Presentazione di Apache Spark 3.0
Ora disponibile in Databricks Runtime 7.0
di Matei Zaharia, Reynold Xin, Xiao Li, Wenchen Fan e Yin Huai
Siamo entusiasti di annunciare che Apache SparkTM 3.0.0 release è disponibile su Databricks come parte del nostro nuovo Databricks Runtime 7.0. La 3.0.0 La release include oltre 3.400 patch ed è il culmine di enormi contributi da parte della community open-source, apportando importanti progressi nelle funzionalità Python e SQL e ponendo l'attenzione sulla facilità d'uso sia per l'esplorazione che per la produzione. Queste iniziative riflettono come il progetto si sia evoluto per soddisfare più casi d'uso e un pubblico più ampio, e quest'anno si celebra il suo decimo anniversario come progetto open-source.
Ecco le principali nuove funzionalità di Spark 3.0:
- Miglioramento delle prestazioni di 2 volte su TPC-DS rispetto a Spark 2.4, reso possibile dall'esecuzione di query adattiva, dall' eliminazione dinamica delle partizioni e da altre ottimizzazioni
- Conformità ANSI SQL
- Significativi miglioramenti nelle API di pandas, inclusi i type hint di Python e UDF di pandas aggiuntive
- Migliore gestione degli errori di Python, che semplifica le eccezioni di PySpark
- Nuova UI per lo streaming strutturato
- Accelerazione fino a 40 volte per la chiamata di funzioni R definite dall'utente
- Oltre 3.400 ticket di Jira risolti
Non sono richieste modifiche sostanziali al codice per adottare questa versione di Apache Spark. Per maggiori informazioni, consulta la guida alla migrazione.
Festeggiamo i 10 anni di sviluppo ed evoluzione di Spark
