Che cos'è il flusso di dati?
Spostamento e trasformazione dei dati dalla sorgente alla destinazione tramite pipeline di streaming, flussi di lavoro batch, elaborazione di eventi in tempo reale ed ETL orchestrato
- I modelli includono estrazione-trasformazione-caricamento (ETL) per l'elaborazione batch, estrazione-caricamento-trasformazione (ELT) che sfrutta il calcolo del sistema target, architetture di streaming per l'elaborazione continua e architetture lambda che combinano elaborazione batch e in tempo reale.
- L'orchestrazione gestisce le dipendenze delle attività, pianifica l'esecuzione, gestisce gli errori, consente l'elaborazione parallela, fornisce dashboard di monitoraggio e mantiene lo stato su sistemi distribuiti coordinando flussi di lavoro complessi a più fasi.
- Le tecniche di ottimizzazione comprendono l'elaborazione incrementale che evita il ricalcolo completo, il partizionamento per il parallelismo, la memorizzazione nella cache dei risultati intermedi, il pushdown dei predicati che riduce al minimo lo spostamento dei dati e l'allocazione adattiva delle risorse in base alle caratteristiche del carico di lavoro.
Che cos'è il flusso di dati?
Il "flusso di dati" è il movimento dei dati attraverso l'architettura di un sistema, da un processo o componente a un altro. L'espressione descrive il modo in cui i dati vengono acquisiti, elaborati, archiviati e restituiti all'interno di un sistema, di un'applicazione o di una rete. Il flusso di dati ha un impatto diretto sull'efficienza, l'affidabilità e la sicurezza di qualsiasi sistema informatico; di conseguenza, è fondamentale che il sistema sia correttamente configurato per ottimizzarne gli output.
Esistono diversi componenti chiave che definiscono il modo in cui i dati si spostano e vengono elaborati all'interno di un sistema di flusso di dati:
- Sorgente di dati. Il flusso di dati inizia con l'acquisizione dei dati da una determinata sorgente, che può includere dati strutturati e non strutturati, fonti generate tramite script o input dei clienti. Queste sorgenti avviano il flusso di dati e mettono in moto il sistema di flusso dei dati.
- Trasformazione dei dati. Una volta acquisiti nel sistema, i dati possono essere trasformati in una struttura o un formato utilizzabile per l'analisi o la data science. Questo avviene in base a regole di trasformazione che definiscono come i dati devono essere gestiti o modificati all'interno di un sistema. È così possibile garantire che i dati siano nel formato corretto per i processi aziendali e per il raggiungimento degli obiettivi.
- Destinazione dei dati. Una volta completate acquisizione e trasformazione, la destinazione finale dei dati elaborati è il data sink. Si tratta del punto finale di un sistema di dati, dove i dati vengono utilizzati senza essere ulteriormente trasferiti nel flusso di dati. Il data sink può includere un database, un lakehouse, report o file di log in cui i dati vengono registrati per scopi di audit o di analisi.
- Percorsi del flusso di dati. I diagrammi di flusso dei dati definiscono i percorsi o i canali attraverso i quali i dati viaggiano tra sorgenti, processi e destinazioni. Questi percorsi possono includere connessioni di rete fisiche o percorsi logici, come le chiamate API, e comprendono anche protocolli e canali per una trasmissione dei dati sicura ed efficiente.
Esempi di flusso di dati
Esistono alcuni modi comuni per gestire il flusso di dati in base a come la tua organizzazione struttura la propria pipeline di dati. Un processo di estrazione, trasformazione e caricamento (ETL, Extract Transform Load) organizza, prepara e centralizza i dati provenienti da più origini, rendendoli accessibili e utilizzabili per analisi, report e decisioni operative. Gestendo il flusso di dati dai sistemi di origine a un database o data warehouse di destinazione, l'ETL favorisce integrazione e coerenza dei dati, essenziali per generare informazioni affidabili e supportare strategie basate sui dati.
- Analisi in tempo reale. Questo flusso di dati può elaborare un numero infinito di record dalla sorgente originale ed elaborare un flusso continuo di dati in entrata. Ciò consente agli utenti di ottenere analisi e informazioni istantanee e dettagliate, utili per applicazioni in cui sono essenziali risposte tempestive, come il monitoraggio, il tracciamento, le raccomandazioni e qualsiasi azione automatizzata.
- Pipeline di dati operativi. Le pipeline di dati operativi sono progettate per gestire dati transazionali e operativi fondamentali per le funzioni quotidiane di un'organizzazione. Queste pipeline acquisiscono dati da varie fonti, come interazioni con i clienti, transazioni finanziarie, movimenti di inventario e letture di sensori, e assicurano che tali dati vengano elaborati, aggiornati e resi disponibili su tutti i sistemi in tempo quasi reale o con bassa latenza. Lo scopo delle pipeline di dati operativi è quello di mantenere sincronizzati applicazioni e database, garantendo che le operazioni aziendali si svolgano senza problemi e che tutti i sistemi riflettano lo stato più aggiornato dei dati.
