Trasformare i report di manutenzione solare ed eolica con Genie e agenti AI
Come Plenitude utilizza Databricks Genie e Agent Bricks per trasformare i PDF di manutenzione non strutturati in un livello di dati ricercabile e in analisi in linguaggio naturale per gli impianti solari ed eolici.
- Plenitude ha sviluppato un sistema basato su agenti su Databricks Genie che converte PDF non strutturati relativi alla manutenzione solare ed eolica in un modello di dati unificato e interrogabile.
- La soluzione utilizza Genie, insieme ai metadati semantici di Unity Catalog e alle AI Functions, per consentire agli utenti di porre domande in linguaggio naturale e creare visualizzazioni tra diversi impianti e nel tempo.
- I primi risultati includono un'analisi multi-impianto più rapida, un accesso self-service governato con sicurezza a livello di riga e una base per la manutenzione predittiva su asset critici come gli inverter.
Dai PDF di manutenzione a insight operativi con gli agenti AI
I fornitori di servizi di gestione e manutenzione per impianti solari ed eolici in genere inviano i report in formato PDF, con le informazioni chiave distribuite tra testo libero, tabelle e immagini. Questo formato è accessibile ma non scalabile: i team devono leggere manualmente ogni documento per comprendere guasti, tendenze o problemi ricorrenti, rendendo i confronti tra i vari impianti lenti e incoerenti con l'aumentare del numero di asset.
Plenitude e Databricks hanno sviluppato un sistema basato su agenti che converte questi report di manutenzione in formato PDF in dati strutturati. L'idea di fondo è semplice: trasformare i documenti in dati, quindi utilizzare un agente AI per ricavare insight operativi da tali dati. Ora gli utenti possono porre domande in linguaggio naturale, analizzare le tendenze nel tempo, confrontare gli impianti ed esportare output strutturati, invece di consultare i report uno alla volta.
Architettura basata su agenti per l'analisi dei dati da PDF
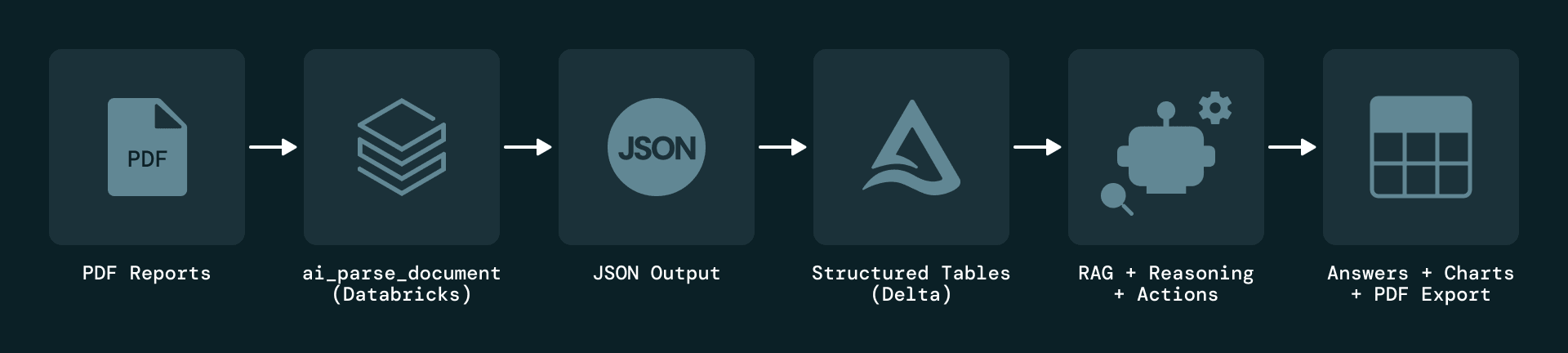
La soluzione inizia con l'ingestione basata su eventi dei report PDF a livello di impianto. Ogni nuovo report attiva un Databricks Job che analizza il documento e applica l'estrazione basata su LLM. Gli elementi estratti vengono serializzati in formato JSON e memorizzati in Delta Lake, che mantiene la cronologia completa delle versioni per l'audit e la riproduzione.
