Utilizzo di MemAlign per migliorare la valutazione del machine learning tradizionale in Genie Code
Colmare il divario tra giudici LLM ed esperti umani con MemAlign e MLflow.
di Stepan Nosov, Pavle Martinović, Tejas Sundaresan, Alkis Polyzotis e Nemanja Petrovic
- Genie Code genera notebook ML completi da prompt in linguaggio naturale — abbiamo creato nove giudici LLM per valutarne la qualità in dimensioni come l'addestramento del modello, l'imputazione dei dati e l'ingegneria delle feature.
- L'annotazione umana ha rivelato che i giudici erano in disaccordo con gli esperti fino a 0,68 MAE su una scala di 3 punti. MemAlign, un framework di allineamento open-source in MLflow, ha colmato questo divario utilizzando solo ~50 esempi etichettati.
- Nelle tre dimensioni peggiori allineate, MemAlign ha ridotto l'errore del giudice del 74-89%, e uno studio di follow-up ha dimostrato che sia la memoria semantica che quella episodica sono essenziali per il risultato.
Il Genie Code annunciato di recente è il partner AI autonomo di Databricks, creato appositamente per il lavoro sui dati. Ha sostituito Databricks Assistant, assorbendo diversi agenti e fornendo nuovi punti di integrazione e funzionalità. Genie Code ha una profonda integrazione con Unity Catalog, il che significa che comprende le tue tabelle, colonne, lineage, viste metriche e definizioni aziendali (semantica). Questa consapevolezza contestuale rende Genie Code molto più utile per i professionisti dei dati rispetto ai chatbot generici.
Quando Genie Code genera un notebook per attività ML tradizionali, come "costruisci un modello di previsione dell'abbandono", ci aspettiamo che produca un flusso di lavoro pronto per la produzione che includa l'installazione delle librerie Python appropriate, l'esplorazione e la pre-elaborazione dei dati, l'addestramento, l'ottimizzazione, la registrazione e il deployment del modello, e la valutazione delle sue prestazioni. Ci aspettiamo inoltre che ogni passaggio sia veramente informato dai dati: ad esempio, Genie Code dovrà comprendere che classi sbilanciate in un problema di classificazione binaria comportano flussi di lavoro e metriche di successo drasticamente diversi.
Per garantire che Genie Code segua costantemente le best practice native di Databricks ed eviti, ad esempio, di saltare la cross-validation, di non notare data leakage o di un'imputazione dati impropria, avevamo bisogno di un modo rigoroso per rispondere a una domanda: Come sappiamo se il codice generato è davvero valido? Il notebook generato dipenderà in gran parte dal problema che il cliente sta cercando di risolvere, e questo può variare enormemente tra clienti diversi, quindi questa è una domanda molto non banale.
In questo post, illustreremo come abbiamo costruito una pipeline di valutazione per le capacità ML tradizionali di Genie Code e come abbiamo utilizzato MemAlign (un nuovo framework di allineamento open-source in MLflow) per colmare l'enorme divario che abbiamo riscontrato tra i giudici LLM e gli esperti umani. I giudici migliorati ci hanno aiutato a identificare e correggere lacune nella guida ML di Genie Code che altrimenti avremmo trascurato.
Costruire il Framework di Valutazione
Un robusto framework di valutazione è necessario per:
- Hillclimbing: quantificare come prompt, strumenti, competenze e modifiche all'architettura influenzano l'output.
- Protezione contro le regressioni: Assicurarsi che il miglioramento dell'"Addestramento del Modello" non degradi accidentalmente l'"Esplorazione dei Dati".
- Benchmarking: Misurare come diversi modelli di base (backend LLM) influiscono sulla qualità del notebook.
- CI: Monitorare come le modifiche al loop agentico sottostante si ripercuotono sui task ML finali.
