Semplifica l'ingestione dei dati con la nuova API Python per origini dati
Questo blog esplora come la nuova API Python Data Source di Spark semplifica l'ingestione dei dati IoT.
I team di data engineering hanno spesso il compito di creare soluzioni di ingestione personalizzate per una miriade di origini dati personalizzate, proprietarie o specifiche del settore. Molti team scoprono che questo lavoro di creazione di soluzioni di ingestione è macchinoso e richiede tempo. Riconoscendo queste sfide, abbiamo intervistato numerose aziende di diversi settori per comprendere meglio le loro diverse esigenze di integrazione dei dati. Questo feedback completo ci ha portato allo sviluppo della Python Data Source API per Apache Spark™.
Uno dei clienti con cui abbiamo lavorato a stretto contatto è Shell. I guasti alle apparecchiature nel settore energetico possono avere conseguenze significative, incidendo sulla sicurezza, sull'ambiente e sulla stabilità operativa. In Shell, minimizzare questi rischi è una priorità, e un modo per farlo è concentrarsi sul funzionamento affidabile delle apparecchiature.
Shell possiede una vasta gamma di asset e apparecchiature di capitale del valore di oltre 180 miliardi di dollari. Per gestire le enormi quantità di dati generate dalle operazioni di Shell, si affidano a strumenti avanzati che migliorano la produttività e consentono ai loro team di dati di lavorare senza interruzioni su varie iniziative. La Databricks Data Intelligence Platform svolge un ruolo cruciale democratizzando l'accesso ai dati e promuovendo la collaborazione tra analisti, ingegneri e scienziati di Shell. Tuttavia, l'integrazione dei dati IoT ha posto delle sfide per alcuni casi d'uso.
Utilizzando il nostro lavoro con Shell come esempio, questo blog esplorerà come questa nuova API affronta le sfide precedenti e fornirà codice di esempio per illustrarne l'applicazione.
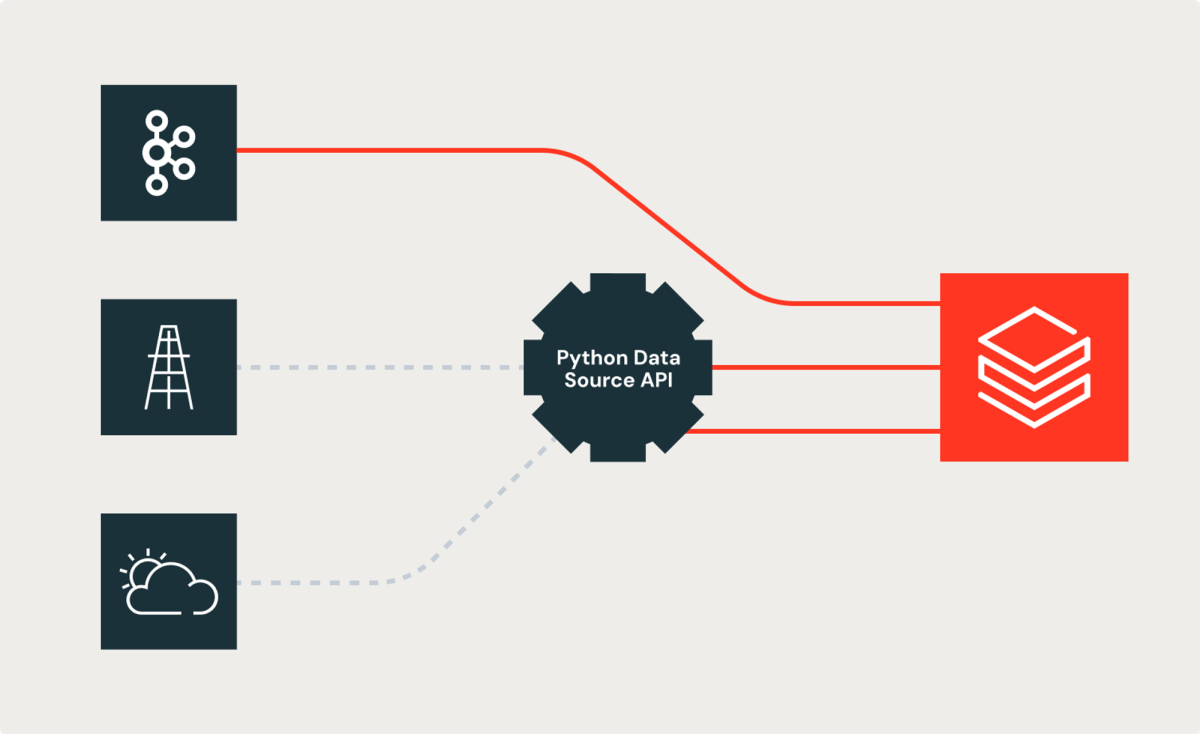
La sfida
Innanzitutto, diamo un'occhiata alla sfida che gli ingegneri dei dati di Shell hanno riscontrato. Sebbene molte origini dati nelle loro pipeline di dati utilizzino sorgenti Spark integrate (ad esempio, Kafka), alcune si basano su API REST, SDK o altri meccanismi per esporre i dati ai consumatori. Gli ingegneri dei dati di Shell hanno lottato con questo fatto. Hanno finito per creare soluzioni personalizzate per unire i dati dalle sorgenti Spark integrate con i dati provenienti da queste origini. Questa sfida ha consumato tempo ed energia agli ingegneri dei dati. Come spesso accade nelle grandi organizzazioni, tali implementazioni personalizzate introducono incoerenze nelle implementazioni e nei risultati. Bryce Bartmann, Chief Digital Technology Advisor di Shell, desiderava semplicità, dicendoci: "Scriviamo molte API REST interessanti, anche per casi d'uso di streaming, e vorremmo semplicemente usarle come origine dati in Databricks invece di scrivere noi stessi tutto il codice di collegamento.".
