliente, dati dell'azienda, dati dei contenuti, dati del codice e dati di controllo. Dati del cliente: "profili individuali e di account, cronologie delle transazioni, segnali comportamentali (visite web, utilizzo del prodotto)" si trova al centro di tutto.
È qui che opera Snowplow. Ma spingerei la definizione leggermente oltre quanto fa il report.
C'è una differenza significativa tra record del cliente e contesto del cliente. CRM e CDP gestiscono da tempo bene i primi: chi è il cliente, quali trattative ha, a quali segmenti appartiene. Ciò che è sempre stato più difficile da fornire è il secondo, ovvero: cosa sta facendo, in questo momento, e cosa ti dice quel comportamento sulla sua intenzione?
I flussi di eventi comportamentali, il record continuo e granulare di come i clienti interagiscono con il tuo prodotto, il tuo sito web, la tua app, sono il segnale in tempo reale più ricco disponibile per qualsiasi agente AI che cerca di prendere una decisione. E sono notoriamente difficili da ottenere correttamente. Gli eventi devono essere strutturati al momento della raccolta, validati rispetto a uno schema e arricchiti prima di raggiungere la base dati. Se i dati comportamentali che entrano nella tua piattaforma unificata sono rumorosi, incoerenti o mal modellati, gli agenti AI che operano su di essi amplificheranno tali errori su larga scala.
Snowplow è il customer context layer. Ci posizioniamo tra il momento in cui un cliente fa qualcosa (un clic, un evento di prodotto, una ricerca, uno scroll) e la piattaforma dati che deve agire su di esso. Il nostro compito è garantire che i dati comportamentali siano strutturati, ben governati e semanticamente coerenti dal momento in cui vengono creati.
E il contesto senza identità è rumore. Un ricco flusso comportamentale è utile solo quanto la tua capacità di collegarlo a un individuo noto e risolto attraverso touchpoint, dispositivi e sessioni, comprese le transizioni tra stati anonimi e autenticati. Snowplow's Identities svolge questo lavoro a livello di raccolta, prima che i dati arrivino alla piattaforma. Il risultato non è solo un flusso di eventi. È un quadro risolto e continuo del percorso di ogni cliente su cui la tua piattaforma dati, i tuoi analisti e i tuoi agenti AI possono operare con fiducia.
La componibilità è sempre stata l'architettura, non la funzionalità
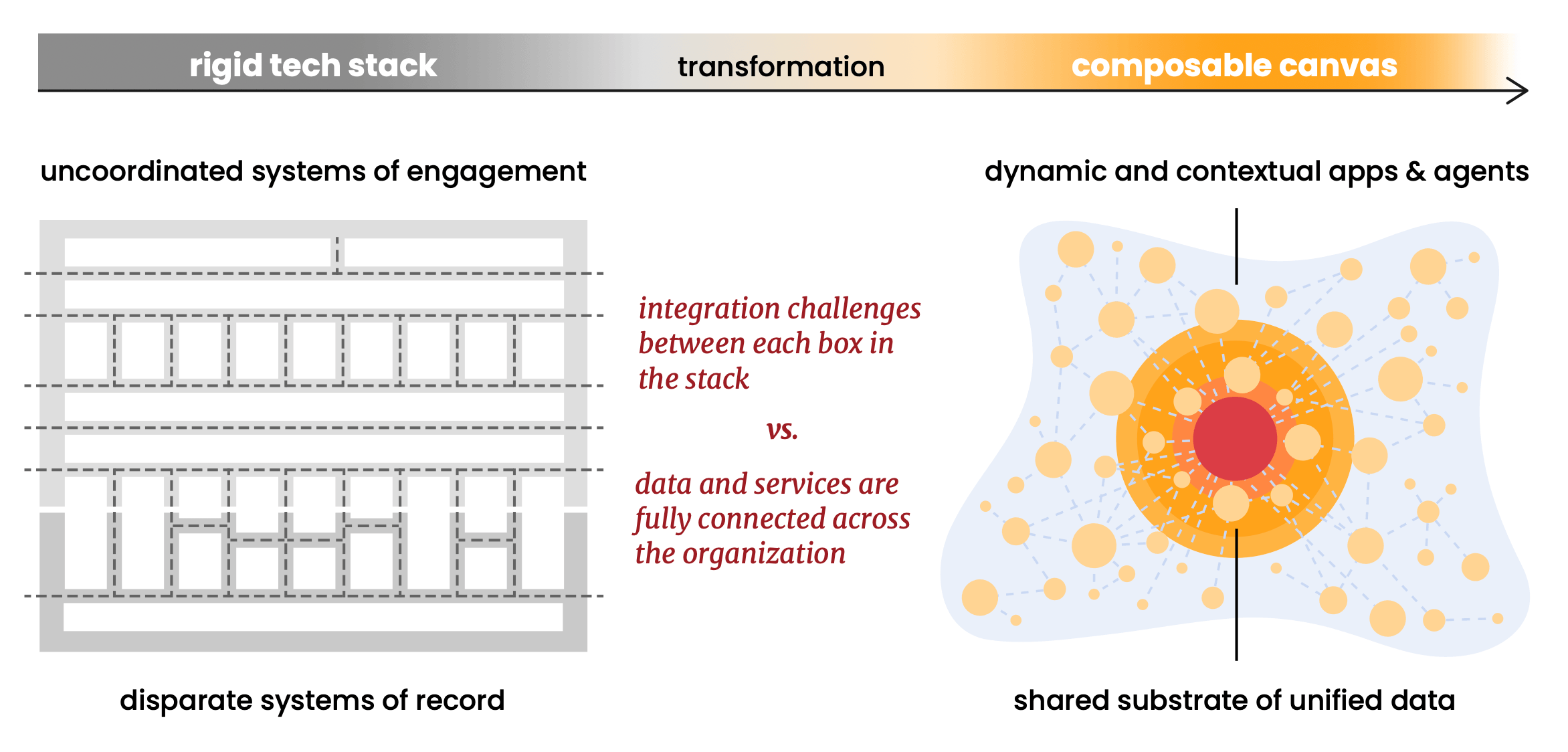
L'argomento della componibilità del report è uno dei più forti. Sostiene formati dati aperti (Delta Lake della Linux Foundation, Apache Iceberg), protocolli aperti (MCP per agenti) e standard aperti come prerequisito per una tela veramente componibile. Il principio: standardizzare la base in modo da poter diversificare tutto ciò che viene eseguito sopra.
