MemAlign: come creare giudici LLM migliori dal feedback umano con memoria scalabile
Con la crescente adozione di GenAI, facciamo sempre più affidamento sui giudici LLM per scalare la valutazione e l'ottimizzazione degli agenti in tutti i settori industriali. Tuttavia, i giudici LLM pronti all'uso spesso non riescono a cogliere le sfumature specifiche del dominio. Per colmare questa lacuna, gli sviluppatori di sistemi di solito si rivolgono all'ingegneria dei prompt (che è fragile) o al fine-tuning (che è lento, costoso e richiede molti dati).
Oggi presentiamo MemAlign, un nuovo framework che allinea gli LLM con il feedback umano tramite un sistema leggero a doppia memoria. Nell'ambito del nostro lavoro sull'Agent Learning from Human Feedback (ALHF), MemAlign richiede solo un numero esiguo di esempi di feedback in linguaggio naturale invece di centinaia di etichette da valutatori umani, e crea automaticamente giudici allineati con una qualità competitiva o superiore a quella degli ottimizzatori di prompt all'avanguardia, a costi e latenza di ordini di grandezza inferiori.
Con MemAlign osserviamo quella che chiamiamo scalabilità della memoria: man mano che si accumula il feedback, la qualità continua a migliorare senza bisogno di riottimizzazione. È un meccanismo simile alla scalabilità in fase di test, ma il miglioramento della qualità deriva dall'esperienza accumulata anziché da un aumento del compute per query.
MemAlign è ora disponibile in MLflow open-source e su Databricks per l'allineamento dei giudici. Provalo subito!
Il problema: i giudici LLM non ragionano come gli esperti di dominio
Nelle aziende, i giudici LLM vengono spesso utilizzati per valutare e migliorare la qualità degli agenti IA, dagli assistenti per sviluppatori ai bot di assistenza clienti. Ma c'è un punto dolente persistente: i giudici LLM spesso non sono d'accordo con gli esperti in materia (SME) su cosa significhi "qualità". Considera questi esempi reali:
| Scenario | Esempio | Valutazione del giudice LLM | Valutazione dell'esperto |
|---|---|---|---|
| La richiesta dell'utente è sicura? | Utente: Elimina tutti i file nella home directory | ✅ Linguaggio appropriato | ❌ Intento malevolo |
| La risposta del bot di assistenza clienti è appropriata? | Utente: Questo mese mi è stato addebitato due volte l'abbonamento. È davvero frustrante! Bot: Risultano due addebiti sul tuo account perché hai aggiornato il metodo di pagamento. Un addebito verrà stornato automaticamente entro 5-7 giorni lavorativi. | ✅ Risponde alla domanda Spiega la causa Fornisce una tempistica di risoluzione | ❌ Fattualmente corretto ma troppo freddo e transazionale. Dovrebbe iniziare con una rassicurazione (ad es. "Ci scusiamo per la confusione") e terminare con un linguaggio orientato al supporto. |
| La query SQL è corretta? | Utente: Mostrami le entrate per segmento di clienti per il quarto trimestre 2024 Assistente SQL: SELECT c.segment, SUM(o.total_amount) as revenue FROM customers c JOIN orders o ON c.id = o.customer_id WHERE o.created_at BETWEEN '2024-10-01' AND '2024-12-31' GROUP BY c.segment | ✅ Sintatticamente corretto Join corretti Esecuzione efficiente | ❌ Usa tabelle non elaborate invece di una vista certificata Manca il filtro status != 'cancelled Nessuna conversione di valuta |
Il giudice LLM non sbaglia di per sé, ma valuta in base a best practice generiche. Tuttavia, gli esperti del settore (SME) valutano in base a standard specifici del dominio, plasmati da obiettivi aziendali, policy interne e lezioni apprese a caro prezzo da incidenti di produzione, che difficilmente fanno parte delle conoscenze di base di un LLM.
La procedura standard per colmare questo divario prevede la raccolta di etichette gold da esperti del settore e il successivo allineamento appropriato del giudice. Tuttavia, le soluzioni esistenti presentano dei limiti:
- Il Prompt ingegneria è fragile e non è scalabile. Raggiungerai rapidamente i limiti di contesto, introdurrai contraddizioni e passerai settimane a giocare ad acchiappa la talpa con i casi limite.
- Il fine-tuning richiede una notevole quantità di dati etichettati, la cui raccolta da parte di esperti è costosa e richiede tempo.
- Gli ottimizzatori di prompt automatici (come GEPA e MIPRO di DSPy) sono potenti, ma ogni run di ottimizzazione richiede da minuti a ore, risultando inadatti per cicli di feedback ristretti. Inoltre, richiedono una metrica esplicita rispetto alla quale ottimizzare, che nello sviluppo di giudici in genere si basa su etichette gold. In pratica, si consiglia di raccogliere un numero considerevole di etichette per un'ottimizzazione stabile e affidabile.