Spark è nato presso l'UC Berkeley’s AMPlab, un laboratorio di ricerca focalizzato sul calcolo intensivo dei dati. I ricercatori di AMPlab stavano lavorando con grandi aziende su scala Internet per risolvere i loro problemi relativi a dati e IA, ma hanno capito che questi stessi problemi sarebbero stati affrontati anche da tutte le aziende con volumi di dati grandi e in crescita. Il team ha sviluppato un nuovo motore per gestire questi carichi di lavoro emergenti e allo stesso tempo rendere le APIs per lavorare con i Big Data molto più accessibili agli sviluppatori.
I contributi della community sono arrivati rapidamente per espandere Spark in diverse aree, con nuove funzionalità per lo streaming, Python e SQL, e questi modelli costituiscono oggi alcuni dei principali casi d'uso di Spark. Questo investimento continuo ha portato Spark al punto in cui si trova oggi, ovvero a essere il motore di fatto per i carichi di lavoro di elaborazione dati, data science, machine learning e analitiche dei dati. Apache Spark 3.0 prosegue questa tendenza migliorando in modo significativo il supporto per SQL e Python, i due linguaggi più utilizzati oggi con Spark, oltre a ottimizzare le prestazioni e l'operatività del resto di Spark.
Miglioramento del motore Spark SQL
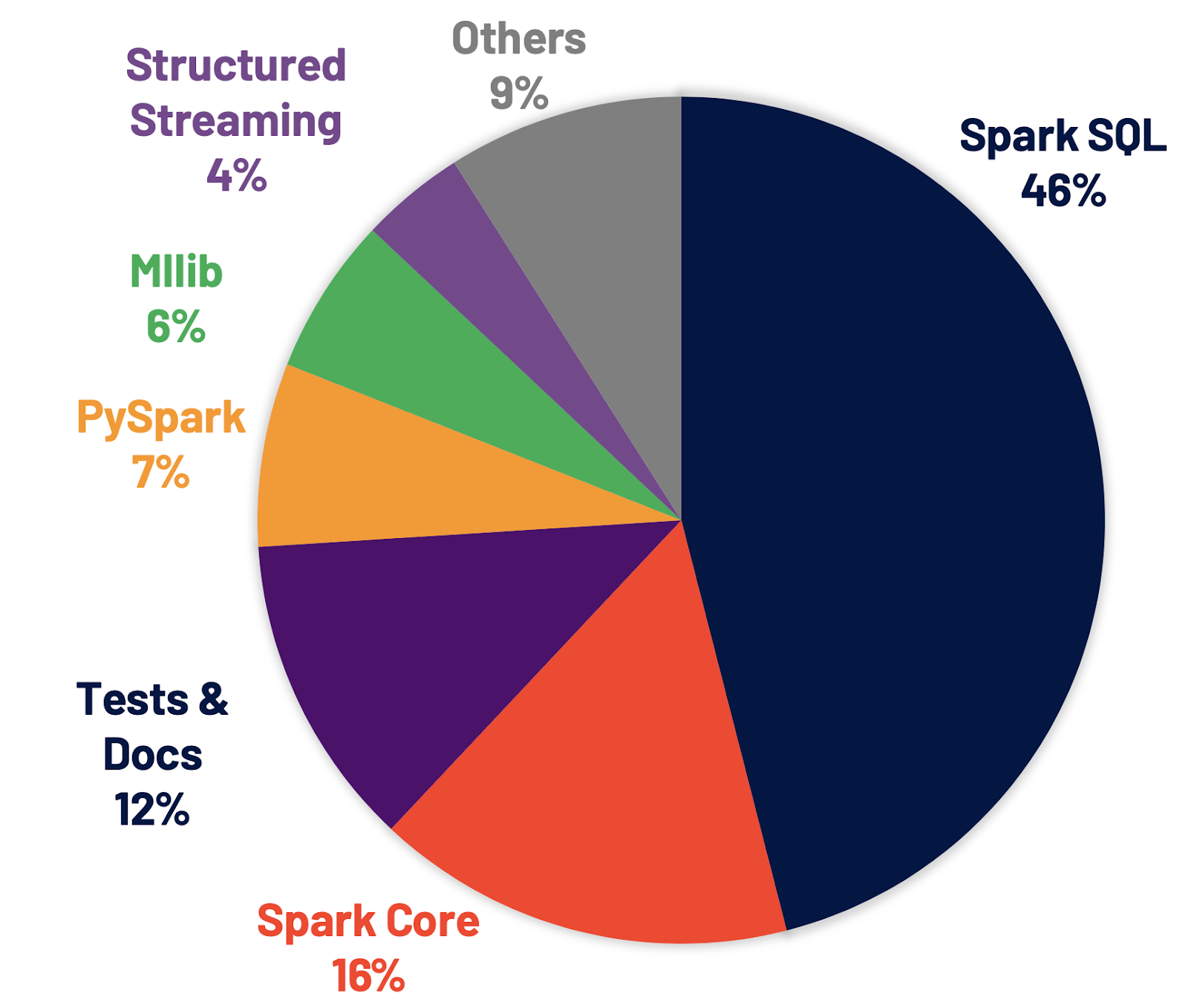
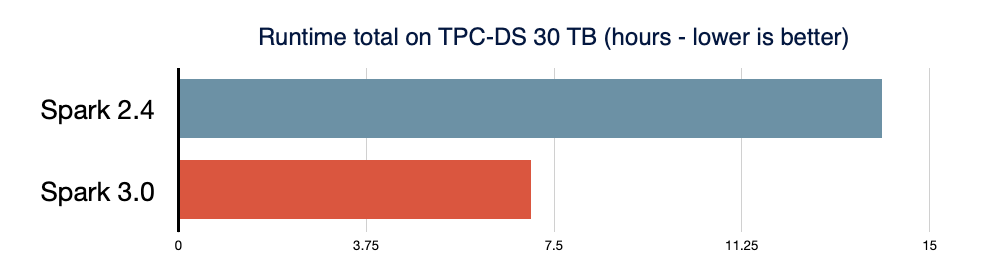
Spark SQL è il motore che supporta la maggior parte delle applicazioni Spark. Ad esempio, su Databricks, abbiamo riscontrato che oltre il 90% delle chiamate Spark API utilizza le API DataFrame, set di dati e SQL, insieme ad altre librerie ottimizzate dall'ottimizzatore SQL. Ciò significa che anche gli sviluppatori Python e Scala eseguono gran parte del loro lavoro attraverso il motore Spark SQL. Nella release di Spark 3.0, il 46% di tutte le patch apportate riguardava SQL, migliorando sia le prestazioni che la compatibilità ANSI. Come illustrato di seguito, Spark 3.0 ha ottenuto prestazioni circa 2 volte superiori a quelle di Spark 2.4 in termini di tempo di esecuzione totale. Di seguito, illustriamo quattro nuove funzionalità del motore Spark SQL.
