Che cos'è Apache Kylin?
Un motore OLAP distribuito che precalcola cubi multidimensionali da dati Hadoop, fornendo query in meno di un secondo su set di dati su scala petabyte
- Pre-calcola i cubi OLAP utilizzando MapReduce o Spark, memorizzando i risultati in HBase come coppie chiave-valore che consentono risposte alle query a livello di millisecondi su miliardi di righe.
- Fornisce un'interfaccia SQL ANSI e un'integrazione perfetta con strumenti di BI come Tableau, Power BI ed Excel tramite API JDBC, ODBC e REST per flussi di lavoro di analisi familiari.
- Gestisce schemi a stella e a fiocco di neve con supporto per build di cubi incrementali, conteggi distinti approssimativi tramite HyperLogLog e tecniche di compressione per ottimizzare l'archiviazione.
Che cos'è Apache Kylin?
Apache Kylin è un motore di elaborazione analitica online (OLAP) distribuito e open source per l'analisi interattiva dei Big Data. È stato progettato per fornire un'interfaccia SQL e analisi multidimensionale (OLAP) su Hadoop/Spark. Inoltre, si integra facilmente con strumenti di BI tramite driver ODBC, driver JDBC e API REST. Creato da eBay nel 2014, è diventato un Top Level Project della Apache Software Foundation appena un anno dopo, nel 2015, e ha vinto il premio come miglior strumento open source per Big Data sia nel 2015 che nel 2016. Attualmente, viene utilizzato da migliaia di aziende in tutto il mondo come applicazione essenziale per l'analisi dei Big Data. Mentre altri motori OLAP faticano a gestire volumi di dati elevati, Kylin consente risposte alle query nell'ordine dei millisecondi, garantendo una latenza a livello di frazioni di secondo anche su set di dati che scalano fino ai petabyte. La sua incredibile velocità deriva dal precalcolo delle varie combinazioni dimensionali e degli aggregati delle misure tramite query Hive, i cui risultati vengono poi memorizzati in HBase. 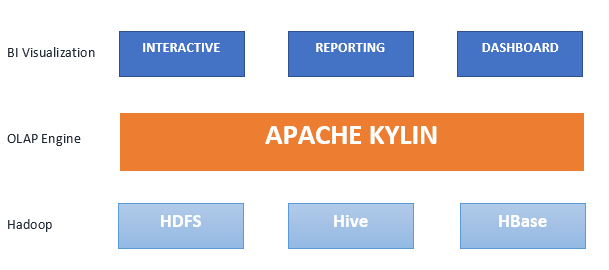
Il playbook sull'AI agentiva per l'enterprise

Come funziona Apache Kylin?
Il motore di query Kylin, accessibile tramite l'interfaccia utente intuitiva di Kylin, un'API o JDBC, sfrutta il processore di query Apache Calcite e le funzionalità di HBase per ricerche rapide. Kylin si basa sull'ecosistema Hadoop:
- Hive – Fonte di input, pre-join dello schema a stella durante la costruzione dei cubi
- MapReduce – Aggrega le metriche durante la costruzione dei cubi
- HDFS – Memorizza file intermedi durante la costruzione dei cubi
- HBase – Memorizza e interroga i cubi di dati
- Calcite – Parsing SQL, generazione di codice, ottimizzazione Cosa può fare Apache Kylin per la tua organizzazione?
- Motore OLAP estremamente veloce e scalabile - Kylin è progettato per ridurre la latenza delle query su Hadoop e può elaborare oltre 10 miliardi di righe di dati a pochi secondi
- Interfaccia ANSI SQL su Hadoop - Kylin offre ANSI SQL su Hadoop e supporta la maggior parte delle funzioni di query ANSI SQL. Può essere utilizzato facilmente sia da analisti che da ingegneri in quanto non richiede alcuna programmazione
- Integrazione perfetta con strumenti di BI - Attualmente, Kylin offre capacità di integrazione con strumenti di BI come Tableau, JDBC/ODBC/Rest API
- Capacità di query interattiva - Gli utenti possono interagire con i dati di Hadoop tramite Kylin con una latenza inferiore al secondo
- Servizio di query MOLAP su miliardi di righe - Gli utenti possono definire un modello di dati e pre-costruirlo in Kylin, anche se contiene oltre 10 miliardi di record di dati grezzi.
Driver ODBC open-source - Il driver ODBC di Kylin è stato creato da zero e funziona molto bene con Tableau.
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.