Cosa sono i modelli di apprendimento automatico?
Algoritmi che apprendono modelli dai dati di addestramento per fare previsioni, dalla regressione lineare e dagli alberi decisionali alle reti neurali profonde
- Il processo di addestramento prevede l'inserimento di dati etichettati tramite algoritmi che regolano i parametri interni (pesi, coefficienti) per ridurre al minimo l'errore di previsione sui set di convalida, utilizzando tecniche come la discesa del gradiente, la backpropagation e la regolarizzazione.
- I tipi di modello spaziano dall'apprendimento supervisionato (classificazione, regressione), all'apprendimento non supervisionato (clustering, riduzione della dimensionalità), all'apprendimento per rinforzo e agli approcci semi-supervisionati, ciascuno adatto a diverse strutture del problema e disponibilità dei dati.
- Le metriche di valutazione includono accuratezza, precisione, richiamo, punteggio F1, AUC-ROC per la classificazione; MSE, MAE, R² per la regressione; e punteggio silhouette, indice di Davies-Bouldin per il clustering, guidando la selezione del modello e l'ottimizzazione degli iperparametri.
Che cos'è un modello di machine learning?
Un modello di machine learning è un programma che ha la capacità di trovare schemi o prendere decisioni analizzando un set di dati mai visto prima. Ad esempio, nell'elaborazione del linguaggio naturale (NLP), i modelli di machine learning possono analizzare e riconoscere correttamente il significato di frasi o combinazioni di parole mai sentite prima. Nel riconoscimento di immagini, un modello di machine learning può essere addestrato per riconoscere oggetti, come automobili o cani. Un modello di machine learning può eseguire questi compiti se viene "addestrato" su un set di dati ampio. Durante l'addestramento, l'algoritmo di machine learning viene ottimizzato per estrarre determinati schemi o risultati dal set di dati, a seconda del compito richiesto. Il risultato di questo processo (spesso un programma con regole e strutture di dati precise) viene chiamato modello di machine learning.
Che cos'è un algoritmo di machine learning?
Un algoritmo di machine learning è un metodo matematico per individuare schemi ricorrenti in un set di dati. Gli algoritmi di machine learning sono spesso ricavati da statistiche, calcolo e algebra lineare. Alcuni esempi diffusi di algoritmi di machine learning sono la regressione lineare, gli alberi decisionali, la foresta casuale e XGBoost.
Che cosa si intende per addestramento di un modello nel machine learning?
Il processo di esecuzione di un algoritmo di machine learning su un set di dati (chiamati dati di addestramento) e l'ottimizzazione dell'algoritmo per la ricerca di determinati schemi o risultati viene detto addestramento del modello. La funzione risultante con regole e strutture di dati viene chiamata modello addestrato di machine learning.
Quali sono i diversi tipi di machine learning?
In generale, le tecniche di machine learning possono essere suddivise in apprendimento supervisionato, apprendimento non supervisionato e apprendimento per rinforzo.
Che cos'è il machine learning supervisionato?
Nell'apprendimento supervisionato, l'algoritmo riceve un set di dati di partenza e viene premiato oppure ottimizzato se rispetta un insieme di risultati specifici. Ad esempio, il machine learning supervisionato viene impiegato diffusamente nel riconoscimento di immagini, utilizzando la tecnica di classificazione. Il machine learning supervisionato viene usato anche nelle previsioni demografiche, ad esempio aumento della popolazione o metriche della salute, con una tecnica detta regressione.
Che cos'è il machine learning non supervisionato?
Nell'apprendimento non supervisionato, l'algoritmo riceve un set di dati di partenza ma non viene premiato oppure ottimizzato in base a risultati specifici; viene invece addestrato per raggruppare gli oggetti con caratteristiche comuni. Ad esempio, i motori di raccomandazioni sui negozi online utilizzano il machine learning non supervisionato, specificamente la tecnica di clustering.
Che cos'è l'apprendimento per rinforzo?
Nell'apprendimento per rinforzo, l'algoritmo si addestra autonomamente procedendo per tentativi. L'apprendimento per rinforzo è un processo in cui l'algoritmo interagisce continuamente con l'ambiente circostante invece di utilizzare dati di addestramento. Uno degli esempi più conosciuti di apprendimento per rinforzo è la guida autonoma.
Quali sono i diversi modelli di machine learning?