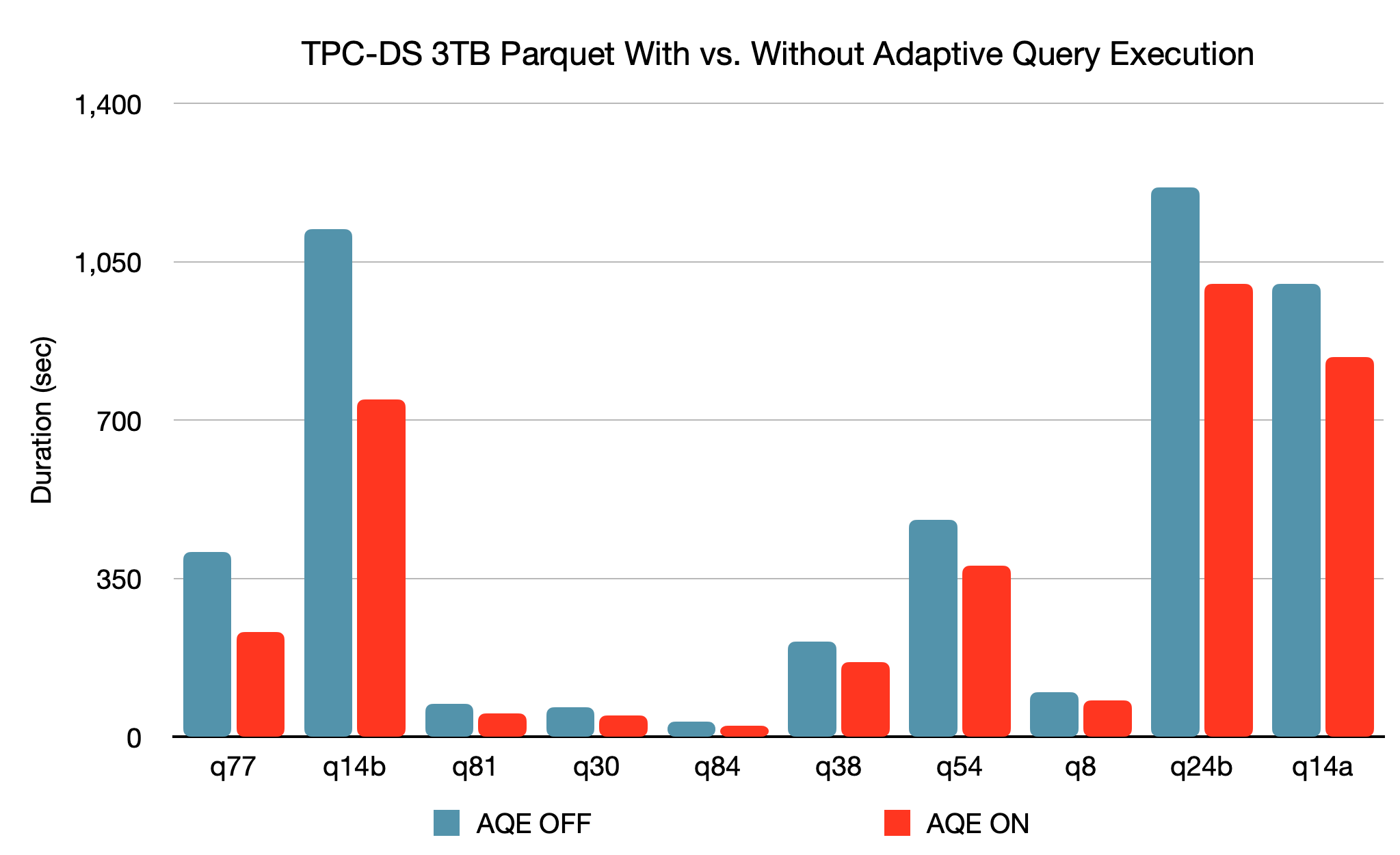
Il nuovo framework Adaptive Query Execution (AQE) migliora le prestazioni e semplifica l'ottimizzazione generando un piano di esecuzione migliore in fase di esecuzione, anche se il piano iniziale è subottimale a causa di statistiche sui dati assenti/imprecise e costi stimati in modo errato. A causa della separazione tra archiviazione e compute in Spark, l'arrivo dei dati può essere imprevedibile. Per tutte queste ragioni, l'adattabilità in fase di esecuzione diventa più critica per Spark rispetto ai sistemi tradizionali. Questa versione introduce tre importanti ottimizzazioni adattive:
- L'unione dinamica delle partizioni di shuffle semplifica o addirittura evita la regolazione del numero di partizioni di shuffle. Gli utenti possono impostare un numero relativamente elevato di partizioni di shuffle all'inizio e AQE può quindi unire le partizioni piccole adiacenti in partizioni più grandi in fase di esecuzione.
- Il cambio dinamico delle strategie di join evita parzialmente l'esecuzione di piani non ottimali a causa di statistiche mancanti e/o di una stima errata delle dimensioni. Questa ottimizzazione adattiva può convertire automaticamente il sort-merge join in broadcast-hash join a runtime, semplificando ulteriormente la messa a punto e migliorando le prestazioni.