La valutazione dei notebook ML tradizionali è uno dei task di valutazione più complessi in quanto copre la valutazione della qualità del codice, delle best practice ML e degli adattamenti/personalizzazioni basati sui dati. Per gestire un task ampio e disordinato come la valutazione dei notebook ML, utilizziamo un LLM-as-a-judge - un "esperto" LLM istruito dagli umani su come dovrebbe essere un buon notebook. Abbiamo creato nove giudici a cui viene chiesto di valutare i notebook ML secondo nove dimensioni che appaiono nella maggior parte dei flussi di lavoro ML:
| Dimensioni | Cosa valutiamo |
|---|---|
| Installazione Libreria | Dipendenze corrette |
| Analisi Esplorativa dei Dati | EDA approfondita e |
| Imputazione Dati | Tempo Medio per Contenere |
| Gestione dei valori mancanti senza leakage. | Feature Engineering |
| Selezione/trasformazione delle feature. | Addestramento del Modello |
| Selezione del modello, Cross Validation, Ottimizzazione degli iperparametri | Riutilizzo del modello addestrato per fare inferenza. |
| Valutazione delle Metriche | Logica di inferenza e metriche appropriate al task (es. MAPE per forecasting, MAE per regressione, Accuracy per classificazione). |
| Logging MLflow | Configurazione del tracciamento degli esperimenti. |
| Organizzazione delle Celle | Suddivisione del codice in celle, pulizia del codice, leggibilità, intestazioni markdown, logging appropriato. |
Per ogni dimensione, abbiamo scritto delle rubriche di punteggio (riutilizzate tra valutatori umani e giudici LLM) che assegnano un punteggio da 1 a 3, e 0 per "non applicabile":
- 3 (Buono): Il notebook soddisfa un alto standard per una dimensione. Dimostra best practice, copre l'ambito previsto e gestisce correttamente i casi limite.
- 2 (Medio): Accettabile ma con lacune. Le basi sono presenti, ma il notebook manca di rifiniture che un professionista esperto si aspetterebbe.
- 1 (Scadente): Problemi fondamentali. Passaggi chiave mancanti, errati o applicati in modo tale da portare a conclusioni errate.
- N/A (Non Applicabile): Questa dimensione non è applicabile a questo prompt (es. la dimensione imputazione dati non può essere applicata se il set di dati non ha valori mancanti).
Per dare un'idea della granularità, ecco la rubrica specifica che utilizziamo per la dimensione "imputazione dati":
Insieme ai giudici, manteniamo un set di casi di test di valutazione che coprono una gamma di task ML (classificazione, regressione, forecasting), attraverso diverse dimensioni di dataset, domini e livelli di complessità. Ogni caso di test include un prompt utente che dice a Genie Code il task ML che dovrebbe risolvere sul dataset specificato ("Ho dati sui passeggeri nelle tabelle titanic_train_table e titanic_test_table. Puoi capire chi è sopravvissuto?"). Il ciclo di valutazione consiste nell'utilizzare Genie Code per generare un notebook (o più di uno) per ogni caso di test, e quindi valutare ogni notebook lungo tutte le dimensioni applicabili.
Valutare il sistema di valutazione
Utilizzando giudici LLM, invece di umani, per valutare gli artefatti di Genie Code, abbiamo essenzialmente scambiato un problema difficile con un altro: il giudice out-of-the-box è inesperto sul compito da svolgere e non allineato con le valutazioni umane. Il nostro problema è far sì che i punteggi dei giudici LLM si allineino con quelli dei valutatori umani.
Il set di valutazione per la valutazione dei giudici LLM contiene 50 notebook generati da Genie Code ("casi di test") in cui esperti umani hanno valutato ogni dimensione applicabile, fornendo sia un punteggio che una breve giustificazione per servire come nostro ground truth. Nelle zone grigie tra due punteggi, ai valutatori è stato permesso di esprimere il proprio giudizio, ma gli schemi sono stati scritti in modo tale che questo accada raramente.
La misura dell'allineamento umano-macchina è l'errore assoluto medio (MAE) tra i punteggi in ciascuna dimensione. I risultati sono stati misti, alcune dimensioni hanno mostrato un forte allineamento (4 dimensioni avevano un MAE di <= 0.10), mentre altre hanno rivelato un disaccordo significativo:
- Addestramento del Modello: MAE di 0.680
- Utilizzo del Modello: MAE di 0.562
- Imputazione Dati: MAE di 0.474
- Esplorazione Dati: MAE di 0.407
Questo divario esiste perché gli umani e gli LLM non interpretano la stessa rubrica nello stesso modo. Mentre un valutatore umano può individuare una strategia di imputazione sottilmente difettosa o un ciclo di addestramento che "funziona" ma è logicamente insensato, un giudice LLM spesso perde quella sfumatura tecnica. Abbiamo anche scoperto che il giudice soffriva di un classico bias di positività - era semplicemente troppo "gentile" e questo ha ostacolato l'ottenimento di risultati oggettivi.
