Tutorial: come distribuire in modo sicuro e su larga scala le modifiche ai dashboard AI/BI con i Databricks Asset Bundles
Implementa l'analitica con sicurezza: una guida completa per creare dashboard AI/BI affidabili e scalabili senza processi manuali
di Eason Gao, Noah Sommerfeld e Jen Lim
- Implementare dashboard a livello di organizzazione e di grande impatto con sicurezza e stabilità.
- Mantenere la fiducia con modifiche e cronologia visibili, revisionabili e reversibili.
- Aggiorna le metriche e la logica della dashboard man mano che le definizioni aziendali cambiano - senza interrompere il reporting di produzione.
L'idea di una riunione del consiglio di amministrazione che inizia con un dashboard pieno di errori dovrebbe tenere svegli la notte i team delle analitiche. Così come scoprire, a posteriori, che un piano di assunzioni, il lancio di un prodotto o una previsione dei ricavi si basavano su una metrica errata. O che un team di assistenza ha emesso troppi rimborsi perché un dashboard rappresentava in modo errato la cronologia degli acquisti di un cliente.
Questi fallimenti sono raramente causati da un'analisi errata. Come qualsiasi sistema di produzione, spesso derivano dall'aggiornamento manuale delle dashboard con l'evolversi dei modelli di dati e dei requisiti, senza versioning, senza un processo di revisione affidabile o senza un modo ripetibile per promuovere le modifiche tra gli ambienti.
Questo post su un blog sostiene una tesi semplice: le dashboard di livello produttivo che guidano il business devono essere gestite con la stessa disciplina del codice di produzione. Poiché Databricks AI/BI viene eseguito sulla stessa Data Intelligence Platform delle pipeline di dati e del livello di governance, i team possono applicare anche alle dashboard le stesse pratiche di produzione: controllo delle versioni, configurazione specifica per l'ambiente e distribuzione controllata.
Per fare un esempio pratico, mostreremo come gli analisti possono usare le funzionalità Databricks di livello produttivo senza cambiare il modo in cui creano le dashboard quotidianamente.
Nello specifico, mostreremo come questo flusso ti consente di:
- Esamina e approva ogni modifica a una dashboard
- Tieni traccia della cronologia di un dashboard e collega le modifiche al codice ai requisiti aziendali
- Ripristina una dashboard a una versione precedente
Prerequisiti:
Questo flusso di lavoro richiede una configurazione dell'infrastruttura una tantum che la maggior parte delle organizzazioni ha già implementato. Se non li hai già, chiedi al tuo gruppo DevOps o IT interno di aiutarti a configurare:
- Almeno due Databricks workspace (ad esempio, un workspace di sviluppo e un workspace di produzione) per creare, testare e implementare le dashboard
- Cartelle supportate da Git in Databricks (AWS | Azure | GCP), utilizzate per il versionamento delle definizioni dei dashboard
- Databricks Asset Bundles (DAB) (AWS | Azure | GCP) configurati per il progetto
Introduzione: un flusso di lavoro strutturato per la distribuzione sicura delle modifiche ai dashboard
Analizzeremo uno scenario realistico: sei proprietario di una dashboard Performance delle vendite utilizzata settimanalmente dalla dirigenza dei reparti Finance e Sales. È iniziato come un progetto per stagisti, creato direttamente in un'area di lavoro, ma si è evoluto nel tempo e ora viene utilizzato in diverse revisioni dirigenziali.
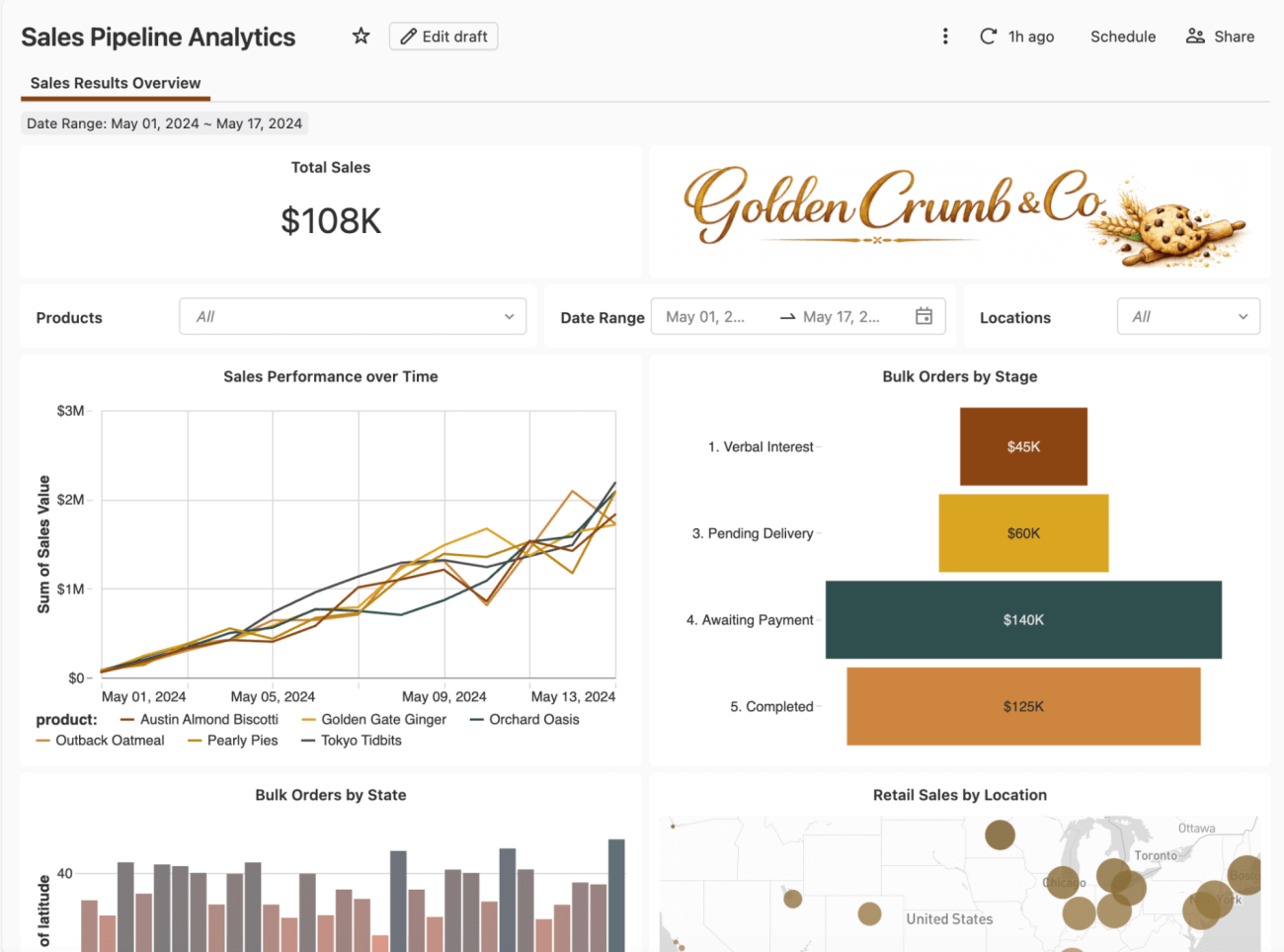
Un cambiamento di priorità derivante da una riunione del consiglio di amministrazione comporta un nuovo requisito: il reparto finanziario deve ora monitorare gli importi delle vendite confermati e non confermati, sostituendo una singola metrica di vendita aggregata, e il dashboard deve riflettere la nuova definizione prima della prossima revisione delle previsioni.
Questi valori confluiscono direttamente nelle decisioni aziendali reali, inclusi i calcoli di retribuzione e bonus, quindi prendiamo questa dashboard e inseriamola per la prima volta in un percorso di implementazione disciplinato.
Passaggio 1: Aggiungere il dashboard in un Databricks Asset Bundle
Prima di iniziare il processo, collabora con il tuo gruppo IT per configurare alcuni strumenti di codice di base: un repository Git con un "Databricks Asset Bundle" vuoto e alcuni script CI/CD per distribuire automaticamente il bundle.
Un repository Git è uno strumento per tracciare le modifiche ai file. Per iniziare, dobbiamo collegarlo a Databricks in modo da poter tracciare le modifiche alla configurazione della dashboard. Dall'area di lavoro di Databricks, crea una cartella Git e incolla l'URL del repository nella finestra di dialogo di configurazione. In questo modo Databricks viene a conoscenza del repository e ci permette di aggiungervi la dashboard nel passaggio successivo.

Un Databricks Asset Bundle è un modo per raggruppare file di codice (in questo caso, una dashboard). Se il repository contiene già un bundle, questo viene rilevato automaticamente e può essere aperto utilizzando l'icona della freccia. Altrimenti, è possibile creare un nuovo bundle dal menu Crea nella cartella Git.