Esistono molti modelli di machine learning, quasi tutti basati su determinati algoritmi di machine learning. Gli algoritmi di classificazione e regressione più diffusi rientrano nella categoria dell'apprendimento supervisionato, mentre gli algoritmi di clustering vengono solitamente impiegati in contesti di apprendimento non supervisionato.
Machine learning supervisionato
- Regressione logistica: la regressione logistica consente di determinare se un input appartiene o meno a un determinato gruppo.
- SVM: le Support Vector Machine creano coordinate per ogni oggetto in uno spazio n-dimensionale e usa un iperpiano per raggruppare gli oggetti per caratteristiche comuni.
- Naive Bayes: è un algoritmo che parte dal presupposto dell'indipendenza fra le variabili e usa le probabilità per classificare gli oggetti in base alle loro caratteristiche.
- Alberi decisionali: si tratta di classificatori utilizzati per determinare in quale categoria rientra un input procedendo lungo i nodi e le foglie terminali dell'albero.
- Regressione lineare: viene utilizzata per individuare le relazioni fra la variabile di interesse e gli input, prevedendo i valori della variabile in base ai valori delle variabili di input.
- kNN: la tecnica k Nearest Neighbors raggruppa gli oggetti fra loro più simili in un set di dati e individua le caratteristiche più frequenti o medie fra gli oggetti.
- Foresta casuale: è una raccolta di numerosi alberi decisionali ricavati da sottoinsiemi casuali dei dati, da cui scaturisce una combinazione di alberi che può generare previsioni più accurate rispetto a un singolo albero decisionale.
- Algoritmi di boosting: gli algoritmi di boosting, come Gradient Boosting Machine, XGBoost e LightGBM, usano l'apprendimento d'insieme. Combinano le previsioni di molteplici algoritmi (ad esempio alberi decisionali), tenendo conto dell'errore dell'algoritmo precedente.
Machine learning non supervisionato
- K-Means: questo algoritmo individua similitudini fra oggetti e li raggruppa in diversi cluster K.
- Clustering gerarchico: questo metodo costruisce un albero di cluster nidificati senza che sia necessario specificare il numero di cluster.
Che cos'è un albero decisionale nel machine learning (ML)?
Un albero decisionale è un approccio predittivo che consente di determinare la classe alla quale appartiene un oggetto. Come suggerisce il nome, si tratta di un diagramma di flusso simile a un albero, dove la classe di un oggetto viene determinata passo dopo passo, utilizzando alcune condizioni note. 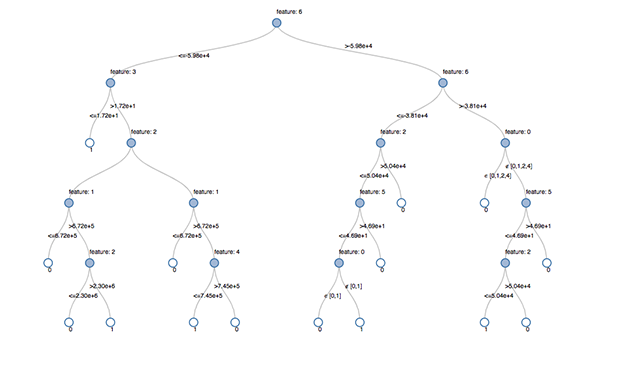 Un albero decisionale visualizzato in Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
Un albero decisionale visualizzato in Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
Il playbook sull'AI agentiva per l'enterprise

Che cos'è la regressione nel machine learning?
Nell'ambito della data science e del machine learning, la regressione è un metodo statistico che consente di prevedere esiti in base a un insieme di variabili iniziali. L'esito è spesso una variabile che dipende da una combinazione di variabili d partenza. 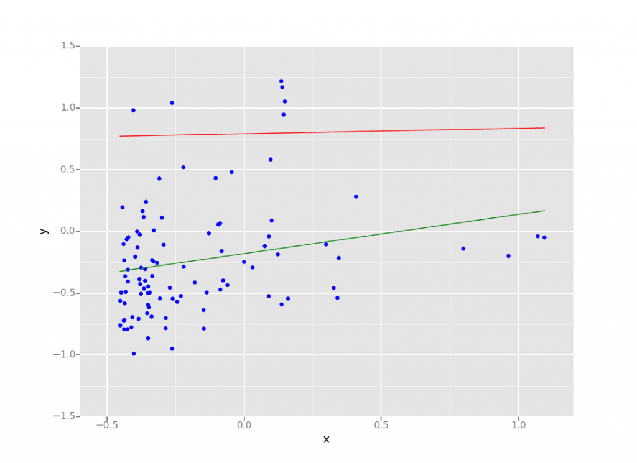 Un modello di regressione lineare eseguito su Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
Un modello di regressione lineare eseguito su Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
Che cos'è un classificatore nel machine learning?