È diventato lampante che, data la stessa rubrica, i giudici LLM e gli umani non avrebbero prodotto gli stessi risultati - un disallineamento. Questo è esattamente lo scenario per cui MemAlign è stato progettato.
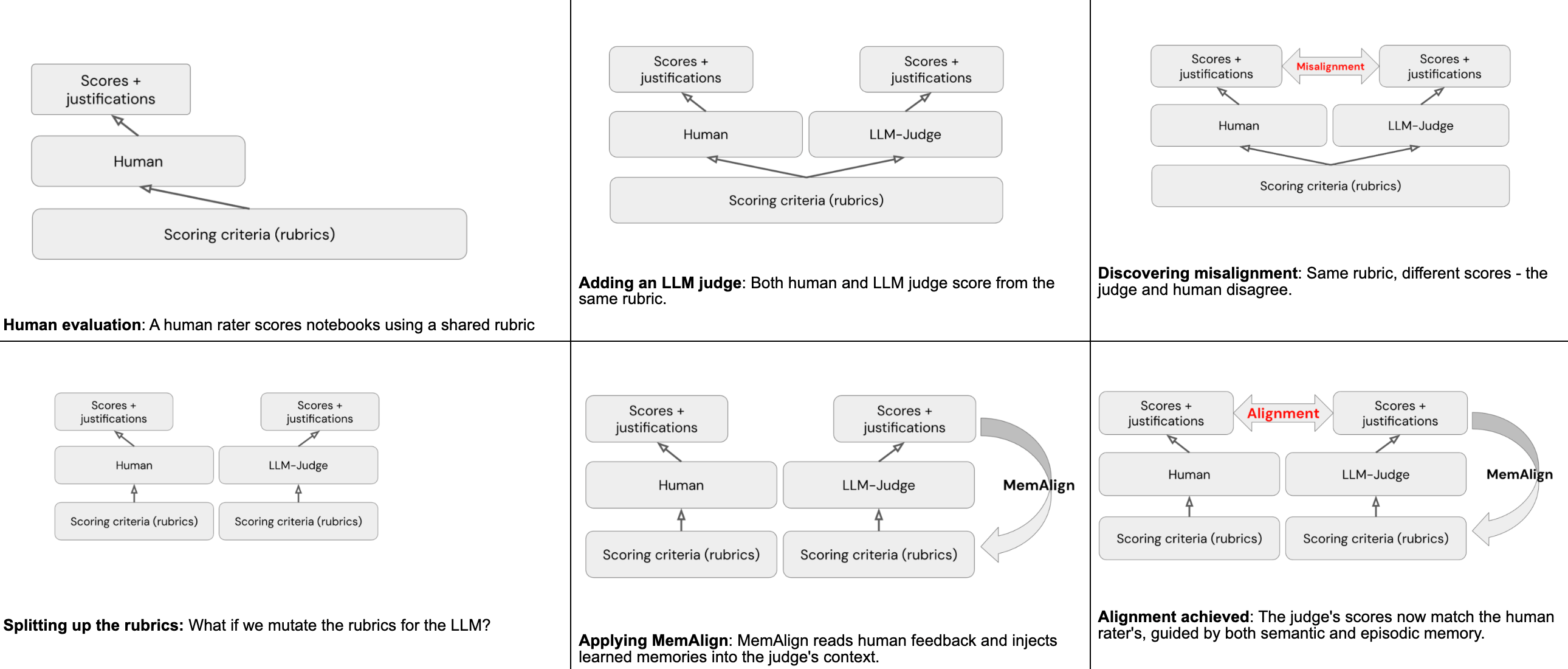
Utilizzare MemAlign per l'allineamento
MemAlign è un framework all'interno di MLflow che può, dato una piccolissima quantità di feedback in linguaggio naturale umano, eseguire l'allineamento tra i valutatori umani e i giudici LLM. Questo viene ottenuto attraverso due tipi di "memorie" formate leggendo il feedback umano:
- Memoria semantica memorizza linee guida generalizzate - regole distillate dal feedback che si applicano ampiamente
- Memoria episodica memorizza esempi specifici - casi in cui il giudice ha sbagliato, conservati come punti di riferimento per decisioni future
Al momento dell'inferenza, MemAlign costruisce un contesto di lavoro estraendo tutte le linee guida semantiche e recuperando gli esempi episodici più pertinenti per l'input corrente. Il giudice carica tutto questo nel suo contesto, insieme alla rubrica originale, e utilizza la conoscenza accumulata per assegnare un punteggio più accurato a tutti i notebook futuri.
