L'AI di TabPFN accelera la trasformazione aziendale su Databricks
Scopri come TabPFN su Databricks accelera le previsioni di ML su dati strutturati, elimina i cicli di riaddestramento e scala l'AI nelle principali attività operative con una governance completa.
di Dominik Safari, Philipp Singer, Diana Kriuchkova, Sauraj Gambhir, Ryuta Yoshimatsu , Bryan Smith e Dael Williamson
- Perché i flussi di lavoro di ML classico rimangono complessi e ad alta intensità di risorse e come TabPFN cambia radicalmente questa situazione
- In che modo Databricks consente ai team di creare, implementare e governare le previsioni di TabPFN direttamente accanto ai dati Lakehouse
- Il valore aziendale sbloccato: time-to-prediction più rapido, riduzione dell'overhead di data science e più ampia adozione del ML nelle attività operative principali
Oggi è difficile trovare una rivista di settore, una conferenza stampa sugli utili trimestrali, un white paper o una presentazione sulla strategia di trasformazione aziendale che non sia incentrata sull'intelligenza artificiale (AI). L'AI moderna rappresenta un cambiamento fondamentale nel modo in cui le organizzazioni approcciano il consumo, l'interpretazione e la generazione di contenuti, consentendo alle aziende di potenziare e automatizzare un'ampia gamma di attività che in precedenza richiedevano una profonda competenza e anni di conoscenza specialistica.
Ma nonostante tutta l'attenzione riscossa dalla capacità dell'AI di comprendere e produrre contenuti non strutturati, ad es., testi, immagini, audio, ecc., moltissimi processi aziendali di base si affidano da tempo al Machine Learning (ML) classico, una tecnologia diversa ma correlata, che produce etichette predittive da input di dati strutturati (Figura 1). Finora, il potere trasformativo dell'AI ha lasciato il ML classico sostanzialmente invariato.
La persistenza dei flussi di lavoro di ML tradizionali deriva dalla loro complessità intrinseca e dall'intensità del lavoro. I data scientist dedicano abitualmente più dell'80% del loro tempo ad attività che si svolgono ancora prima dell'addestramento del modello: preparazione e convalida di input di dati strutturati, ingegneria delle feature e selezione della classe di modelli più adatta. Inoltre, poiché le distribuzioni dei dati sottostanti cambiano e le prestazioni del modello peggiorano nel tempo, questo lavoro non è un investimento una tantum, ma un ciclo continuo di monitoraggio, debug e riaddestramento.
Su larga scala, questa sfida si intensifica. Le organizzazioni che implementano centinaia, se non migliaia, di modelli di ML si affidano a framework di sperimentazione automatizzata per valutare migliaia di combinazioni di parametri. Ma anche l'automazione non può superare i vincoli fondamentali delle risorse.
La realtà è dura: le aziende devono scegliere quali modelli ottimizzare e quali funzionano "abbastanza bene", date le risorse limitate e la necessità di ottenere rapidamente risultati di business. Tuttavia, l'emergere di nuovi modelli di IA incentrati su input di dati strutturati e output predittivi potrebbe finalmente offrire una via da seguire.
Video 1. Interazione con il modello TabPFN come parte dell'acceleratore di soluzioni Databricks
Presentazione di TabPFN, un modello di AI per il Machine Learning
Uno degli sviluppi più promettenti in questo campo è TabPFN, un modello di base (AI) di Prior Labs che reinventa radicalmente il flusso di lavoro del Machine Learning (ML) per i dati strutturati. A differenza degli approcci di ML tradizionali, che richiedono la creazione e l'addestramento di un modello unico per ogni attività di previsione, TabPFN applica lo stesso paradigma "pre-addestrato, pronto all'uso" degli LLM ai dati aziendali tabulari. Il modello è stato pre-addestrato su oltre 130 milioni di set di dati sintetici, di fatto, "imparando a imparare" dai dati strutturati in quasi tutti i domini o casi d'uso (Figura 1).
