La "Rosetta Stone" della CPS: la libreria di Claroty basata sull'IA
Come un sistema AI multi-agente su Databricks risolve la crisi dell'identità CPS
di Ben Hazan, Anton Berlinsky, Ohad Avni, Itay Wagner, Guy Zalcman , Dor Bdolach, Ravid Ariely e Gal Sberro
- La libreria AI-Powered CPS di Claroty risolve la crisi dell'identità degli asset - dove l'88% dei dispositivi CPS non dispone di un codice prodotto esatto - automatizzando la risoluzione delle entità su oltre 17 milioni di asset industriali e sanitari.
- Un sistema AI multi-agente basato sugli Agenti Personalizzati di Databricks combina agenti NLP e di ragionamento con feedback human-in-the-loop, alimentato da un'Architettura Medallion su Delta Lake, per trasformare i segnali frammentati dei dispositivi in una fonte di verità deterministica.
- Il risultato: solo nell'MVP, abbiamo riscontrato un miglioramento di oltre il 25% nell'accuratezza dell'attribuzione delle vulnerabilità e oltre il 56% dei dispositivi analizzati ha ricevuto nuove raccomandazioni di sicurezza per firmware obsoleti precedentemente invisibili.
La Stele di Rosetta dei CPS: Dentro la Rivoluzionaria Libreria AI di Claroty
Per decenni, il mondo dei sistemi cyber-fisici (CPS) - i macchinari che alimentano le nostre fabbriche, ospedali e infrastrutture critiche - ha sofferto di una silenziosa "crisi d'identità". Mentre un amministratore IT può facilmente identificare ogni laptop sulla propria rete, un team di sicurezza OT (Operational Technology) spesso fatica a sapere esattamente cosa è in funzione nel proprio impianto.
Un recente rapporto del team di ricerca Team82 di Claroty ha rivelato una realtà sconcertante: l'88% degli asset CPS non trasmette un codice prodotto esatto e il 76% utilizza codici prodotto diversi dai registri ufficiali del fornitore. Questa mancanza di un "certificato di nascita digitale" rende la gestione delle vulnerabilità quasi impossibile, poiché i team di sicurezza sono costretti a mettere insieme manualmente le informazioni da risorse incoerenti.
Per risolvere questo problema, Claroty ha recentemente presentato la sua Libreria CPS basata sull'AI, un motore di mappatura autorevole, primo nel suo genere, progettato per essere il "traduttore universale" per l'hardware industriale e sanitario.
Al suo interno, questa è una sfida di Entity Resolution (ER) e lo scopo del sistema è risolvere la crisi d'identità abbinando e consolidando dati rumorosi del mondo reale in un'unica fonte di verità. Per ottenere una tracciabilità deterministica ad alta fedeltà, siamo andati oltre gli algoritmi di abbinamento standard, ingegnerizzando un'architettura ibrida che combina metodi ER classici e collaudati con la potenza cognitiva del Generative AI.
In risposta a un punto dolente critico del settore, abbiamo collaborato con Databricks attraverso il loro programma GenAI MVP. Questa collaborazione sfrutta la nostra offerta specializzata e le capacità Data & AI di Databricks per fornire una soluzione definitiva al problema.
Cosa sembra nella realtà
Immagina una situazione tipica in una fabbrica: Claroty xDome trova un dispositivo con un numero di modello come 1769-L36ERMS/B utilizzando il protocollo CIP. Per una persona o un semplice strumento di sicurezza, questo è solo un codice interno Rockwell Automation, non è presente in alcun database di vulnerabilità e non suggerisce immediatamente alcun rischio.
Per proteggere questo dispositivo, il personale dovrebbe solitamente capire manualmente di cosa si tratta, il che comporta:
- Ricerca sul Web: Consultare i cataloghi Rockwell per scoprire che questo codice corrisponde a un controller Compact GuardLogix 5370.
- Verifica delle Vulnerabilità: Cercare avvisi CISA per quel nome, che potrebbero indicare CVE-2020-6998 come rischio per "versioni 33 e precedenti".
- Conferma dei Dettagli: Controllare il NVD (National Vulnerability Database) per vedere se il CPE (Common Platform Enumeration) specifico corrisponde, solo per trovare una voce generica per "CompactLogix 5370 L3" che potrebbe o meno includere il sottotipo "GuardLogix".