La proprietà chiave che ha reso MemAlign eccezionale sono le alte prestazioni ottenute utilizzando solo un piccolo numero di esempi. Questo perché MemAlign distilla efficacemente l'apprendimento da ricchi segnali di apprendimento nel feedback del linguaggio naturale e li incorpora nel sistema a doppia memoria.
Ecco un esempio di alcuni frammenti di memoria semantica generati per la dimensione "imputazione dei dati", che colma le lacune nella rubrica precedentemente definita fornendo generalmente punti di riferimento, esempi e controesempi:
Inoltre, come menzionato in precedenza, la memoria semantica riflessa nel prompt è integrata con esempi pertinenti dalla memoria episodica del giudice al momento della valutazione, fornendo così al giudice ancora più contesto per interpretare le istruzioni ottimizzate.
Progettazione dell'Esperimento
Validazione Incrociata K-Fold
Seguendo il paradigma di addestramento-test ML, abbiamo applicato la validazione incrociata K-fold (K=4) su 50 casi di test (notebook) evitando così la fuga di dati e la necessità di etichettare un set di test separato. Per ogni fold abbiamo fatto quanto segue:
- Fase di addestramento: MemAlign ha allineato il giudice utilizzando le tracce degli altri fold per ottenere il giudice.
- Fase di valutazione: Abbiamo valutato i notebook nel fold i con il giudice.
Intervalli di Confidenza Bootstrap
Per calcolare gli intervalli di confidenza senza dati etichettati aggiuntivi, abbiamo generato 100 campioni bootstrap con reimmissione dai 50 originali. Ripetendo questo processo 10.000 volte e monitorando la MAE tra i punteggi umani e quelli della macchina, abbiamo calcolato gli intervalli di confidenza per l'allineamento uomo-macchina con un CI al 95% che definisce un cambiamento statisticamente significativo.
Implementazione
La pipeline di valutazione è implementata come un singolo snippet MLflow che orchestra l'intero processo:
L'ottimizzatore MemAlign è in grado di allineare i giudici LLM basandosi sulle tracce dei casi di test in poche righe di codice. Abbiamo utilizzato questo nuovo giudice "allineato" per calcolare la nuova MAE. L'allineamento di un giudice su una singola dimensione richiede circa 25 secondi per fold, quindi l'allineamento stesso non rappresenta un collo di bottiglia.