- L'ottimizzazione dinamica degli skew join è un altro miglioramento critico delle prestazioni, poiché gli skew join possono portare a uno squilibrio estremo del carico di lavoro e ridurre gravemente le prestazioni. Dopo che AQE ha rilevato un'asimmetria dalle statistiche dei file di shuffle, può suddividere le partizioni asimmetriche in partizioni più piccole e unirle con le partizioni corrispondenti dall'altro lato. Questa ottimizzazione può parallelizzare l'elaborazione degli skew e ottenere prestazioni complessive migliori.
Sulla base di un benchmark TPC-DS da 3 TB, rispetto all'assenza di AQE, Spark con AQE può generare un'accelerazione delle prestazioni superiore a 1,5 volte per due query e superiore a 1,1 volte per altre 37 query.
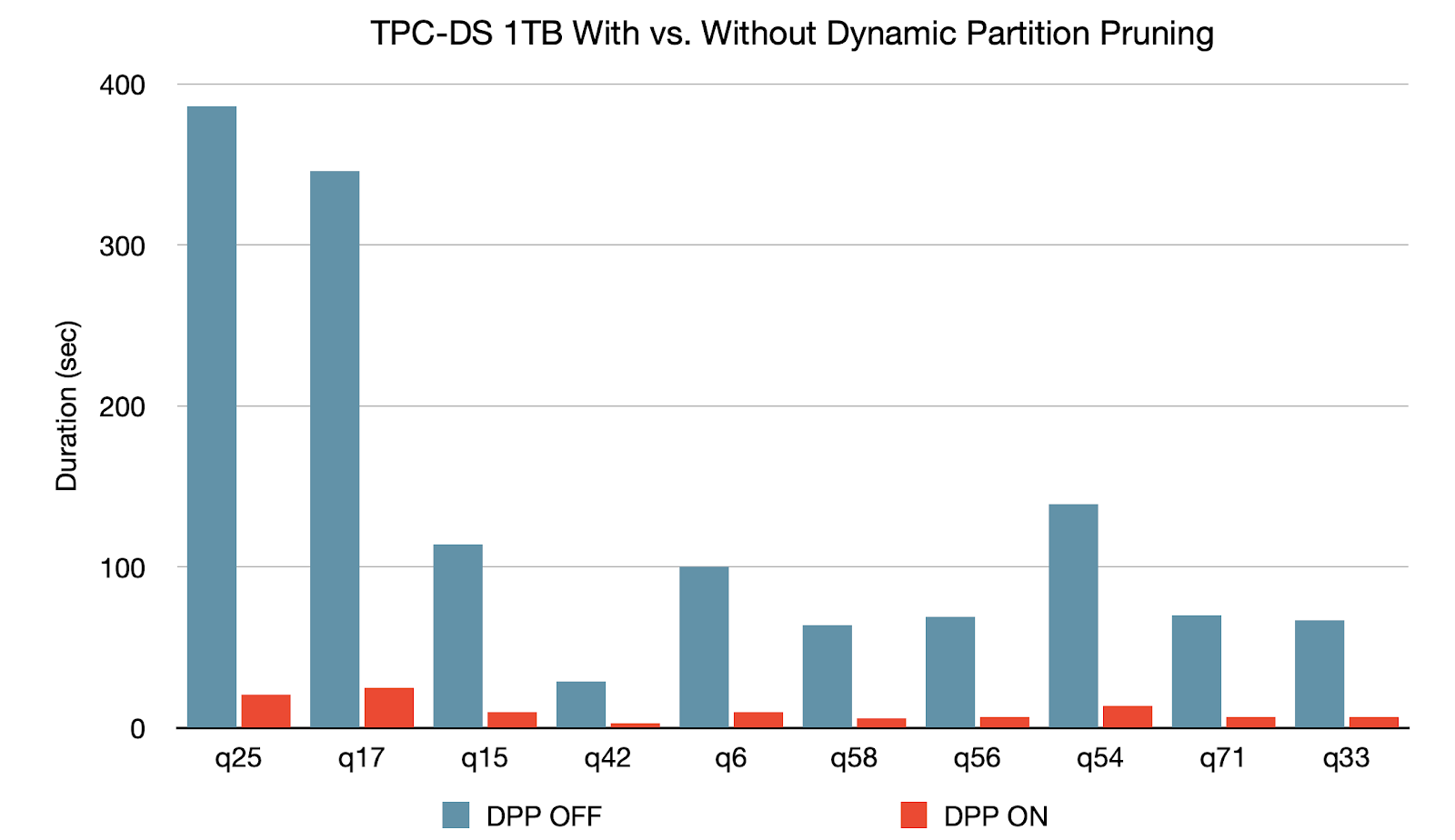
Dynamic Partition Pruning viene applicato quando l'ottimizzatore non è in grado di identificare in fase di compilazione le partizioni che può saltare. Questo non è raro negli schemi a stella, che consistono in una o più tabelle dei fatti che fanno riferimento a un numero qualsiasi di tabelle delle dimensioni. In tali attività operative di join, possiamo eliminare le partizioni che il join legge da una tabella dei fatti, identificando quelle partizioni che risultano dal filtraggio delle tabelle delle dimensioni. In un benchmark TPC-DS, 60 query su 102 mostrano un significativo aumento della velocità compreso tra 2x e 18x.