“Scriviamo molte API REST interessanti, anche per casi d'uso di streaming, e vorremmo semplicemente usarle come origine dati in Databricks invece di scrivere noi stessi tutto il codice di collegamento.”- Bryce Bartmann, Chief Digital Technology Advisor, Shell
La soluzione
La nuova API Python per sorgenti dati personalizzate allevia il problema consentendo di affrontare il problema utilizzando concetti orientati agli oggetti. La nuova API fornisce classi astratte che consentono al codice personalizzato, come le ricerche basate su API REST, di essere incapsulato e reso disponibile come un'altra sorgente o destinazione Spark.
Gli ingegneri dei dati desiderano semplicità e componibilità. Ad esempio, immagina di essere un ingegnere dei dati e di voler ingerire dati meteorologici nella tua pipeline di streaming. Idealmente, vorresti scrivere codice che assomigli a questo:
Quel codice sembra semplice ed è facile da usare per gli ingegneri dei dati perché hanno già familiarità con la DataFrame API. In precedenza, un approccio comune per accedere a un'API REST in un processo Spark era utilizzare un PandasUDF. Questo articolo mostra quanto possa essere complicato scrivere codice riutilizzabile in grado di inviare dati a un'API REST utilizzando un Pandas UDF. La nuova API, d'altra parte, semplifica e standardizza il modo in cui i processi Spark – in streaming o batch, destinazione o sorgente – lavorano con sorgenti e destinazioni non native.
Successivamente, esaminiamo un esempio del mondo reale e mostriamo come la nuova API ci consente di creare una nuova origine dati ("weather" in questo esempio). La nuova API fornisce funzionalità per sorgenti, destinazioni, batch e streaming e l'esempio seguente si concentra sull'utilizzo della nuova API di streaming per implementare una nuova sorgente "weather".
Utilizzo della Python Data Source API – uno scenario del mondo reale
Immagina di essere un ingegnere dei dati incaricato di costruire una pipeline di dati per un caso d'uso di manutenzione predittiva che richiede dati di pressione dalle apparecchiature di testa pozzo. Supponiamo che le metriche di temperatura e pressione della testa pozzo fluiscano attraverso Kafka dai sensori IoT. Sappiamo che Structured Streaming ha un supporto nativo per l'elaborazione dei dati da Kafka. Fin qui tutto bene. Tuttavia, i requisiti aziendali presentano una sfida: la stessa pipeline di dati deve anche acquisire i dati meteorologici relativi al sito della testa pozzo, e questi dati non stanno fluendo tramite Kafka ma sono invece accessibili tramite un'API REST. Gli stakeholder aziendali e gli scienziati dei dati sanno che il tempo influisce sulla durata e sull'efficienza delle apparecchiature, e questi fattori influiscono sui programmi di manutenzione delle apparecchiature.
Iniziare in modo semplice
La nuova API fornisce un'opzione semplice adatta a molti casi d'uso: l'API SimpleDataSourceStreamReader. L'API SimpleDataSourceStreamReader è appropriata quando l'origine dati ha un basso throughput e non richiede partizionamento. La utilizzeremo in questo esempio perché abbiamo bisogno solo di letture di dati meteorologici per un numero limitato di siti di testa pozzo e la frequenza delle letture meteorologiche è bassa.
Diamo un'occhiata a un semplice esempio che utilizza l'API SimpleDataSourceStreamReader.
Spiegheremo un approccio più complicato in seguito. L'altro approccio, più complesso, è ideale quando si costruisce una sorgente dati Python consapevole del partizionamento. Per ora, non ci preoccuperemo di cosa significhi. Invece, mostreremo un esempio che utilizza l'API semplice.