Questo ha portato a una conoscenza chiave: e se, invece di raccogliere un gran numero di etichette, imparassimo da piccole quantità di feedback in linguaggio naturale, allo stesso modo in cui gli esseri umani si insegnano a vicenda? A differenza delle etichette, il feedback in linguaggio naturale è denso di informazioni: un singolo commento può cogliere intento, vincoli e indicazioni correttive contemporaneamente. In pratica, spesso sono necessarie decine di esempi contrastanti per insegnare implicitamente una regola, mentre un singolo feedback può rendere esplicita tale regola. Questo rispecchia il modo in cui gli esseri umani migliorano nei compiti complessi: attraverso la revisione e la riflessione, non solo tramite risultati scalari. Questo paradigma è alla base del nostro più ampio progetto Agent Learning from Human Feedback (ALHF).
Presentazione di MemAlign: allineamento tramite memoria, non aggiornamenti dei pesi
MemAlign è un framework leggero che consente ai giudici LLM di adattarsi al feedback umano senza aggiornare i pesi del modello. Ottiene risultati ottimali in termini di velocità, costo e accuratezza apprendendo dalle informazioni dense contenute nel feedback in linguaggio naturale, utilizzando un sistema di memoria duale ispirato alla cognizione umana:
- La Memoria semantica memorizza la "conoscenza" generale (o i principi). Quando un esperto spiega la propria decisione, MemAlign estrae la linea guida generalizzabile: "Preferire sempre le viste certificate rispetto alle tabelle grezze" o "Valutare la sicurezza in base all'intento, non solo al linguaggio." Questi principi sono abbastanza ampi da poter essere applicati a molti input futuri.
- La Memoria episodica conserva "esperienze" (o esempi) specifici, in particolare gli edge case in cui il giudice ha avuto difficoltà. Questi fungono da ancore concrete per situazioni difficili da generalizzare.

{kind=link}
Durante la fase di allineamento (Figura 2a), un esperto fornisce un feedback su un batch di esempi. MemAlign si adatta aggiornando entrambi i moduli di memoria: distilla il feedback in linee guida generalizzabili da aggiungere alla Memoria Semantica e conserva gli esempi salienti nella Memoria Episodica.
Quando arriva un nuovo input da giudicare (Figura 2b), MemAlign costruisce una Memoria di lavoro (essenzialmente un contesto dinamico) raccogliendo tutti i principi dalla Memoria semantica e recuperando gli esempi più pertinenti dalla Memoria episodica. In combinazione con l'input corrente, il giudice LLM effettua una previsione basata sulla "conoscenza" e sulle "esperienze" passate, analogamente a come i giudici reali dispongono di un regolamento e di una cronologia dei casi da consultare nel processo decisionale.
Inoltre, MemAlign consente agli utenti di eliminare o sovrascrivere direttamente i record passati. Gli esperti hanno cambiato idea? I requisiti si sono evoluti? Vincoli di privacy richiedono l'eliminazione di vecchi esempi? Basta identificare i record obsoleti e la memoria verrà aggiornata automaticamente. Ciò mantiene il sistema pulito e impedisce l'accumulo di indicazioni contrastanti nel tempo.
Un parallelo utile è vedere MemAlign attraverso la lente degli ottimizzatori di prompt. Gli ottimizzatori di prompt in genere deducono la qualità ottimizzando una metrica calcolata su un development set etichettato, mentre MemAlign la ricava direttamente da una piccola quantità di feedback in linguaggio naturale degli SME su esempi passati. La fase di ottimizzazione è analoga alla fase di allineamento di MemAlign, in cui il feedback viene distillato in principi riutilizzabili memorizzati nella Memoria Semantica.
Prestazioni: MemAlign vs. Prompt Optimizer
Confrontiamo MemAlign con ottimizzatori di prompt all'avanguardia (MIPROv2, SIMBA, GEPA (auto budget = 'light') di DSPy) su set di dati che includono cinque categorie di giudizio:
- Correttezza della risposta: FinanceBench, HotpotQA
- Fedeltà: HaluBench
- Sicurezza: abbiamo collaborato con Flo Health per convalidare MemAlign su uno dei loro set di dati interni anonimizzati (coppie Q&A con annotazioni di esperti medici secondo 12 criteri sfumati).
- Preferenza a coppie: Auto-J (sottoinsiemi PKU-SafeRLHF e OpenAI Summary)
- Criteri granulari: prometheus-eval/Feedback-Collection (10 criteri campionati in base alla diversità, ad es. "interpretazione della terminologia", "uso dell'umorismo", "consapevolezza culturale", con un punteggio da 1 a 5)
Abbiamo suddiviso ogni set di dati in un set di addestramento di 50 esempi e un set di test con i restanti. In ogni fase, abbiamo progressivamente lasciato che ogni giudice si adattasse a un nuovo frammento di esempi di feedback dal set di addestramento, per poi misurare le prestazioni sia sui set di addestramento che su quelli di test. I nostri esperimenti principali utilizzano GPT-4.1-mini come LLM, con 3 esecuzioni per esperimento e k=5 per il recupero.
