Cos'è un file system distribuito Hadoop (HDFS)?
Archiviazione distribuita che suddivide i file in blocchi replicati sui nodi del cluster, fornendo tolleranza ai guasti, capacità scalabile e accesso ad alta velocità di trasferimento
- Il File System Distribuito Hadoop (HDFS) è un sistema di archiviazione che suddivide i file in blocchi e li distribuisce su molte macchine per scalabilità e tolleranza ai guasti.
- HDFS è stato progettato per archiviare set di dati molto grandi su cluster di hardware generico e mantenere i dati disponibili anche quando i singoli nodi falliscono.
- Sebbene molte organizzazioni ora utilizzino l'archiviazione a oggetti cloud con architetture lakehouse, la comprensione di HDFS aiuta a spiegare le basi dei primi sistemi di big data.
HDFS
HDFS (Hadoop Distributed File System) è il sistema di archiviazione primario utilizzato dalle applicazioni Hadoop. Questo framework open source funziona trasferendo rapidamente dati tra i nodi. Viene spesso utilizzato da aziende che necessitano di gestire e archiviare big data. HDFS è un componente chiave di molti sistemi Hadoop, poiché fornisce un mezzo per la gestione dei big data, oltre a supportare l'analisi dei big data.
Ci sono molte aziende in tutto il mondo che utilizzano HDFS, quindi cos'è esattamente e perché è necessario? Immergiamoci in ciò che è HDFS e perché potrebbe essere utile per le aziende.
Cos'è HDFS?
HDFS sta per Hadoop Distributed File System. HDFS opera come un file system distribuito progettato per essere eseguito su hardware di commodity.
HDFS è tollerante ai guasti ed è progettato per essere distribuito su hardware di commodity a basso costo. HDFS fornisce un accesso ai dati ad alta produttività ai dati delle applicazioni ed è adatto per applicazioni che hanno grandi set di dati e abilita l'accesso in streaming ai dati del file system in Apache Hadoop.