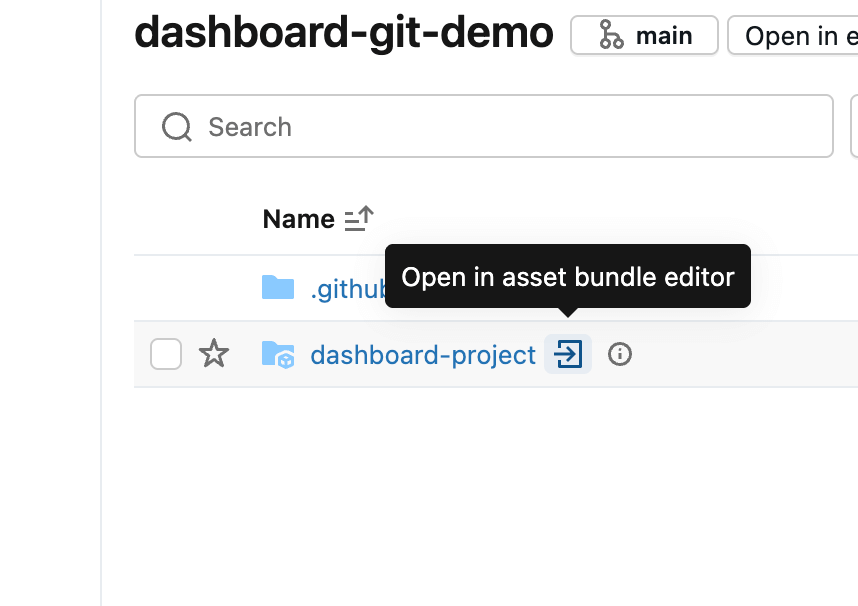
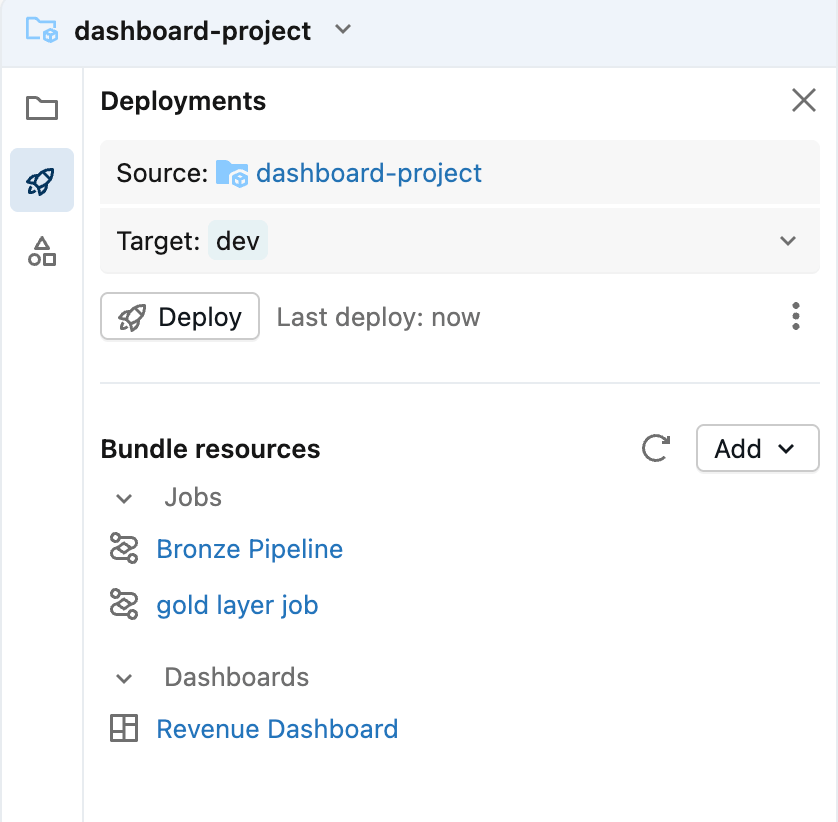
Nell'editor di Asset Bundle, puoi aggiungere al bundle attualmente vuoto sia componenti nuovi che esistenti. Per includere la dashboard, apri il menu Aggiungi e seleziona Aggiungi dashboard esistente. Dopo averla aggiunta, vedrai la dashboard apparire nella cartella src come parte del bundle.
Da questo momento in poi, la dashboard viene gestita come un asset distribuibile, facilitando la promozione della stessa dashboard tra i Workspace di sviluppo, test e produzione.
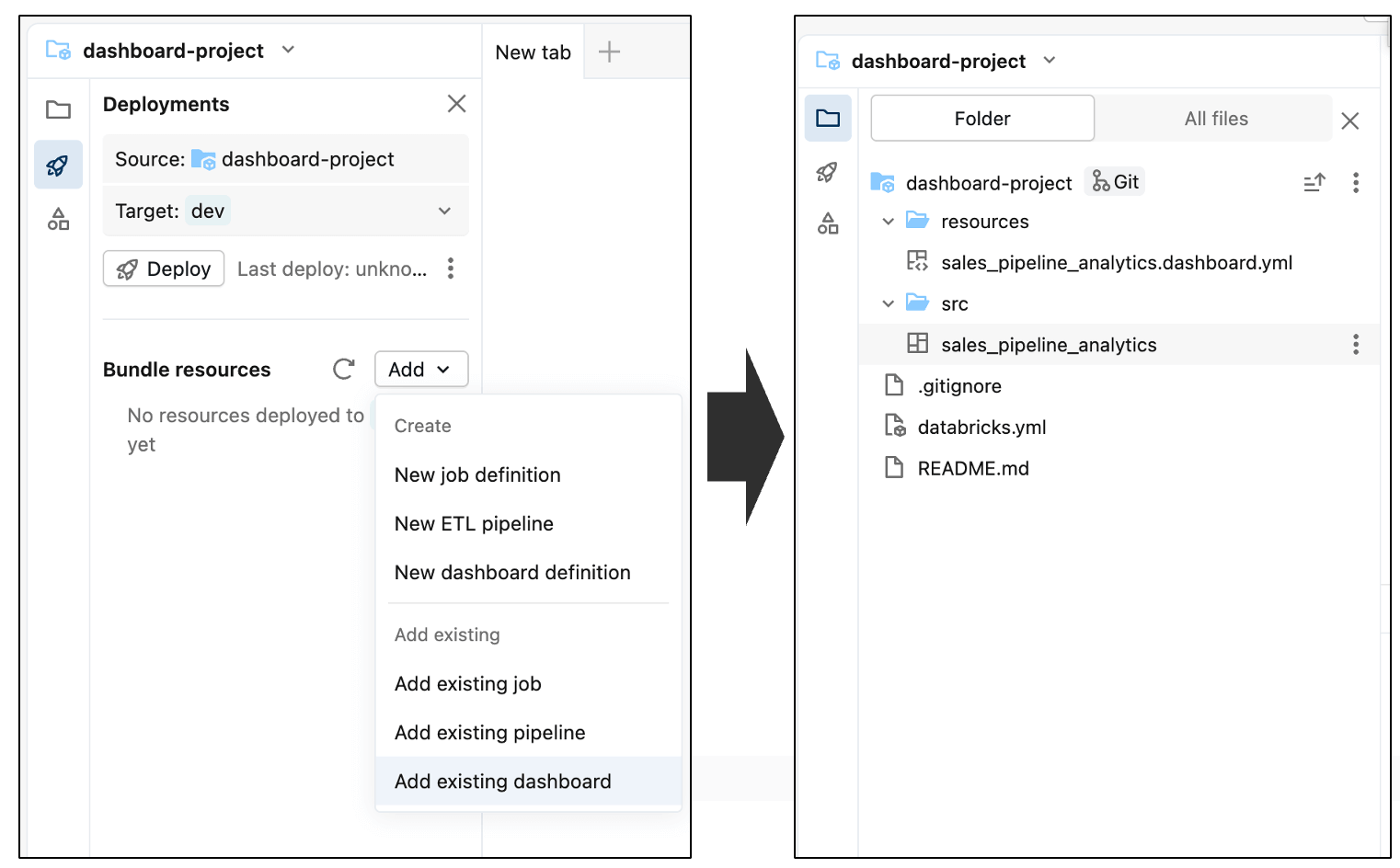
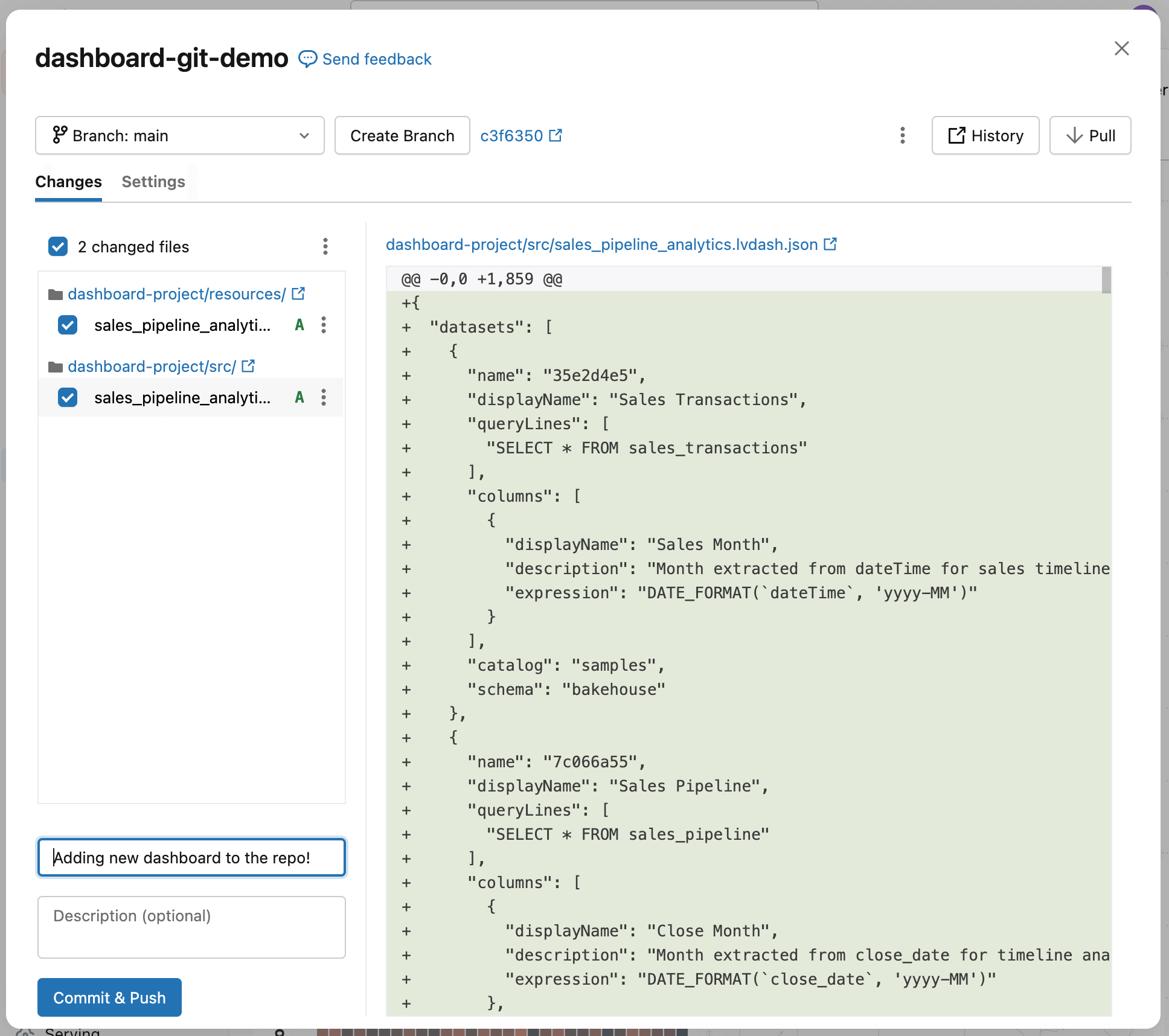
Infine, esegui il commit della dashboard nel repository. Questa operazione acquisisce lo stato corrente della dashboard come baseline e stabilisce un punto di partenza chiaro per tracciare e rivedere le modifiche future.