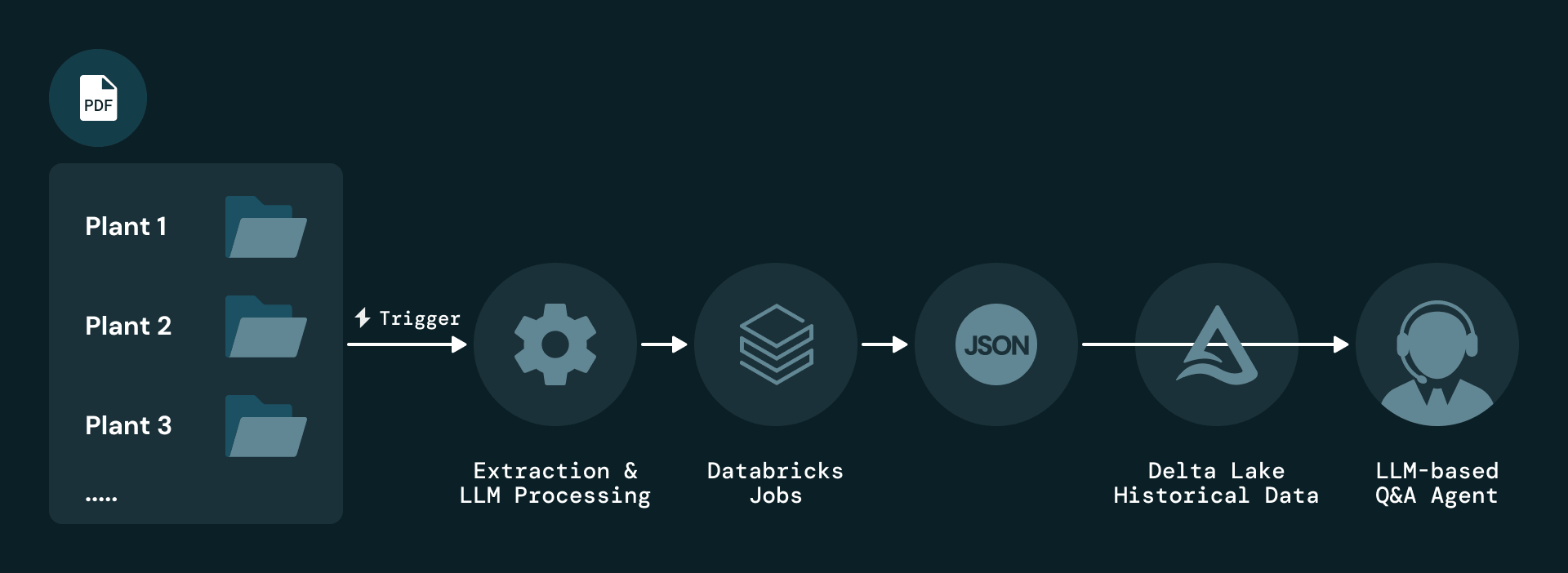
Per affrontare il problema fondamentale legato al fatto che le informazioni sulla manutenzione risiedono quasi interamente in PDF non strutturati, Plenitude utilizza le AI Functions di Databricks Document Intelligence, nello specifico ai_parse_document, per estrarre diversi tipi di elementi da ogni pagina, inclusi blocchi di testo, tabelle, figure e metadati. Ogni elemento viene arricchito con attributi quali impianto, periodo del report, numero di pagina e tipo di contenuto, e ogni record mantiene un collegamento diretto al report originale per garantire la tracciabilità.
Questa struttura sblocca potenti funzionalità:
- Filtraggio per tempo, categoria e area geografica.
- Identificazione dei tipi di contenuto e utilizzo delle coordinate spaziali.
- Tracciamento di ogni insight fino al PDF originale.
- Integrazione con strumenti di BI e agenti digitali senza modificare i documenti sottostanti.
Invece di file statici, i report di manutenzione diventano un data layer persistente pronto per l'analisi avanzata e il ragionamento degli agenti.
Elaborazione dei dati su Databricks: da PDF a Delta Lake
L'architettura è organizzata in tre livelli principali: ingestione e analisi (parsing), strutturazione dei dati e interazione basata su agenti.