La conformità ANSI SQL è fondamentale per la migrazione dei carichi di lavoro da altri motori SQL a Spark SQL. Per migliorare la conformità, questa versione passa al calendario gregoriano prolettico e consente inoltre agli utenti di vietare l'uso delle parole chiave riservate di ANSI SQL come identificatori. Inoltre, abbiamo introdotto il controllo dell'overflow in fase di esecuzione nelle attività operative numeriche e l'applicazione dei tipi in fase di compilazione durante l'inserimento di dati in una tabella con uno schema predefinito. Queste nuove convalide migliorano la qualità dei dati.
Suggerimenti di join: Anche se continuiamo a migliorare il compilatore, non vi è alcuna garanzia che il compilatore possa sempre prendere la decisione ottimale in ogni situazione: la selezione dell'algoritmo di join si basa su statistiche ed euristiche. Quando il compilatore non è in grado di fare la scelta migliore, gli utenti possono utilizzare i suggerimenti di join per influenzare l'ottimizzatore a scegliere un piano migliore. Questa versione estende i suggerimenti di join esistenti aggiungendo nuovi suggerimenti: SHUFFLE_MERGE, SHUFFLE_HASH e SHUFFLE_REPLICATE_NL.
Python è oggi il linguaggio più utilizzato in Spark e, di conseguenza, è stato un'area di interesse chiave dello sviluppo di Spark 3.0. Il 68% dei comandi dei notebook su Databricks è in Python. PySpark, l'API Python di Apache Spark, registra più di 5 milioni di download mensili su PyPI, il Python Indice dei pacchetti.
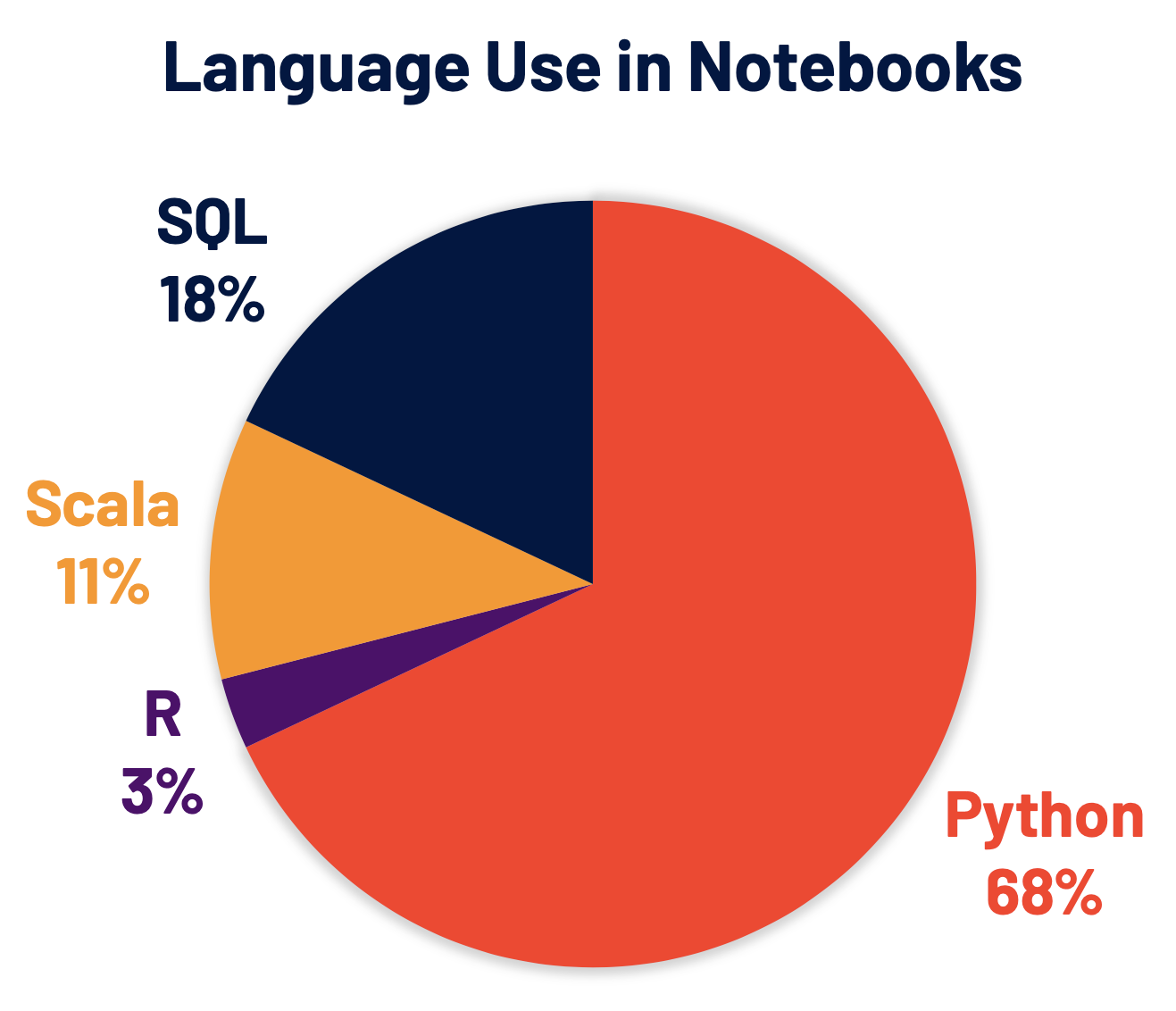
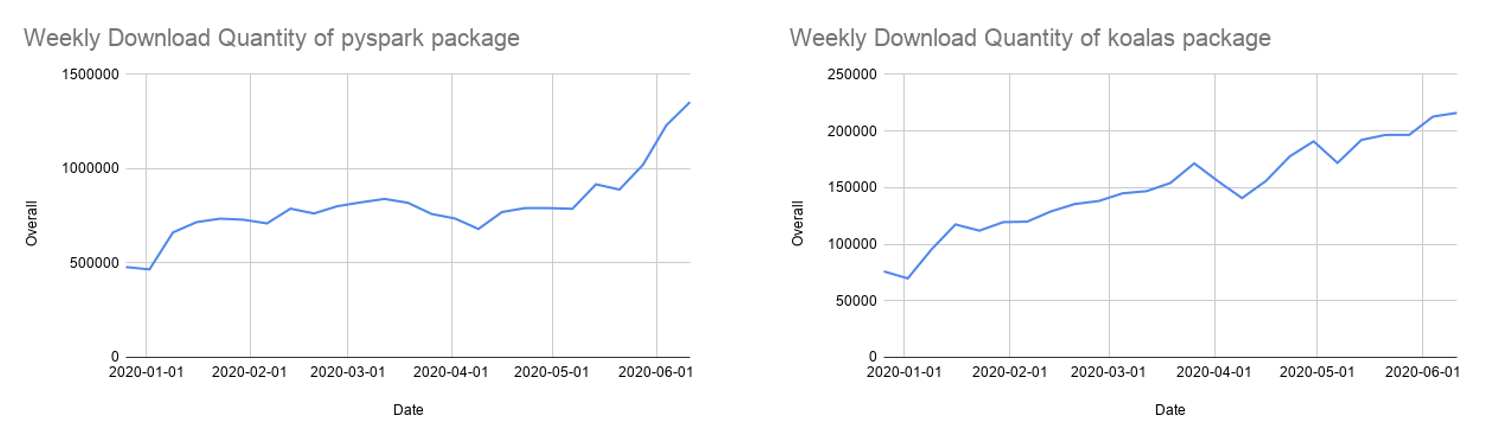
Molti sviluppatori Python utilizzano l'API di pandas per le strutture di dati e l'analisi dei dati, ma è limitata all'elaborazione su un singolo nodo. Abbiamo inoltre continuato a sviluppare Koalas, un'implementazione dell'API di pandas basata su Apache Spark, per rendere i data scientist più produttivi quando lavorano con i Big Data in ambienti distribuiti. Koalas elimina la necessità di creare molte funzioni (ad esempio, il supporto per il plotting) in PySpark per ottenere prestazioni efficienti su un cluster.
Dopo più di un anno di sviluppo, la copertura dell'API di Koalas per pandas è vicina all'80%. I download mensili di Koalas da PyPI sono cresciuti rapidamente fino a 850.000 e Koalas si sta evolvendo altrettanto rapidamente con una cadenza di rilascio bisettimanale. Sebbene Koalas possa essere il modo più semplice per migrare il codice pandas da un singolo nodo, molti utilizzano ancora le API di PySpark, che sono anch'esse sempre più popolari.