Crediamo profondamente in questo e abbiamo costruito Snowplow attorno ad esso fin dall'inizio. Crediamo negli standard open core. Le nostre strutture dati funzionano nativamente su Apache Iceberg e Delta Lake della Linux Foundation. Operiamo all'interno del tuo account cloud (indicato come hyperscaler nell'articolo di Scott: AWS, GCP o Azure), il che significa che i tuoi dati comportamentali non lasciano mai il tuo ambiente. Non esiste un data store proprietario di Snowplow che diventi una dipendenza o un rischio di migrazione. Quando desideri sostituire o estendere qualsiasi parte dello stack, i dati comportamentali sono già dove devono essere: nella tua piattaforma, in formati aperti, pronti per essere composti.
Il report osserva che i "CDP componibili ribaltano" il modello tradizionale portando le funzionalità CDP ai dati anziché tirare i dati nel CDP. Snowplow lo faceva prima che la categoria avesse un nome, perché per noi la componibilità non è mai stata una funzionalità che abbiamo aggiunto. Era il principio fondante su cui è stato costruito il prodotto.
Il livello semantico inizia prima della piattaforma
Una delle idee più importanti che il report sviluppa è il ruolo del livello semantico, in particolare ciò che chiama "il custode della coerenza". Questo è il vocabolario condiviso che rende i dati significativi e coerenti attraverso ogni agente e applicazione che li utilizza. Cosa significa "cliente" tra i team. Come viene calcolata la "conversione". Cosa costituisce un "lead qualificato".
Dal nostro punto di vista, aggiungerei un'osservazione pratica: la maggior parte di queste domande deve essere risposta prima che i dati entrino nella piattaforma, non dopo. I dati comportamentali in particolare sono straordinariamente facili da raccogliere male. Gli eventi arrivano con nomi incoerenti, proprietà mancanti, schemi non definiti. Quando i dati raggiungono la piattaforma, sono già incoerenti. Puoi costruire un livello semantico sopra dati scadenti, ma stai coprendo un problema strutturale invece di risolverlo.
Il nostro schema registry e la validazione degli eventi tramite il nostro Event Studio impongono la coerenza semantica al momento della raccolta. Rifiutiamo o segnaliamo gli eventi che non sono conformi alle strutture definite prima che raggiungano la piattaforma dati. Nella tela componibile descritta nel report - dove decine di agenti e applicazioni attingono tutti agli stessi dati comportamentali - la qualità di tali dati alla fonte determina se è possibile fidarsi di qualsiasi cosa costruita su di essi.