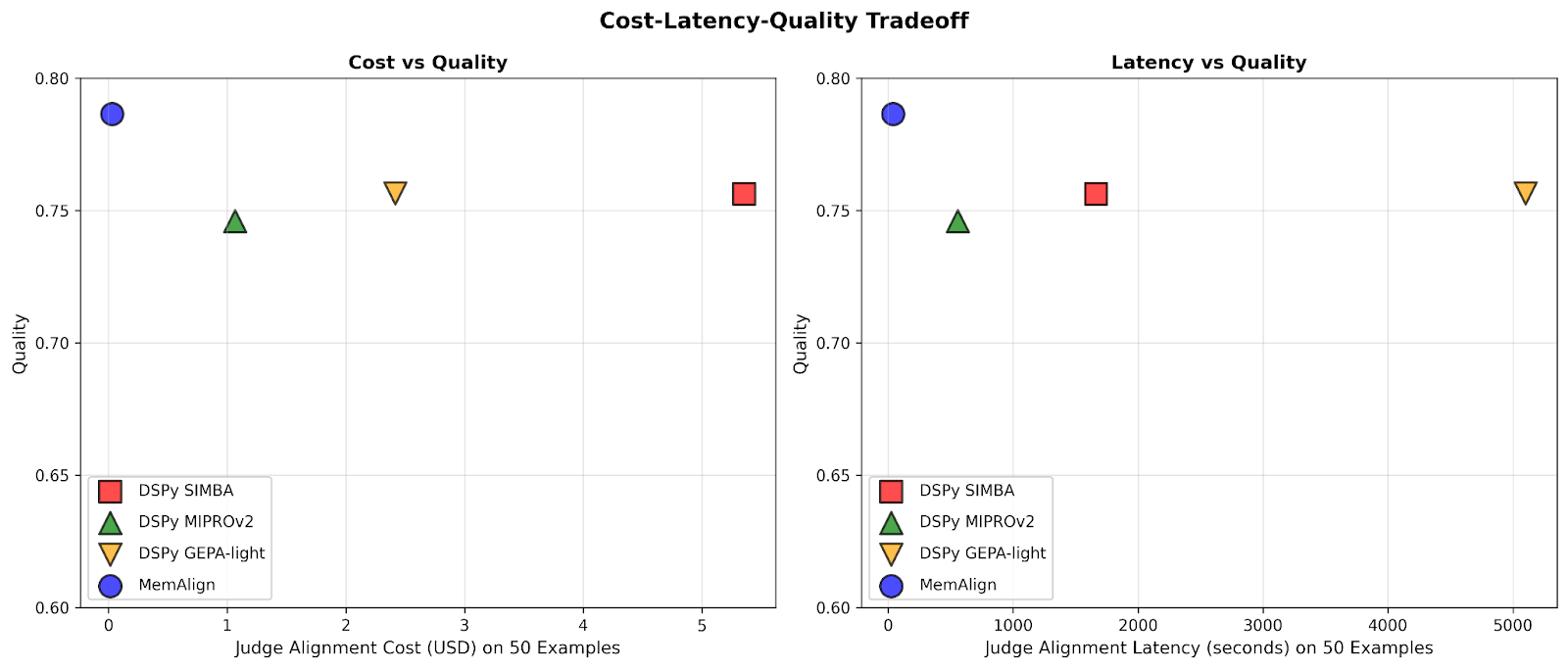
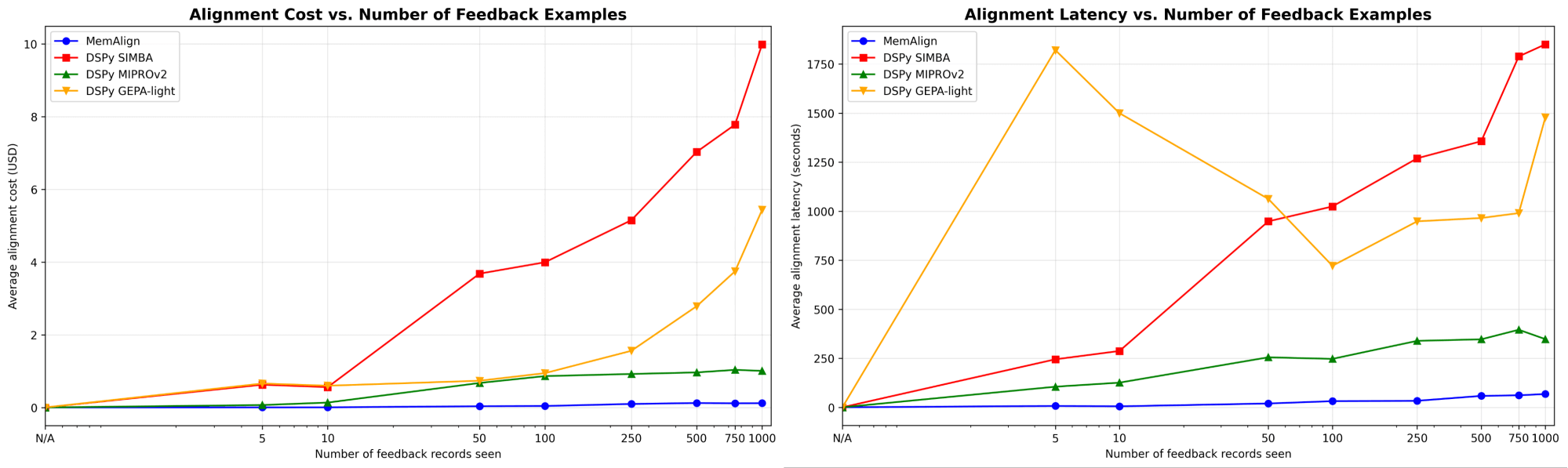
MemAlign si adatta in modo decisamente più rapido ed economico
Innanzitutto, mostriamo la velocità e il costo di allineamento di MemAlign a confronto con gli ottimizzatori di prompt di DSPy:
{kind=link}
Man mano che la quantità di feedback cresce fino a centinaia o addirittura un migliaio, l'allineamento diventa sempre più veloce ed economico rispetto ai baseline. MemAlign si adatta in pochi secondi con <50 esempi e in circa 1,5 minuti con fino a 1000, con un costo di soli 0,01-0,12 $ per fase. Nel