Esempio di codice
L'esempio di codice seguente presuppone che l'API "semplice" sia sufficiente. Il metodo __init__ è essenziale perché è così che la classe reader (WeatherSimpleStreamReader di seguito) comprende i siti di testa pozzo che dobbiamo monitorare. La classe utilizza un'opzione "locations" per identificare le posizioni da cui emettere informazioni meteorologiche.
Ora che abbiamo definito la classe reader semplice, dobbiamo integrarla in un'implementazione della classe astratta DataSource.
Ora che abbiamo definito la DataSource e integrato un'implementazione del reader in streaming, dobbiamo registrare la DataSource con la sessione Spark.
Ciò significa che la sorgente dati meteorologica è una nuova sorgente in streaming con le familiari operazioni DataFrame con cui gli ingegneri dei dati hanno familiarità. Questo punto merita di essere sottolineato perché queste sorgenti dati personalizzate vanno a beneficio dell'intero team. Con un approccio più orientato agli oggetti, il team più ampio dovrebbe beneficiare di questa sorgente dati qualora avesse bisogno di dati meteorologici come parte del proprio caso d'uso. Pertanto, gli ingegneri dei dati potrebbero voler estrarre le sorgenti dati personalizzate in una libreria wheel Python per il riutilizzo in altre pipeline.
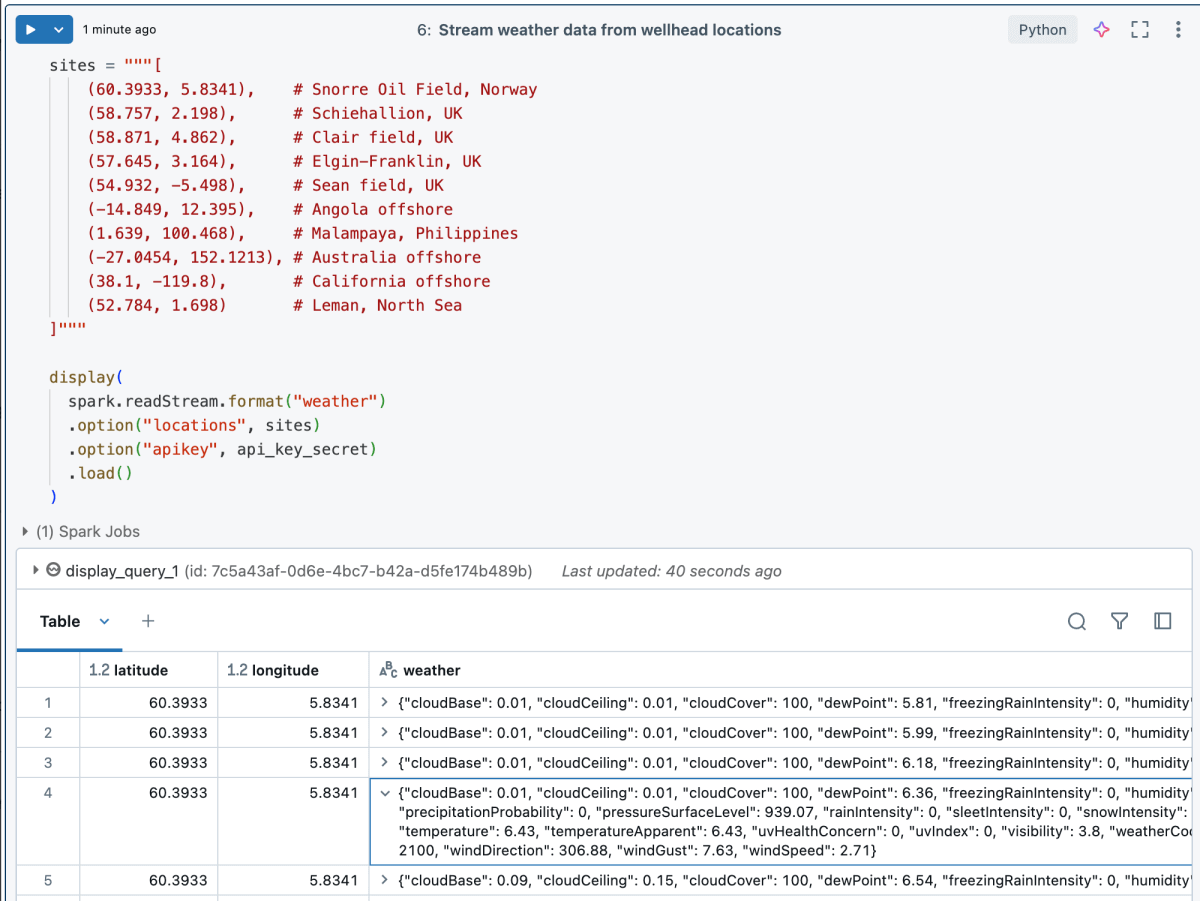
Di seguito, vediamo quanto è facile per l'ingegnere dei dati sfruttare lo stream personalizzato.