Spark 3.0 introduce diversi miglioramenti alle APIs PySpark:
- Nuove API di pandas con suggerimenti di tipo: le UDF di pandas sono state introdotte inizialmente in Spark 2.3 per la scalabilità delle funzioni definite dall'utente in PySpark e per l'integrazione delle API di pandas nelle applicazioni PySpark. Tuttavia, l'interfaccia esistente è difficile da capire quando vengono aggiunti altri tipi di UDF. Questa versione introduce una nuova interfaccia UDF di pandas che sfrutta i type hint di Python per gestire la proliferazione dei tipi di UDF di pandas. La nuova interfaccia diventa più Pythonic e auto-descrittiva.
- Nuovi tipi di UDF pandas e APIs di funzioni pandas: Questa versione aggiunge due nuovi tipi di UDF pandas, iteratore di serie a iteratore di serie e iteratore di più serie a iteratore di serie. È utile per il prefetching dei dati e per l'inizializzazione onerosa. Inoltre, vengono aggiunte due nuove API di funzioni pandas, map e co-grouped map. Maggiori dettagli sono disponibili in questo post su un blog.
- Migliore gestione degli errori: la gestione degli errori di PySpark non è sempre intuitiva per gli utenti Python. Questa versione semplifica le eccezioni di PySpark, nasconde lo stack trace della JVM non necessario e le rende più Pythonic.
Migliorare il supporto e l'usabilità di Python in Spark continua a essere una delle nostre massime priorità.
Hydrogen, streaming ed estensibilità
Con Spark 3.0, abbiamo completato i componenti chiave per Project Hydrogen e introdotto nuove funzionalità per migliorare lo streaming e l'estensibilità.
- Pianificazione consapevole degli acceleratori: Project Hydrogen è un'importante iniziativa di Spark per unificare meglio il deep learning e l'elaborazione dei dati su Spark. Le GPU e altri acceleratori sono stati ampiamente utilizzati per accelerare i carichi di lavoro di deep learning. Per consentire a Spark di sfruttare gli acceleratori hardware sulle piattaforme di destinazione, questa versione migliora lo scheduler esistente per rendere il gestore del cluster consapevole degli acceleratori. Gli utenti possono specificare gli acceleratori tramite la configurazione con l'aiuto di uno script di rilevamento. Gli utenti possono quindi chiamare le nuove API RDD per sfruttare questi acceleratori.
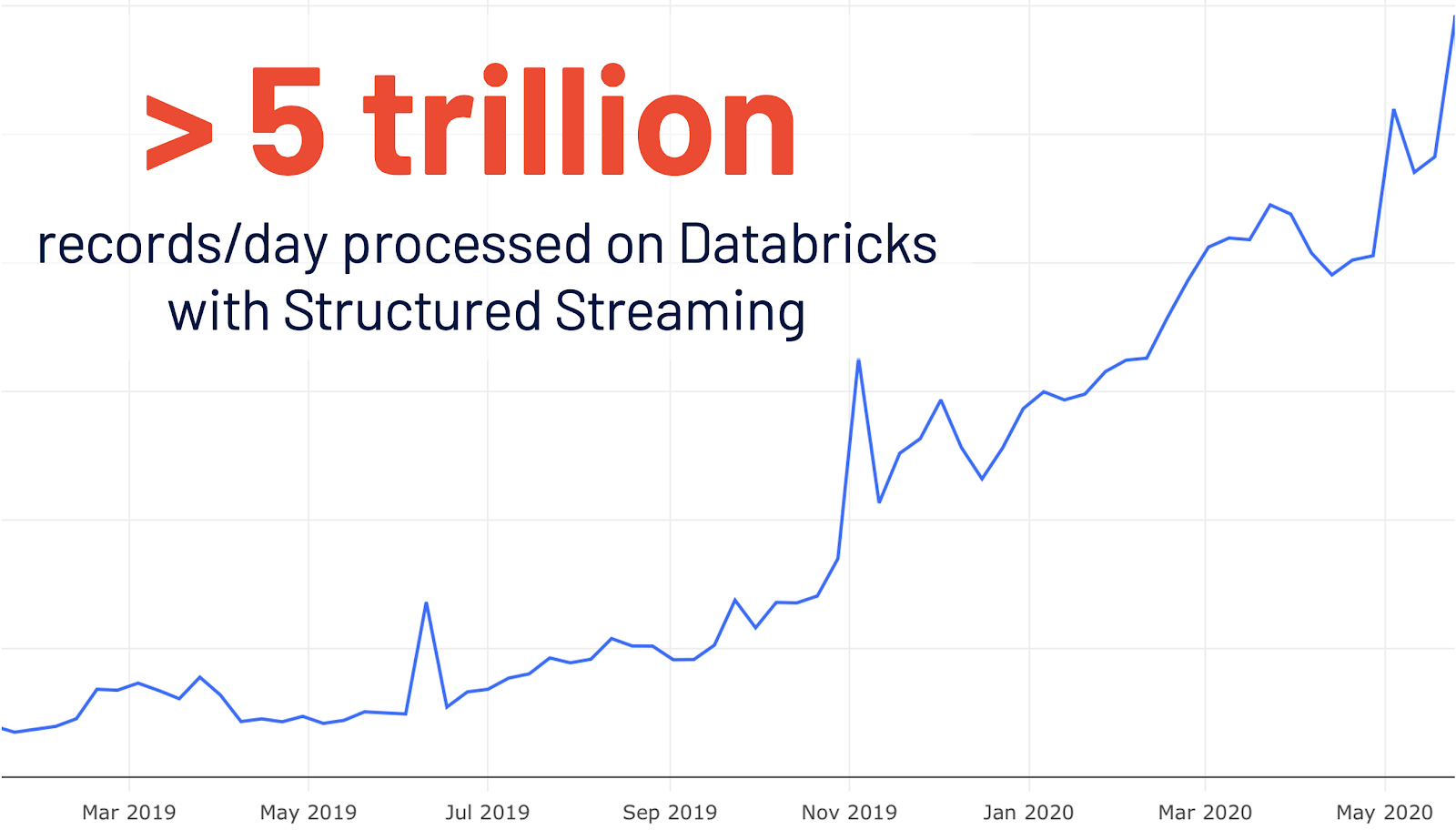
- Nuova UI per lo streaming strutturato: lo streaming strutturato è stato introdotto inizialmente in Spark 2.0. Dopo una crescita del 4x su base annua nell'utilizzo su Databricks, più di 5 mila miliardi di record al giorno vengono elaborati su Databricks con lo streaming strutturato. Questa versione aggiunge una nuova Spark UI dedicata per l'ispezione di questi processi di streaming. Questa nuova UI offre due set di statistiche: 1) informazioni aggregate sui Job di query di streaming completati e 2) informazioni statistiche dettagliate sulle query di streaming.
