Che cos'è Spark Tuning?
L'ottimizzazione sistematica delle configurazioni di Apache Spark, dell'utilizzo della memoria e delle strategie di esecuzione per massimizzare le prestazioni prevenendo al contempo i colli di bottiglia delle risorse
- Spark tuning regola l'allocazione della memoria tra storage ed esecuzione, gestisce la serializzazione dei dati per le prestazioni di rete e ottimizza le partizioni shuffle per prevenire costosi spilling del disco.
- Adaptive Query Execution (AQE) trova automaticamente le partizioni shuffle ottimali e risolve la distorsione dei dati, mentre Cost-Based Optimizer (CBO) utilizza le statistiche delle tabelle per selezionare strategie di join efficienti.
- Tecniche avanzate includono join broadcast per tabelle di piccole dimensioni, pushdown dei predicati per ridurre il trasferimento dati e un'attenta gestione della cache rispetto allo storage su disco per accessi ripetuti ai dati.
Che cos'è l'ottimizzazione delle prestazioni di Spark?
L'ottimizzazione delle prestazioni di Spark si riferisce al processo di regolazione delle impostazioni relativamente alla memoria, ai core e alle istanze utilizzate dal sistema. Questo processo garantisce che Spark abbia prestazioni ottimali e previene i colli di bottiglia delle risorse. 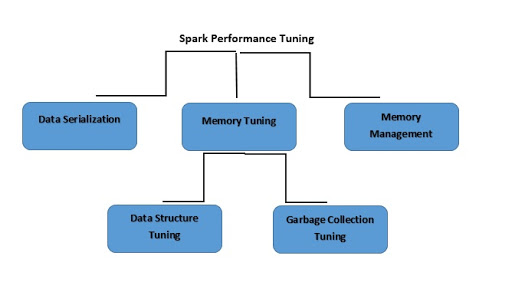
Che cos'è la serializzazione dei dati?
Per ridurre l'uso della memoria, potrebbe essere necessario memorizzare gli RDD Spark in forma serializzata, una soluzione che migliora anche le prestazioni della rete. Puoi ottenere una buona prestazione da Spark:
- Interrompendo i job che si protraggono a lungo.
- Garantendo che i job vengano eseguiti su un motore di esecuzione specifico.
- Utilizzando tutte le risorse in modo efficiente.
- Migliorando il tempo di esecuzione del sistema.
Spark supporta due librerie di serializzazione:
- Serializzazione Java
- Serializzazione Kryo
Che cos'è l'ottimizzazione della memoria?
Nell'ottimizzazione dell'utilizzo della memoria bisogna considerare tre aspetti:
- L'intero set di dati deve essere contenuto nella memoria, quindi è necessario tenere conto della memoria utilizzata dagli oggetti.
- Avendo un elevato avvicendamento di oggetti, l'overhead della garbage collection diventa una necessità.
- Bisogna tenere conto del costo che accedere a tali oggetti comporta.
Il playbook sull'AI agentiva per l'enterprise

Che cos'è l'ottimizzazione della struttura dei dati?
Un'opzione per ridurre il consumo di memoria �è quella di evitare le funzioni di Java che potrebbero creare overhead. Ecco alcuni suggerimenti:
- Se la dimensione della RAM è inferiore a 32 GB, il flag JVM deve essere impostato su –xx:+ UseCompressedOops. Questa operazione costruirà un puntatore di quattro byte anziché otto.
- È possibile evitare le strutture annidate utilizzando diversi piccoli oggetti e puntatori.
- Invece di usare stringhe come chiavi, si potrebbero usare ID numerici e oggetti enumerati.
Che cos'è l'ottimizzazione della garbage collection?
Per evitare l'overhead legato agli RDD che sono stati precedentemente memorizzati dal programma, Java elimina i vecchi oggetti per fare spazio ai nuovi. Tuttavia, utilizzando strutture di dati con un numero inferiore di oggetti, il costo si riduce notevolmente. Un esempio potrebbe essere l'impiego di un array di interi al posto di un elenco collegato. In alternativa, si possono usare gli oggetti in forma serializzata, in modo da avere un solo oggetto per ogni partizione RDD.
Che cos'è la gestione della memoria?
Un uso efficiente della memoria è essenziale per ottenere buone prestazioni. Spark utilizza la memoria principalmente per l'archiviazione e l'esecuzione. Quella archiviazione viene utilizzata per memorizzare i dati che verranno riutilizzati in seguito. La memoria di esecuzione viene invece utilizzata per il calcolo nelle operazioni di shuffle, ordinamento, join e aggregazione. I conflitti di accesso alla memoria pongono tre sfide ad Apache Spark:
- Come distribuire la memoria tra esecuzione e memorizzazione?
- Come distribuire la memoria tra più task in esecuzione contemporaneamente?
- Come distribuire la memoria tra gli operatori in esecuzione nello stesso task?
Invece di allocare staticamente la memoria in anticipo, si potrebbero gestire i conflitti di accesso alla memoria quando si presentano, forzando lo spilling.
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.