Che cos'è un database relazionale (RDBMS)?
Archivia e gestisci dati strutturati in tabelle con relazioni definite, garantendo l'integrità dei dati tramite proprietà ACID
- Comprendere cosa sono i sistemi di gestione di database relazionali (RDBMS) e come organizzano i dati in tabelle strutturate con relazioni.
- Approfondire i principi dei database relazionali, tra cui chiavi primarie, chiavi esterne, normalizzazione e query basate su SQL.
- Scoprire perché le soluzioni RDBMS rimangono essenziali per i sistemi transazionali che richiedono coerenza dei dati e integrità referenziale.
Che cos'è un database relazionale?
Un database relazionale è un tipo di database che archivia e fornisce l'accesso a dati in tabelle che possono essere collegate tra loro tramite colonne e righe condivise, chiamate relazioni, con identificatori univoci (chiavi) che mostrano le diverse relazioni tra le tabelle.
Questo modello relazionale è simile a un modello a foglio di calcolo in cui le righe rappresentano i singoli record, come clienti, account o transazioni, mentre le colonne rappresentano gli attributi di tali record, come l'ID cliente, il numero di account o l'importo della transazione. Utilizzando questo modello, le righe di una tabella possono essere collegate alle righe di un'altra tabella utilizzando chiavi comuni che stabiliscono le relazioni tra le tabelle.
Questo modello fornisce un modo standard per rappresentare ed eseguire query sui dati che può essere utilizzato da una moltitudine di applicazioni.
Un sistema di gestione di database relazionali (RDBMS) è un sistema software (a volte indicato come motore di database) che implementa il modello di database relazionale e gestisce i dati relazionali, non solo le tabelle, dalle scritture e letture su/da dischi, al mantenimento degli indici, all'esecuzione di query e all'applicazione dell'integrità dei dati.
Concetti fondamentali del modello relazionale
Tabelle, righe e colonne
La struttura fondamentale del modello relazionale è l'organizzazione dei dati in tabelle, righe e colonne. Le tabelle sono strutture di dati bidimensionali create per mostrare una raccolta di dati correlati, organizzati in modo logico per consentire l'esecuzione di query strutturate.
Le righe rappresentano entità o record specifici (tuple) in una tabella di un database relazionale e contengono il valore per ogni colonna.
Le colonne rappresentano le categorie di attributi per ogni record in una riga.
In sostanza, le colonne definiscono la struttura e le righe forniscono i dati effettivi. Una semplice tabella di prodotti potrebbe includere le seguenti righe di prodotti specifici con colonne di attributi associati:
| ID prodotto | Nome prodotto | Tipo di prodotto | Prezzo ($) |
|---|---|---|---|
| PSHL16 | Salsiccia di maiale piccante di Chuck | Salsicce di maiale piccanti (1 libbra) | 5.99 |
| PSML16 | Salsiccia di maiale delicata di Chuck | Salsicciotti di maiale delicati (1 lb) | 5.99 |
| GTS16 | Salsiccia di tacchino macinato di Chuck | Carne di tacchino macinata e condita (1 lb) | 6.59 |
| GT48 | Tacchino macinato di Chuck | Tacchino macinato (3 libbre) | 18.59 |
Schema e dati strutturati
Lo schema di un database relazionale descrive la struttura del database. Definisce un modello di come dovrebbero apparire i dati e le regole che devono seguire. I dati strutturati vengono archiviati in un formato coerente e prevedibile secondo quello schema (righe e colonne con relazioni coerenti che definiscono quali tipi di dati possono essere inseriti e come devono essere rappresentati).
Un buon schema garantisce l'integrità e la coerenza dei tipi di dati. Con una struttura nota, è possibile ottimizzare l'archiviazione e le query per mantenere le prestazioni e migliorare la comprensione, poiché ogni tabella e colonna ha lo stesso significato.
Vincoli e indici
Possono esserci vincoli e regole quando si scrive in una tabella. Ad esempio, nell'esempio precedente, ogni prodotto deve essere associato a un ID prodotto reale e ogni tipo di prodotto descriverà i prodotti confezionati (link) o macinati insieme al loro peso in modo coerente. Può inoltre impostare dei paletti, ad esempio stabilendo che ogni colonna debba contenere valori (NOT NULL) senza duplicati (UNIQUE), ad eccezione del prezzo.
Ciò significa che ogni riga ha gli stessi campi e ogni campo ha lo stesso significato. Con uno schema rigido, i dati rimangono puliti, le relazioni rimangono valide e le query rimangono prevedibili.
I database relazionali possono anche avere indici che rendono più rapida la ricerca delle righe senza una scansione completa della tabella. Un indice memorizza i valori della colonna e fornisce puntatori alle righe della tabella in cui tali valori compaiono. Le prestazioni possono diminuire quando si eseguono query su tabelle di grandi dimensioni e l'indicizzazione evita la scansione di ogni riga di una tabella.