Il ciclo di feedback agentivo: come si chiude effettivamente il processo decisionale in tempo reale
Il report fa un'affermazione che ritengo meriti ancora più enfasi: gli agenti AI sono "affamati di contesto". Non hanno solo bisogno di record dei clienti; hanno bisogno di capire cosa sta succedendo al momento, ovvero: i segnali comportamentali che indicano intenzione, urgenza e opportunità.
Aggiungerei qualcosa al modello che Scott ha delineato qui. Il report inquadra i dati come flussi verso gli agenti - una base da cui gli agenti attingono per prendere decisioni. Ciò che non sviluppa completamente è il ciclo che si verifica dopo che l'agente agisce, e perché chiudere quel ciclo è sempre più il problema dati strategicamente più importante nel martech. Questo è qualcosa a cui pensiamo molto in Snowplow, ed è centrale per come la tela componibile opera effettivamente in pratica.
Il ciclo ha quattro fasi:
- La fase di raccolta acquisisce eventi comportamentali sia da interazioni umane che guidate dall'IA come dati strutturati e convalidati dallo schema, che fluiscono continuamente nella piattaforma dati. Ma la definizione di "dati comportamentali" deve espandersi per includere una seconda classe di attività che la maggior parte delle architetture non sta ancora catturando bene. Questa seconda classe ha due facce distinte. La prima è l'analisi degli agenti IA: quando un cliente interagisce con un agente conversazionale, riceve una raccomandazione personalizzata o ha un percorso modellato da un sistema di decisione automatizzato, queste interazioni guidate dall'agente sono esse stesse eventi che devono essere raccolti con lo stesso rigore di qualsiasi comportamento umano. La seconda è l'analisi agentica: agenti IA che conducono ricerche per conto di un utente. Quando un'IA naviga nelle tue pagine di prodotto, legge la tua documentazione o confronta opzioni per conto di un cliente, quel traffico è intento, espresso solo attraverso un attore non umano. Trattarlo come rumore di bot da filtrare significa scartare un segnale che ti dice qualcosa di reale su ciò che un cliente sta valutando. Snowplow distingue e cattura entrambi come eventi comportamentali strutturati, separati dall'interazione umana diretta ma ugualmente significativi per comprendere l'intento e informare le decisioni.
- La fase di risoluzione e arricchimento trasforma i flussi di eventi grezzi in un quadro coerente del cliente attraverso la risoluzione dell'identità, l'unione di sessioni, dispositivi e punti di contatto a un individuo noto. Qui il flusso comportamentale diventa un quadro coerente: non "un utente ha visitato tre pagine", ma "questo account, attualmente in fase di valutazione avanzata, ha visto tre dirigenti ricercare i prezzi nelle ultime 48 ore".
- La fase di servizio fornisce un contesto comportamentale arricchito in due modalità simultanee: in tempo reale per la personalizzazione in-session, e combinata in tempo reale più storica per il processo decisionale dell'agente IA. Per la personalizzazione in-session, è in tempo reale: la piattaforma dati espone i segnali comportamentali abbastanza velocemente che l'esperienza che viene presentata a questo cliente in questo momento riflette ciò che ha fatto in questa sessione. Per il processo decisionale dell'agente IA, è sia in tempo reale che storico: un agente che coordina la prossima azione migliore per un account attinge al flusso comportamentale live e all'intero record storico del cliente. La domanda non è solo "cosa sta facendo questo cliente?", ma "cosa significa questo comportamento, dato tutto ciò che sappiamo di clienti simili a loro?"
- La fase di apprendimento chiude il ciclo di feedback instradando gli esiti di ogni decisione dell'agente nuovamente nella fondazione dati come eventi comportamentali di prima classe. L'output di ogni decisione dell'agente, ogni esperienza personalizzata, ogni azione automatizzata è esso stesso un evento comportamentale. Il prodotto consigliato è stato aggiunto al carrello? L'email personalizzata è stata aperta? L'intervento in-session ha cambiato la traiettoria della sessione? La sessione di ricerca dell'agente IA ha portato a una conversione? Questi esiti devono tornare nella stessa fondazione dati che ha alimentato la decisione originale. Senza questo feedback, gli agenti IA operano su dati storici che diventano sempre più obsoleti. Con esso, il sistema diventa genuinamente auto-migliorante.