Vedrai che la dashboard è stata aggiunta al repository, insieme ad alcuni file di configurazione generati automaticamente (che terminano con .yml). Questi file descrivono come eseguire il deployment della dashboard in ambienti diversi—non è necessario modificarli.
Aggiungi una breve nota che descriva ciò che hai fatto nel campo messaggio di commit, quindi seleziona Commit & Push. Questo crea un checkpoint per la dashboard—uno stato sicuramente funzionante a cui puoi tornare in seguito—in modo da poter confrontare, revisionare e implementare in sicurezza le modifiche future.
Passaggio 2: Aggiorna la dashboard
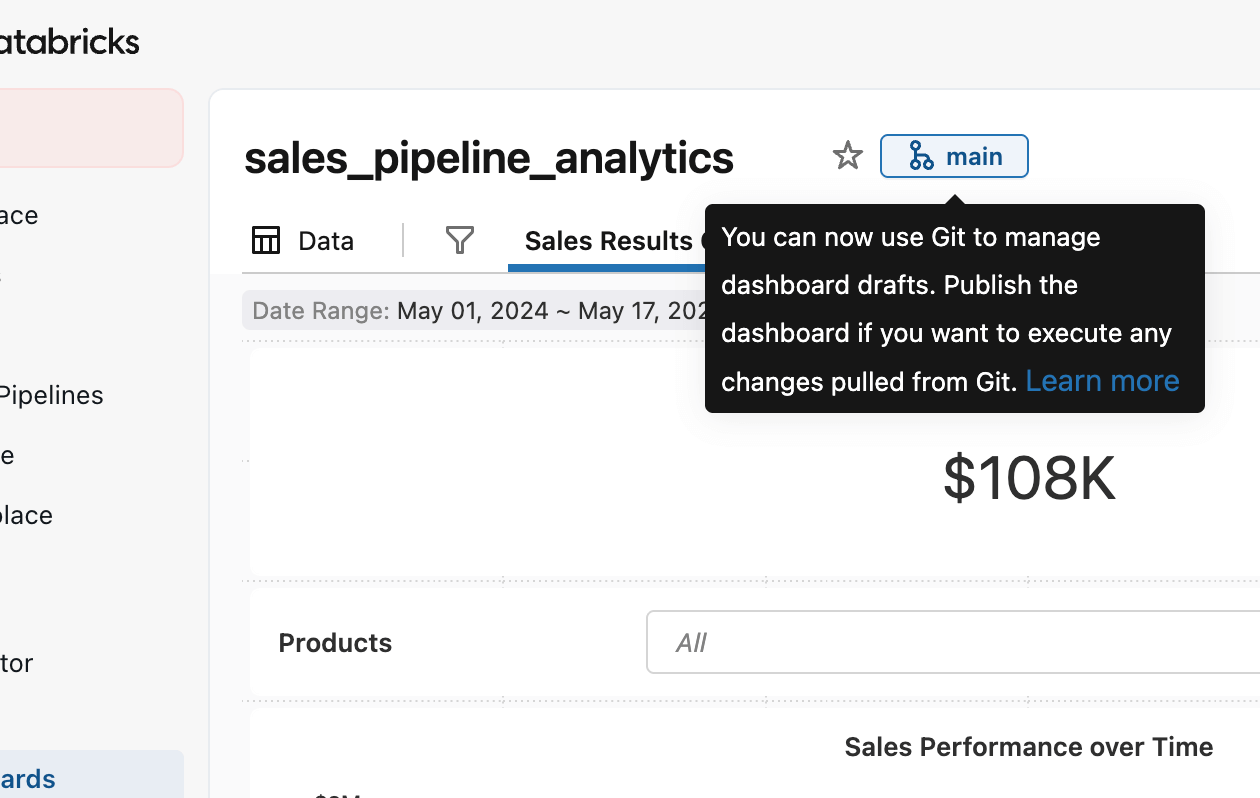
Ora che è stato eseguito il commit della dashboard esistente, puoi iniziare ad apportarvi modifiche senza influire su ciò che è già in produzione e Git terrà traccia delle modifiche specifiche che hai apportato.
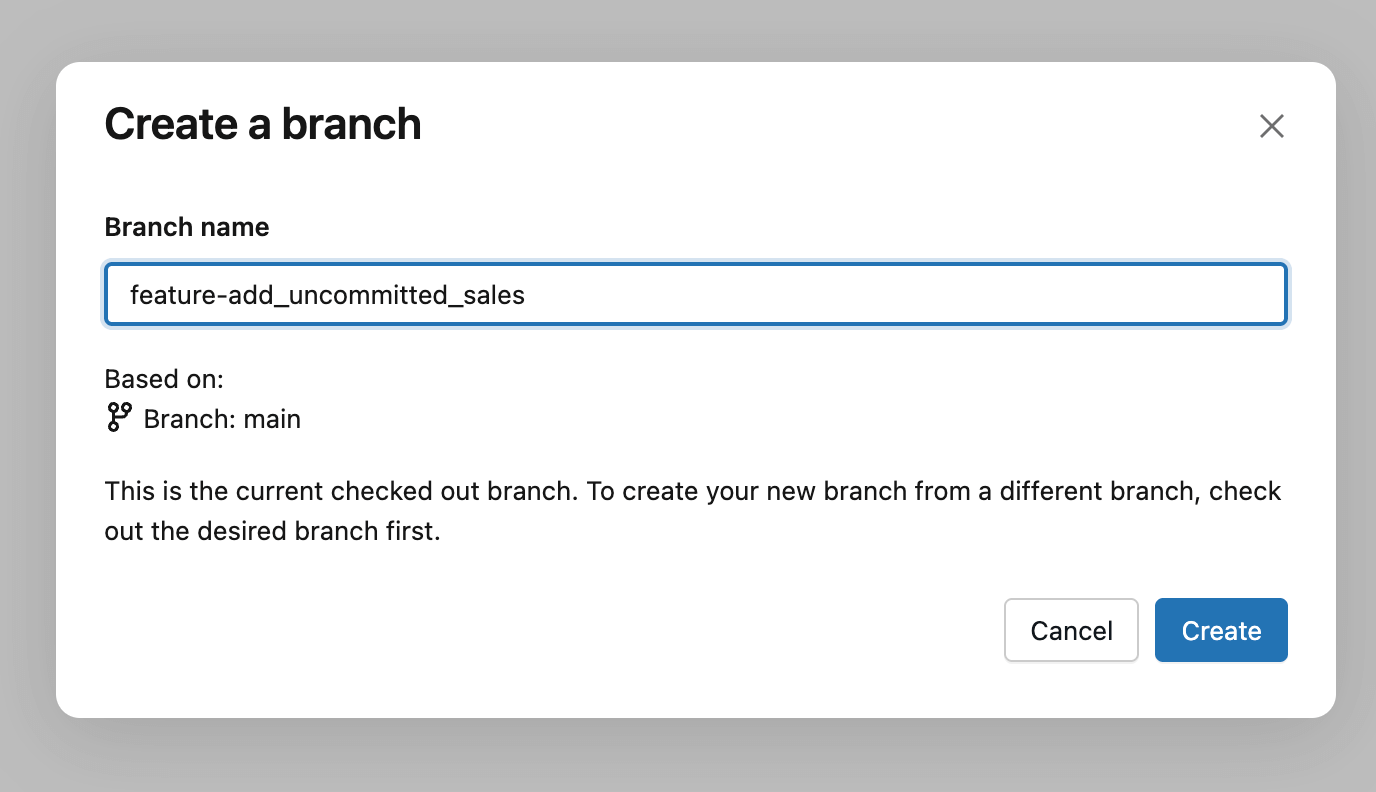
La prassi generale è creare un branch Git, ovvero una versione del dashboard su cui lavorare senza influire sugli altri. Puoi farlo tramite il pulsante Crea branch e assegnargli un nome descrittivo come il tuo nome, una funzionalità o il numero di ticket associato alla modifica. Considerala come una versione privata per il tuo aggiornamento: puoi modificare, testare e perfezionare liberamente il dashboard, per poi decidere separatamente quando le modifiche sono pronte per essere revisionate e distribuite.