I database memorizzano gli indici in diversi tipi di strutture ottimizzate per migliorare la velocità di recupero dei dati:
- L'indicizzazione ad albero B è una struttura di dati comune progettata per gestire in modo efficiente grandi set di dati riducendo l'altezza dell'albero. Ogni nodo in un albero B può memorizzare più chiavi e avere più figli, il che riduce al minimo il numero di attività operative di I/O su disco necessarie per l'accesso ai dati. Consentendo un numero maggiore di figli sotto un singolo nodo rispetto a un normale albero di ricerca binario autobilanciato, l'albero B riduce l'altezza dell'albero e inserisce i dati in un numero inferiore di blocchi separati.
- Le tabelle hash sono strutture di dati che associano le chiavi ai valori e utilizzano una funzione hash per convertire una chiave in un indice in cui è memorizzato il valore corrispondente. Gli indici basati su hash sono efficaci per le ricerche di corrispondenza esatta, ma non sono universalmente supportati o utilizzati come tipo di indice default in tutti gli RDBMS e non preservano l'ordinamento come gli alberi B (B-Tree).
Chiavi e relazioni
Le chiavi sono essenziali per garantire l'unicità, l'integrità e il recupero efficiente dei dati. Identificano in modo univoco le righe, stabiliscono relazioni tra le tabelle e prevengono la duplicazione, formando la spina dorsale della progettazione dello schema relazionale. I punti dati nelle tabelle possono essere uniti tramite chiavi comuni, rendendo possibile interrogare le tabelle per produrre report. Utilizzando chiavi comuni, le relazioni possono essere uno-a-uno, uno-a-molti e molti-a-molti.
Le tabelle si collegano con diversi tipi di chiavi:
- Le superchiavi sono insiemi di uno o più attributi che possono identificare univocamente un record
- Una chiave candidata è un insieme minimo di attributi in grado di identificare in modo univoco un record
- Una chiave primaria è una chiave univoca che identifica una riga nella sua tabella. Ad esempio, in una tabella clienti, l'ID cliente sarebbe una chiave primaria.
- Una chiave alternativa è una chiave candidata non scelta come chiave primaria.
- Una chiave esterna è una colonna che fa riferimento a una chiave primaria in un'altra tabella. Ad esempio, una tabella delle transazioni potrebbe fare riferimento all'ID cliente dalla tabella dei clienti con Orders.customer_id.
- Una chiave composita è necessaria quando per identificare tutti i record di una tabella serve una combinazione di due o più attributi
Proprietà chiave dei database relazionali
I database relazionali sono gruppi di attività operative (transazioni) che funzionano insieme e hanno diverse caratteristiche distintive per renderli affidabili. Queste transazioni seguono una serie di regole note come ACID, che sta per:
- Atomicità: tutti gli aggiornamenti devono essere completati interamente.
- Coerenza: le regole vengono sempre applicate
- Isolamento: le transazioni concorrenti non interferiscono con gli stati intermedi l'una dell'altra
- Durabilità: una volta confermati, i dati possono sopravvivere a crash o interruzioni
Queste regole aiutano a garantire l'integrità dei dati a livello transazionale, garantendo che le attività operative del database vengano completate in modo affidabile e corretto. La progettazione dello schema, i tipi di dati e i vincoli sono responsabili di garantire che i valori nelle colonne siano atomici e coerenti nel significato. I vincoli vengono utilizzati per mantenere la coerenza tra più tabelle.
Un'altra proprietà chiave dei database relazionali è lo Structured Query Language (SQL), il linguaggio più comune per l'estrazione dei dati. Poiché i dati sono memorizzati in tabelle prevedibili con relazioni, SQL viene utilizzato per rispondere in modo efficiente a domande complesse per aiutare ad analizzare i dati. Offre un metodo standard per eseguire query, recuperare dati, inserire/aggiornare/eliminare record, creare nuovi database o nuove tabelle e impostare autorizzazioni su tabelle, procedure e viste.
I database relazionali devono anche garantire la sicurezza/il controllo degli accessi per proteggere i dati secondo diverse dimensioni:
- Autenticazione: coloro che accedono al database sono chi dichiarano di essere.
- Autorizzazione – Fare ciò che si è autorizzati a fare
- Auditing – Conferma di cosa è stato fatto e quando.
La sicurezza del database include anche funzionalità come la crittografia per proteggere i dati in caso di intercettazione o furto e il backup e ripristino per non perdere i dati in caso di guasti del sistema.