Risultati
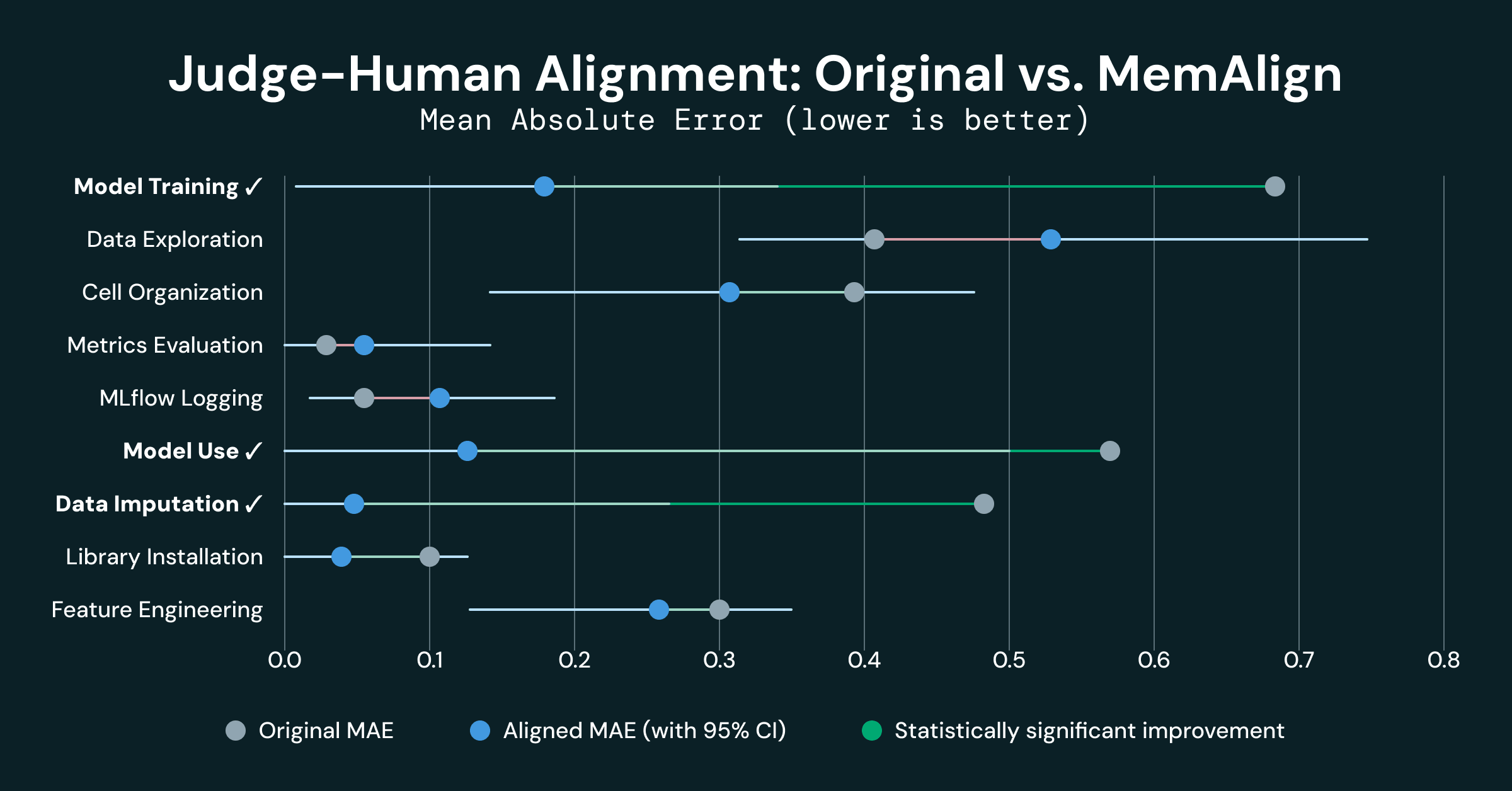
Tre delle 9 dimensioni hanno mostrato un miglioramento statisticamente significativo:
- Addestramento del modello migliorato di 0.500 MAE (0.680 → 0.180), una riduzione del 74%
- Utilizzo del modello migliorato di 0.438 MAE (0.562 → 0.125), una riduzione del 78%
- Imputazione dei dati migliorata di 0.421 MAE (0.474 → 0.053), una riduzione dell'89%
Queste 3 dimensioni sono tra le 4 dimensioni iniziali che erano fortemente disallineate. Un debole allineamento iniziale è indicativo del fatto che gli LLM e gli umani hanno una comprensione fondamentalmente diversa delle rubriche condivise, e la memoria iniettata da MemAlign sembra fornire un contesto sufficiente per farli "trovare un'intesa".
- La valutazione delle metriche e il logging MLflow erano già ben allineati (MAE < 0.10 originariamente), e il loro degrado non è statisticamente significativo (rumore sperimentale)
- L'esplorazione dei dati ha mostrato una leggera regressione (-0.130), ma non statisticamente significativa dato il suo intervallo di confidenza [-0.33, +0.09]. Questa dimensione ha mostrato la più alta varianza inter-valutatore, e questo rumore ha impedito a MemAlign di migliorare (e potrebbe persino averlo ostacolato).