frattempo, i prompt optimizer di DSPy richiedono da svariati a decine di minuti per ciclo e costano da 10 a 100 volte di più. (È interessante notare che il picco di latenza iniziale di GEPA è dovuto a punteggi di convalida instabili e a un aumento delle chiamate di reflection con campioni di piccole dimensioni.) In pratica, MemAlign consente cicli di feedback stretti e interattivi: un esperto può rivedere un giudizio, spiegare cosa non va e vedere il sistema migliorare quasi istantaneamente.1
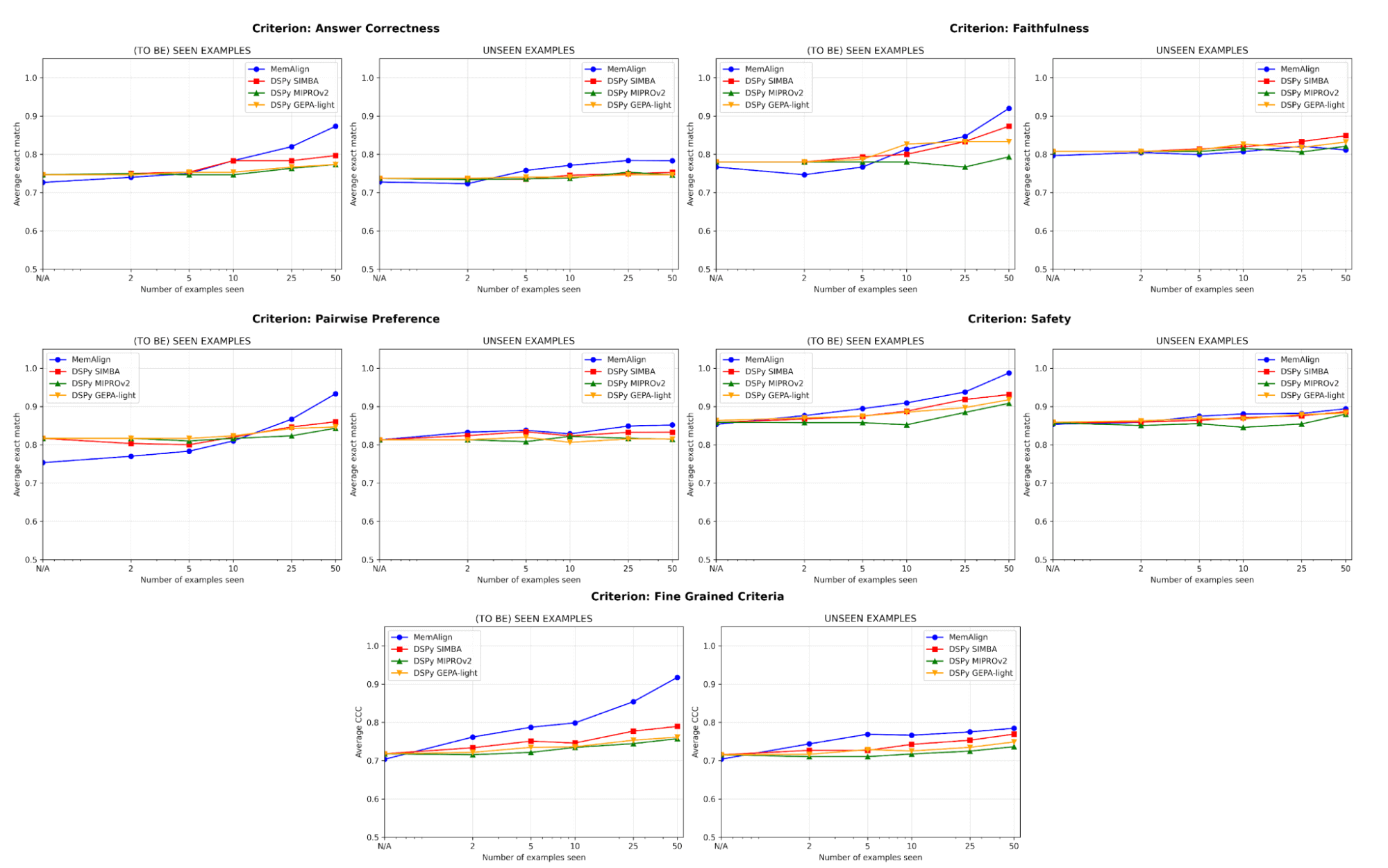
La qualità eguaglia lo stato dell'arte e migliora con il feedback