Quindi, cos'è Hadoop? E in cosa differisce da HDFS? Una differenza fondamentale tra Hadoop e HDFS è che Hadoop è il framework open source che può archiviare, elaborare e analizzare dati, mentre HDFS è il file system di Hadoop che fornisce l'accesso ai dati. Ciò significa essenzialmente che HDFS è un modulo di Hadoop.
Diamo un'occhiata all'architettura di HDFS:
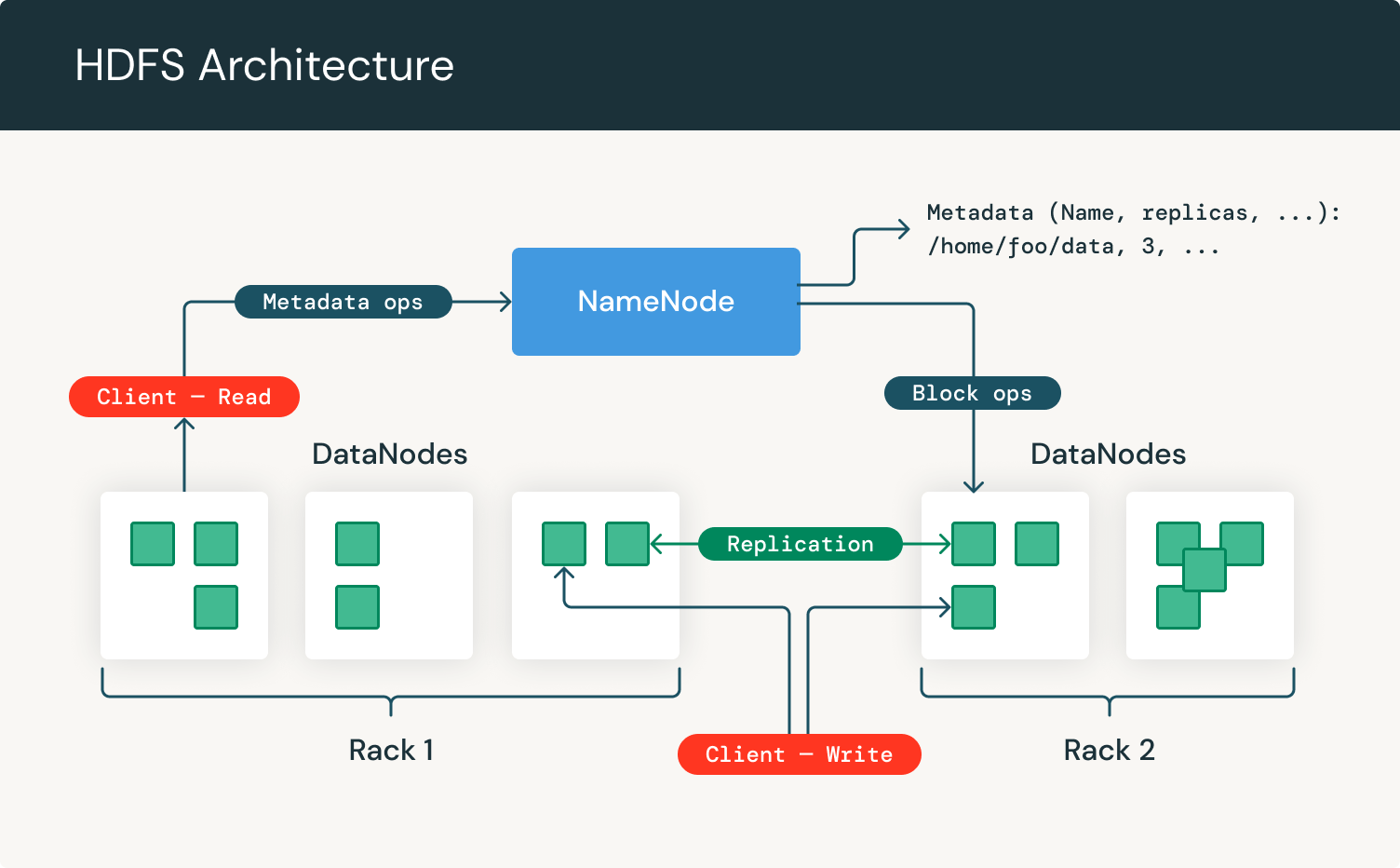
Come possiamo vedere, si concentra su NameNodes e DataNodes. Il NameNode è l'hardware che contiene il sistema operativo e il software GNU/Linux. Il file system distribuito Hadoop funge da server master e può gestire i file, controllare l'accesso di un client ai file e supervisionare i processi operativi sui file come rinominare, aprire e chiudere file.
Un DataNode è un hardware che possiede il sistema operativo GNU/Linux e il software DataNode. Per ogni nodo in un cluster HDFS, troverai un DataNode. Questi nodi aiutano a controllare l'archiviazione dei dati del loro sistema poiché possono eseguire operazioni sui file system se il client lo richiede, e anche creare, replicare e bloccare file quando il NameNode lo istruisce.
Il significato e lo scopo di HDFS sono raggiungere i seguenti obiettivi:
- Gestire grandi set di dati - Organizzare e archiviare set di dati può essere un compito difficile da gestire. HDFS viene utilizzato per gestire le applicazioni che devono affrontare enormi set di dati. Per fare ciò, HDFS dovrebbe avere centinaia di nodi per cluster.
- Rilevamento dei guasti - HDFS dovrebbe disporre di una tecnologia per scansionare e rilevare rapidamente ed efficacemente i guasti, poiché include un gran numero di hardware di commodity. Il guasto dei componenti è un problema comune.
- Efficienza hardware - Quando sono coinvolti grandi set di dati, può ridurre il traffico di rete e aumentare la velocità di elaborazione.
La storia di HDFS
Quali sono le origini di Hadoop? La progettazione di HDFS si basava sul Google File System. È stato originariamente costruito come infrastruttura per il progetto del motore di ricerca web Apache Nutch, ma da allora è diventato un membro dell'Ecosistema Hadoop.