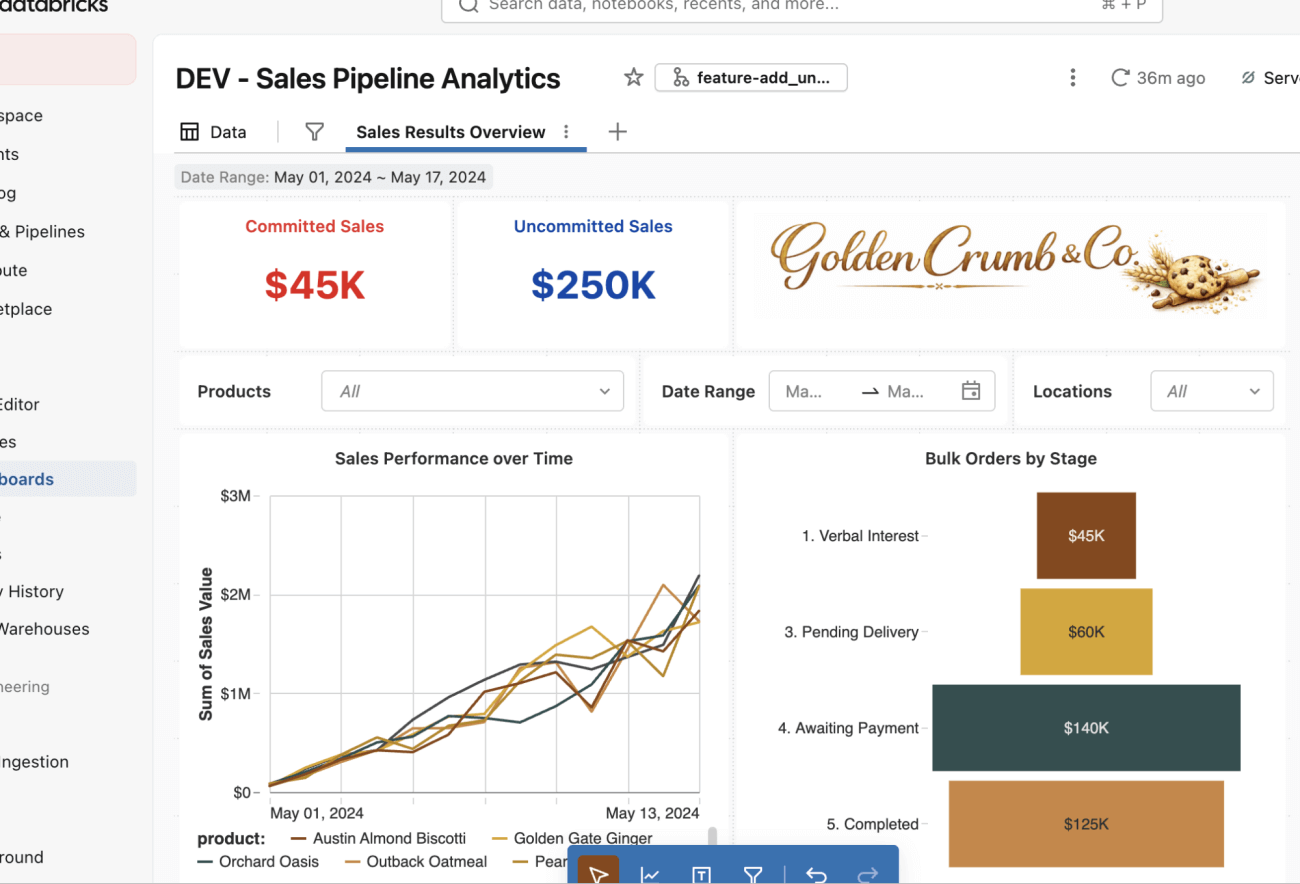
Ora puoi apportare le modifiche al dashboard! In questo caso, modificherai il numero delle vendite in alto a sinistra per aggiungere i contatori delle vendite non confermate e confermate (in grassetto blu e rosso per una maggiore visibilità).
Noterai che l'esperienza di creazione non cambia: apporta queste modifiche come faresti normalmente utilizzando l'editor dell'interfaccia utente della dashboard.
Una volta che il dashboard risulta corretto in fase di sviluppo, è possibile procedere per applicare le modifiche in produzione. Utilizzare lo stesso pulsante Git in alto come prima per eseguire il check-in di queste modifiche con un breve messaggio di commit.
Passaggio 3: Revisione della modifica
Successivamente, si ottiene un altro vantaggio chiave di questo flusso di lavoro: uno spazio in cui altri possono esaminare le modifiche e offrire feedback prima che la modifica venga rilasciata in produzione. La necessità di una revisione da parte di una seconda persona è una best practice generale ma, cosa altrettanto importante, crea uno spazio a basso rischio per discutere idee, convalidare ipotesi e perfezionare la modifica prima che abbia un impatto sulla reportistica.
Per avviare la revisione, crea una Pull Request (PR) nel tuo provider Git, che è essenzialmente una pagina di revisione per l'aggiornamento della dashboard. Il revisore può vedere esattamente cosa è cambiato, lasciare commenti da gestire e approvare l'aggiornamento una volta che è tutto a posto.
Durante la revisione, la dashboard di produzione rimane invariata. Si procede solo dopo che il feedback è stato gestito e la modifica approvata.
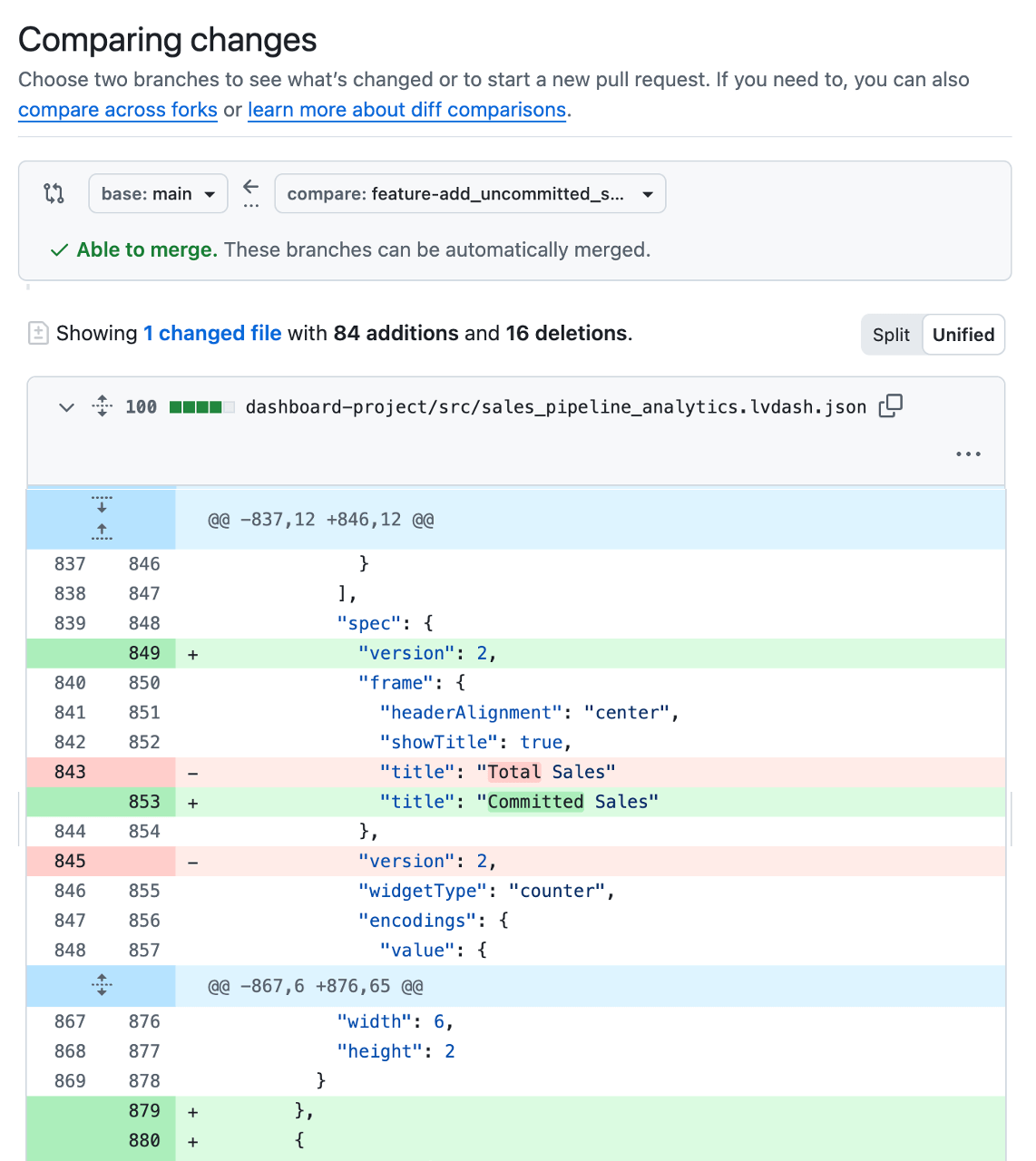
Anche se le modifiche alla dashboard vengono archiviate e monitorate come file di configurazione dietro le quinte, è spesso difficile capire cosa è cambiato effettivamente. Per questo motivo, la maggior parte dei team usa una piccola automazione per implementare automaticamente una versione di test temporanea della dashboard per la revisione ogni volta che viene aperta una PR. In questo modo, i revisori possono vedere le metriche, i calcoli e i layout proposti nel loro contesto prima che qualsiasi cosa arrivi in produzione e individuare problemi di logica dei dati o di UI. L'inclusione di screenshot o link alla dashboard di test direttamente nella PR da parte dello sviluppatore o del revisore rende inoltre il feedback più rapido e sicuro.
