Dal banco di prova al lakehouse: come AVL modernizza l'analisi dei dati di misura con Impulse
di Dr. Thomas Bonfert, Jonathan Bräuer, Fabian Ade, Maxim Hammer, Florian Gorzitzke, David Crescence, Christa Simon, Jörg Zimmermann e Hannes Schneider
- Impulse è un framework open-source di Databricks Labs che consente agli ingegneri di dominio di analizzare i dati dei sensori su Databricks con semplici espressioni Python.
- Impulse scala l'analisi delle serie temporali a centinaia di terabyte di dati di misurazione, mantenendo le analisi riproducibili, condivisibili tra i team e governate da Unity Catalog.
- AVL ha sostituito la sua piattaforma legacy on-premise con Impulse su Databricks, riducendo i tempi di analisi da giorni a minuti e standardizzando l'analisi dei dati di misurazione in tutta l'organizzazione.
1. Introduzione - Impulse: analisi delle serie temporali per i dati di misurazione
Una singola campagna di test automobilistici produce centinaia di migliaia di registrazioni di misurazione e centinaia di terabyte di dati dei sensori delle serie temporali. Questi dati vengono memorizzati in formati binari come ASAM MDF4 e sono tradizionalmente analizzati con strumenti desktop come NI DIAdem o MATLAB. Gli ingegneri di dominio apprezzano questi strumenti per un valido motivo. Possono concentrarsi sull'analisi effettiva, decidendo quali segnali confrontare e quali condizioni definiscono un evento critico, senza dover diventare esperti di framework per big data e calcolo distribuito. Tuttavia, questi strumenti non sono scalabili, le analisi basate su script isolati sono difficili da riprodurre e i dati rimangono al di fuori della governance su cui fa affidamento il resto di un'azienda moderna.
Impulse è una libreria di analisi basata su Python, pubblicata come progetto Databricks Labs, che colma questo divario sulla Databricks Intelligence Platform. Al suo interno (Figura 1), Impulse fornisce tre ingredienti chiave:
- Un Time Series Analytics Language (TSAL) dichiarativo che consente agli ingegneri di esprimere l'aritmetica dei segnali, le condizioni degli eventi e le aggregazioni in Python naturale senza richiedere competenze Spark.
- Un motore di query pluggabile che compila le espressioni TSAL in un'esecuzione Spark distribuita su migliaia di registrazioni memorizzate in qualsiasi layout di dati di input.
- Astrazioni orientate al dominio che si mappano direttamente sul modo in cui gli ingegneri pensano ai propri dati, inclusi container di misurazione, canali dei sensori, eventi operativi e aggregazioni pesate in base alla durata e alla distanza.
In questo post del blog, mostriamo come Impulse alimenta il Lakehouse per i dati di misurazione di AVL su Databricks. AVL è un'azienda leader a livello mondiale nelle tecnologie per la mobilità, specializzata nello sviluppo, nella simulazione e nel test di sistemi di veicoli ed energia. Lavorano con dati di misurazione e simulazione per convalidare i progetti, comprendere il comportamento del sistema e accelerare lo sviluppo di prodotti guidato dai dati, dai modelli virtuali ai test nel mondo reale. Esamineremo l'architettura lakehouse, tre modalità d'uso complementari adatte sia a ingegneri di dominio, data engineer che data scientist, e l'impatto che AVL ha riscontrato in produzione. Impulse si basa su un modello di dati gerarchico del livello Silver sviluppato in collaborazione con Mercedes-Benz e descritto nel nostro post del blog precedente.