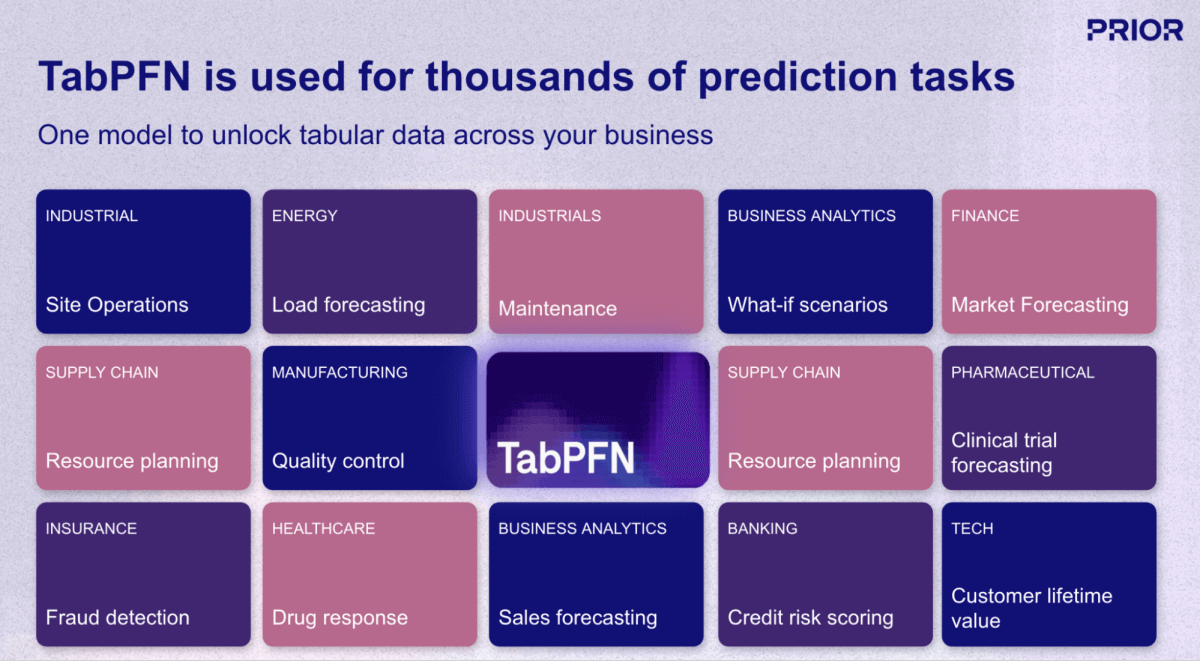
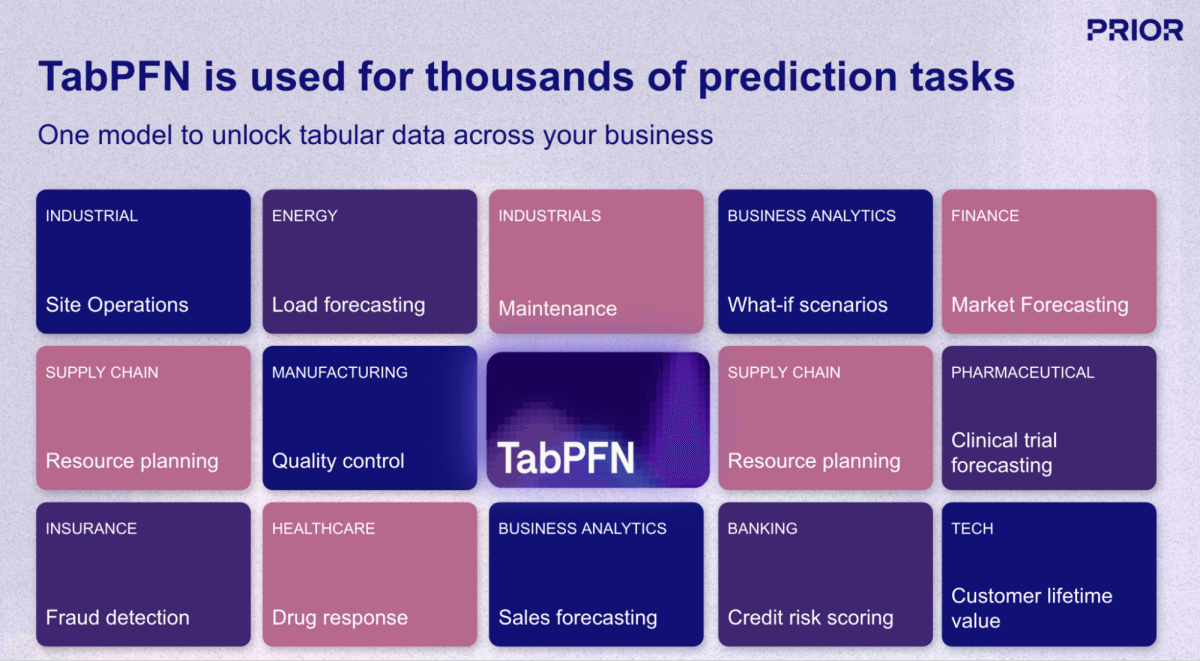{kind=link}
Comprimere la timeline del ML
Le implicazioni per la produttività del ML sono notevoli. Mentre gli approcci tradizionali richiedono ai data scientist di investire ore o giorni nella preparazione dei dati, nell'ingegneria delle funzionalità, nella selezione del modello e nell'ottimizzazione degli iperparametri, TabPFN fornisce previsioni di livello produttivo in un unico passaggio in avanti, generalmente misurato in secondi.