Qui è dove l'analisi degli agenti IA e l'analisi agentica completano il ciclo. Hai raccolto eventi comportamentali degli agenti IA come dati di prima classe; ora puoi analizzarli con lo stesso rigore che applicheresti al comportamento umano. Quali agenti stanno performando? Quali modelli decisionali si stanno degradando? Dove sta convertendo il traffico generato dall'IA e dove sta calando? Queste domande possono essere risposte solo se la raccolta è stata corretta fin dall'inizio. L'analisi degli agenti IA e l'analisi agentica non sono un livello di reporting che aggiungi in seguito. Sono una conseguenza di come hai raccolto i dati in primo luogo.
Questo è il ciclo di feedback unico per ottenere un'infrastruttura di dati comportamentali corretta. Non è una pipeline. È un volano.
Dall'analisi al processo decisionale: gli strumenti giusti per il processo decisionale in tempo reale
Qualcosa che il report accenna e che penso meriti più spazio, in particolare per i leader di marketing e dati che pensano a cosa l'IA richiede effettivamente dal loro stack: il passaggio dall'uso dei dati comportamentali per l'analisi al loro uso per il processo decisionale è un cambiamento architetturale significativo, non semplicemente un'espansione del caso d'uso.
L'analisi guarda al passato. Raccogli eventi, li modelli e interroghi i risultati. Una latenza di minuti o ore è accettabile. I dati informano un essere umano che prende una decisione.
Il processo decisionale guarda al futuro ed è in tempo reale. Un agente IA necessita di contesto comportamentale entro millisecondi per determinare quale esperienza offrire a questo cliente, in questa sessione, proprio ora. I requisiti infrastrutturali sono diversi. I requisiti di qualità dei dati sono più elevati perché gli errori non emergono come un'anomalia nel dashboard che qualcuno individua la settimana successiva; emergono come un'esperienza cliente scadente fornita istantaneamente, su larga scala.
Sfortunatamente, la maggior parte delle pipeline di dati impone un compromesso. Alcune ottimizzano per la velocità, ma ti fanno perdere la profondità storica. Altre ottimizzano per la ricchezza, ma ti fanno perdere il margine di latenza di cui il processo decisionale in tempo reale ha bisogno.
La tela componibile richiede entrambi contemporaneamente, sugli stessi dati. Questo è un problema infrastrutturale più difficile di quanto sembri, e vale la pena risolverlo alla base piuttosto che cercare di rattopparlo in seguito quando un agente sta prendendo decisioni alla velocità dei millisecondi e ti rendi conto che il tuo contesto storico si trova in un archivio separato.
Su grafi di contesto e dati comportamentali
Il report introduce un concetto che ho trovato genuinamente interessante: il grafo di contesto — un registro vivo di tracce decisionali che cattura non solo cosa è successo ma perché è stato permesso che accadesse. Logica decisionale, concessioni di eccezioni, catene di approvazione. Il tipo di memoria istituzionale che attualmente vive nei thread di Slack e nelle teste delle persone.
Sosterrei che i flussi di eventi comportamentali sono la materia prima naturale per i grafi di contesto dal lato del cliente. Ogni azione dell'agente che coinvolge un cliente (una raccomandazione fatta, un segmento attivato, un messaggio inviato) dovrebbe essere tracciabile fino ai segnali comportamentali che l'hanno innescata. Il modello di eventi di Snowplow è strutturato per catturare precisamente questa causalità: quale segnale è stato attivato, quali dati sono stati osservati, quale soglia è stata superata.
Man mano che i grafi di contesto maturano come modello architetturale, il livello dei dati comportamentali sarà fondamentale per essi. Il "cosa è successo" e il "perché è successo" sono entrambi codificati nel flusso di eventi, se lo raccogli correttamente fin dall'inizio.
Come costruire una fondazione di processo decisionale in tempo reale che scala
Per qualsiasi organizzazione che costruisce verso la tela componibile descritta nel report, ottenere un'infrastruttura di dati comportamentali corretta è il primo investimento a più alto rendimento: non perché sia il più eccitante, ma perché tutto il resto si basa su di essa.
Ciò significa fare quattro cose correttamente fin dall'inizio:
- Raccolta strutturata con convalida dello schema integrata fin dal primo giorno
- Risoluzione dell'identità a livello di raccolta, non aggiunta in seguito
- Una pipeline costruita per il processo decisionale in tempo reale e l'analisi storica sugli stessi dati
- La disciplina di raccogliere gli output delle interazioni degli agenti IA come eventi comportamentali di prima classe, in modo che il ciclo di feedback si chiuda fin dall'inizio
L'architettura componibile significa anche che le decisioni sui fornitori che prendi oggi dovrebbero essere reversibili. Se la tua pipeline di dati comportamentali scrive in formati aperti nella tua infrastruttura cloud, preservi l'opzionalità. Se scrive in un archivio proprietario, hai creato una dipendenza che limiterà ogni decisione futura sullo stack.