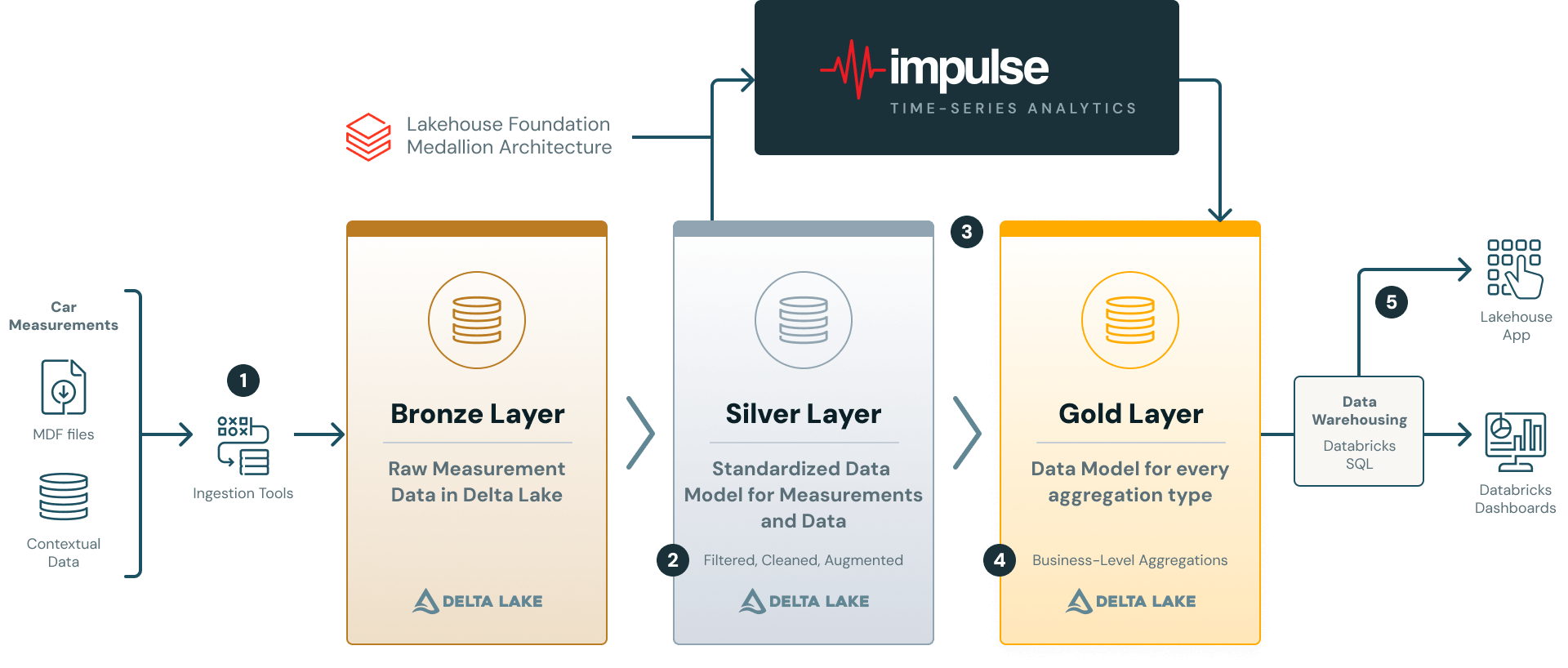
2. L'architettura: un lakehouse per i dati di misurazione
La piattaforma di AVL segue l'architettura Medallion, con Unity Catalog che fornisce la governance su tutti i livelli e Databricks Workflows che orchestra la pipeline (vedere la Figura 2).
1. Origine e ingestione: i file di misurazione grezzi (ad esempio nel formato ASAM MDF4) vengono inseriti nel livello Bronze utilizzando un Databricks Solution Accelerator. AVL ha esteso questo acceleratore per funzionare con AVL Concerto, il loro sistema di gestione dei dati di misurazione che supporta molteplici formati di file proprietari. I metadati contestuali (ID dei veicoli, versioni del software, tag di progetto, ecc.) vengono inseriti insieme ai file registrati.
2. Livello Silver: i dati del livello Bronze vengono trasformati nel modello di dati gerarchico per i dati di misurazione. Il modello organizza i dati attorno a container (ovvero singoli file) e canali (segnali dei sensori), ciascuno arricchito con attributi/tag e metriche a livello di container e di canale. Il livello Silver memorizza dati convalidati e con qualità garantita, preparati per l'elaborazione analitica. Le regole di garanzia della qualità dei dati sono implementate utilizzando il framework Databricks DQX e sono completamente configurabili e personalizzabili per soddisfare specifiche esigenze di analisi a valle. Consultare il nostro post del blog pubblicato in precedenza per ulteriori dettagli sul modello di dati del livello Silver.
3. + 4. Dal livello Silver al Gold: il livello Silver alimenta Impulse, che traduce la logica di analisi dichiarativa in un'esecuzione Spark distribuita. I risultati possono essere uno schema a stella del livello Gold per la reportistica, DataFrame ad hoc per l'esplorazione o matrici di feature per il ML (vedere la Sezione 5).
5. Servizio e analisi: gli strumenti di BI come Databricks Dashboards o Lakehouse Apps utilizzano i dati del livello Gold tramite SQL Warehouse, consentendo un'esplorazione interattiva senza toccare la pipeline di calcolo.
3. Mettere all'opera Impulse: un'analisi completa in 10 righe di Python
Il modo migliore per comprendere Impulse è vederlo in azione. In questa sezione, esamineremo un esempio minimo ma realistico: la selezione dei sensori di temperatura della batteria, la definizione di un evento di rischio di fuga termica basato su tali sensori e il calcolo di un istogramma pesato sulla durata, il tutto utilizzando il Time Series Analytics Language (TSAL).
Selezione dei canali fisici e definizione dei canali virtuali
Il punto di partenza per qualsiasi analisi è la selezione dei canali dei sensori fisici di interesse. Il QueryBuilder cerca nelle tabelle dei metadati del livello Silver e restituisce un'espressione TSAL. Nell'esempio seguente, recuperiamo le temperature delle celle più alte e più basse dalla nostra piattaforma EV e calcoliamo lo sbilanciamento di temperatura (delta):
Si noti che la singola riga per la definizione del canale virtuale codifica un calcolo non banale. Il framework esegue automaticamente la risoluzione degli alias dei canali, la conversione delle unità di misura, allinea i canali a un asse temporale comune ed esegue l'interpolazione dei punti dati prima di eseguire l'aritmetica.