Questo "lavoro investigativo" manuale è spesso il punto in cui la sicurezza fallisce. La Libreria CPS basata sull'AI automatizza l'intero processo. Riconosce istantaneamente il codice interno, lo collega al nome commerciale, identifica le parti specifiche e le versioni del firmware e allega i CVE corretti con precisione definitiva, trasformando una stringa di caratteri confusa in una configurazione chiara e sicura in millisecondi.
Risolvere la Crisi d'Identità con Visibilità Deterministica
La Libreria CPS non è solo un database; è un sistema AI multi-agente che abilita la remediation "dell'ultimo miglio". Collaborando con i giganti del settore, Claroty ha costruito un grafo di evidenze che riconcilia dati di rete disordinati in un'unica fonte di verità.
Principali Innovazioni Includono:
- Tracciabilità Deterministica: Anche quando un dispositivo riporta dati minimi, la libreria utilizza inferenza statistica e logica guidata dal dominio per triangolare la sua identità esatta.
- Attribuzione delle Vulnerabilità: Identificando sottocomponenti specifici e alberi di firmware, la libreria ha migliorato l'accuratezza nell'identificazione delle vulnerabilità del 25%.
- Insight Azionabili: Nei test iniziali, il 56% dei dispositivi analizzati ha ricevuto raccomandazioni di sicurezza nuove o aggiornate per firmware obsoleto che in precedenza erano invisibili ai team di sicurezza.
Sotto il Cofano: Il Motore Databricks Data Intelligence
Per gestire un catalogo globale di oltre 17 milioni di asset e le loro intricate dipendenze, Claroty sfrutta la Databricks Data Intelligence Platform come sua spina dorsale unificata. Adottando un'architettura Lakehouse, Claroty elimina i tradizionali silos di dati, consentendo l'ingestione di dataset diversi - dai protocolli OT proprietari e dalle chiamate API ai manuali PDF dei fornitori non strutturati - in un unico ambiente scalabile. Questa base fornisce il calcolo ad alte prestazioni necessario per eseguire complessi modelli di inferenza statistica su milioni di punti dati, garantendo che ogni CPS-ID (il nuovo standard del settore per l'identità dei sistemi cyber-fisici di Claroty) sia supportato da una rigorosa integrità dei dati e da un'intelligenza inter-silo.
Data Engineering su Scala: La Pipeline Medallion
Ad alimentare questo ecosistema è una robusta Architettura Medallion costruita su Delta Lake e governata in Unity Catalog. Il viaggio inizia nello strato Bronze, dove payload JSON grezzi ed eterogenei vengono acquisiti in tabelle Delta append-only. Da lì, una pipeline di promozione - leggendo dal Delta Change Data Feed (CDF) - applica dinamicamente un registro di mappatura per trasformare le evidenze grezze in uno schema canonico governato. Utilizzando l'evoluzione dello schema e il time travel di Delta Lake, Claroty mantiene una catena di custodia ininterrotta; ogni record di asset è tracciabile fino al suo artefatto grezzo originale e alla specifica versione di mappatura che lo ha classificato, garantendo la completa auditabilità anche negli ambienti industriali più sensibili.
Intelligenza Multi-Agente tramite Agenti Personalizzati di Databricks
La parte più sofisticata di questo motore ibrido è l'uso degli Agenti Personalizzati di Databricks. Invece di fare affidamento su un singolo modello monolitico, Claroty ha progettato un Sistema Orchestrato Multi-Agente, una rete sincronizzata in cui agenti AI specializzati collaborano per interpretare segnali complessi.
Per alimentare questi agenti con un contesto affidabile, combiniamo l'analisi statistica classica di dati strutturati raccolti da fonti proprietarie con tecniche NLP avanzate che estraggono segnali dal rumore intrinseco nella documentazione dei fornitori, nelle schede tecniche e nelle fonti web aperte. Unity Catalog di Databricks fornisce la base dati governata necessaria per unificare questi diversi dataset, mentre le pipeline basate su Spark elaborano e normalizzano le informazioni su larga scala. Insieme, queste capacità sintetizzano informazioni frammentate e incoerenti nelle risposte precise e contestualizzate di cui gli agenti hanno bisogno per fornire abbinamenti accurati di entity resolution.
