Cos'è l'ecosistema Hadoop?
Una suite completa di strumenti open source tra cui HDFS, MapReduce, YARN, Hive e Spark che lavorano insieme per archiviare, elaborare e analizzare enormi set di dati
- HDFS fornisce storage distribuito fault-tolerant utilizzando l'architettura NameNode e DataNode, mentre YARN gestisce le risorse del cluster e MapReduce gestisce l'elaborazione parallela dei dati.
- Apache Hive offre query di tipo SQL tramite HiveQL per le operazioni di data warehouse e Apache Spark fornisce elaborazione in memoria per analisi in tempo reale e apprendimento automatico.
- L'ecosistema include strumenti complementari come Pig per lo scripting, HBase per l'archiviazione NoSQL, Oozie per la pianificazione del flusso di lavoro e Sqoop per il trasferimento dati tra Hadoop e database relazionali.
Che cos'è l'ecosistema Hadoop?
L'ecosistema Apache Hadoop è costituito dai diversi componenti della libreria software Apache Hadoop; comprende progetti open-source e una gamma completa di strumenti complementari. Fra gli strumenti più conosciuti dell'ecosistema Hadoop ci sono HDFS, Hive, Pig, YARN, MapReduce, Spark, HBase, Oozie, Sqoop, Zookeeper ecc. Ecco una veloce panoramica dei componenti dell'ecosistema Hadoop utilizzati più spesso dagli sviluppatori.
Che cos'è HDFS?
Hadoop Distributed File System (HDFS) è uno dei progetti Apache più importanti e il principale sistema di storage di Hadoop. Utilizza un'architettura NameNode e DataNode. È un file system distribuito in grado di memorizzare file di grandi dimensioni, che gira su cluster di hardware comune.
Che cos'è Hive?
Hive è uno strumento per ETL e data warehouse utilizzato per interrogare e analizzare grandi set di dati memorizzati nell'ecosistema Hadoop. Hive svolge tre funzioni principali: riassunto dei dati, query e analisi di dati non strutturati e semi-strutturati in Hadoop. Ha un'interfaccia di tipo SQL, usa un linguaggio HQL che funziona in modo simile a SQL e traduce automaticamente le query in lavori MapReduce.
Che cos'è Apache Pig?
È un linguaggio di scripting di alto livello utilizzato per eseguire query su set di dati di grandi dimensioni utilizzati all'interno di Hadoop. Il semplice linguaggio di scripting di Pig, chiamato Pig Latin, è simile a SQL e ha lo scopo principale di eseguire le operazioni richieste e presentare il risultato finale nel formato desiderato.
Il playbook sull'AI agentiva per l'enterprise

Che cos'è MapReduce?

È un altro livello di elaborazione dei dati di Hadoop. Consente di elaborare grandi quantità di dati strutturati e non, e di gestire file di dati molto grandi in parallelo, suddividendo il lavoro in una serie di compiti indipendenti (sottolavori).
Che cos'è YARN?
YARN è l'acronimo di Yet Another Resource Negotiator, ma è conosciuto da tutti solo con il suo acronimo. È uno dei componenti chiave di Apache Hadoop open-source per la gestione delle risorse. Viene impiegato per gestione dei carichi di lavoro, monitoraggio e implementazione dei controlli di sicurezza. Inoltre, assegna risorse di sistema alle varie applicazioni che girano in un cluster Hadoop, indicando quali compiti devono essere eseguiti da ciascun nodo del cluster. YARN ha due componenti principali:
- Resource Manager
- Node Manager
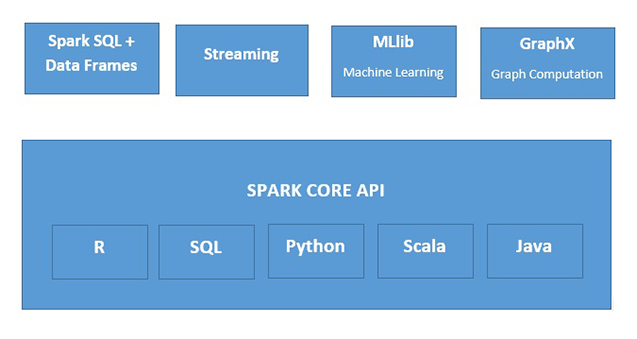
Che cos'è Apache Spark?
Apache Spark è un veloce motore di elaborazione dei dati in memoria, adatto per un ampio ventaglio di situazioni. Spark può essere implementato in molti modi, usa linguaggi di programmazione Java, Python, Scala e R, e supporta SQL, streaming di dati, machine learning ed elaborazione di grafi, che possono essere utilizzati insieme in un'applicazione.
Risorse aggiuntive
- Migrazione passo dopo passo: da Hadoop a Databricks
- Modernizzare il cloud con Databricks e AWS
- Centro risorse di Databricks sulla migrazione
- Whitepaper: il valore nascosto della migrazione da Hadoop
- È ora di rivalutare la relazione con Hadoop
- Delta Lake ed ETL
- Migliorare Apache Spark™ con Delta Lake
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.