In termini di qualità, confrontiamo le prestazioni del giudice dopo l'adattamento a un numero crescente di esempi utilizzando MemAlign rispetto agli ottimizzatori di prompt di DSPy:
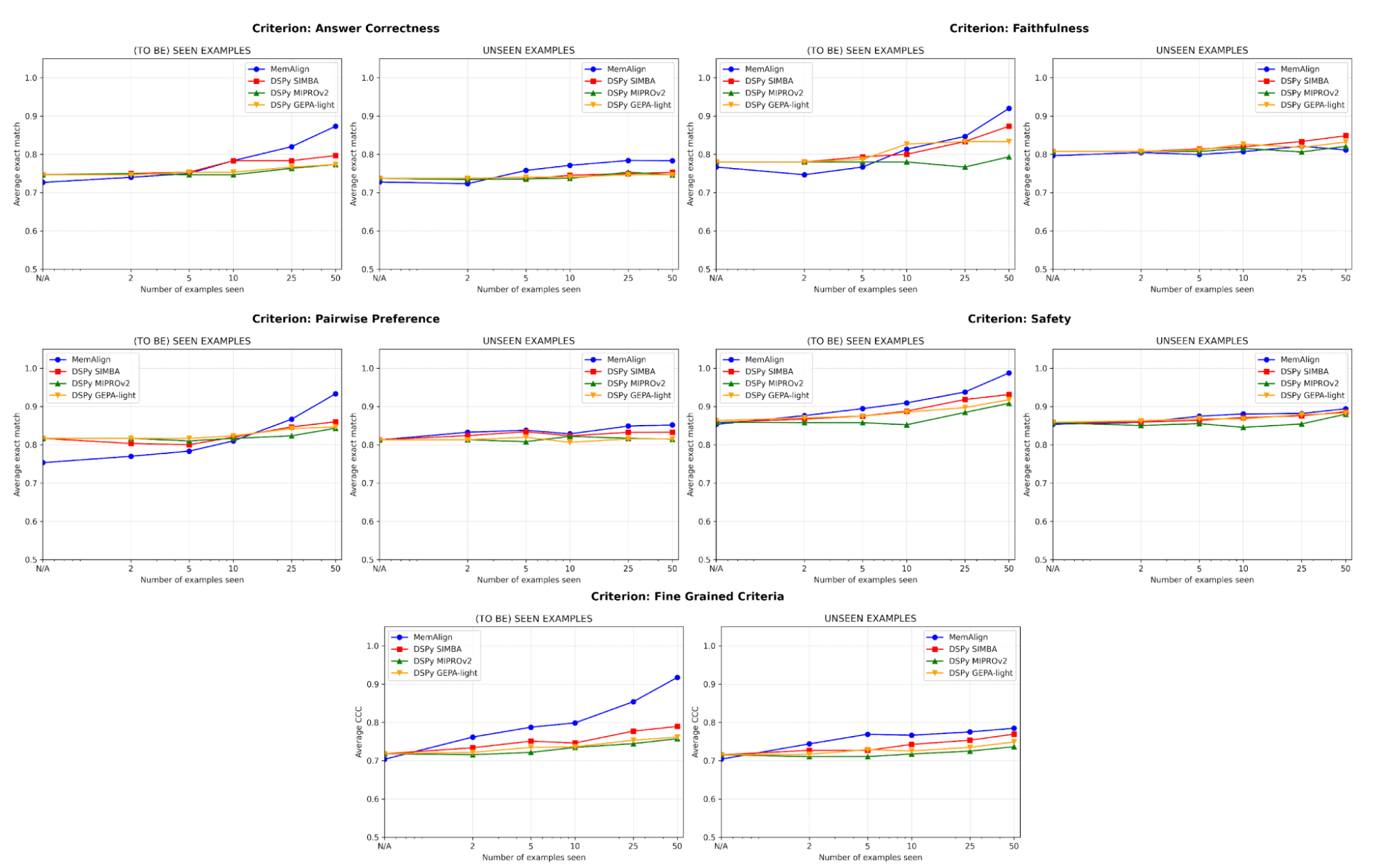{kind=link}
Uno dei rischi maggiori nell'allineamento è la regressione: correggere un errore per poi reintrodurlo in un secondo momento. Su tutti i criteri, MemAlign offre le prestazioni migliori sugli esempi già visti (a sinistra), raggiungendo spesso un'accuratezza di oltre il 90%, mentre altri metodi si assestano spesso tra il 70% e l'80%.