La terza era è già qui per coloro che hanno investito presto
Il report inquadra la terza era del Martech come un orizzonte di 3-5 anni. Per i clienti Snowplow che hanno già effettuato gli investimenti architetturali descritti qui, ovvero: piattaforme dati come nucleo operativo, dati comportamentali che alimentano agenti in tempo reale, il ciclo completo di decisione-analisi in esecuzione su una base componibile, questo non è uno stato futuro. È già come operano oggi.
Questa non è un'affermazione specifica su Snowplow. È la prova che l'architettura è realizzabile ora, per le organizzazioni disposte a darle priorità. La tela componibile non aspetta nuove tecnologie. Aspetta decisioni architetturali e la convinzione di prenderle.
Il report di Scott è un'articolazione chiara e generosa di quali dovrebbero essere tali decisioni. Siamo lieti di vedere questa conversazione svolgersi a questo livello di profondità e lieti di farne parte!

Leggi il report di ricerca completo di Scott Brinker qui: Il nuovo "stack" Martech per l'era dell'IA
Webinar live con Scott Brinker, CMO di Samsara e VP of Marketing Data Science di HP su come il martech si sta evolvendo per l'IA: Registrati al webinar
Se vuoi approfondire cosa serve realmente per la fondazione dati per l'analisi agentica, il team di Snowplow ne ha parlato in dettaglio qui: Cos'è l'analisi agentica? Una guida per i leader dei dati
FAQ:
In cosa si differenzia il processo decisionale in tempo reale dall'elaborazione batch? L'elaborazione batch raccoglie e analizza i dati a intervalli programmati, spesso ore dopo che si è verificata un'interazione. Il processo decisionale in tempo reale elabora i segnali comportamentali nel momento in cui vengono generati e attiva un'azione all'interno della stessa sessione, spesso entro millisecondi. I requisiti infrastrutturali, gli standard di qualità dei dati e le tolleranze di latenza sono fondamentalmente diversi tra i due approcci.
Perché gli agenti AI necessitano di un livello di contesto del cliente? Gli agenti AI che prendono decisioni in-session necessitano di un contesto comportamentale che rifletta ciò che un cliente sta facendo in questo momento, non ciò che ha fatto ieri. Il livello di contesto del cliente fornisce flussi di eventi comportamentali strutturati e risolti per identità, che gli agenti AI possono interrogare in tempo reale. Senza di esso, gli agenti operano su dati obsoleti che degradano la qualità delle decisioni su larga scala.
Qual è la differenza tra record del cliente e contesto del cliente? I record del cliente descrivono chi è un cliente: il suo profilo, la cronologia degli acquisti, lo stato dell'account e l'appartenenza a segmenti. Il contesto del cliente descrive ciò che sta facendo nel momento attuale: quali pagine ha visitato, cosa ha cercato, per quanto tempo si è impegnato e cosa quel comportamento segnala sulla sua intenzione. Il processo decisionale in tempo reale richiede entrambi, ma la maggior parte degli stack di dati è più efficiente nel primo che nel secondo.
Quali sono le quattro fasi del ciclo di feedback agentico? Il ciclo di feedback agentico si articola in quattro fasi: (1) Raccolta — acquisizione di eventi comportamentali da interazioni umane e guidate dall'AI come dati strutturati; (2) Risoluzione e arricchimento — collegamento degli eventi a un'identità nota e costruzione di un quadro coerente del cliente; (3) Servizio — erogazione del contesto arricchito agli agenti AI e ai sistemi di personalizzazione in tempo reale; (4) Apprendimento — immissione dei risultati di ogni decisione dell'agente nel fondamento dei dati in modo che il sistema migliori continuamente.
Quale infrastruttura dati è necessaria per il processo decisionale in tempo reale? Il processo decisionale in tempo reale richiede quattro capacità fondamentali: raccolta strutturata di eventi con convalida dello schema al momento dell'acquisizione; risoluzione dell'identità a livello di raccolta anziché posticipata; una pipeline dati in grado di servire contemporaneamente contesto in tempo reale e storico; e la disciplina di trattare gli output delle interazioni degli agenti AI come eventi comportamentali di prima classe che rientrano nel sistema.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.