Il sistema è costruito attorno a tre componenti principali:
- Agenti NLP: Analizzano dati complessi e in formato misto - incluse stringhe di denominazione derivate da protocolli e oscuri marcatori software che i modelli standard spesso non colgono.
- Agenti di Ragionamento: Applicano punteggi di confidenza e test statistici per pesare le evidenze, discriminando segnali ad alta fedeltà dal rumore per garantire l'integrità dei dati.
- Human-in-the-loop (HITL): Un meccanismo di feedback critico che segnala mappature a bassa confidenza per la revisione da parte di esperti. L'output di queste sessioni viene reimmesso nel sistema, riaddestrando i modelli per continui miglioramenti dell'accuratezza.
Innovazione attraverso le Capacità di Databricks
Il successo di questa architettura non risiede solo negli agenti stessi, ma nell'ecosistema end-to-end basato su Databricks che li alimenta. Abbiamo sfruttato l'intera piattaforma per passare da MVP alla produzione con velocità e affidabilità:
1. Intelligenza Specifica del Dominio tramite Model Serving Per affrontare le sfumature della sanità e dell'OT, gli embedding generici erano insufficienti per il livello di precisione richiesto. Abbiamo identificato che affinché il "Traduttore Universale" abbia veramente successo, le architetture RAG generiche devono evolvere in framework specifici del dominio. Attualmente colmiamo questo divario distribuendo modelli di embedding medici best-in-class come endpoint personalizzati utilizzando Databricks Model Serving. Tuttavia, guardando al futuro, vediamo il fine-tuning di questi modelli come il passo logico successivo per garantire che i nostri agenti comprendano i dialetti industriali più oscuri con precisione deterministica.
2. RAG Avanzato ed Estrazione di Informazioni Abbiamo sfruttato il Knowledge Assistant per costruire robusti sistemi RAG (Retrieval-Augmented Generation) in grado di ingerire vaste quantità di documentazione proprietaria. Utilizzando un agente di Information Extraction, possiamo analizzare strutturalmente documenti proprietari non strutturati, trasformando il testo grezzo in intelligenza azionabile per la Libreria CPS.
3. Gestione del Ciclo di Vita Completo con MLflow che funge da spina dorsale del nostro ciclo di vita di sviluppo ML, fornendo una piattaforma unificata dalla fase MVP iniziale fino alla valutazione rigorosa e al deployment finale.
- Valutazione Continua: Abbiamo implementato una strategia di valutazione completa utilizzando "LLM come Giudice" insieme a sessioni di etichettatura manuale. Le funzionalità di MLflow ci hanno permesso di valutare costantemente le prestazioni del modello per prevenire il concept drift.
- Osservabilità e Monitoraggio: In produzione, utilizziamo le funzionalità di osservabilità di MLflow per monitorare lo stato dell'agente in tempo reale. Ciò include il monitoraggio dell'utilizzo dei token e dei costi dell'infrastruttura, l'identificazione dei colli di bottiglia della latenza e il rilevamento di potenziali bug prima che influiscano sugli utenti. Un'area di attenzione strategica è l'efficienza dei costi dei nostri indici di AI Search. Sebbene le prestazioni siano di livello mondiale, l'attuale mancanza di un modello "scale-to-zero" per gli endpoint vettoriali—una sfumatura particolarmente rilevante per la natura intermittente e guidata dagli eventi dei dati di sicurezza industriale—ci impone di progettare specifici pattern architetturali per mantenere un ROI elevato durante i periodi di inattività.
Fusing metodi classici di Entity Resolution con una strategia sofisticata e orchestrata multi-agente—supportata dall'infrastruttura robusta di Databricks—abbiamo creato un livello di intelligenza auto-migliorante, efficiente in termini di costi e altamente accurato. Questo sistema colma finalmente il divario tra dati di rete disordinati e l'unica fonte di verità, risolvendo la crisi d'identità per la sicurezza CPS.
Automazione tramite Jobs, Pipelines e LLM
Per gestire la vasta quantità di informazioni provenienti da varie fonti, Claroty utilizza Lakeflow Jobs per orchestrare l'intero processo, dai dati grezzi a una tabella ben strutturata.