Esperimento con Solo Memoria Semantica
La struttura a doppia memoria di MemAlign ci ha portato a chiederci se entrambe stessero effettivamente contribuendo all'allineamento del giudice. In particolare, la memoria episodica dovrebbe aiutare il giudice fornendo un set dei notebook annotati più simili come punto di riferimento (utilizzando la ricerca del vicino più prossimo). Ma cosa succede se i notebook recuperati (vicini più prossimi) non sono effettivamente simili a quello corrente, ma solo i meno dissimili? Caricarli nel contesto del giudice potrebbe confondere le cose anziché aiutare. Lo spazio problematico che stiamo valutando (notebook ML) è molto ampio, e inizialmente avevamo ipotizzato che un set di 50 notebook non sarebbe stato sufficiente per ottenere un set di memorie sufficientemente denso da far ricordare al giudice.
Senza memoria episodica, il quadro degrada sostanzialmente:
- L'addestramento del modello migliora ancora (+0.420), ma il guadagno è inferiore rispetto a +0.500 con MemAlign completo, e la MAE allineata è 0.260 contro 0.180.
- L'utilizzo del modello perde completamente la significatività statistica - il miglioramento scende da +0.438 a +0.294, con l'intervallo di confidenza che ora attraversa lo zero.
- L'imputazione dei dati passa da una riduzione dell'errore dell'89% a nessun miglioramento - la MAE allineata è uguale alla MAE originale (0.455).
- Il logging MLflow e la valutazione delle metriche regrediscono significativamente. Senza esempi episodici a cui ancorare il giudice, le linee guida distillate introducono rumore nelle dimensioni che erano già ben calibrate, spingendo il logging MLflow da 0.062 a 0.396 MAE.
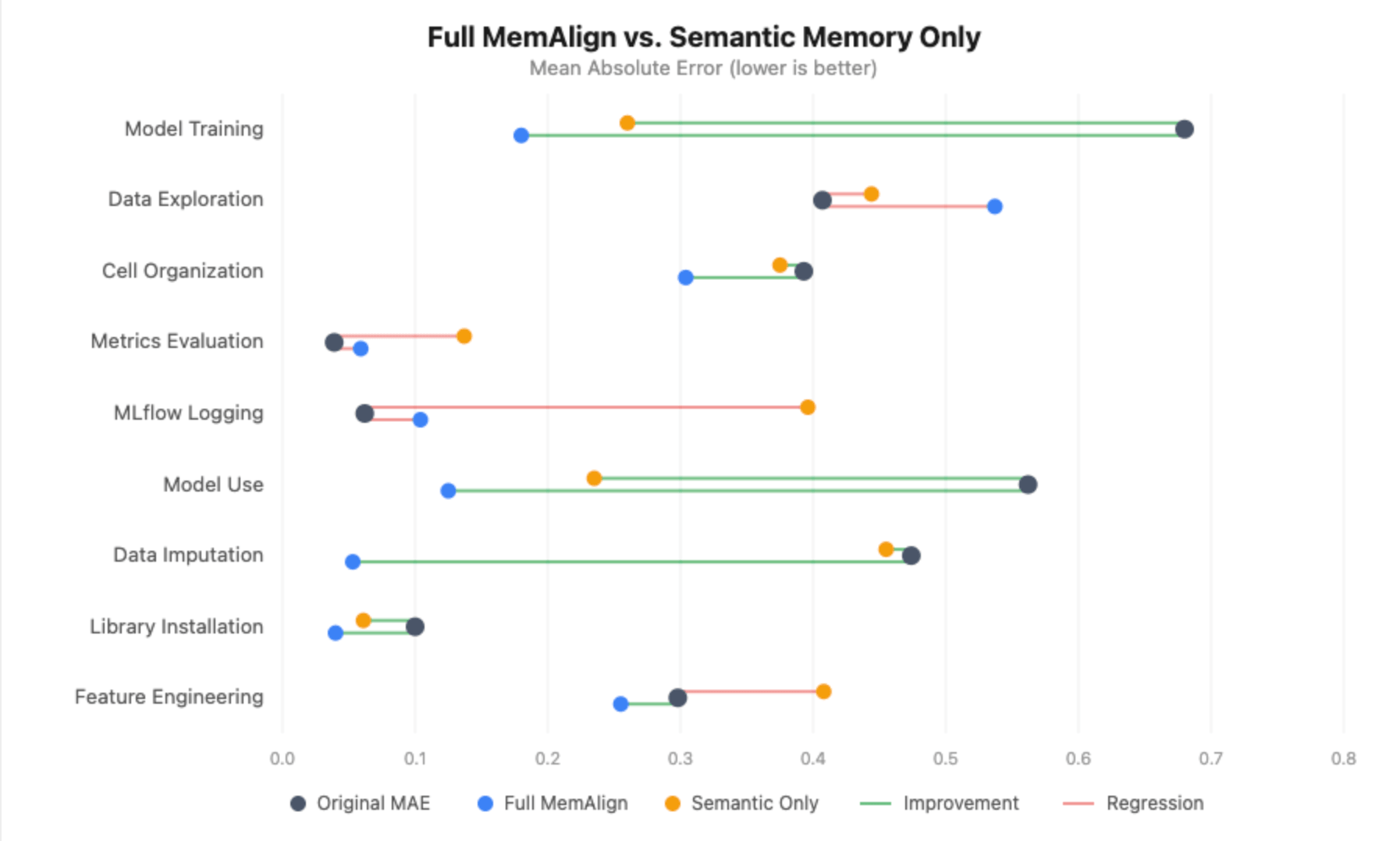
Questo era l'opposto di quanto ci aspettavamo. Avevamo inizialmente ipotizzato che il nostro set sparso annotato avrebbe confuso il giudice, ma quasi tutte le dimensioni sono peggiorate senza memoria episodica. L'unica eccezione è stata l'Esplorazione dei Dati, dove l'eliminazione degli esempi episodici potrebbe aver effettivamente aiutato - senza i notebook specifici su cui i nostri annotatori non erano d'accordo, il giudice aveva solo le linee guida distillate e un segnale meno rumoroso su cui lavorare.