- Elaborazione in batch. Nel flusso di dati, l'elaborazione in batch si riferisce alla gestione di grandi volumi di dati a intervalli pianificati o dopo aver raccolto una quantità sufficiente di dati da elaborare in una sola volta. A differenza dell'elaborazione in tempo reale, l'elaborazione in batch non richiede risultati immediati; si concentra invece sull'efficienza, la scalabilità e l'accuratezza dell'elaborazione, aggregando i dati prima di elaborarli. L'elaborazione in batch viene spesso utilizzata per attività come la generazione di report, l'analisi storica e le trasformazioni di dati su larga scala, in cui non è essenziale ottenere immediatamente informazioni.
Strumenti e tecnologia per il flusso di dati
Un flusso di lavoro ETL è un esempio comune di flusso di dati. Nel processo ETL, i dati vengono acquisiti dai sistemi di origine e scritti in un'area di staging, trasformati in base ai requisiti (garantendo la qualità dei dati, eliminando i duplicati e segnalando i dati mancanti) e infine scritti in un sistema di destinazione come un data warehouse o un data lake.
L'esistenza di sistemi ETL solidi nella tua organizzazione può contribuire a ottimizzare l'architettura dei dati in termini di throughput, latenza, costi ed efficienza operativa. Questo ti consente di avere accesso a dati tempestivi e di alta qualità per guidare decisioni precise.
Con l'enorme quantità e varietà di dati critici per l'azienda che vengono generati, comprendere il flusso di dati è essenziale per una buona ingegneria dei dati. Mentre molte aziende devono scegliere tra l'elaborazione in batch e lo streaming in tempo reale per gestire i propri dati, Databricks offre una sola API per dati in batch e in streaming. Strumenti come Delta Live Tables aiutano gli utenti a ottimizzare i costi da un lato e la latenza o il throughput dall'altro, consentendo di passare facilmente da una modalità di elaborazione all'altra. Questo può aiutare gli utenti a rendere le loro soluzioni "a prova di futuro", preparandoli a migrare facilmente all'elaborazione in streaming man mano che le loro esigenze aziendali evolvono.
Il playbook sull'AI agentiva per l'enterprise

Creare diagrammi di flusso dei dati
Uno dei modi in cui le organizzazioni illustrano il flusso dei dati all'interno del sistema è tramite la creazione di un diagramma di flusso dei dati (DFD). Si tratta di una rappresentazione grafica che mostra come le informazioni vengono raccolte, elaborate, archiviate e utilizzate, stabilendo il flusso direzionale dei dati tra le diverse parti del sistema. Il tipo di DFD da costruire dipende dalla complessità dell'architettura dei dati: può essere una semplice panoramica del flusso di dati o un più complesso DFD multilivello che descrive come i dati vengono gestiti nelle diverse fasi del loro ciclo di vita.
I DFD si sono evoluti nel tempo e oggi Delta Live Tables utilizza grafi aciclici diretti (DAG) per rappresentare la sequenza di trasformazioni e dipendenze dei dati tra tabelle o viste all'interno di una pipeline. Ogni trasformazione o tabella è un nodo, e gli archi tra i nodi definiscono il flusso di dati e le dipendenze. Ciò garantisce che le operazioni vengano eseguite nell'ordine corretto e in un ciclo direzionalmente chiuso.
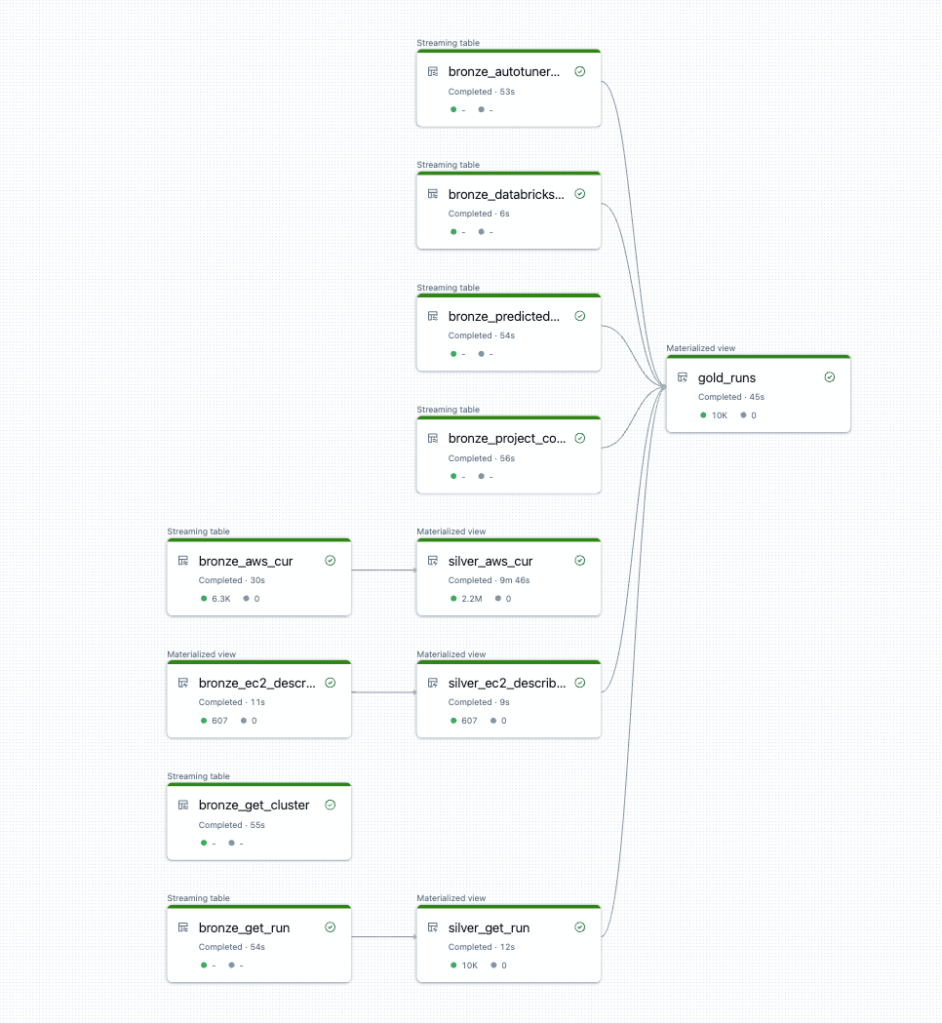
I DAG offrono un'immagine chiara delle relazioni tra le attività e possono anche aiutare a identificare e gestire errori o guasti nel sistema di flusso dei dati. Delta Live Tables garantisce che il DAG sia gestito in modo efficiente, pianificando e ottimizzando operazioni come il caricamento, le trasformazioni e gli aggiornamenti dei dati per mantenere coerenza e prestazioni.