Definizione di un evento
Gli eventi sono finestre temporali derivate dalle condizioni dei segnali. Qui definiamo un evento di sicurezza critico in cui la temperatura massima assoluta della cella supera una soglia di sicurezza (60 °C) OPPURE la variazione di temperatura tra le celle è sospettosamente alta (superiore a 5 °C):
Le espressioni TSAL sono completamente componibili: canali virtuali, condizioni booleane e aggregazioni possono fare riferimento l'una all'altra.
Calcolo di un istogramma all'interno dell'evento
Infine, definiamo un istogramma pesato sulla durata della temperatura massima della cella, limitato all'evento di rischio termico. L'istogramma conta il tempo trascorso in ciascun intervallo di temperatura, producendo risultati fisicamente significativi indipendentemente dalla frequenza di campionamento del sensore:
Esecuzione dell'analisi
Due chiamate di metodo avviano l'elaborazione distribuita su tutte le registrazioni di misurazione corrispondenti e salvano in modo persistente i risultati come tabelle con schema a stella del livello Gold in Unity Catalog. L'intera analisi, dalla selezione dei canali al calcolo dei segnali virtuali, alla definizione degli eventi, all'aggregazione degli istogrammi e alla persistenza, richiede circa 10 righe di Python. L'utente non deve mai scrivere una trasformazione DataFrame, una funzione definita dall'utente, una join o una window function.
4. Tre modi per utilizzare Impulse: reporting, analisi ad-hoc e ML
Impulse supporta tre modalità di utilizzo complementari (Figura 3), tutte basate sullo stesso linguaggio di espressione TSAL e motore di query. Nella modalità di reporting strutturato, gli ingegneri di dominio definiscono eventi e aggregazioni che vengono eseguiti in parallelo su tutte le registrazioni corrispondenti e salvati in modo persistente in uno schema a stella del livello Gold, pronti per le dashboard AI/BI o le Lakehouse App. La pipeline può essere pianificata come Databricks Workflow per aggiornarsi automaticamente all'arrivo di nuove misurazioni. Nella modalità ad-hoc, le espressioni TSAL vengono valutate direttamente dal motore di query e restituite come DataFrame di Spark per l'esplorazione interattiva nei notebook, senza scrivere nel livello Gold. Nella modalità ML, le statistiche relative all'evento e le distribuzioni degli istogrammi vengono estratte come matrici di feature piatte che possono essere passate direttamente a MLflow, AutoML o a pipeline di addestramento personalizzate.

Come AVL utilizza Impulse nella pratica
Nella pratica, AVL sfrutta i punti di forza del framework Impulse utilizzando principalmente la sua modalità di reporting strutturato per creare pacchetti di analisi configurabili e standardizzati ("toolbox"). Questi toolbox vengono eseguiti dagli ingegneri di dominio sulle campagne di misurazione in entrata, a seconda del loro specifico compito ingegneristico o focus analitico.
I risultati del livello Gold così ottenuti sono integrati perfettamente nelle Databricks Dashboard e nelle Lakehouse App, dove gli ingegneri possono esplorare i risultati in modo interattivo e creare istogrammi, mappe di calore e altre visualizzazioni statistiche per supportare decisioni ingegneristiche basate sui dati.
5. Risultati e impatto
Con l'aiuto del framework Impulse e della Databricks Data Intelligence Platform, AVL ha creato una piattaforma dati ingegneristica end-to-end per supportare lo sviluppo di prodotti basato sui dati. La piattaforma introduce un nuovo standard nell'analisi dei dati automobilistici e offre miglioramenti su molteplici fronti:
Miglioramenti quantitativi
- Significativa riduzione dei tempi di analisi (da giorni a minuti rispetto agli approcci tradizionali)
- Capacità di elaborare un gran numero di registrazioni di misurazione in un'unica esecuzione
- Risparmio sui costi dell'infrastruttura rispetto alle soluzioni on-premise
Miglioramenti qualitativi
- Maggiore autonomia degli ingegneri di dominio grazie all'analisi self-service
- Analisi completamente riproducibili e trasparenti
- Standardizzazione tra i vari team su un'unica piattaforma dati unificata
6. Prossimi passi: l'open source e la strada da percorrere
Impulse viene rilasciato come progetto Databricks Labs (consulta qui), aperto ai contributi della community per nuove aggregazioni, risolutori di query ed estensioni specifiche per il dominio. Il framework viene fornito con un dataset dimostrativo pubblico, documentazione completa e notebook Databricks per illustrare le modalità di utilizzo per reporting e ML.
Per AVL, l'implementazione odierna è solo la base del loro lakehouse per i dati di misurazione. La roadmap estende Impulse alla validazione di ADAS e guida autonoma, alla manutenzione predittiva e ai dati di simulazione, puntando a uno sviluppo del prodotto end-to-end basato sui dati.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.