Il modello gestisce direttamente gli input grezzi, gestendo automaticamente i valori mancanti, i tipi di dati misti, le feature categoriche e testuali e gli outlier, senza richiedere l'ampia pre-elaborazione che in genere richiede la maggior parte dello sforzo della data science. L'aspetto forse più significativo è che TabPFN elimina l'onere della manutenzione continua legata al riaddestramento del modello: man mano che nuovi dati diventano disponibili, le organizzazioni aggiornano semplicemente il contesto del modello anziché avviare un nuovo ciclo di addestramento.
Prestazioni senza compromessi
TabPFN supera l'accuratezza dei metodi tradizionali che richiedono ore di ottimizzazione automatizzata. Questo profilo di prestazioni altera radicalmente l'aspetto economico descritto in precedenza: le organizzazioni non devono più affrontare una scelta binaria tra l'accuratezza del modello e l'allocazione delle risorse. Possono invece implementare rapidamente funzionalità predittive in una gamma più ampia di casi d'uso senza dover scalare proporzionalmente i loro team di data science, democratizzando il ML oltre la manciata di applicazioni di maggior valore che in genere giustificano sforzi di ottimizzazione dedicati (Figura 2).
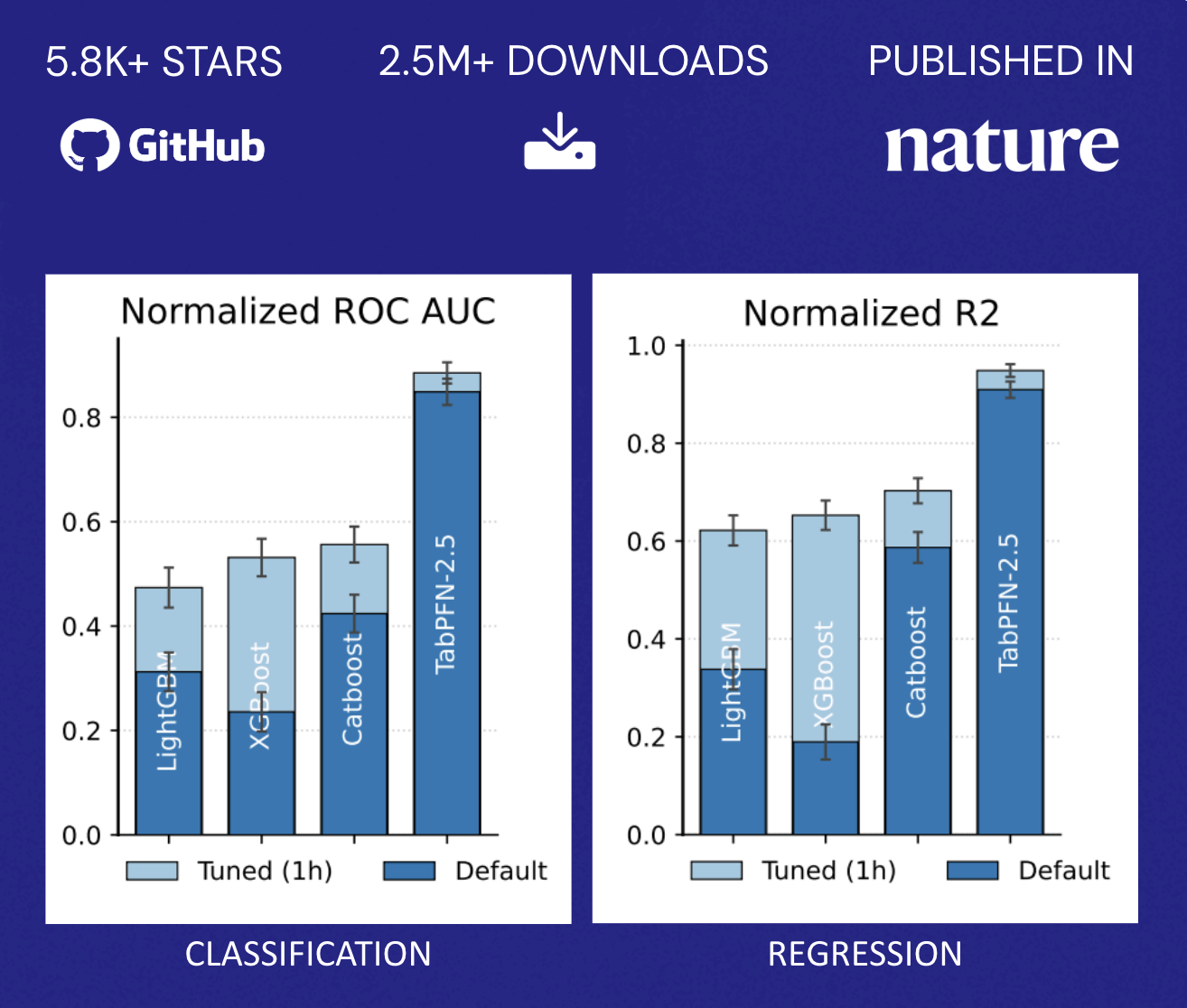
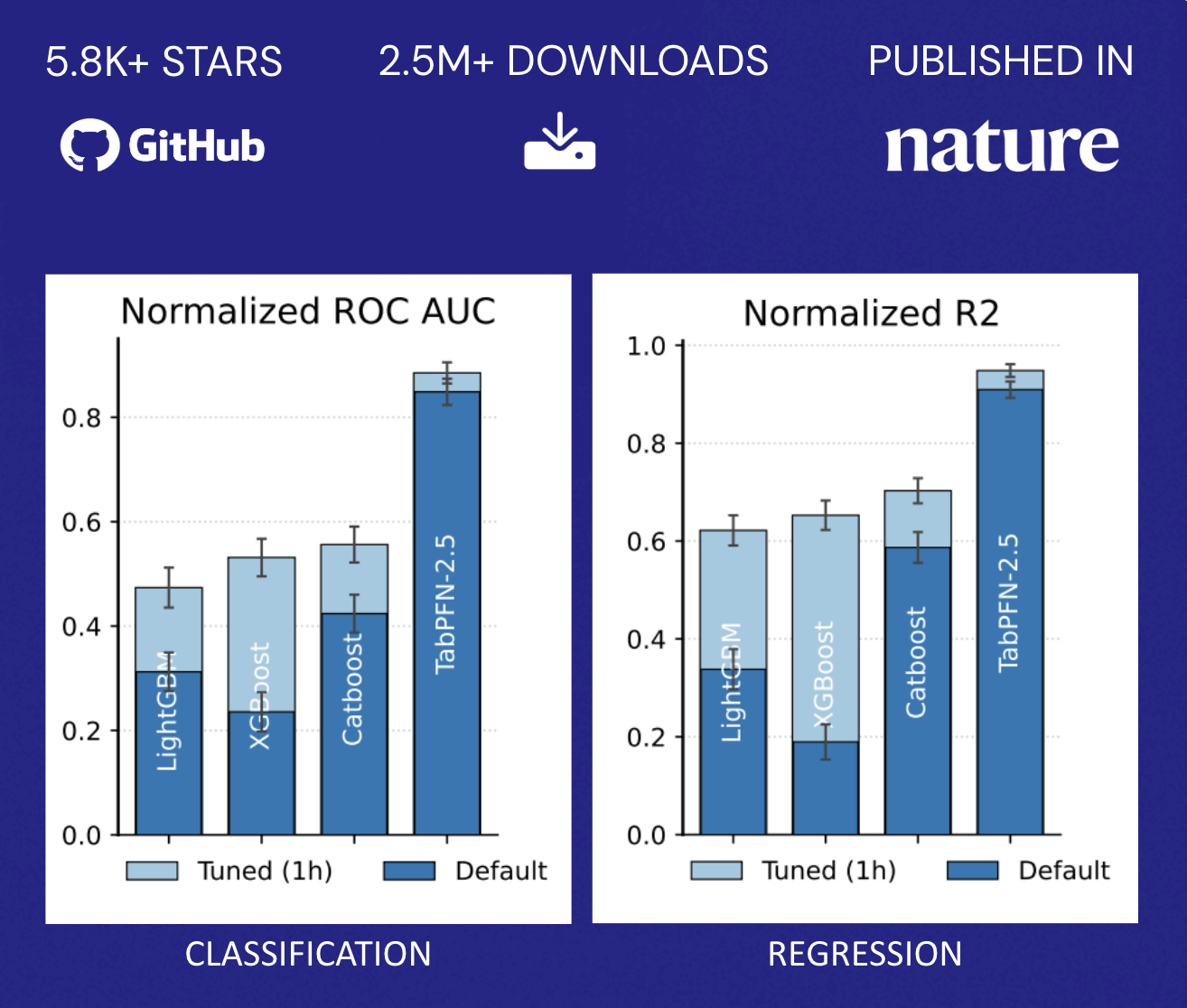{kind=link}
Scalare l'impatto dell'IA sulla previsione strutturata