Nei primi anni di Internet, sono apparsi i web crawler come mezzo per le persone per cercare informazioni sulle pagine web. Ciò ha creato vari motori di ricerca come Yahoo e Google.
Ha anche creato un altro motore di ricerca chiamato Nutch, che voleva distribuire dati e calcoli su più computer contemporaneamente. Nutch si è poi trasferito a Yahoo, ed è stato diviso in due. Apache Spark e Hadoop sono ora entità separate. Dove Hadoop è progettato per gestire l'elaborazione batch, Spark è fatto per gestire i dati in tempo reale in modo efficiente.
Oggi, la struttura e il framework di Hadoop sono gestiti dalla Apache Software Foundation, che è una comunità globale di sviluppatori e contributori di software.
HDFS è nato da questo ed è progettato per sostituire le soluzioni di archiviazione hardware con un metodo migliore e più efficiente: un file system virtuale. Quando è apparso per la prima volta, MapReduce era l'unico motore di elaborazione distribuita che poteva utilizzare HDFS. Più recentemente, componenti alternativi di servizi dati Hadoop come HBase e Solr utilizzano anche HDFS per archiviare dati.
Cos'è HDFS nel mondo dei big data?
Quindi, cosa sono i big data e come entra in gioco HDFS? Il termine "big data" si riferisce a tutti i dati difficili da archiviare, elaborare e analizzare. I big data di HDFS sono dati organizzati nel file system HDFS.
Come sappiamo ora, Hadoop è un framework che funziona utilizzando l'elaborazione parallela e l'archiviazione distribuita. Questo può essere utilizzato per ordinare e archiviare big data, poiché non possono essere archiviati nei modi tradizionali.
Infatti, è il software più comunemente utilizzato per gestire i big data, ed è utilizzato da aziende come Netflix, Expedia e British Airways che hanno una relazione positiva con Hadoop per l'archiviazione dei dati. HDFS nei big data è vitale, poiché è così che molte aziende scelgono ora di archiviare i propri dati.
Ci sono cinque elementi fondamentali dei big data organizzati dai servizi HDFS:
- Velocità - Quanto velocemente vengono generati, raccolti e analizzati i dati.
- Volume - La quantità di dati generati.
- Varietà - Il tipo di dati, che può essere strutturato, non strutturato, ecc.
- Veridicità - La qualità e l'accuratezza dei dati.
- Valore - Come è possibile utilizzare questi dati per ottenere informazioni sui processi aziendali.
Vantaggi di Hadoop Distributed File System
Come sottoprogetto open source all'interno di Hadoop, HDFS offre cinque vantaggi fondamentali quando si tratta di big data:
- Tolleranza ai guasti. HDFS è stato progettato per rilevare i guasti e recuperare automaticamente rapidamente, garantendo continuità e affidabilità.
- Velocità, grazie alla sua architettura a cluster, può mantenere 2 GB di dati al secondo.
- Accesso a più tipi di dati, in particolare dati in streaming. Grazie alla sua progettazione per gestire grandi quantità di dati per l'elaborazione batch, consente elevate velocità di trasferimento dati, rendendolo ideale per supportare dati in streaming.
Compatibilità e portabilità. HDFS è progettato per essere portatile su una varietà di configurazioni hardware e compatibile con diversi sistemi operativi sottostanti, offrendo in definitiva agli utenti la possibilità di utilizzare HDFS con la propria configurazione personalizzata. Questi vantaggi sono particolarmente significativi quando si tratta di big data e sono stati resi possibili dal modo particolare in cui HDFS gestisce i dati.
Questo grafico dimostra la differenza tra un file system locale e HDFS.
- Scalabile. È possibile scalare le risorse in base alle dimensioni del file system. HDFS include meccanismi di scalabilità verticale e orizzontale.