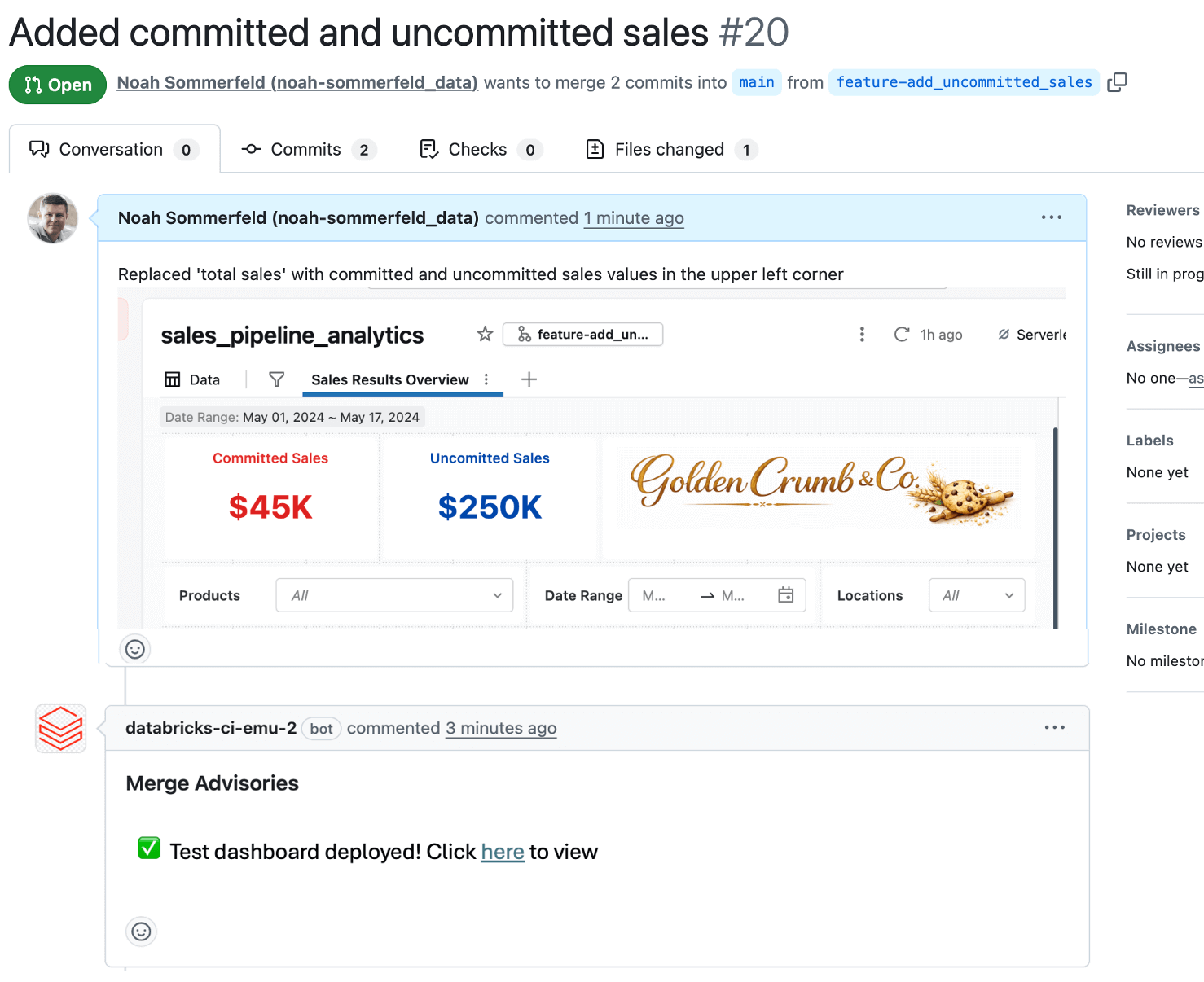
I revisori possono aggiungere commenti e approvare le modifiche, che vengono registrate per facilitarne la comprensione in un secondo momento.
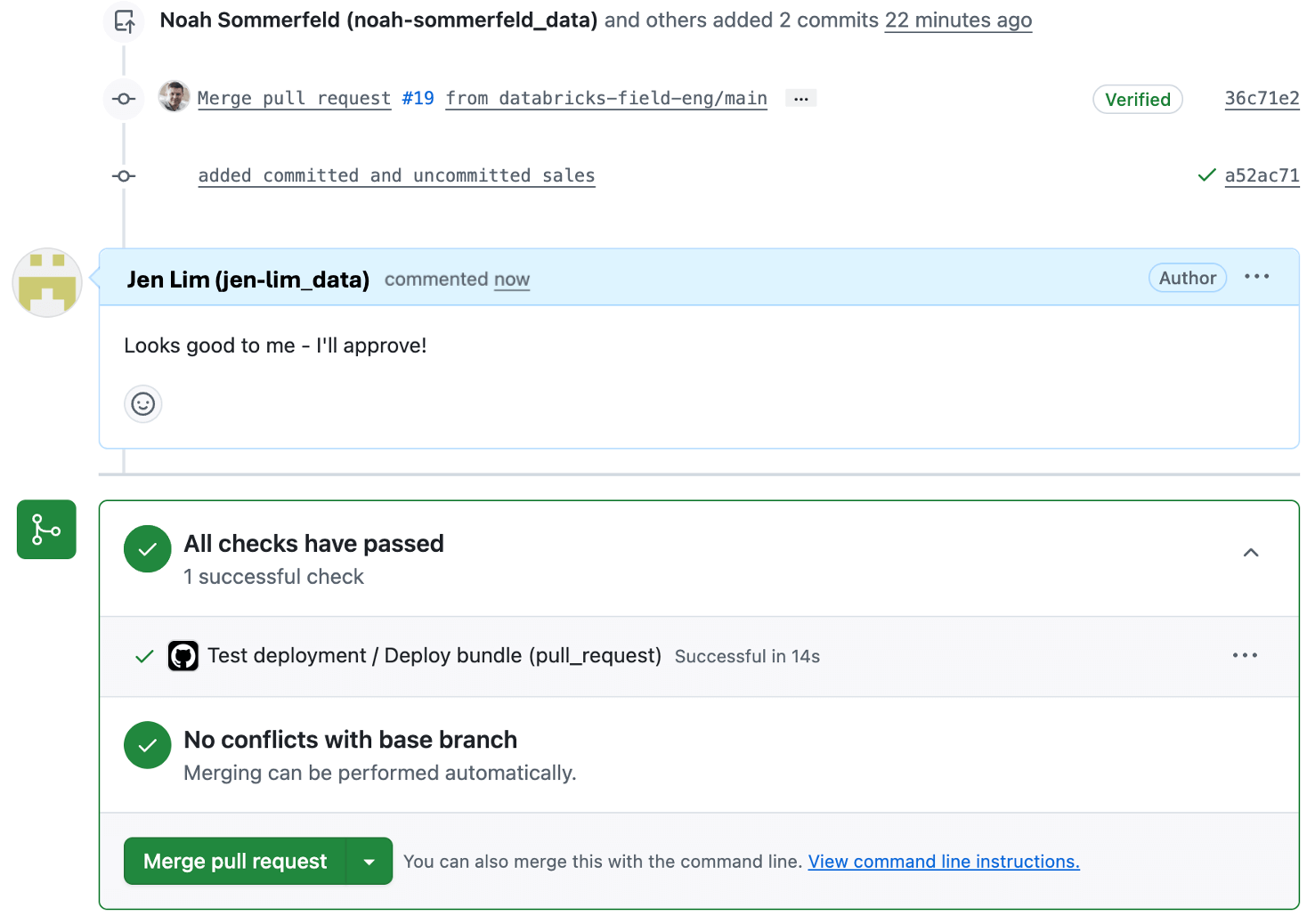
Passaggio 4: Implementazione della dashboard in produzione tramite il bundle
Una volta approvata la modifica, si è pronti per distribuire il dashboard in produzione.
