Che cos'è Spark Streaming?
Come Spark Streaming elabora micro-batch di dati in tempo reale con DStreams e perché Structured Streaming è ora il motore preferito
- Scopri cos'è Apache Spark Streaming, come estende l'API Spark principale e perché ora è considerato un motore di streaming legacy a favore dello Structured Streaming.
- Scopri come Spark Streaming acquisisce dati da fonti come Kafka, Flume e Amazon Kinesis, li elabora in micro-batch e invia i risultati a file, database o dashboard utilizzando DStreams.
- Esplora i principali vantaggi introdotti da Spark Streaming, come l'elaborazione unificata di batch e streaming, la tolleranza agli errori e l'integrazione con MLlib e Spark SQL.
Apache Spark Streaming è la generazione precedente del motore di streaming di Apache Spark. Non sono più disponibili aggiornamenti per Spark Streaming e il progetto è stato dismesso. Esiste un motore di streaming più nuovo e facile da usare in Apache Spark chiamato Structured Streaming. Per lo streaming di applicazioni e pipeline bisognerà quindi utilizzare Spark Structured Streaming. Vedi Structured Streaming.
Che cos'è Spark Streaming?
Apache Spark Streaming è un sistema di elaborazione in streaming, scalabile e tollerante agli errori, che supporta nativamente carichi di lavoro in batch e in streaming. Spark Streaming è un'estensione dell'API Spark principale che consente a data engineer e data scientist di elaborare dati in tempo reale da diverse sorgenti, fra cui Kafka, Flume, Amazon Kinesis e altre ancora. I dati elaborati possono essere poi trasferiti a file system, database e dashboard in tempo reale. L'astrazione chiave è Discretized Stream, o DStream, che rappresenta un flusso di dati diviso in piccoli batch. I flussi DStream sono basati sulle RDD, la principale astrazione di dati di Spark. Questo consente a Spark Streaming di integrarsi direttamente con qualsiasi altro componente Spark come MLlib e Spark SQL. Spark Streaming è diverso da altri sistemi che hanno un motore di elaborazione progettato esclusivamente per lo streaming, oppure hanno API per batch e streaming simili ma compilano internamente su motori diversi. Il singolo motore di esecuzione di Spark e il modello di programmazione unificato per batch e streaming offre alcuni vantaggi esclusivi rispetto ad altri sistemi di streaming tradizionali.
Il playbook sull'AI agentiva per l'enterprise

Quattro aspetti principali di Spark Streaming
- Recupero rapido da guasti e ritardi
- Miglior bilanciamento del carico e utilizzo delle risorse
- Combinazione di dati in streaming con set di dati statici e query interattive
- Integrazione nativa con librerie di elaborazione avanzate (SQL, machine learning, elaborazione di grafi)
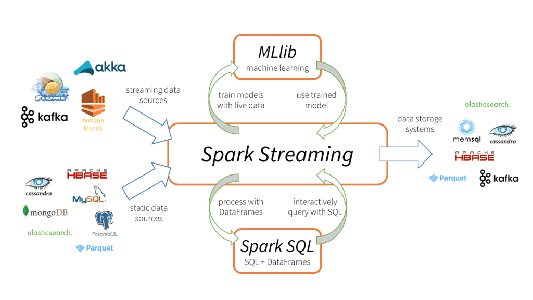
L'unificazione di diverse funzionalità di elaborazione dati è il motivo principale per la rapida adozione di Spark Streaming. Per gli sviluppatori risulta infatti molto facile utilizzare un unico framework per tutte le loro esigenze di elaborazione.
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.