Attualmente TabPFN supporta set di dati fino a 100.000 righe e 2.000 feature, con versioni enterprise che si estendono fino a 10 milioni di righe, coprendo la stragrande maggioranza dei casi d'uso operativi di ML nei settori retail, finanziario, sanitario, manifatturiero e in altri settori industriali. Per le organizzazioni che cercano di rendere operativa l'IA al di là della generazione di contenuti e delle attività in linguaggio naturale, i modelli di base (foundation model) come TabPFN rappresentano il tassello mancante, apportando gli stessi miglioramenti di produttività a gradino (step-function) ai dati strutturati e all'analisi predittiva che da tempo costituiscono la spina dorsale del processo decisionale basato sui dati (Figura 3).
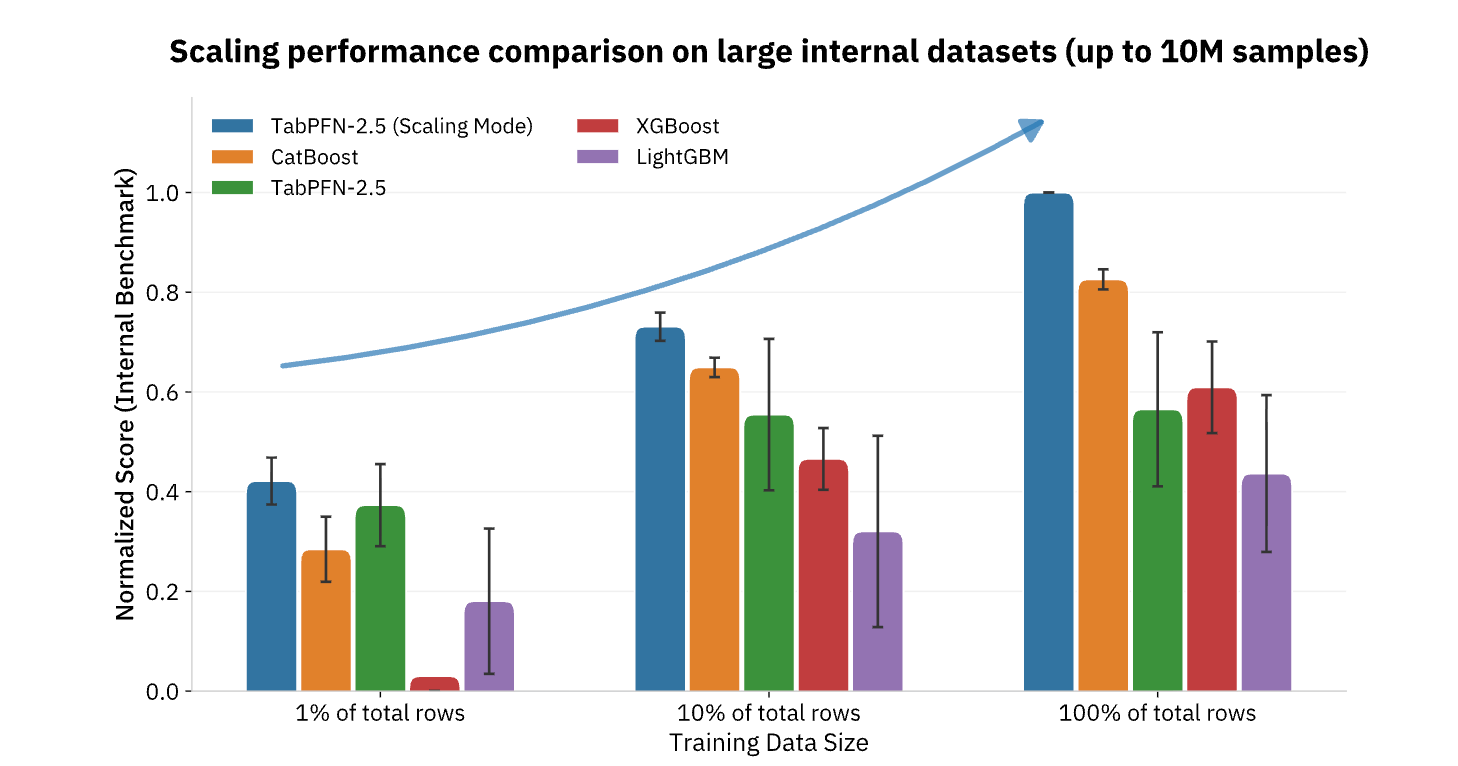