Una delle nostre pipeline orchestra un processo ETL che analizza CSAF, un advisory di sicurezza in formato JSON, in una struttura tabellare. In questo processo, ogni passaggio legge e scrive voci in una delta table dedicata.
In questo ETL, e in molti altri casi d'uso, utilizziamo gli LLM per arricchire i dati - da attività di classificazione e AI Functions come ai_query, utilizzando vari Serving endpoints e MLflow per valutare le risposte che otteniamo dall'LLM, utilizzando metriche statistiche e LLM-as-a-judge, e monitorando i costi.
Per mantenere questa pipeline affidabile su larga scala, utilizziamo un approccio LLM as a Judge per valutare continuamente la qualità delle nostre stesse output LLM. Invece di fare affidamento solo su ground truth completamente etichettati—che spesso mancano o sono ambigui nei dati CPS del mondo reale—lasciamo che un modello giudice dedicato esamini la risposta di un altro modello e decida se sembra accettabile. Il compito del giudice è semplice e conservativo: contrassegnare ogni risultato come pass, sembra corretto, fail, sembra sbagliato, o unknown, non abbastanza informazioni. Tutti questi giudici sono archiviati in una Delta table. Utilizzando questo metodo, i nostri team possono caricare campioni di valutazione, avviare custom MLflow GenAI judges ed eseguire valutazioni strutturate. Le capacità native di monitoraggio MLflow GenAI ci offrono un modo coerente per monitorare la qualità, confrontare le versioni e individuare regressioni in molti casi d'uso LLM, senza dover costruire uno stack di valutazione personalizzato per ogni nuovo workflow.
Integrità Transazionale con Lakebase
Affinché la "Library" funzioni, i dati devono essere coerenti e altamente disponibili. Claroty integra Lakebase, un livello dati transazionale completamente gestito su Databricks. Lakebase è costruito su Postgres e fornisce le prestazioni a bassa latenza richieste per le query in tempo reale, mantenendo un collegamento trasparente con il Lakehouse più ampio per l'elaborazione analitica, consentendo vincoli rigorosi per garantire che i nostri dati mantengano la loro alta qualità e assicurando che le mappature degli asset rimangano accurate anche quando le configurazioni cambiano.
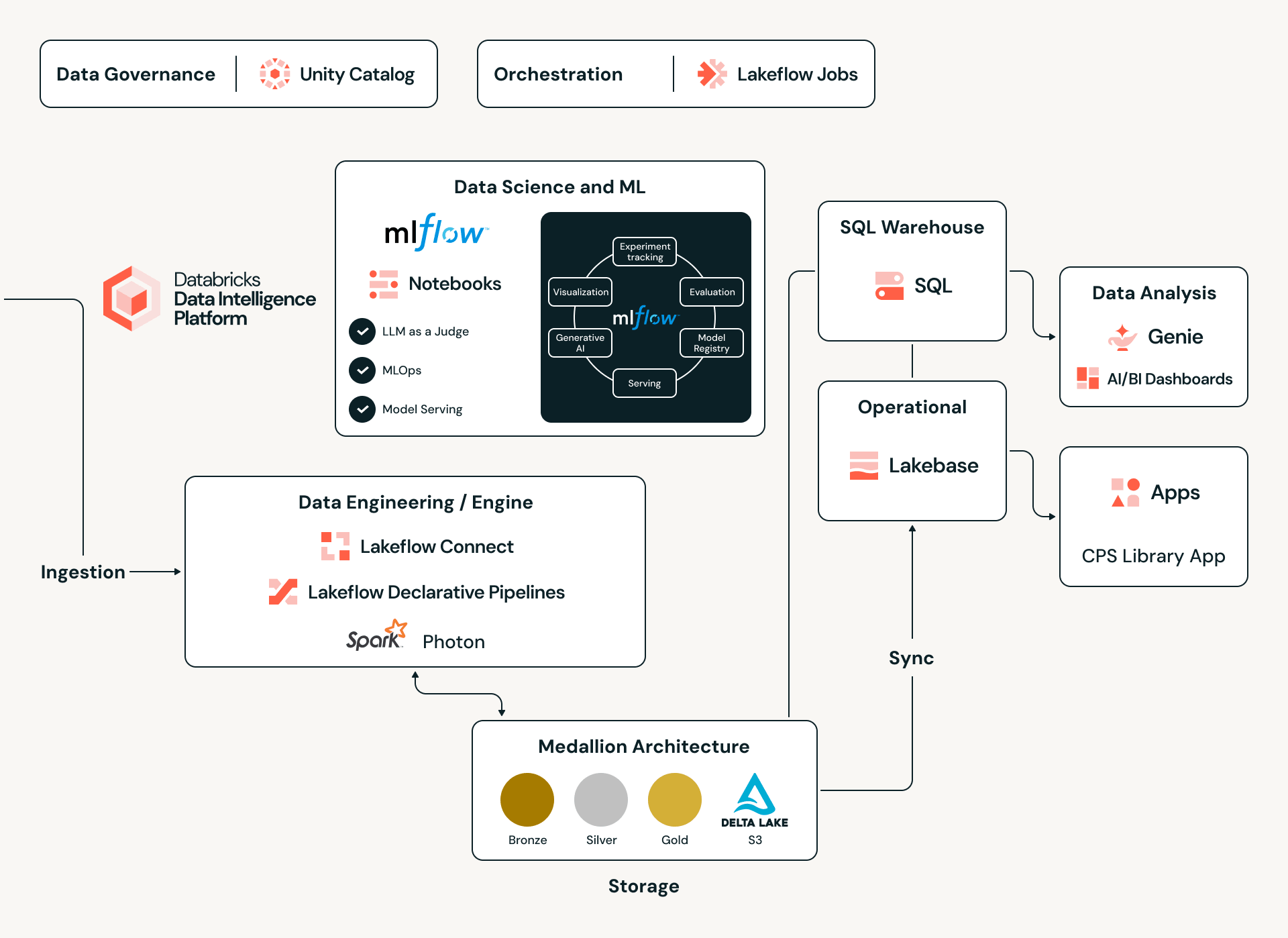
Innovazione Rapida con Databricks Apps