- Località dei dati. Quando si tratta del file system Hadoop, i dati risiedono nei data node, anziché spostare i dati dove si trova l'unità computazionale. Riducendo la distanza tra i dati e il processo di calcolo, si riduce la congestione della rete e si rende il sistema più efficace ed efficiente.
- Conveniente. Inizialmente, quando pensiamo ai dati, potremmo pensare a hardware costoso e larghezza di banda occupata. Quando si verifica un guasto hardware, può essere molto costoso da riparare. Con HDFS, i dati vengono archiviati in modo economico poiché è virtuale, il che può ridurre drasticamente i costi di archiviazione dei metadati del file system e dei dati dello spazio dei nomi del file system. Inoltre, poiché HDFS è open source, le aziende non devono preoccuparsi di pagare una licenza.
- Archivia grandi quantità di dati. L'archiviazione dei dati è ciò di cui si occupa HDFS, il che significa dati di tutte le varietà e dimensioni, ma in particolare grandi quantità di dati da aziende che faticano ad archiviarli. Ciò include dati sia strutturati che non strutturati.
- Flessibile. A differenza di alcuni altri database di archiviazione più tradizionali, non è necessario elaborare i dati raccolti prima di archiviarli. È possibile archiviare la quantità di dati desiderata, con l'opportunità di decidere esattamente cosa farne e come utilizzarla in seguito. Ciò include anche dati non strutturati come testo, video e immagini.
Come usare HDFS
Quindi, come si usa HDFS? Bene, HDFS funziona con un NameNode principale e più altri datanode, tutti su un cluster di hardware di commodity. Questi nodi sono organizzati nello stesso posto all'interno del data center. Successivamente, viene suddiviso in blocchi che vengono distribuiti tra i DataNode multipli per l'archiviazione. Per ridurre le possibilità di perdita di dati, i blocchi vengono spesso replicati tra i nodi. È un sistema di backup in caso di perdita di dati.
Vediamo i NameNode. Il NameNode è il nodo all'interno del cluster che sa cosa contiene il dato, a quale blocco appartiene, la dimensione del blocco e dove dovrebbe andare. I NameNode sono anche utilizzati per controllare l'accesso ai file, inclusi i momenti in cui qualcuno può scrivere, leggere, creare, rimuovere e replicare dati tra i vari DataNode.
Il cluster può anche essere adattato quando necessario in tempo reale, a seconda della capacità del server, il che può essere utile quando c'è un picco di dati. I nodi possono essere aggiunti o rimossi quando necessario.
Ora, passiamo ai DataNode. I DataNode sono in costante comunicazione con i NameNode per identificare se devono avviare e completare un'attività. Questo flusso di collaborazione costante significa che il NameNode è pienamente consapevole dello stato di ciascun DataNode.
Quando un DataNode viene individuato come non operativo nel modo corretto, il NameNode è in grado di riassegnare automaticamente tale attività a un altro nodo funzionante nello stesso datablock. Allo stesso modo, i DataNode sono anche in grado di comunicare tra loro, il che significa che possono collaborare durante le operazioni standard sui file. Poiché il NameNode è consapevole dei DataNode e delle loro prestazioni, sono cruciali nel mantenimento del sistema.
I Datablock vengono replicati su più DataNode e acceduti dal NameNode.
Per utilizzare HDFS è necessario installare e configurare un cluster Hadoop. Questo può essere una configurazione a nodo singolo, più adatta agli utenti alle prime armi, o una configurazione a cluster per cluster di grandi dimensioni e distribuiti. È quindi necessario familiarizzare con i comandi HDFS, come quelli sottostanti, per operare e gestire il proprio sistema.
| Comando | Descrizione |
| -rm | Rimuove file o directory |
| -ls | Elenca i file con permessi e altri dettagli |
| -mkdir | Crea una directory chiamata path in HDFS |
| -cat | Mostra il contenuto del file |
| -rmdir | Elimina una directory |
| -put | Carica un file o una cartella da un disco locale a HDFS |
| -rmr | Elimina il file identificato da path o la cartella e le sottocartelle |
| -get | Sposta file o cartella da HDFS a file locale |
| -count | Conta il numero di file, il numero di directory e la dimensione del file |
| -df | Mostra lo spazio libero |
| -getmerge | Unisce più file in HDFS |
| -chmod | Cambia i permessi del file |
| -copyToLocal | Copia i file nel sistema locale |
| -Stat | Stampa statistiche sul file o sulla directory |
| -head | Visualizza il primo kilobyte di un file |
| -usage | Restituisce l'aiuto per un singolo comando |
| -chown | Assegna un nuovo proprietario e gruppo a un file |
Come funziona HDFS?