Le dashboard spesso necessitano di impostazioni diverse in produzione rispetto allo sviluppo, ad esempio, puntando a un catalogo o schema di produzione invece che a un set di dati di sviluppo, o utilizzando un SQL warehouse diverso.
La buona notizia è che queste differenze sono previste e gestite come parte del processo di deployment.
Quando hai aggiunto la dashboard all'Asset Bundle, Databricks ha generato un piccolo .yml file di configurazione che acquisisce queste impostazioni specifiche per l'ambiente. Questo file consente di sovrascrivere i valori per ambiente senza modificare la logica della dashboard stessa. Nel nostro caso, abbiamo specificato che il catalogo utilizzato dalla dashboard in produzione deve essere diverso da quello in fase di test, utilizzando un valore ${variable} per il nome del catalogo.
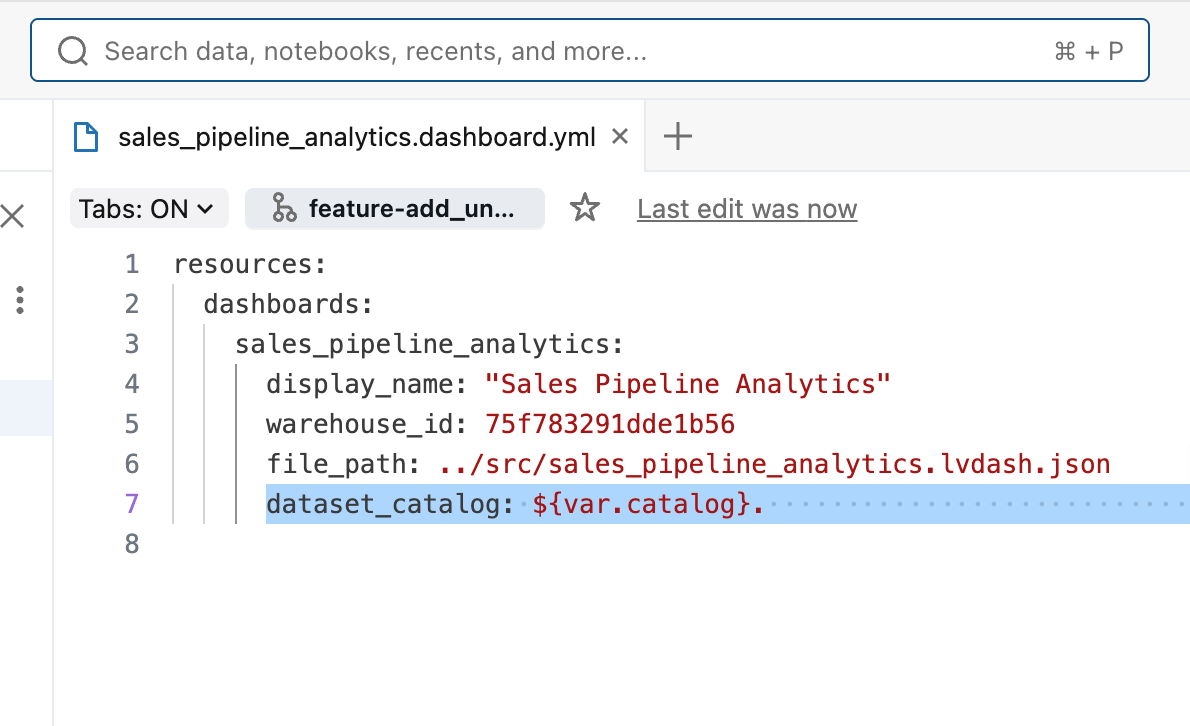
Infine, il file databricks.yml collega tutte le risorse del bundle e definisce quale catalogo viene utilizzato in ogni ambiente, facilitando la gestione di implementazioni coerenti tra i Workspace di sviluppo, test e produzione.
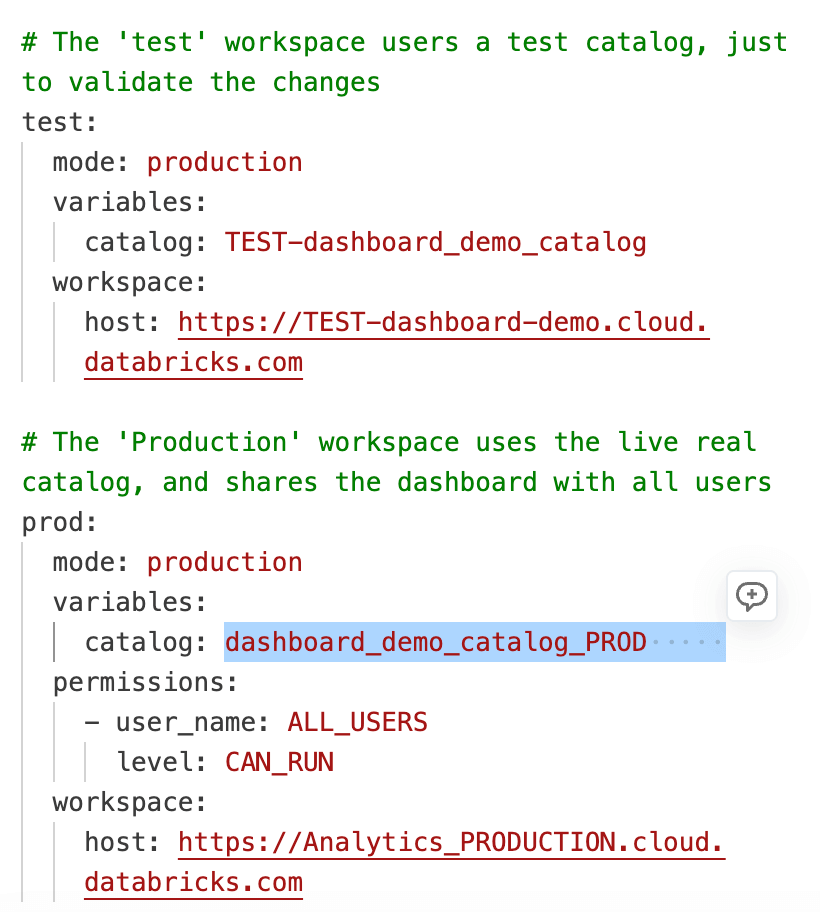
Una volta che la Pull Request è approvata e unita al ramo principale, l'automazione della distribuzione viene eseguita e utilizza i valori specifici dell'ambiente definiti in databricks.yml. Lo stesso codice della dashboard viene riutilizzato tra i Workspace, mentre impostazioni quali catalogo, schema e warehouse vengono applicate in base all'ambiente di destinazione. Ciò elimina la necessità di mantenere copie separate della dashboard per ogni workspace e garantisce che le modifiche abbiano un comportamento prevedibile ovunque.
Per la maggior parte dei provider Git, sarà possibile visualizzare l'automazione del deployment sulla pull request in modo da poter monitorare il deployment e confermarne il completamento (o l'eventuale insorgenza di un problema). Se si verifica un problema, il deployment si interrompe senza influire sulla dashboard di produzione esistente per consentire la risoluzione dei problemi. Una volta completato con successo il deployment, la dashboard aggiornata è attiva in produzione e pronta per gli stakeholder.
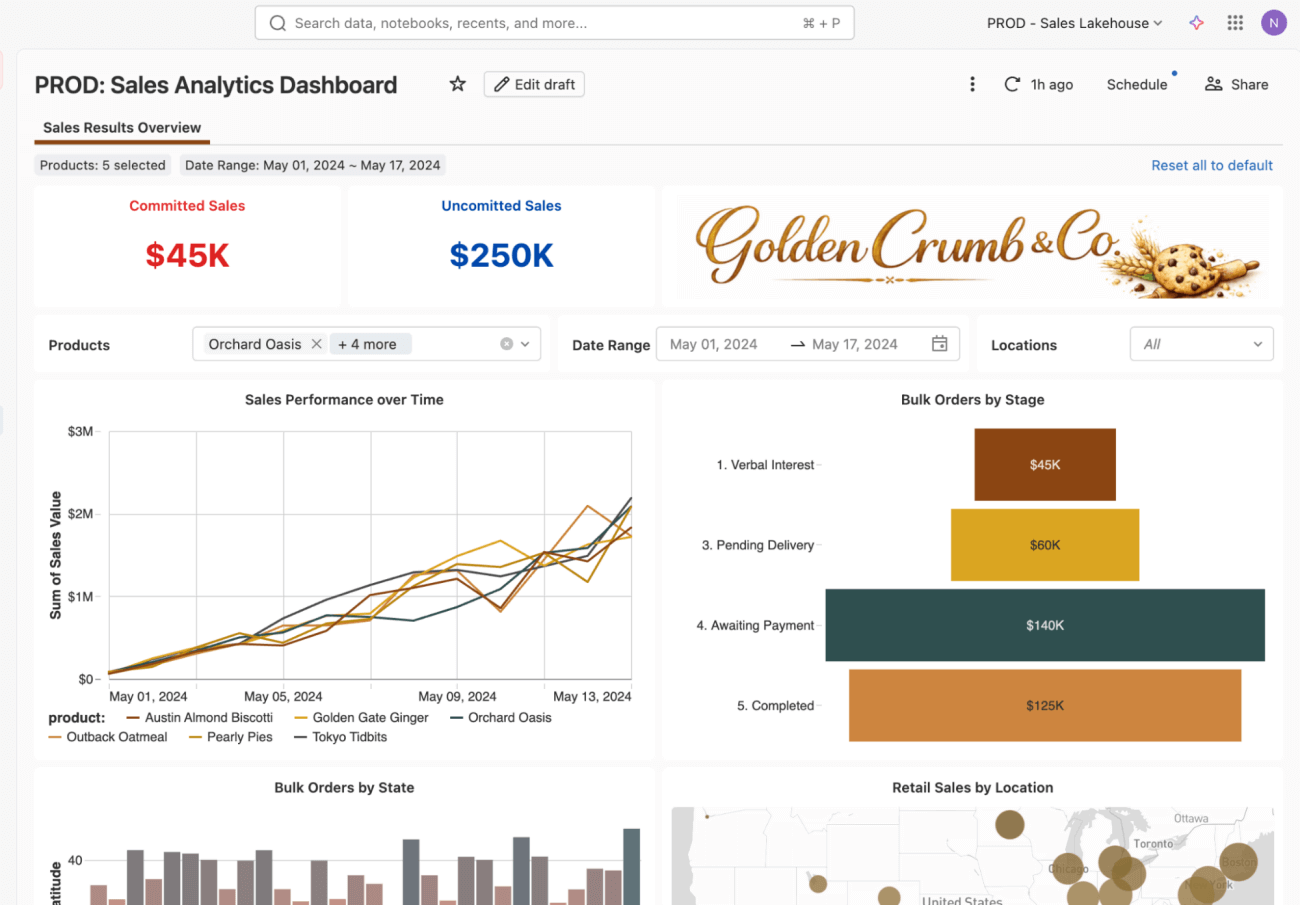
Bonus 1: Cosa fare se si desidera esaminare la cronologia?