Un classificatore è un modello di machine learning che assegna un oggetto a una categoria o un gruppo. Ad esempio, i classificatori vengono utilizzati per stabilire se un messaggio di posta elettronica è spam, oppure se una transazione è fraudolenta.
Quanti modelli esistono nel machine learning?
Moltissimi! Il machine learning è un settore in continua evoluzione e vengono sviluppati sempre più modelli di machine learning.
Qual è il modello migliore per il machine learning?
Il modello di machine learning più adatto in ogni specifica situazione dipende dall'esito desiderato. Ad esempio, per prevedere le vendite di autoveicoli in una città sulla base di dati storici, il metodo più adatto potrebbe essere una tecnica di apprendimento supervisionato come la regressione lineare. Per contro, per capire se un potenziale cliente residente in quella città acquisterebbe un'auto, in base al suo reddito e alle sue abitudini da pendolare, potrebbe funzionare meglio un albero decisionale.
Che cosa si intende per implementazione del modello nel machine learning (ML)?
L'implementazione è il processo con cui un modello di machine learning viene reso disponibile per l'utilizzo in un ambiente di destinazione, a scopo di test o produzione. Il modello è solitamente integrato con altre applicazioni presenti nell'ambiente (come database e UI) attraverso API. L'implementazione è la fase in cui un'organizzazione può realmente ottenere un ritorno sull'investimento ingente effettuato nello sviluppo del modello. 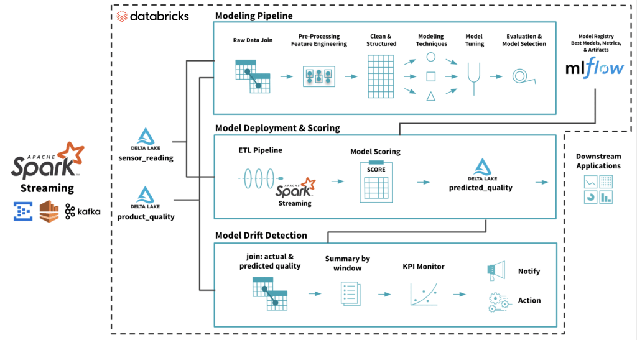 Ciclo di vita completo del modello di machine learning su Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
Ciclo di vita completo del modello di machine learning su Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
Che cosa sono i modelli di deep learning?
I modelli di deep learning sono una classe di modelli ML che imitano il modo in cui gli esseri umani elaborano le informazioni. Questo tipo di modello utilizza diversi livelli di elaborazione (da qui il termine "profondo") per estrarre caratteristiche di alto livello dai dati forniti. Ogni livello di elaborazione passa al livello successivo una rappresentazione più astratta dei dati, fino ad arrivare al livello finale che offre informazioni approfondite di tipo umano. A differenza dei modelli ML tradizionali che richiedono di etichettare i dati, i modelli di deep learning possono ingerire grandi quantità di dati non strutturati. Vengono utilizzati per svolgere funzioni più simili a quelle umane, come riconoscimento facciale ed elaborazione del linguaggio naturale.  Una rappresentazione semplificata di deep learning. Fonte: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
Una rappresentazione semplificata di deep learning. Fonte: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
Che cos'è la previsione delle serie temporali?
In un modello di machine learning per serie temporali, una delle variabili indipendenti è un periodo di tempo (minuti, giorni, anni ecc.) che influisce sulla variabile dipendente o prevista. I modelli di machine learning per serie temporali vengono utilizzati per prevedere eventi legati al tempo, ad esempio il meteo della prossima settimana, il numero di clienti attesi nel prossimo mese, i ricavi previsti per il prossimo anno, e così via.
Dove posso trovare maggiori informazioni sul machine learning?
- Leggi questo e-book gratuito per scoprire diversi casi d'uso di machine learning interessanti, realizzati da aziende in tutto il mondo.
- Per approfondimenti sul machine learning proposti da esperti del settore, consulta il blog di Databricks sul machine learning.
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.