Come accennato in precedenza, HDFS utilizza NameNode e DataNode. HDFS consente il rapido trasferimento di dati tra i nodi di calcolo. Quando HDFS riceve dati, è in grado di suddividere le informazioni in blocchi, distribuendoli a diversi nodi in un cluster.
I dati vengono suddivisi in blocchi e distribuiti tra i DataNode per l'archiviazione; questi blocchi possono anche essere replicati tra i nodi, consentendo un'efficiente elaborazione parallela. È possibile accedere, spostarsi e visualizzare i dati tramite vari comandi. Le opzioni HDFS DFS come "-get" e "-put" consentono di recuperare e spostare i dati secondo necessità.
Inoltre, HDFS è progettato per essere altamente reattivo e può rilevare rapidamente i guasti. Il file system utilizza la replica dei dati per garantire che ogni pezzo di dato venga salvato più volte e quindi lo assegna a singoli nodi, garantendo che almeno una copia sia su un rack diverso rispetto alle altre copie.
Ciò significa che quando un DataNode non invia più segnali al NameNode, questo rimuove il DataNode dal cluster e opera senza di esso. Se questo nodo dati ritorna, può essere assegnato a un nuovo cluster. Inoltre, poiché i datablock sono replicati su diversi DataNode, la rimozione di uno non comporterà alcuna corruzione dei file di alcun tipo.
Componenti HDFS
È importante sapere che ci sono tre componenti principali di Hadoop. Hadoop HDFS, Hadoop MapReduce e Hadoop YARN. Diamo un'occhiata a cosa questi componenti portano ad Hadoop:
- Hadoop HDFS - Hadoop Distributed File System (HDFS) è l'unità di archiviazione di Hadoop.
- Hadoop MapReduce - Hadoop MapReduce è l'unità di elaborazione di Hadoop. Questo framework software viene utilizzato per scrivere applicazioni per elaborare enormi quantità di dati.
- Hadoop YARN - Hadoop YARN è un componente di gestione delle risorse di Hadoop. Elabora ed esegue dati per l'elaborazione batch, stream, interattiva e grafica, tutti archiviati in HDFS.
Come creare un file system HDFS
Vuoi sapere come creare un file system HDFS? Segui i passaggi seguenti che ti guideranno su come creare il sistema, modificarlo e rimuoverlo se necessario.
Elenco del tuo HDFS
Il tuo elenco HDFS dovrebbe essere /user/yourUserName. Per visualizzare il contenuto della tua directory home HDFS, inserisci:
Dato che sei solo all'inizio, non sarai in grado di vedere nulla in questa fase. Quando vuoi visualizzare il contenuto di una directory non vuota, inserisci:
Potrai quindi vedere i nomi delle directory home di tutti gli altri utenti Hadoop.
Creazione di una directory in HDFS
Ora puoi creare una directory di test, chiamiamola testHDFS. Apparirà all'interno del tuo HDFS. Inserisci semplicemente quanto segue:
Ora devi verificare che la directory esista utilizzando il comando che hai inserito quando hai elencato il tuo HDFS. Dovresti vedere la directory testHDFS elencata.
Verificalo di nuovo utilizzando il percorso completo HDFS della tua HDFS. Inserisci:
Verifica che questo funzioni prima di passare ai passaggi successivi.