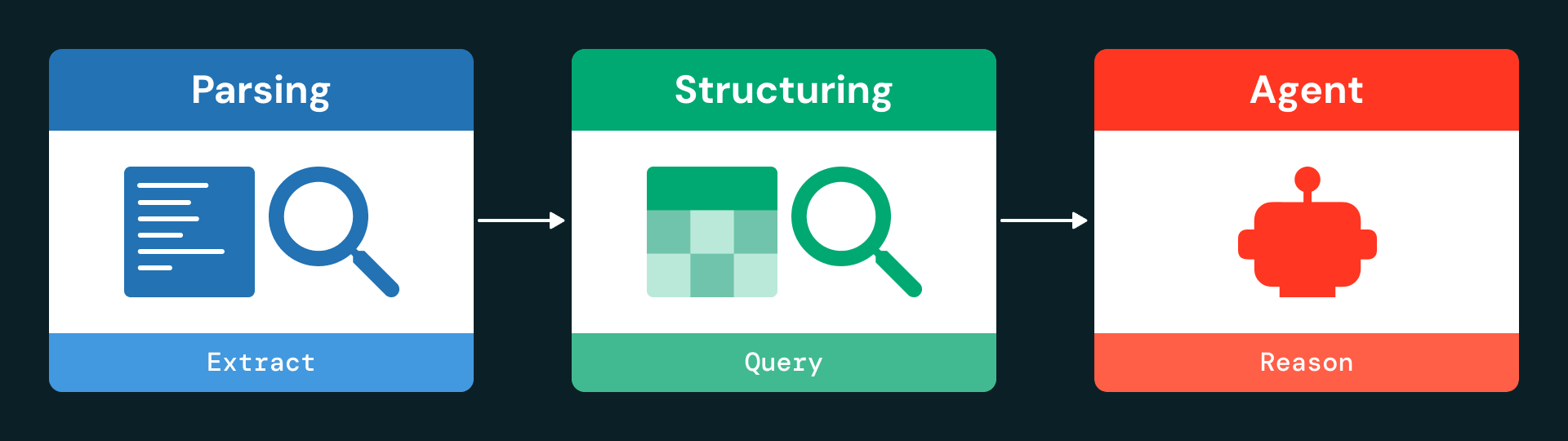
Fase 1: parsing
Utilizzando ai_parse_document, la pipeline estrae testo, tabelle e metadati da ogni pagina e li serializza come oggetti JSON strutturati. Anche le tabelle complesse vengono acquisite con il contesto completo, inclusa la loro posizione sulla pagina e la rappresentazione HTML.
Fase 2: normalizzazione e archiviazione
Per ogni pagina (page_id) e oggetto (id), il sistema crea una riga in una tabella Delta Lake. Ogni riga contiene:
- Il contenuto JSON estratto.
- Identificatori di pagina e oggetto.
- Coordinate (coords) che rappresentano il rettangolo di delimitazione (bounding box) sulla pagina.
- Tipo di contenuto (ad esempio, testo o tabella).
- Metadati di alto valore come mese, anno, nome del file, categoria e paese.
Questo modello normalizzato trasforma i PDF in un dataset unificato e interrogabile, trasparente e facile da unire ad altre fonti, preservando al contempo la completa tracciabilità fino ai documenti originali.
Fase 3: spazio Genie e modalità Agent
Su questo data layer curato, Plenitude crea uno spazio Genie dedicato e poi sfrutta la modalità Agent di Genie per eseguire ricerche approfondite (Deep Research) sui dati. Genie utilizza le tabelle Delta Lake strutturate come contesto principale e consente agli utenti di interagire con i dati di manutenzione utilizzando il linguaggio naturale.
Quando un utente pone una domanda, Genie:
- Utilizza i metadati semantici in Unity Catalog per identificare le tabelle e le colonne disponibili.
- Sfrutta descrizioni dettagliate delle colonne, un archivio di conoscenze curato e campioni SQL per guidare la generazione delle query.
- Genera ed esegue query SQL sul livello strutturato.
- Restituisce risposte, visualizzazioni e risultati opzionalmente esportabili.