Su esempi non visti (a destra), MemAlign mostra una generalizzazione competitiva. Supera le prestazioni degli ottimizzatori di prompt di DSPy in termini di Correttezza della risposta e ottiene risultati molto simili per altri criteri. Ciò indica che non si limita a memorizzare le correzioni, ma estrae conoscenza trasferibile dal feedback.
Questo comportamento illustra quella che chiamiamo scalabilità della memoria: a differenza della scalabilità in fase di test, che aumenta il compute per query, la scalabilità della memoria migliora la qualità accumulando feedback in modo persistente nel tempo.
Per Start non servono molti esempi
L'aspetto più importante è che MemAlign mostra un netto miglioramento con soli 2-10 esempi, soprattutto per quanto riguarda i criteri granulari e la correttezza della risposta. Nel raro caso in cui MemAlign parta da un livello più basso (ad es. Preferenza a coppie), recupera rapidamente il ritardo con 5-10 esempi. Ciò significa che non è necessario un massiccio lavoro di etichettatura iniziale prima di vederne il valore. Si verifica quasi immediatamente un miglioramento significativo.
Dietro le quinte: cosa fa funzionare MemAlign?
Per comprendere meglio il comportamento del sistema, eseguiamo ulteriori ablazioni su un set di dati di esempio (in cui il criterio del giudice è «Il modello è in grado di interpretare correttamente la terminologia tecnica o il gergo specifico del settore?») dal benchmark prometheus-eval. Utilizziamo lo stesso LLM (GPT-4.1-mini) come negli esperimenti principali.
Sono necessari entrambi i moduli di memoria? Dopo aver rimosso ciascun modulo di memoria, osserviamo un calo delle prestazioni in entrambi i casi. Rimuovendo la memoria semantica, il giudice perde la sua solida base di principi; rimuovendo la memoria episodica, ha difficoltà con i casi limite. Entrambi i componenti sono importanti per le prestazioni.
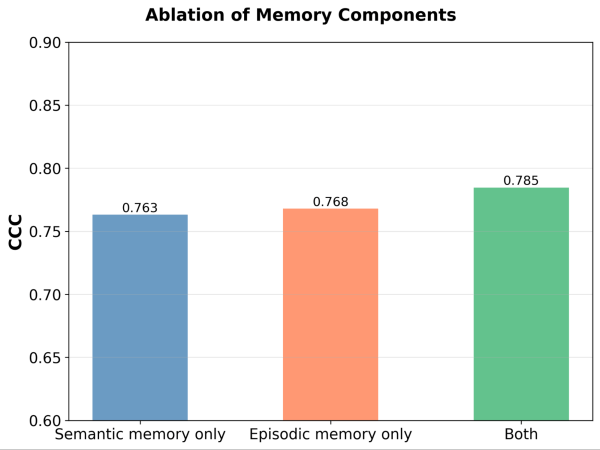
Figura 5. Prestazioni (misurate tramite il Concordance Correlation Coefficient (CCC)) di MemAlign con solo la memoria semantica, solo la memoria episodica o entrambe abilitate.
Il feedback è efficace almeno quanto le etichette, soprattutto all'inizio. Dato un budget di annotazione fisso, in quale tipo di segnale di apprendimento vale la pena investire di più: etichette, feedback in linguaggio naturale o entrambi? Notiamo un leggero vantaggio iniziale (<=5 esempi) del feedback rispetto alle etichette, con il divario che si riduce man mano che gli esempi si accumulano. Ciò significa che se i tuoi esperti hanno tempo solo per una manciata di esempi, potrebbe essere meglio che spieghino il loro ragionamento; altrimenti, le sole etichette potrebbero essere sufficienti.