Per riunire tutte queste informazioni, utilizziamo Databricks Apps, una funzionalità che consente a Claroty di creare e distribuire applicazioni full-stack e data-intensive direttamente all'interno dell'ambiente Databricks. Utilizzando framework UI moderni (come React o Streamlit) per il frontend e Lakebase, il database OLTP Postgres completamente gestito da Databricks, per i carichi di lavoro transazionali, possiamo ospitare sia la logica dell'applicazione che i dati operativi sulla stessa piattaforma del nostro lakehouse. Ciò significa che l'applicazione eredita la sicurezza integrata della piattaforma, la governance e l'autenticazione (tramite Unity Catalog e OAuth), eliminando la necessità di server di app, database e pipeline di distribuzione separati. Ciò che tradizionalmente richiederebbe l'unione di più stack tecnologici e servizi è consolidato in una soluzione singola, conveniente e robusta.
Human-in-the-Loop tramite Databricks Apps
Mentre le nostre pipeline AI automatizzano il lavoro pesante, la principale esigenza sul campo per creare fiducia è il feedback degli SME human-in-the-loop. Con Databricks App e Lakebase, abilitiamo una visione trasparente e un ciclo di feedback "human-in-the-loop" senza interruzioni. Questa interfaccia intuitiva consente agli esperti di dominio di rivedere le classificazioni, correggere e arricchire le entità, e reintrodurre dati ad alta fedeltà e validati nelle nostre pipeline MLflow e nella migrazione R&D, garantendo che il sistema diventi più intelligente e accurato nel tempo.
Il Futuro della Resilienza
Combinando la profonda competenza di dominio di Claroty nei protocolli OT con la potenza della piattaforma Databricks, la CPS Library sta stabilendo un nuovo standard. Non si tratta più solo di vedere che un dispositivo esiste, ma di sapere esattamente cos'è, quali rischi comporta e come risolverlo con totale sicurezza.
La leadership di Claroty in questo settore è stata recentemente convalidata dalla sua nomina a Leader nel Gartner® Magic Quadrant™ 2025 per le Piattaforme di Protezione CPS, posizionata più in alto per "Ability to Execute". Man mano che il settore avanza, questo approccio "identity-first" sarà il fondamento per migliorare la resilienza in ogni ambiente connesso.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.