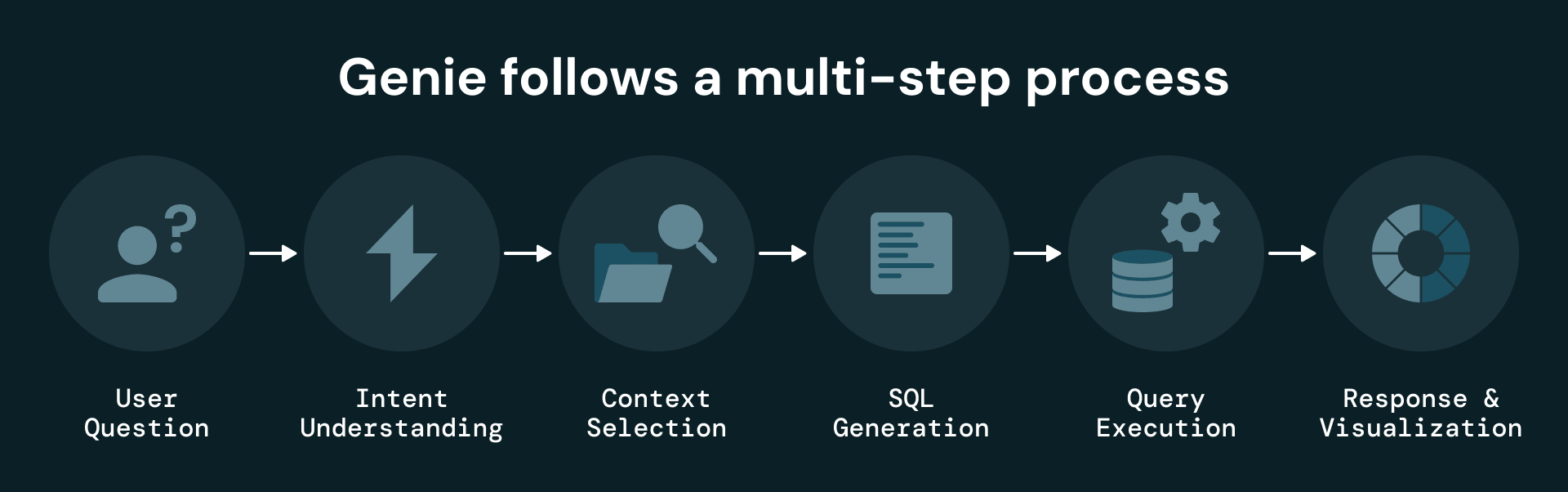
Questo design consente a Genie di comprendere sia la semantica aziendale dei dati di manutenzione sia la loro struttura sottostante, fornendo risposte accurate e sensibili al contesto.
Perché i metadati e le istruzioni sono importanti per Genie
Per ottenere risultati affidabili da dataset complessi derivati da PDF, il solo contesto non è sufficiente. Plenitude ha scoperto che due design pattern sono fondamentali: metadati ricchi e istruzioni esplicite per lo spazio Genie.
I metadati come contratto con l'agente
Descrizioni ben definite di tabelle e colonne indicano a Genie il significato di ciascun campo e come dovrebbe essere utilizzato. Ad esempio, page_id identifica la pagina di origine nel report originale, type indica se l'elemento è testo o una tabella, coords codifica la posizione spaziale e content contiene il testo estratto o la rappresentazione della tabella. Questi metadati trasformano il JSON non elaborato in conoscenza comprensibile su cui Genie può ragionare.
Istruzioni generali come base operativa
Quando i dati sono frammentati o si estendono su più pagine, le istruzioni specifiche del dominio aggiunte al knowledge store locale dello spazio Genie diventano essenziali. Plenitude codifica regole per la gestione di tabelle multipagina, l'esclusione di artefatti HTML, l'esclusione di righe di intestazione e l'applicazione di filtri specifici per l'impianto.
Un esempio pratico: anche con metadati completi, Genie potrebbe calcolare un totale trimestrale errato se somma le colonne YTD o ignora i mesi mancanti. Aggiungendo istruzioni chiare come “utilizza solo colonne a livello mensile, mai campi YTD” e “verifica che tutti i mesi richiesti siano presenti prima di sommare”, il team fornisce a Genie guardrail operativi che garantiscono risultati coerenti.
Queste istruzioni specifiche per lo spazio Genie, combinate con i metadati di Unity Catalog, aiutano Genie ad applicare la logica corretta per interpretare i dati in modo esatto.
Utilizzo di Genie e Agent Bricks per workflow di agenti scalabili
Mentre Genie offre una potente esperienza di agente di ricerca sul livello di manutenzione strutturato, Plenitude ha anche bisogno di workflow ripetibili e orchestrazione per supportare un insieme crescente di casi d'uso. Agent Bricks rappresenta il passo successivo in questa evoluzione.
Con Agent Bricks, Plenitude può passare da pattern “LLM più prompt” a workflow agentici che eseguono sequenze di azioni per conto di analisti e ingegneri della manutenzione. Le stesse tabelle Delta Lake curate, i metadati e le istruzioni che alimentano Genie possono essere riutilizzati da agenti in stile Supervisor creati con Agent Bricks per:
- Scomporre domande complesse in attività analitiche più piccole.
