From test bench to lakehouse: how AVL modernizes measurement data analytics with Impulse
by Dr. Thomas Bonfert, Jonathan Bräuer, Fabian Ade, Maxim Hammer, Florian Gorzitzke, David Crescence, Christa Simon, Jörg Zimmermann and Hannes Schneider
- Impulse is an open-source Databricks Labs framework that lets domain engineers analyze sensor data on Databricks with simple Python expressions.
- Impulse scales time-series analytics to hundreds of terabytes of measurement data, while keeping analyses reproducible, shareable across teams and governed by Unity Catalog.
- AVL replaced its legacy on-premise platform with Impulse on Databricks, cutting analysis time from days to minutes and standardizing measurement data analytics across the organization.
1. Introduction - Impulse: time-series analytics for measurement data
A single automotive test campaign produces hundreds of thousands of measurement recordings and hundreds of terabytes of time-series sensor data. This data is stored in binary formats like ASAM MDF4 and is traditionally analyzed with desktop tools such as NI DIAdem or MATLAB. Domain engineers like these tools for a good reason. They can focus on the actual analysis, deciding which signals to compare and which conditions define a critical event, without becoming experts in big-data frameworks and distributed computing. But the tools don't scale, analyses based on isolated scripts are hard to reproduce, and the data sits outside the governance the rest of a modern enterprise relies on.
Impulse is a Python-based analytics library, published as a Databricks Labs project, that closes this gap on the Databricks Intelligence Platform. At its core (Figure 1), Impulse provides three key ingredients:
- A declarative Time Series Analytics Language (TSAL) that lets engineers express signal arithmetic, event conditions, and aggregations in natural Python without requiring Spark expertise.
- A pluggable query engine that compiles TSAL expressions into distributed Spark execution across thousands of recordings stored in any input data layout.
- Domain-aware abstractions that map directly onto how engineers think about their data, including measurement containers, sensor channels, operating events, and duration- and distance-weighted aggregations.
In this blog post, we show how Impulse powers AVL's Lakehouse for Measurement Data on Databricks. AVL is a world-leading mobility technology company that specializes in the development, simulation, and testing of vehicle and energy systems. They work with measurement and simulation data to validate designs, understand system behavior, and accelerate data-driven product development from virtual models to real-world testing. We walk through the lakehouse architecture, three complementary usage modes that serve domain engineers, data engineers and data scientists alike, and the impact AVL has seen in production. Impulse builds on a hierarchical Silver-layer data model co-developed with Mercedes-Benz and described in our previous blog post.

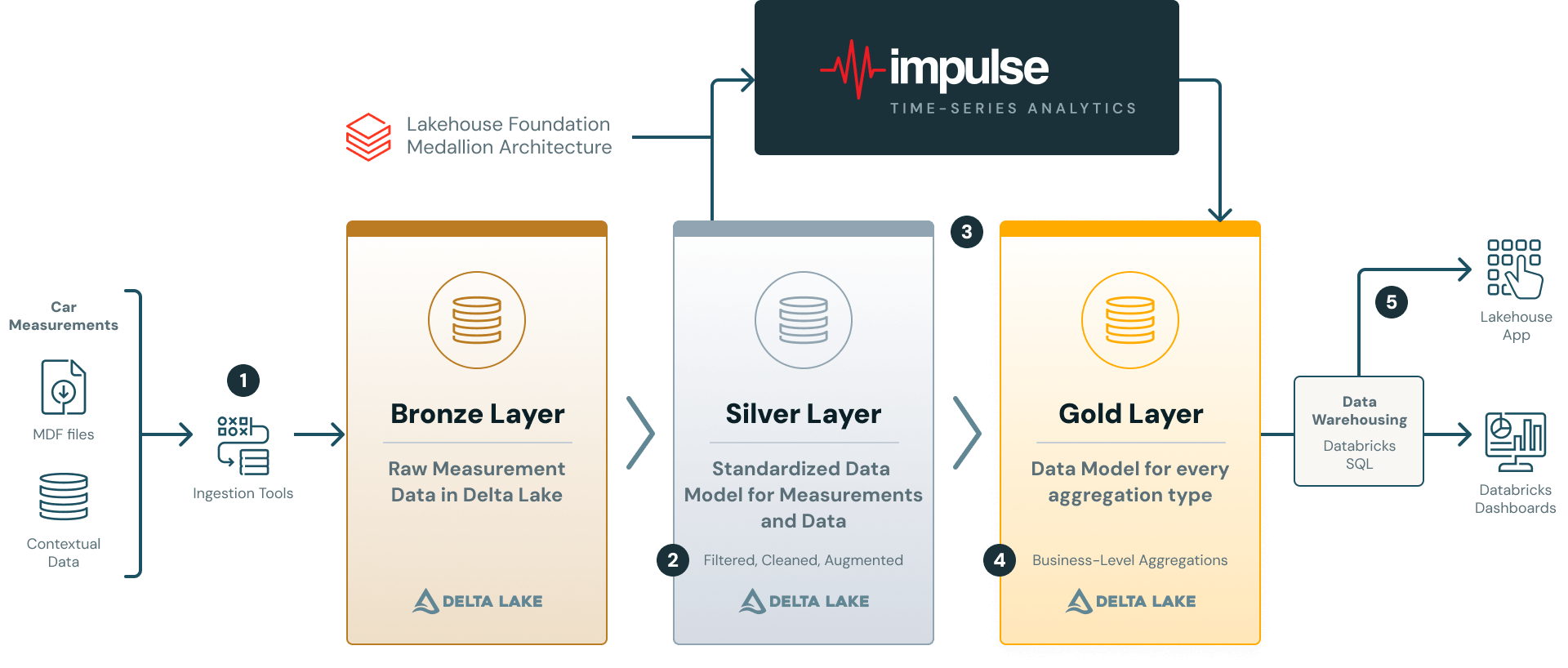
2. The architecture - a lakehouse for measurement data
AVL’s platform follows the Medallion Architecture, with Unity Catalog providing governance across all layers and Databricks Workflows orchestrating the pipeline (see Figure 2).