Copia di un file
Per copiare un file dal tuo file system locale a HDFS, inizia creando un file che desideri copiare. Per fare ciò, inserisci:
Questo creerà un nuovo file chiamato testFile, inclusi i caratteri HDFS test file. Per verificarlo, inserisci:
ls
E poi per verificare che il file sia stato creato, inserisci:
Dovrai quindi copiare il file in HDFS. Per copiare file da Linux a HDFS, devi usare:
Nota che devi usare il comando "-copyFromLocal" perché il comando "-cp" viene utilizzato per copiare file all'interno di HDFS.
Ora devi solo confermare che il file è stato copiato correttamente. Fallo inserendo quanto segue:
Spostamento e copia di file
Quando hai copiato il testfile, è stato inserito nella directory home di base. Ora puoi spostarlo nella directory testHDFS che hai già creato. Usa quanto segue:
La prima parte ha spostato il tuo testFile dalla directory home HDFS a quella di test che hai creato. La seconda parte di questo comando ci mostra quindi che non è più nella directory home HDFS, e la terza parte conferma che è stato ora spostato nella directory test HDFS.
Per copiare un file, inserisci:
Controllo dell'utilizzo del disco
Il controllo dello spazio su disco è utile quando si utilizza HDFS. Per fare ciò, puoi inserire il seguente comando:
Questo ti permetterà quindi di vedere quanto spazio stai utilizzando nella tua HDFS. Puoi anche vedere quanto spazio è disponibile in HDFS nel cluster inserendo:
Rimozione di un file/directory
Potrebbe arrivare un momento in cui è necessario eliminare un file o una directory in HDFS. Questo può essere ottenuto con il comando:
Vedrai che hai ancora la directory testHDFS e testFile2 rimaste che hai creato. Rimuovi la directory inserendo:
Apparirà un messaggio di errore, ma non farti prendere dal panico. Leggerà qualcosa come "rmdir: testhdfs: Directory is not empty". La directory deve essere vuota prima di poter essere eliminata. Puoi usare il comando "rm" per aggirare questo problema e rimuovere una directory inclusi tutti i file che contiene. Inserisci:
Il playbook sull'AI agentiva per l'enterprise

Come installare HDFS
Per installare Hadoop, devi ricordare che esiste un singlenode e un multinode. A seconda di ciò che ti serve, puoi utilizzare un cluster singlenode o multinode.
Un cluster a nodo singolo significa che è in esecuzione solo un DataNode. Includerà il NameNode, il DataNode, il gestore delle risorse e il gestore dei nodi su una macchina.
Per alcuni settori, questo è tutto ciò che serve. Ad esempio, nel campo medico, se stai conducendo studi e hai bisogno di raccogliere, ordinare ed elaborare dati in sequenza, puoi utilizzare un cluster a nodo singolo. Questo può gestire facilmente i dati su scala ridotta, rispetto ai dati distribuiti su centinaia di macchine. Per installare un cluster a nodo singolo, segui questi passaggi:
- Scarica il pacchetto Java 8. Salva questo file nella tua directory home.
- Estrai il file Tar di Java.
- Scarica il pacchetto Hadoop 2.7.3.
- Estrai il file Tar di Hadoop.
- Aggiungi i percorsi di Hadoop e Java nel file bash (.bashrc).
- Modifica i file di configurazione di Hadoop.
- Apri core-site.xml e modifica la proprietà.
- Modifica hdfs-site.xml e modifica la proprietà.
- Modifica il file mapred-site.xml e modifica la proprietà.
- Modifica yarn-site.xml e modifica la proprietà.
- Modifica hadoop-env.sh e aggiungi il percorso Java.
- Vai alla directory home di Hadoop e formatta il NameNode.
- Vai alla directory hadoop-2.7.3/sbin e avvia tutti i daemon.
- Verifica che tutti i servizi Hadoop siano in esecuzione.
Ed ecco fatto, dovresti ora avere un HDFS installato con successo.