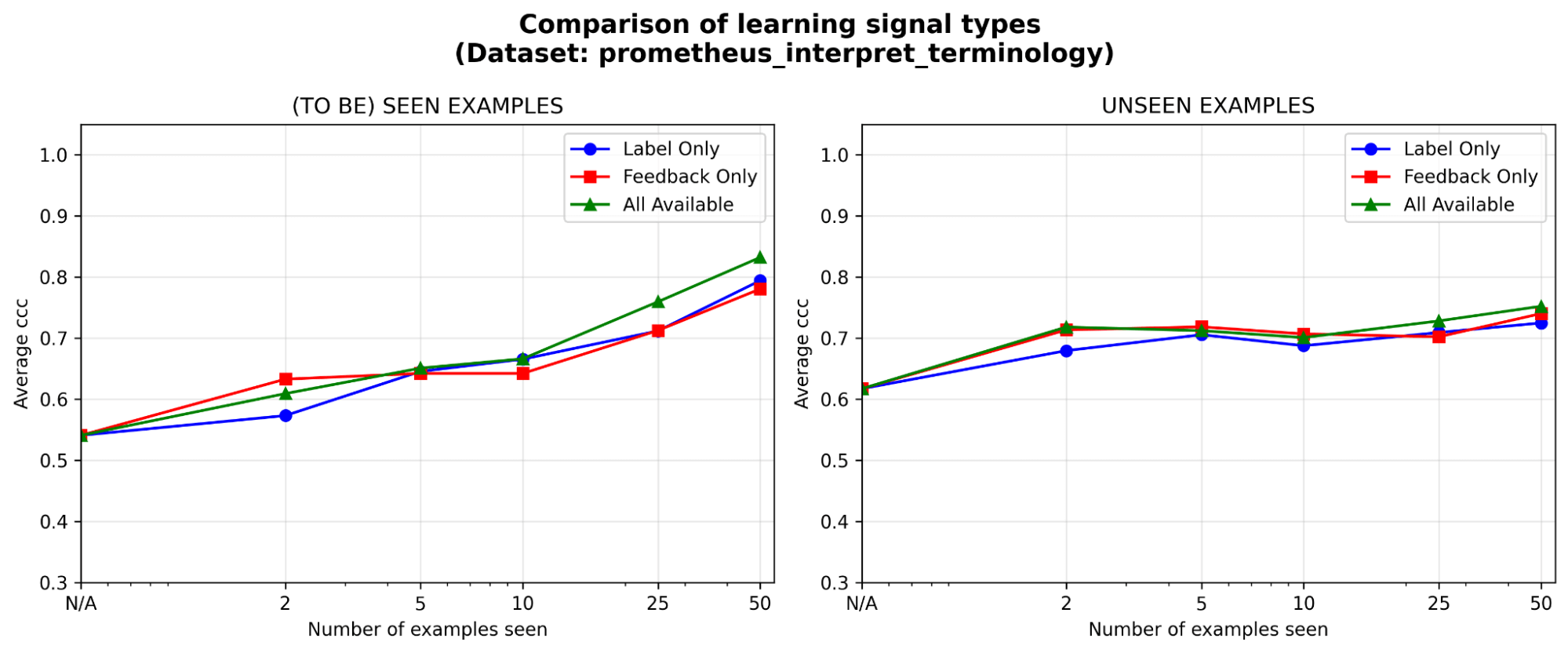
{kind=link}
MemAlign è sensibile alla scelta dell'LLM? Abbiamo eseguito MemAlign con LLM di diverse famiglie e dimensioni. Nel complesso, Claude-4.5 Sonnet offre le prestazioni migliori. Ma i modelli più piccoli mostrano comunque un miglioramento sostanziale: ad esempio, anche se GPT-4.1-mini parte da un livello basso, eguaglia le prestazioni di modelli di frontiera come GPT-5.2 dopo aver visto 50 esempi. Questo significa che non si è vincolati a costosi modelli di frontiera per ottenere valore.
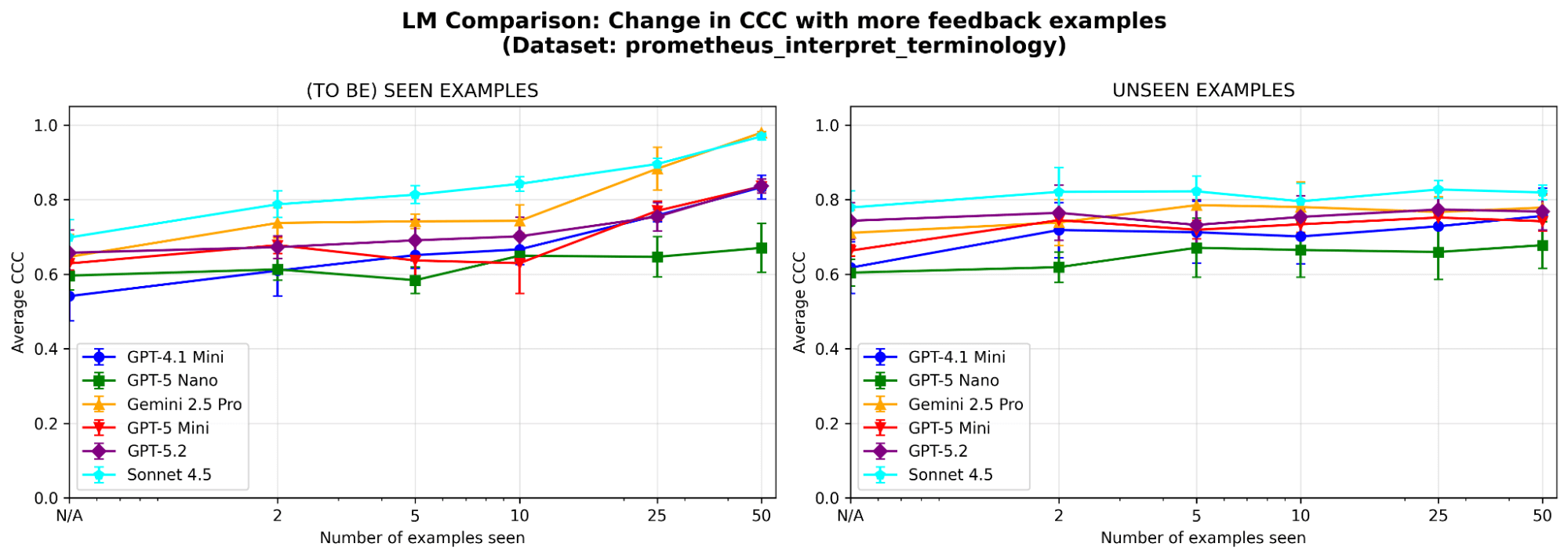
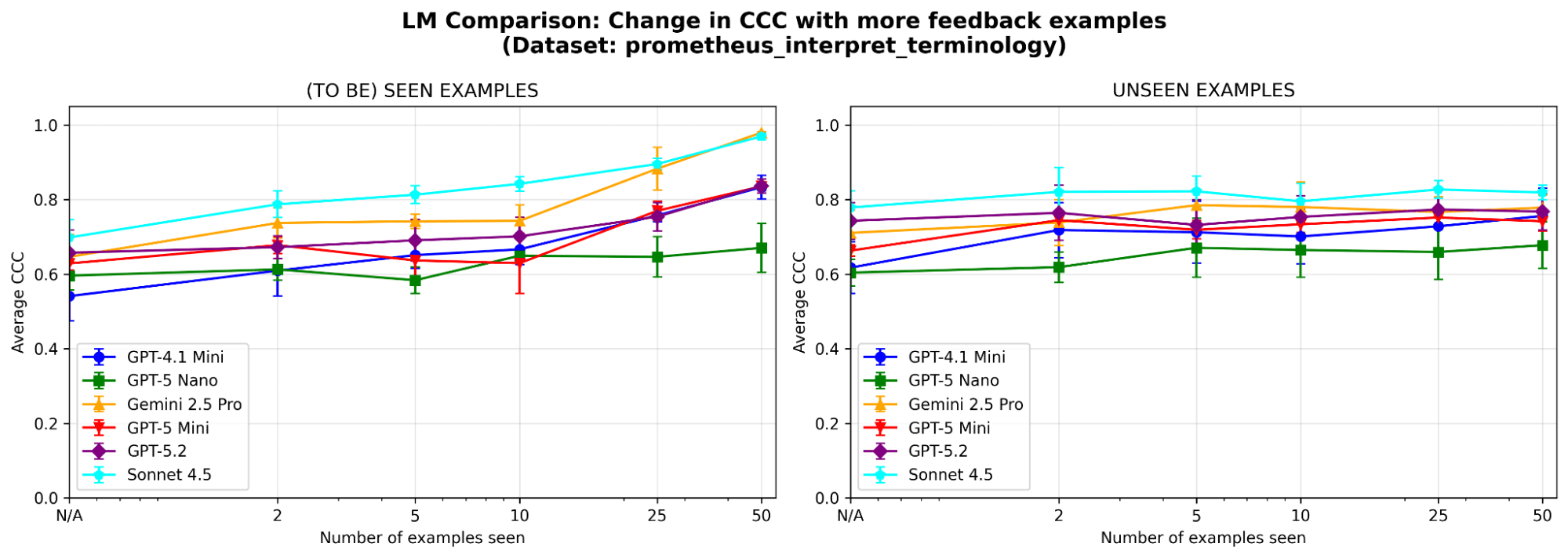{kind=link}
Punti chiave
MemAlign colma il divario tra gli LLM generici e le sfumature specifiche del dominio utilizzando un'architettura a memoria duale che consente un allineamento rapido ed economico. Riflette una filosofia diversa: sfruttare il denso feedback in linguaggio naturale degli esperti umani anziché approssimarlo con un gran numero di etichette. Più in generale, MemAlign evidenzia la promessa dello scaling della memoria: accumulando lezioni invece di riottimizzare ripetutamente, gli agenti possono continuare a migliorare senza sacrificare velocità o costi. Crediamo che questo paradigma sarà sempre più importante per i flussi di lavoro degli agenti di lunga durata e con esperti nel loop.