Una volta che l'aggiornamento del dashboard è attivo, potresti aver bisogno di capire la cronologia delle modifiche: cosa, quando e perché è stato modificato. Un vantaggio di questo flusso è che la modifica è ora tracciabile. Invece di una modifica una tantum apportata direttamente in una workspace, appare come una sequenza di versioni salvate.
Ogni voce rappresenta un aggiornamento della dashboard, insieme all'autore e al timestamp. È possibile aprire qualsiasi voce per rivedere le modifiche ed eseguire il rollback, se necessario.
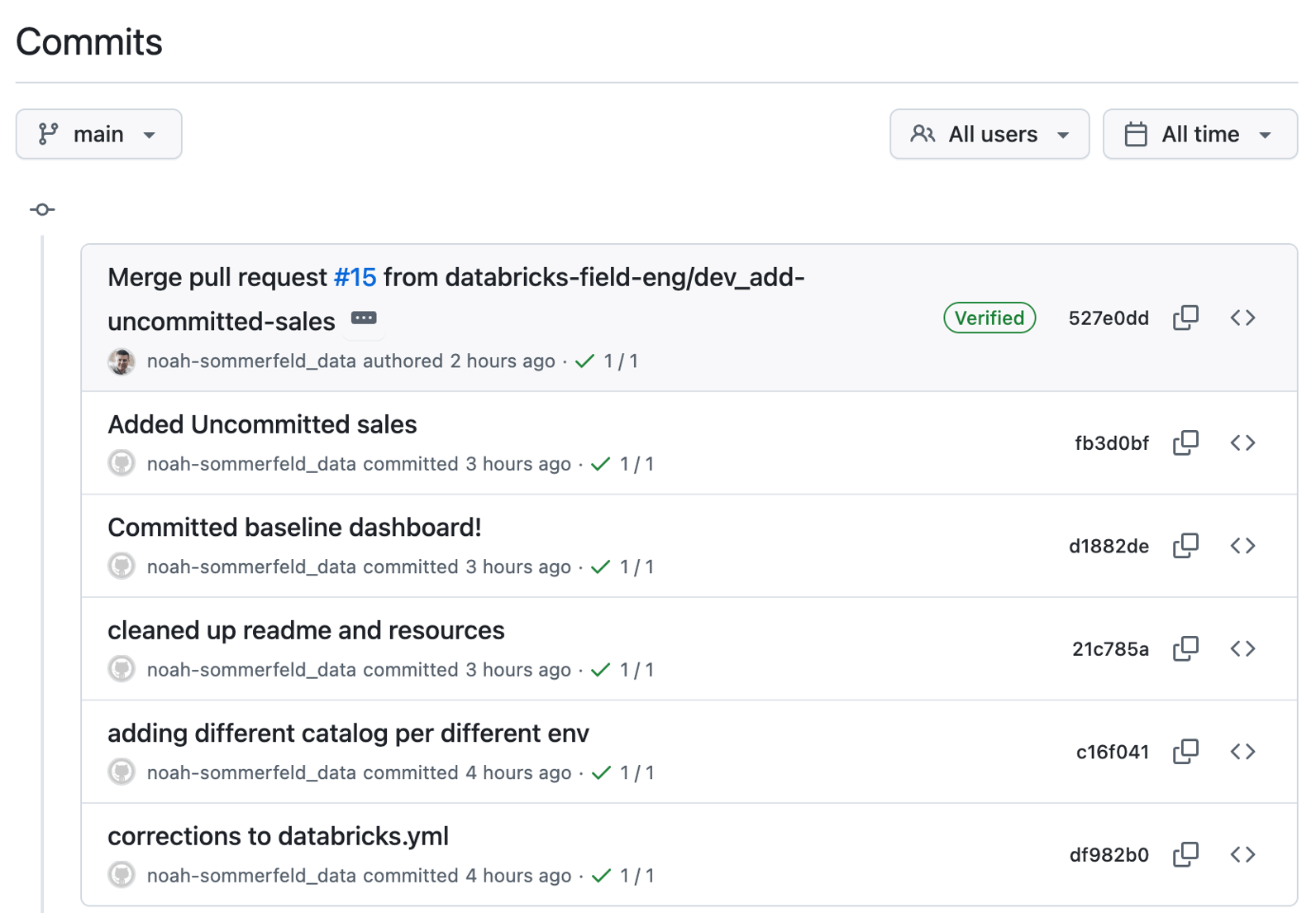
Bonus 2: Cosa fare se è necessario annullare una modifica?
Anche con una revisione e un test accurati, possono comunque emergere dei problemi, ad esempio una dashboard che non si carica o la definizione di una metrica che si rivela errata.
Poiché la dashboard è gestita tramite questo flusso di lavoro, è possibile eseguire il rollback a una versione valida nota utilizzando lo stesso processo controllato usato per distribuire l'aggiornamento.
Per iniziare, apri la cronologia delle modifiche della dashboard nel repository e individua l'aggiornamento che vuoi annullare. Da lì, puoi rivedere cosa è stato modificato per confermare che stai annullando la modifica corretta prima di procedere.
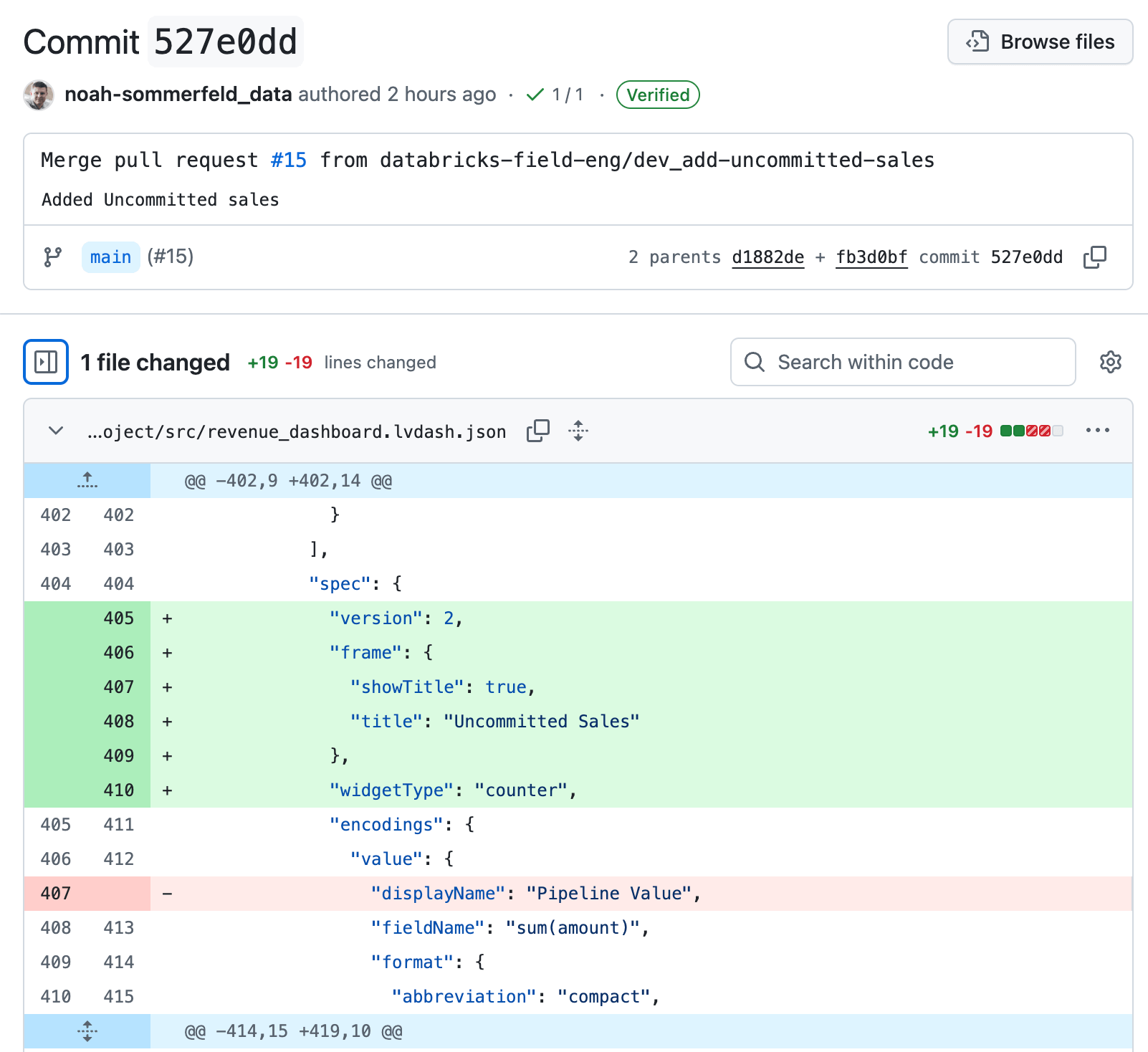
Dai dettagli della modifica, segui il link per tornare alla pagina di revisione. Per annullare l'aggiornamento, seleziona Ripristina. Questo crea una nuova modifica di "annullamento" che inverte solo quello specifico aggiornamento, ripristinando la logica precedente del dashboard e mantenendo intatta il resto della cronologia.