Come accedere ai file HDFS
Non sorprenderà che la sicurezza sia rigorosa quando si tratta di HDFS, dato che abbiamo a che fare con i dati. Poiché HDFS è tecnicamente uno spazio di archiviazione virtuale, si estende attraverso il cluster, quindi puoi vedere solo i metadati sul tuo file system, non sarai in grado di visualizzare i dati specifici effettivi.
Per accedere ai file HDFS puoi scaricare il file "jar" da HDFS sul tuo file system locale. Puoi anche accedere all'HDFS utilizzando la sua interfaccia utente web. Apri semplicemente il tuo browser e digita "localhost:50070" nella barra di ricerca. Da lì, puoi vedere l'interfaccia utente web di HDFS e spostarti nella scheda utilities sul lato destro. Quindi fai clic su "browse file system", questo ti mostrerà un elenco completo dei file presenti nel tuo HDFS.
Esempi HDFS DFS
Ecco alcuni degli esempi di comandi Hadoop più comuni.
Esempio A
Per eliminare una directory è necessario applicare quanto segue (nota: questo può essere fatto solo se i file sono vuoti):
Oppure
Esempio B
Quando hai più file in un HDFS, puoi usare un comando "-getmerge". Questo unirà più file in un unico file, che potrai quindi scaricare sul tuo file system locale. Puoi farlo con il seguente:
Oppure
Esempio C
Quando vuoi caricare un file da HDFS a locale, puoi usare il comando "-put". Specifichi da dove vuoi copiare e quale file vuoi copiare su HDFS. Usa quanto segue:
Oppure
Esempio D
Il comando count viene utilizzato per tracciare il numero di directory, file e dimensioni dei file su HDFS. Puoi usare quanto segue:
Oppure
Esempio E
Il comando "chown" può essere utilizzato per cambiare il proprietario e il gruppo di un file. Per attivarlo, usa quanto segue:
Oppure
Cos'è lo storage HDFS?
Come sappiamo ora, i dati HDFS sono archiviati in qualcosa chiamato blocchi. Questi blocchi sono l'unità più piccola di dati che il file system può archiviare. I file vengono elaborati e suddivisi in questi blocchi, che vengono quindi presi e distribuiti attraverso il cluster - e anche replicati per sicurezza. Tipicamente, ogni blocco può essere replicato tre volte. Questo diagramma mostra i big data e come possono essere archiviati con HDFS.
Il primo lo trovi sul DataNode, il secondo è archiviato su un DataNode separato all'interno del cluster e un terzo è archiviato su un DataNode in un cluster diverso. Questo è come un triplo passaggio di sicurezza. Quindi, se dovesse succedere il peggio e una replica fallisce, i dati non sono persi per sempre.
Il NameNode conserva informazioni importanti, come il numero di blocchi e dove sono archiviate le repliche. Al contrario, un DataNode archivia i dati effettivi e può creare blocchi, rimuovere blocchi e replicare blocchi su comando. Sembra così:
Questo determina dove i DataNode dovrebbero archiviare i suoi blocchi.
Come archivia i dati HDFS?
Il file system HDFS è costituito da un set di servizi Master (NameNode, secondary NameNode e DataNodes). Il NameNode e il secondary NameNode gestiscono i metadati HDFS. I DataNodes ospitano i dati HDFS sottostanti.
Il NameNode tiene traccia di quali DataNodes contengono il contenuto di un dato file in HDFS. HDFS divide i file in blocchi e archivia ogni blocco su un DataNode. Più DataNodes sono collegati al cluster. Il NameNode distribuisce quindi repliche di questi blocchi di dati attraverso il cluster. Inoltre, istruisce l'utente o l'applicazione su dove trovare le informazioni desiderate.
Cosa è progettato per gestire il file system distribuito Hadoop (HDFS)?
In parole povere, quando si chiede "cosa è progettato per gestire il file system distribuito Hadoop?" La risposta è prima di tutto - i big data. Questo può essere inestimabile per le grandi aziende che altrimenti avrebbero difficoltà a gestire e archiviare dati dalle loro attività e dai loro clienti.
