Cosa sono le pipeline ML?
Scopri come le pipeline ML automatizzano e semplificano il flusso di lavoro di apprendimento automatico dalla pre-elaborazione dei dati alla convalida del modello
- Scopri cosa sono le pipeline di ML e come collegano pre-elaborazione, estrazione di feature, adattamento del modello e convalida in un flusso di lavoro unificato.
- Scopri la differenza tra Transformer ed Estimator come le due principali tipologie di fasi della pipeline.
- Esplora come le pipeline di Spark ML consentono un apprendimento automatico scalabile e distribuito con creazione e ottimizzazione di pipeline native.
Solitamente, l'esecuzione di algoritmi di machine learning prevede una sequenza di attività fra cui pre-elaborazione, estrazione di caratteristiche (feature), adattamento del modello e fasi di convalida. Ad esempio, la classificazione di documenti di testo può comportare segmentazione e pulizia del testo, estrazione di caratteristiche e addestramento di un modello di classificazione con convalida incrociata. Nonostante per ogni passaggio siano a disposizione numerose librerie, "unire i puntini" non è facile come sembra, soprattutto con set di dati di grandi dimensioni. La maggior parte delle librerie ML non è progettata per il calcolo distribuito o non fornisce supporto nativo per la creazione e il perfezionamento di pipeline.
Il playbook sull'AI agentiva per l'enterprise

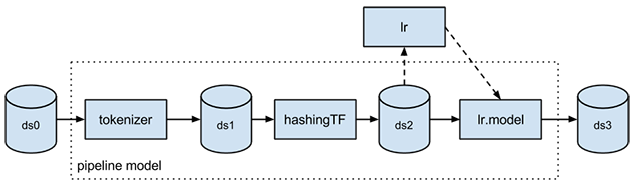
ML Pipelines è un'interfaccia API di alto livello per MLlib che fa parte del pacchetto "spark.ml". Una pipeline è costituita da una sequenza di fasi. Esistono due tipologie principali di fasi della pipeline: trasformatore e stimatore. Il trasformatore è uno strumento che riceve un set di dati in ingresso e produce un set di dati aumentato in uscita. Ad esempio, un tokenizzatore trasforma un set di dati con testo in un set di dati con parole tokenizzate. Lo stimatore deve prima adattarsi al set di dati in entrata per produrre un modello, che coincide con il trasformatore che trasforma il set di dati in entrata. Ad esempio, la regressione logistica è uno stimatore che si addestra su un set di dati con etichette e caratteristiche e che produce un modello di regressione logistica.
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.