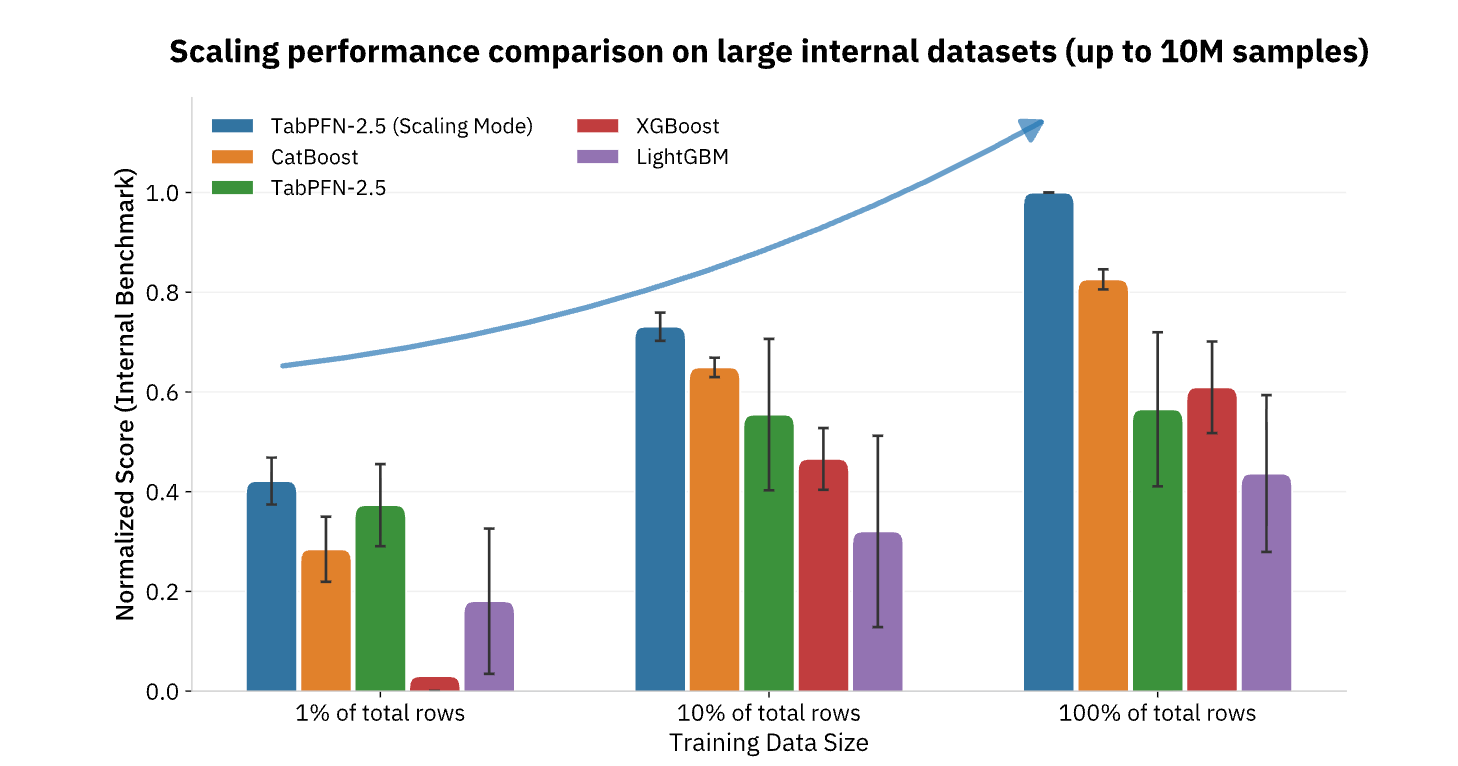{kind=link}
TabPFN sta già alimentando molte applicazioni reali per aziende di tutto il mondo. Le implementazioni in vari settori, dalla gestione del rischio finanziario con Taktile, alla valutazione degli esiti sanitari con NHS, e alla manutenzione predittiva con Hitachi, hanno registrato un notevole incremento, sia in termini di efficienza che di qualità dei risultati. TabPFN supera costantemente i metodi di ML tradizionali, migliorando la baseline del 10%-65% e accelerando i flussi di lavoro di data science del 90%. Le organizzazioni stanno ottenendo maggiori ricavi, migliori esiti sanitari, risparmi sui costi di manutenzione, prevenzione del churn e molto altro ancora.