I database relazionali sono diventati i "sistemi di registrazione" predefiniti grazie alla loro standardizzazione e maturità. Funzionalità, strutture e capacità standard mantengono un RDBMS prevedibile, affidabile, sicuro e scalabile nel tempo. Ad esempio, con SQL come metodo di query standard, i concetti e le competenze di base possono essere trasferiti da un RDBMS all'altro e le applicazioni e gli strumenti per i dati possono essere mantenuti durante le migrazioni. La standardizzazione aumenta anche la concorrenza e la scelta tra i fornitori.
I database relazionali esistono da molto tempo. Questa maturità significa che sono collaudati sul campo per carichi di lavoro reali e ottimizzati per transazioni estremamente raffinate.
Database relazionali e non relazionali
La differenza più ovvia tra database relazionali e non relazionali è che i database non relazionali non archiviano dati strutturati in tabelle. Hanno la flessibilità di archiviare i dati in contenitori nel formato che meglio si adatta ai dati da memorizzare. Questi dati non strutturati e definiti in modo vago possono includere email, documenti aziendali, video e immagini. Ma possono anche archiviare un mix di dati transazionali strutturati e dati non strutturati.
I database non relazionali sono spesso definiti database NoSQL, un termine che in origine significava "non solo SQL", a indicare che questi sistemi non si basano su SQL come interfaccia principale, anche se molti ora supportano l'interrogazione basata su SQL.
I database relazionali utilizzano uno schema fisso con righe, colonne e relazioni con chiavi e join SQL, mentre i database non relazionali archiviano i dati in strutture flessibili che non richiedono uno schema preimpostato, come coppie chiave-valore, nodi/archi e documenti. Con i database relazionali, i dati devono corrispondere allo schema al momento della scrittura, mentre la forma dei dati può variare con i database non relazionali, in cui i dati vengono interpretati al momento della lettura e le relazioni sono solitamente gestite nelle applicazioni, non nel database.
I database relazionali utilizzano inoltre per impostazione predefinita transazioni ACID forti, mentre i database NoSQL sono tradizionalmente progettati per la cosiddetta eventual consistency (coerenza finale) e danno priorità alla disponibilità e alla velocità rispetto alla correttezza.
I database relazionali vengono scelti quando è necessaria una struttura chiara con regole ferree, insieme a un'abbondanza di relazioni tra i punti dati. Un modello relazionale è più adatto per la reportistica e le analitiche con transazioni che devono essere sempre corrette. I database relazionali sono ottimi per le analitiche ad hoc e per il filtraggio e il raggruppamento complessi, mentre quelli non relazionali sono spesso ottimizzati per un set di query ristretto. I database relazionali in genere si scalano verticalmente, con i sistemi moderni che supportano la scalabilità orizzontale tramite repliche, sharding o esecuzione distribuita, spesso con una maggiore complessità, mentre i database non relazionali sono progettati per scalare orizzontalmente e vengono solitamente scelti per reti distribuite di grandi dimensioni.
I database non relazionali vengono scelti per dati flessibili o in rapida evoluzione su vasta scala con modelli di query semplici.
Esempi comuni di RDBMS
- MySQL – Un RDBMS open source, ora di proprietà di Oracle Corp., che implementa lo standard SQL. È spesso la scelta preferita per applicazioni web, sistemi aziendali e servizi critici basati sui dati che richiedono prestazioni elevate. È comunemente utilizzato per applicazioni web, negozi e cataloghi online, account utente e sistemi di autenticazione, registrazione e analitiche, app SaaS e dashboard.
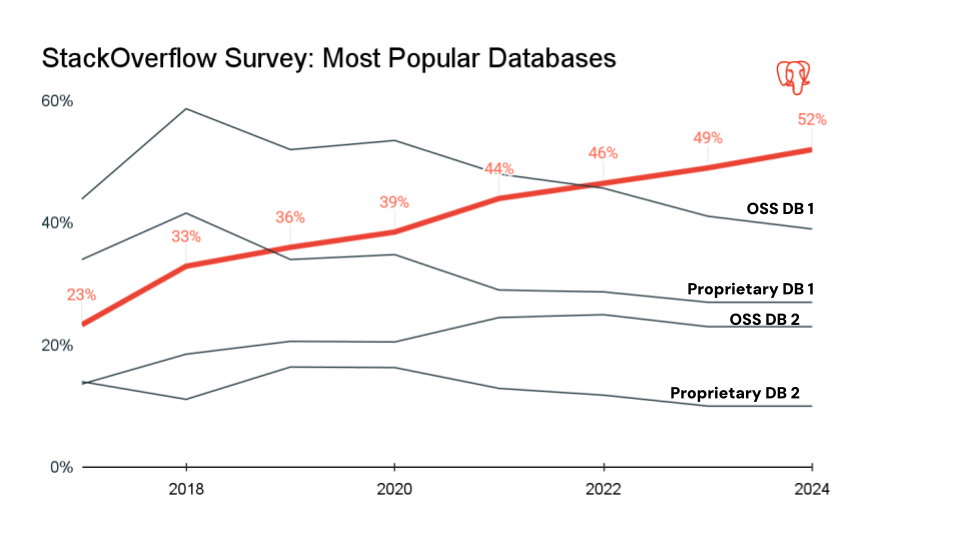
- PostgreSQL – Un RDBMS open-source altamente estensibile, noto per i suoi standard rigorosi e la conformità ACID, con un buon equilibrio tra affidabilità e flessibilità. Supporta sia l'archiviazione SQL che quella semi-strutturata JSON/JSONB e utilizza il Multi-Version Concurrency Control. PostgreSQL viene utilizzato per app web, piattaforme SaaS multi-tenant, transazioni finanziarie, analitiche e reporting, dati scientifici e carichi di lavoro OLTP. È popolare tra le aziende che operano esclusivamente online. Negli ultimi sette anni, Postgres è diventato il database più popolare nella community degli sviluppatori ed è la scelta di database de facto per le applicazioni moderne.