Il punto chiave: anche quando i tuoi input sono grandi e disordinati, la memoria episodica migliora drasticamente le prestazioni del giudice. Sia la memoria semantica che quella episodica sono fondamentali per il funzionamento di MemAlign.
Conclusione: Colmare il Divario di Esperti
Giudicare se un agente di codifica sta facendo il suo lavoro è già abbastanza difficile, mentre valutare un partner AI autonomo nella costruzione e nell'esecuzione di flussi di lavoro ML tradizionali è a un altro livello di complessità. A causa della rapida iterazione sui prodotti AI, non c'è abbastanza tempo per far monitorare agli esperti la "integrazione continua" dell'agente. L'unica soluzione scalabile praticabile sono i giudici LLM - ma abbiamo ancora bisogno di una giuria di umani per tenere sotto controllo il giudice LLM.
Applicando MemAlign, abbiamo ridotto l'errore del giudice del 74-89% nelle dimensioni in cui contava di più. Ma, come per qualsiasi lavoro ML/LLM, il risultato è buono solo quanto le informazioni che inserisci, quindi assicurati che l'etichettatura sia competente.
Punti chiave:
- Misura il tuo sistema di misurazione: Un sistema rumoroso non è ideale per la valutazione e, finché non abbiamo investito tempo e risorse per convalidare e migliorare effettivamente i giudici, non potevamo fidarci del nostro sistema di valutazione.
- Le rubriche da sole non bastano: Ci sono sottili differenze tra il modo in cui un essere umano percepisce le istruzioni e il modo in cui un LLM le percepisce. Queste differenze dovrebbero essere considerate e strumenti di allineamento come MemAlign sono un modo efficace per colmare il divario.
- Qualità delle etichette > quantità: Quando gli annotatori umani non sono d'accordo tra loro (come abbiamo visto nella regressione della nostra esplorazione dati), l'allineamento non ha un segnale coerente da cui imparare.
MemAlign viene fornito con MLflow e ha funzionato per noi con solo ~50 esempi etichettati. Se i tuoi giudici LLM non corrispondono ai tuoi esperti, vale la pena dedicare un pomeriggio.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.