- Richiamare i flussi degli strumenti Genie per generare ed eseguire query SQL.
- Attivare azioni a valle, come la generazione di report o la creazione di avvisi.
Ciò che un tempo richiedeva il collegamento manuale di prompt, strumenti e logica di validazione ora può essere centralizzato in Agent Bricks, sulla stessa piattaforma Databricks che gestisce i dati.
Ottimizzare le prestazioni con il liquid clustering automatico
Poiché le query guidate da agenti sono esplorative e dinamiche, l'ottimizzazione tradizionale basata su Z-ORDER non è sempre l'ideale. Plenitude ha osservato che i pattern di accesso si evolvono con la comparsa di nuovi report, utenti e domande, il che rende il clustering manuale difficile da mantenere.
Il liquid clustering automatico, al contrario, apprende come vengono effettivamente utilizzate le tabelle e adatta il layout di conseguenza. Questo riduce la necessità di progettare gli indici in anticipo e di eseguire un'ottimizzazione continua, il che è particolarmente importante durante le fasi di proof-of-concept e di go-live iniziale. In questo contesto, l'auto-clustering è la scelta preferita per i carichi di lavoro guidati da agenti e LLM su tabelle Delta.
Garantire la sicurezza dell'accesso ai dati per le Genie Room
I dati di manutenzione hanno spesso requisiti di accesso specifici per paese o regione. Per applicare queste regole in modo coerente, Plenitude utilizza la sicurezza a livello di riga in combinazione con Unity Catalog e le tabelle.
Una funzione di Unity Catalog determina a quali paesi l'utente corrente può accedere e restituisce un elenco o la parola chiave ALL se ha visibilità completa. Una tabella filtra quindi le righe in base a tale funzione, in modo che ciascun utente veda solo i dati relativi ai paesi autorizzati.
Quando gli utenti interagiscono attraverso la Genie Room, tutte le query vengono eseguite sulla tabella filtrata, quindi la sicurezza a livello di riga viene applicata automaticamente. Ciò significa che gli utenti possono porre domande in linguaggio naturale, ma ricevono solo i risultati dei dati che sono autorizzati a vedere. Lo stesso dataset alimenta Genie, gli agenti e gli strumenti di BI, mentre la visibilità si adatta per ciascun utente.
Miglioramenti futuri: verso la manutenzione predittiva
Poiché i report di manutenzione contengono incidenti aperti e dettagli sui guasti, il modello di dati strutturato costituisce una solida base per la manutenzione predittiva. Gli inverter sono un buon esempio: i guasti possono portare alla perdita di diversi megawattora per unità e i problemi ricorrenti spesso compaiono prima nelle note di manutenzione.
Analizzando i pattern di guasto nel tempo, Plenitude può:
- Identificare potenziali problemi di registrazione.
- Rilevare segnali di allarme precoce.
- Assegnare la priorità agli impianti che richiedono indagini più approfondite.
- Alimentare i modelli predittivi con cronologie degli incidenti di qualità superiore.
Il sistema basato su agenti trasforma questi segnali in analisi, tendenze e visualizzazioni accessibili, in modo che i team possano anticipare i problemi anziché limitarsi a reagire ad essi.
Vantaggi e funzionalità chiave
Nel metodo precedente, l'analisi si limitava alla lettura individuale dei report, il che rendeva difficile creare tendenze storiche, confrontare gli impianti o generare output strutturati. La creazione di grafici, l'esportazione dei risultati o la combinazione di insight provenienti da più report era, nel migliore dei casi, manuale e spesso non fattibile.
Con la modalità Genie Agent su Databricks e un modello di dati adatto agli agenti, Plenitude può:
- Esplorare i dati di manutenzione nel tempo e tra i diversi impianti.
- Generare visualizzazioni ed esportare i risultati, inclusi gli output in formato PDF.
- Rilevare segnali precoci e pattern ricorrenti.
- Scalare l'analisi senza aumentare lo sforzo manuale.
Combinando dati strutturati, metadati aziendali e ragionamento basato sull'AI, il sistema genera analisi, tendenze e visualizzazioni che supportano il rilevamento precoce e l'anticipazione dei problemi, anziché limitarsi a una reportistica retrospettiva.
Scopri di più su Databricks Genie e Agent Bricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.