Con Hadoop, puoi archiviare e unire dati, che si tratti di dati transazionali, scientifici, social media, pubblicitari e di machine learning. Significa anche che puoi tornare a questi dati e ottenere preziose informazioni sulle prestazioni aziendali e sull'analisi.
Poiché è stato progettato per archiviare dati, HDFS può anche gestire dati grezzi che sono comunemente utilizzati da scienziati o persone nel campo medico che cercano di analizzare tali dati. Questi sono chiamati data lake. Permette loro di affrontare domande più difficili senza restrizioni.
Inoltre, poiché Hadoop è stato progettato principalmente per gestire enormi volumi di dati in vari modi, può anche essere utilizzato per eseguire algoritmi a scopo analitico. Ciò significa che aiuta le aziende a elaborare e analizzare i dati in modo più efficiente, consentendo loro di scoprire nuove tendenze e anomalie. Alcuni set di dati vengono persino rimossi dai data warehouse e spostati in Hadoop. Rende semplicemente più facile archiviare tutto in un unico posto facilmente accessibile.
Quando si tratta di dati transazionali, Hadoop è anche attrezzato per gestire milioni di transazioni. Grazie alle sue capacità di archiviazione ed elaborazione, può essere utilizzato per archiviare e analizzare i dati dei clienti. Puoi anche approfondire i dati per scoprire tendenze e modelli emergenti per aiutare con gli obiettivi aziendali. Non dimenticare, Hadoop viene costantemente aggiornato con nuovi dati e puoi confrontare dati nuovi e vecchi per vedere cosa è cambiato e perché.
Considerazioni su HDFS
Per impostazione predefinita, HDFS è configurato con replicazione 3x, il che significa che i set di dati avranno due copie aggiuntive. Sebbene ciò migliori la probabilità di dati localizzati durante l'elaborazione, introduce costi di archiviazione aggiuntivi.
- HDFS funziona al meglio quando è configurato con storage collegato localmente. Ciò garantisce le migliori prestazioni per il file system.
- Aumentare la capacità di HDFS richiede l'aggiunta di nuovi server (calcolo, memoria, disco), non solo supporti di archiviazione.
HDFS vs. Cloud Object Storage
Come accennato in precedenza, la capacità di HDFS è strettamente legata alle risorse di calcolo. Aumentare la capacità di archiviazione implica l'aumento delle risorse CPU, anche se quest'ultima non è richiesta. Quando si aggiungono più nodi dati a HDFS, è necessaria un'operazione di ribilanciamento per distribuire i dati esistenti sui server appena aggiunti.
Questa operazione può richiedere del tempo. Scalare un cluster Hadoop in un ambiente on-premises può anche essere difficile in termini di costi e spazio. HDFS utilizza storage collegato localmente che può fornire vantaggi in termini di prestazioni IO, supponendo che YARN possa fornire l'elaborazione sui server che archiviano i dati da elaborare.
Con ambienti pesantemente utilizzati, è possibile che la maggior parte delle operazioni di lettura/scrittura dei dati avvenga sulla rete anziché localmente. Lo storage a oggetti cloud include tecnologie come Azure Data Lake Storage, AWS S3 o Google Cloud Storage. È indipendente dalle risorse di calcolo che vi accedono e quindi i clienti possono archiviare quantità molto maggiori di dati nel cloud.
I clienti che desiderano archiviare Petabyte di dati possono farlo facilmente nell'archiviazione di oggetti cloud. Tuttavia, tutte le operazioni di lettura e scrittura sull'archiviazione cloud avverranno tramite la rete. Pertanto, è importante che le applicazioni che accederanno ai suoi dati sfruttino la cache ove possibile o includano logica per ridurre al minimo le operazioni di I/O.
Risorse aggiuntive
- Guida alla migrazione da Hadoop a Lakehouse
- Hub di migrazione
- Ebook sulla modernizzazione del cloud: una guida aziendale al valore nascosto della migrazione da Hadoop
- Demo rapide on-demand della Databricks Lakehouse Platform
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.