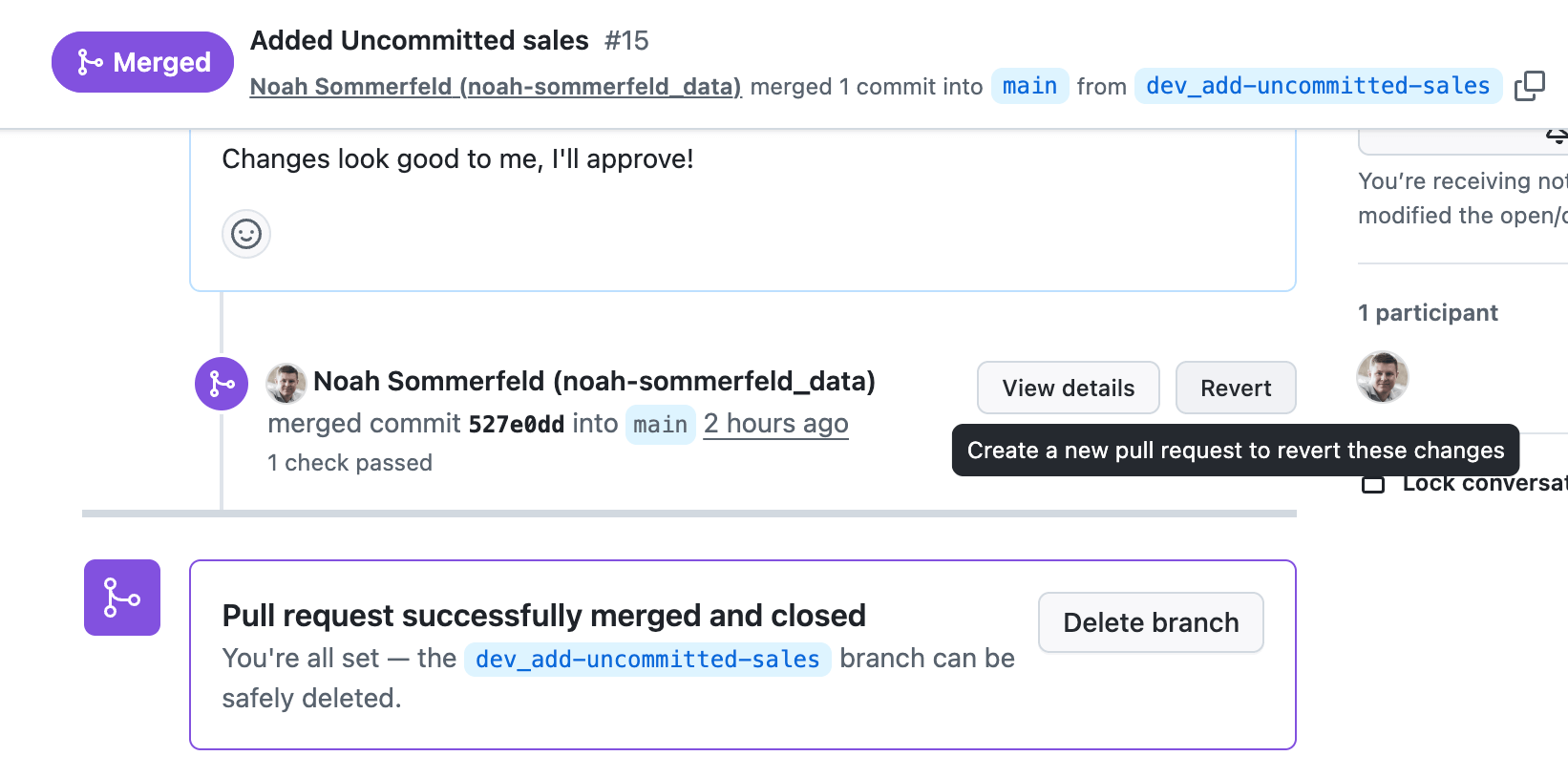
Una volta che la modifica viene Merge al branch principale, la stessa automazione che ha distribuito la dashboard in produzione ne eseguirà il rollback. Ciò significa che puoi rispondere a un'interruzione o a un problema di calcolo ad alto impatto in pochi minuti, senza aggirare i controlli già predisposti.
Bonus 3: Cosa succede se le tue sorgenti di dati vengono aggiornate?
La maggior parte delle dashboard è strettamente collegata alle proprie sorgenti di dati, il che significa che gli aggiornamenti di una dashboard sono spesso strettamente collegati agli aggiornamenti nelle pipeline. La buona notizia è che gli Asset Bundles sono progettati per raggruppare i componenti correlati in un unico pacchetto.
Ciò garantisce che una modifica del modello di dati upstream non colga mai di sorpresa e, quando le modifiche alla visualizzazione richiedono aggiornamenti del modello di dati, è possibile implementare entrambe le modifiche in un unico deployment.
Conclusione
Trattare le dashboard di AI/BI come prodotti di dati di livello produttivo è essenziale per decisioni aziendali affidabili e per la mitigazione dei rischi. In questo flusso di lavoro, una piccola serie di passaggi aggiuntivi rende le modifiche alla dashboard visibili, revisionabili e reversibili, senza modificare il modo in cui si creano le dashboard quotidianamente.
Gestendo i dashboard con Git e i Databricks asset Bundles, i team stabiliscono un flusso di lavoro di routine e prevedibile per gli aggiornamenti: apportare la modifica, revisionarla, testarla e distribuirla. Lo stesso processo si applica sia che l'aggiornamento sia una piccola modifica visiva o una modifica significativa della logica di business.
Con la giusta disciplina di distribuzione, le modifiche ai dashboard cessano di essere una fonte di rischio e diventano una fonte attendibile di informazioni dettagliate che si evolve con l'azienda anche in situazioni ad alto rischio come una riunione del consiglio di amministrazione.
Scopri di più + Passaggi successivi
Se hai trovato l'ispirazione e vuoi approfondire i componenti utilizzati in questo flusso di lavoro, ecco alcune risorse che sono un buon punto da cui continuare:
- "Strategia di branching" (AWS | Azure | GCP)
Scopri come le modifiche vengono Merge e implementate utilizzando un modello di branching che segue le best practice. - Databricks Asset Bundles (AWS | Azure | GCP)
Scopri come vengono usati gli Asset Bundles per creare pacchetti e distribuire le risorse di Databricks in modo coerente in tutti gli ambienti. - CI/CD per il deployment automatizzato su Databricks (AWS | Azure | GCP)
Scopri come implementare CI/CD con gli script di avvio di Github Actions (AWS | Azure | GCP) - Uso degli asset Bundle dalla UI di Databricks Workspace (AWS | Azure | GCP)
Scopri come creare, modificare e distribuire i bundle direttamente dal workspace. - Cartelle in Databricks basate su Git (AWS | Azure | GCP)
Scopri come funziona l'integrazione di Git in Databricks e come il controllo della versione si adatta ai flussi di lavoro di analitiche quotidiane.
Se sei pronto a fare il passo successivo con l'AI/BI di Databricks, puoi scegliere una delle seguenti opzioni:
- Edizione gratuita e di prova: acquisisci esperienza pratica iscrivendoti alla nostra edizione gratuita o di prova.
- Documentazione: approfondisci i dettagli con la nostra documentazione.
- Pagina web: visita la nostra pagina web per saperne di più.
- Demo: guarda i nostri video dimostrativi, partecipa ai tour del prodotto e segui i tutorial pratici per vedere in azione queste soluzioni di AI/BI.
- Addestramento: inizia con l'addestramento gratuito sul prodotto tramite la Databricks Academy.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.