Risultati di esempio:
Altre considerazioni
Quando usare l'API partition-aware
Ora che abbiamo esaminato l'API "semplice" del Data Source Python, spiegheremo un'opzione per la consapevolezza delle partizioni. Le sorgenti dati partition-aware consentono di parallelizzare la generazione dei dati. Nel nostro esempio, un'implementazione di sorgente dati partition-aware comporterebbe la divisione delle posizioni tra più task in modo che le chiamate API REST possano distribuirsi tra i worker e il cluster. Ancora una volta, il nostro esempio non include questa sofisticazione perché il volume di dati previsto è basso.
API Batch vs. Stream
A seconda del caso d'uso e della necessità che l'API generi lo stream di origine o riceva i dati, è necessario concentrarsi sull'implementazione di metodi diversi. Nel nostro esempio, non ci preoccupiamo di ricevere dati. Avremmo anche dovuto includere l'implementazione del reader batch. Tuttavia, puoi concentrarti sull'implementazione delle classi necessarie nel tuo caso d'uso specifico.
| sorgente | sink | |
|---|---|---|
| batch | reader() | writer() |
| streaming | streamReader() o simpleStreamReader() | streamWriter() |
Quando usare le API Writer
Questo articolo si è concentrato sulle API Reader utilizzate in readStream. Le API writer consentono una logica arbitraria simile sul lato di output della pipeline di dati. Ad esempio, supponiamo che i responsabili delle operazioni presso il sito del pozzo desiderino che la pipeline di dati chiami un'API nel sito del pozzo che mostri uno stato dell'attrezzatura rosso/giallo/verde che sfrutta la logica della pipeline. L'API Writer consentirebbe agli ingegneri dei dati la stessa opportunità di incapsulare la logica ed esporre una sink di dati che opererebbe come i familiari formati writeStream.
Conclusione
"La semplicità è la massima sofisticazione." - Leonardo da Vinci
Come architetti e ingegneri dei dati, ora abbiamo l'opportunità di semplificare i carichi di lavoro batch e in streaming utilizzando l'API delle sorgenti dati personalizzate PySpark. Man mano che trovate opportunità per nuove sorgenti dati che andrebbero a beneficio dei vostri team di dati, considerate di separare le sorgenti dati per il riutilizzo in tutta l'azienda, ad esempio, tramite l'uso di una libreria wheel Python.
L'API Python Data Source è esattamente ciò di cui avevamo bisogno. Offre un'opportunità ai nostri ingegneri dei dati di modularizzare il codice necessario per interagire con le nostre API REST e SDK. Il fatto che ora possiamo creare, testare e fornire sorgenti dati Spark riutilizzabili in tutta l'organizzazione aiuterà i nostri team a muoversi più velocemente e ad avere maggiore fiducia nel loro lavoro."- Bryce Bartmann, Chief Digital Technology Advisor, Shell
In conclusione, l'API Python per le origini dati di Apache Spark™ è un'aggiunta potente che affronta sfide significative precedentemente incontrate dagli ingegneri dei dati che lavorano con origini e destinazioni dati complesse, in particolare nei contesti di streaming. Sia che si utilizzi l'API "semplice" o quella consapevole delle partizioni, gli ingegneri hanno ora gli strumenti per integrare in modo efficiente una gamma più ampia di origini e destinazioni dati nelle loro pipeline Spark. Come dimostrato dalla nostra analisi e dal codice di esempio, implementare e utilizzare questa API è semplice, consentendo rapidi successi per la manutenzione predittiva e altri casi d'uso. La documentazione di Databricks (e la documentazione Open Source) spiegano l'API in modo più dettagliato, e diversi esempi di origini dati Python sono disponibili qui.
Infine, l'enfasi sulla creazione di origini dati personalizzate come componenti modulari e riutilizzabili non può essere sottovalutata. Astrando queste origini dati in librerie autonome, i team possono promuovere una cultura di riutilizzo del codice e collaborazione, migliorando ulteriormente la produttività e l'innovazione. Mentre continuiamo a esplorare e spingere i confini di ciò che è possibile con i big data e l'IoT, tecnologie come l'API Python per le origini dati svolgeranno un ruolo fondamentale nel plasmare il futuro del processo decisionale basato sui dati nel settore energetico e oltre.
Se sei già un cliente Databricks, prendi e modifica uno di questi esempi per sbloccare i tuoi dati che si trovano dietro un'API REST. Se non sei ancora un cliente Databricks, inizia gratuitamente e prova uno degli esempi oggi stesso.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.