1. Source and Ingestion: Raw measurement files (e.g in ASAM MDF4 format) are ingested into the Bronze layer using a Databricks Solution Accelerator. AVL extended this accelerator to work with AVL Concerto, their measurement data management system that supports multiple proprietary file formats. Contextual metadata (vehicle IDs, software versions, project tags, etc.) is ingested alongside the recorded files.
2. Silver Layer: Bronze data is transformed into the hierarchical data model for measurement data. The model organizes data around containers (i.e. individual files) and channels (sensor signals), each enriched with container-level and channel-level attributes/tags and metrics. The silver layer stores validated and quality-assured data prepared for analytical processing. Data quality-assurance rules are implemented using the Databricks DQX framework and are fully configurable and customizable to meet specific downstream analytics needs. Please see our previously published blog post for more details on the silver layer data model.
3. + 4. From Silver to Gold: The Silver layer feeds into Impulse, which translates declarative analysis logic into distributed Spark execution. Outputs can be a Gold-layer star schema for reporting, ad-hoc DataFrames for exploration, or feature matrices for ML (see Section 5).
5. Serve and Analysis: BI tools like Databricks Dashboards or Lakehouse Apps consume Gold-layer data via SQL Warehouses, enabling interactive exploration without touching the compute pipeline.
3. Putting Impulse to work: a complete analysis in 10 lines of Python
The best way to understand Impulse is to see it in action. In this section, we walk through a minimal but realistic example: selecting battery temperature sensors, defining a thermal runaway risk event based on those sensors, and calculating a duration-weighted histogram, all using the Time Series Analytics Language (TSAL).
Selecting physical channels & defining virtual channels
The starting point for any analysis is selecting the physical sensor channels of interest. The QueryBuilder searches the Silver-layer metadata tables and returns a TSAL expression. In the example below, we retrieve the highest and lowest cell temperatures from our EV platform and compute the temperature imbalance (delta):
Note that the single line for defining the virtual channel encodes a non-trivial computation. The framework automatically performs channel alias resolution, unit conversion, aligns channels to a common time axis and performs interpolation of data points before performing the arithmetic.
Defining an event
Events are time windows derived from signal conditions. Here, we define a critical safety event where the absolute maximum cell temperature exceeds a safe threshold (60°C) OR the temperature variation between cells is suspiciously high (greater than 5°C):
TSAL expressions are fully composable: virtual channels, boolean conditions, and aggregations can reference each other.
Computing a histogram within the event
Finally, we define a duration-weighted histogram of the maximum cell temperature, scoped to the thermal risk event. The histogram counts time spent in each temperature bin, producing physically meaningful results regardless of sensor sampling rate:
Executing the analysis
Two method calls trigger the distributed computation across all matching measurement recordings and persist the results as Gold-layer star schema tables in Unity Catalog. The entire analysis, from channel selection through virtual signal computation, event definition, histogram aggregation, and persistence, takes roughly 10 lines of Python. The user never writes a DataFrame transformation, a user defined function, a join, or a window function.
4. Three ways to use Impulse – reporting, ad-hoc analysis, and ML
Impulse supports three complementary usage modes (Figure 3), all built on the same TSAL expression language and query engine. In structured reporting mode, domain engineers define events and aggregations that are executed in parallel across all matching recordings and persisted to a Gold-layer star schema, ready for AI/BI Dashboards or Lakehouse Apps. The pipeline can be scheduled as a Databricks Workflow to update automatically as new measurements arrive. In ad-hoc mode, TSAL expressions are evaluated directly by the query engine and returned as Spark DataFrames for interactive exploration in notebooks, without writing to the Gold layer. In ML mode, event-scoped statistics and histogram distributions are extracted as flat feature matrices that can be passed directly to MLflow, AutoML, or custom training pipelines.

How AVL uses Impulse in practice
In practice, AVL leverages the strengths of the Impulse framework by primarily using its structured reporting mode to build configurable, standardized analysis packages (“toolboxes”). These toolboxes are executed by domain engineers on incoming measurement campaigns, depending on their specific engineering task or analytical focus.
The resulting Gold-layer outputs are seamlessly integrated into Databricks Dashboards and Lakehouse Apps, where engineers can interactively explore results and create histograms, heatmaps, and other statistical visualizations to support data-driven engineering decisions.
5. Results and impact
With the help of the Impulse framework and the Databricks Data Intelligence Platform, AVL has built an end-to-end engineering data platform to support data-driven product development. The platform introduces a new standard in automotive data analysis and delivers improvements across multiple dimensions:
Quantitative improvements
- Significant reduction in analysis time (from days to minutes compared to traditional approaches)
- Ability to process a large number of measurement recordings in a single run
- Infrastructure cost savings compared to on-premise solutions
Qualitative improvements
- Empowerment of domain engineers through self-service analytics
- Fully reproducible and transparent analyses
- Cross-team standardization on a single, unified data platform
6. What’s next - open source and the road ahead
Impulse is being released as a Databricks Labs project (please see here), open to community contributions in new aggregations, query solvers, and domain-specific extensions. The framework ships with a public demo dataset, full documentation and Databricks notebooks to demonstrate the reporting & ML usage modes.
For AVL, today's deployment is only the foundation of their lakehouse for measurement data. The roadmap extends Impulse to ADAS and autonomous driving validation, predictive maintenance, and simulation data, working toward end-to-end data-driven product development.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.