Best practice per la gestione del flusso di dati
Per garantire che il flusso di dati sia ottimizzato, efficiente e sicuro è necessario seguire alcune best practice:
- Ottimizzare l'elaborazione dei dati. Ciò comporta la semplificazione del flusso di dati per eliminare i colli di bottiglia, ridurre la ridondanza e abilitare l'elaborazione in tempo reale. Rivedere e perfezionare regolarmente i flussi di lavoro garantisce che i dati fluiscano attraverso il sistema senza inutili complessità, riducendo così il consumo di risorse e migliorando la scalabilità.
- Garantire un flusso di informazioni senza interruzioni. Per ottenere un flusso di informazioni senza interruzioni, è importante ridurre al minimo i silos di dati e dare priorità all'interoperabilità tra i sistemi. Implementando pipeline ETL rigorose, le organizzazioni possono beneficiare di dati coerenti tra applicazioni, reparti e utilizzi diversi. Questo implica anche la creazione di processi di backup e ripristino affidabili per proteggersi da guasti o interruzioni del sistema.
- Considerare la sicurezza. Naturalmente, garantire la sicurezza dei dati durante il loro flusso è fondamentale. Tutti i dati, in particolare quelli sensibili o di identificazione personale, devono essere crittografati durante il trasferimento o l'archiviazione. Limitare l'accesso ai dati può aiutare a ridurre il rischio di esposizione non autorizzata, mentre condurre regolarmente audit di sicurezza e valutazioni delle vulnerabilità permette di identificare potenziali punti deboli e adottare misure proattive per proteggere il flusso di dati end-to-end.
- Monitorare le prestazioni. L'utilizzo di strumenti di analisi per monitorare metriche come latenza, velocità di trasferimento dei dati e tassi di errore consente di identificare le aree in cui il flusso di dati potrebbe rallentare o incontrare problemi. Configurare avvisi e dashboard automatizzati garantisce che i team siano immediatamente informati di eventuali problemi, permettendo una risoluzione rapida e minimizzando le interruzioni. Revisioni periodiche delle prestazioni possono inoltre fornire informazioni utili, assicurando un processo di gestione solido, sicuro ed efficiente.
Vantaggi di un flusso di dati efficiente
Un flusso di dati efficiente può fare una differenza sostanziale nei profitti della tua organizzazione. Ottimizzando il movimento rapido e continuo dei dati tra sistemi e reparti, è possibile semplificare il flusso di lavoro, migliorare la produttività e ridurre il tempo necessario per elaborare le informazioni.
Per altre informazioni su come Databricks può aiutare la tua organizzazione a ottenere un flusso di dati ottimale, consulta alcune delle nostre architetture di riferimento per lakehouse. Inoltre, scopri di più sulla nostra architettura a medaglione, un modello di progettazione dei dati utilizzato per organizzare logicamente i dati in un lakehouse.
Per altre informazioni su come Delta Live Tables può preparare la tua organizzazione a gestire sia i dati in batch che quelli in streaming, contatta un rappresentante Databricks.
Un flusso di dati efficiente può aiutare la tua organizzazione a prendere decisioni informate che rispondano alle sfide operative o alle aspettative dei clienti. L'accesso immediato ai dati consente di prendere decisioni in tempo reale con le informazioni più aggiornate. Inoltre, flussi di dati efficienti assicurano che le informazioni siano coerenti e affidabili.
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.