- Metriche osservabili: Il monitoraggio continuo delle modifiche alla qualità dei dati è una funzionalità altamente desiderabile per la gestione delle pipeline di dati. Questa versione introduce il monitoraggio per le applicazioni sia batch che di streaming. Le metriche osservabili sono funzioni di aggregazione arbitrarie che possono essere definite su una query (DataFrame). Non appena l'esecuzione di un DataFrame raggiunge un punto di completamento (ad esempio, termina una query batch o raggiunge un'epoca di streaming), viene emesso un evento denominato che contiene le metriche per i dati elaborati dall'ultimo punto di completamento.
- Nuova API per plug-in di catalogo: l'API per le sorgenti di dati esistente non ha la capacità di accedere e manipolare i metadati delle sorgenti di dati esterne. Questa versione arricchisce l'API V2 per le sorgenti di dati e introduce la nuova API per plug-in di catalogo. Per le sorgenti di dati esterne che implementano sia l'API per plug-in di catalogo che l'API V2 per le sorgenti di dati, gli utenti possono manipolare direttamente sia i dati che i metadati delle tabelle esterne tramite identificatori multiparte, dopo la registrazione del catalogo esterno corrispondente.
Altri aggiornamenti in Spark 3.0
Spark 3.0 è una release importante per la community, con oltre 3.400 ticket Jira risolti. È il risultato dei contributi di oltre 440 collaboratori, tra cui privati e aziende come Databricks, Google, Microsoft, Intel, IBM, Alibaba, Facebook, Nvidia, Netflix, Adobe e molte altre. In questo post su un blog abbiamo evidenziato alcuni dei principali progressi di SQL, Python e streaming in Spark, ma questa milestone 3.0 include molte altre funzionalità che non sono state trattate qui. Per saperne di più, consulta le note di rilascio e scopri tutti gli altri miglioramenti di Spark, tra cui sorgenti di dati, ecosistema, monitoraggio e altro ancora.
Inizia oggi stesso a usare Spark 3.0
Se vuoi provare Apache Spark 3.0 in Databricks Runtime 7.0, registrati per un account di prova gratuito e inizia in pochi minuti. Usare Spark 3.0 è semplice: basta selezionare la versione "7.0" quando si avvia un cluster.
Scopri di più sulle funzionalità e sui dettagli della versione:
- O’Reilly's New Learning Spark, 2nd Edition, download gratuito dell'e-book
- Adaptive Query Execution blog
- UDF di Pandas e suggerimenti di tipo Python blog
- Spark 3.0 Preview webinar on-demand
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.