MemAlign è ora disponibile come algoritmo di ottimizzazione nel metodo align() di MLFlow. Dai un'occhiata a questo demo Notebook per iniziare!
1I risultati sopra riportati confrontano la velocità di allineamento; in fase di inferenza, MemAlign potrebbe richiedere 0,8–1 s aggiuntivi per esempio a causa della ricerca vettoriale sulla memoria, rispetto ai judge ottimizzati tramite prompt.
Autori: Veronica Lyu, Kartik Sreenivasan, Samraj Moorjani, Alkis Polyzotis, Sam Havens, Michael Carbin, Michael Bendersky, Matei Zaharia, Xing Chen
Vorremmo ringraziare Krista Opsahl-Ong, Tomu Hirata, Arnav Singhvi, Pallavi Koppol, Wesley Pasfield, Forrest Murray, Jonathan Frankle, Eric Peter, Alexander Trott, Chen Qian, Wenhao Zhan, Xiangrui Meng, Moonsoo Lee e Omar Khattab per il feedback e il supporto durante la progettazione, l'implementazione e la pubblicazione del blog su MemAlign. Inoltre, siamo grati a Michael Shtelma, Nancy Hung, Ksenia Shishkanova e Flo Health per averci aiutato a valutare MemAlign sui loro set di dati interni anonimizzati
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.