Utilizzo di TabPFN con Databricks
Databricks è da tempo la piattaforma preferita per i data scientist che desiderano creare capacità predittive con il Machine Learning (ML). In quanto piattaforma aperta, TabPFN è ideale per l'uso all'interno della Databricks Platform.
Crea dove risiedono i dati
La maggior parte del ML classico aziendale parte dai dati Lakehouse: transazioni, telemetria operativa, eventi dei clienti, segnali di inventario e indicatori di rischio. Lo spostamento di tali dati in ambienti esterni rallenta i team creando duplicazioni, aumentando i rischi per la sicurezza e indebolendo la riproducibilità e la verificabilità. Databricks abilita i flussi di lavoro di TabPFN direttamente accanto ai dati governati, in modo che i team possano ridurre al minimo lo spostamento dei dati mantenendo i controlli. Con Unity Catalog, le organizzazioni centralizzano il controllo degli accessi e l'auditing e conservano la derivazione (lineage) dei dati e degli asset di IA, il che è importante quando è necessario dimostrare quali dati sono stati utilizzati, come sono state derivate le feature e chi vi ha avuto accesso al momento della decisione.
Operazionalizzare i risultati in modo efficiente
TabPFN è un approccio di modellazione. Per creare un impatto in produzione, deve integrarsi con pattern aziendali ripetibili come lo scoring batch e in tempo reale, la valutazione, la governance e il monitoraggio. Databricks è una piattaforma solida per questi flussi di lavoro, con un'infrastruttura di compute scalabile e di inferenza in tempo reale in grado di trasformare TabPFN in un processo operativo affidabile. Per la valutazione e il monitoraggio, MLflow offre il tracciamento degli esperimenti e un registro dei modelli per gestire versioni, lineage e flussi di lavoro di promozione in modo verificabile.
Governance continua del modello
Databricks fornisce un monitoraggio continuo delle prestazioni del modello TabPFN, rilevando quando le previsioni iniziano a presentare drift dai risultati aziendali effettivi. Quando sono necessarie delle modifiche, l'architettura di TabPFN elimina il tradizionale ciclo di riaddestramento che dura settimane: i team si limitano ad aggiornare il contesto del modello con i dati recenti e a rieseguire il deployment in pochi minuti anziché giorni. Questa combinazione di monitoraggio automatizzato e capacità di aggiornamento rapido garantisce che la qualità delle previsioni rimanga allineata alle mutevoli condizioni del mercato, riducendo al contempo drasticamente le risorse di Data Science tipicamente necessarie per la manutenzione continua del modello.
Per aiutare i team a testare TabPFN con una configurazione minima, abbiamo pubblicato un acceleratore di soluzioni disponibile pubblicamente che mostra come eseguire TabPFN end-to-end su Databricks con i dati Lakehouse governati. L'acceleratore include una serie di notebook che simulano realisticamente i dati di diversi scenari di settore e creano previsioni utilizzando TabPFN (Video 1).
Inizia oggi stesso, portando il potere trasformativo dell'AI ai tuoi carichi di lavoro di ML e promuovendo una trasformazione completa dei processi aziendali.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.