- SQLite – Un database relazionale serverless, multipiattaforma e open source che utilizza SQL e viene eseguito all'interno di un'applicazione tramite una libreria C leggera. Non richiede alcuna configurazione o amministrazione. SQLite è utilizzato principalmente per i sistemi embedded e per piccole applicazioni su dispositivi personali.
- Oracle: un RDBMS proprietario di livello enterprise sviluppato da Oracle Corp. Noto per scalabilità, clustering e affidabilità, è ottimizzato per carichi di lavoro sia transazionali (OLTP) sia analitici (OLAP) e utilizzato per i settori bancario, aereo, sanitario, delle telecomunicazioni, governativo e per sistemi ERP/CRM su larga scala.
- Microsoft SQL Server – RDBMS proprietario di livello enterprise di Microsoft basato su Transact-SQL (T-SQL), l'estensione SQL di Microsoft. Disponibile su Windows e Linux, SQL Server è noto per i suoi strumenti di gestione e amministrazione e per la sua forte integrazione con Microsoft Azure e altre tecnologie Microsoft. I casi d'uso tipici includono ERP, CRM, HR, e-commerce, Business Intelligence e analitiche. SQL Server è molto diffuso nei settori finanziario, bancario e sanitario.
- IBM Db2 – Una famiglia proprietaria di sistemi RDBMS sviluppata da IBM per l'elaborazione di dati ad alte prestazioni, affidabilità e su scala aziendale. Le versioni RDBMS di Db2 funzionano su più piattaforme, tra cui Linux, UNIX, Windows, IBM AS/400 e mainframe IBM. È basato su SQL ma in alcune versioni supporta documenti JSON, archiviazione XKL, dati di serie temporali, archiviazione a colonne e funzionalità Graph. È ampiamente utilizzato in ambienti finanziari, governativi, sanitari e assicurativi, di vendita al dettaglio, aerei e IT aziendali.
- MariaDB – Un RDBMS open source creato come sostituto drop-in di MySQL, guidato dalla community e gestito dalla MariaDB Foundation. È ampiamente utilizzato per carichi di lavoro sia OLTP che OLAP in app web, piattaforme SaaS, sistemi cloud e aziende, ed è una scelta frequente per i sistemi Linux e gli stack open source. I casi d'uso comuni includono app e siti web, piattaforme SaaS, gestione dei contenuti, e-commerce e analitiche.
Il playbook sull'AI agentiva per l'enterprise

Domande frequenti su SQL, RDBMS e argomenti correlati
SQL è un database relazionale?
No, SQL è un linguaggio di query utilizzato per interagire con un database relazionale, non un sistema di database.
MySQL è un database relazionale?
Sì, MySQL è un RDBMS con una struttura basata su tabelle che supporta le relazioni tra di esse.
Excel è relazionale?
No, Excel è il programma di fogli di calcolo di Microsoft, non un RDBMS. Anche se Excel utilizza un formato a tabella, non esiste uno schema forzato con una struttura e vincoli coerenti. Excel non può eseguire query SQL da solo e non supporta le transazioni ACID.
Qual è la differenza tra la terminologia di database relazionale e RDBMS?
Sebbene strettamente correlati e spesso usati in modo intercambiabile, i database relazionali si riferiscono al modello di dati stesso, mentre un RDBMS è un sistema software che gestisce tale modello di dati.
Vantaggi e limiti
I vantaggi dell'utilizzo dei database relazionali includono:
- Elevata integrità dei dati e consistenza garantite dalle transazioni ACID per assicurare che non vi siano aggiornamenti parziali, dati corrotti e per avere attività operative affidabili. Dati strutturati e ben definiti garantiscono dati puliti e prevedibili.
- Le funzionalità di interrogazione standardizzate e gli strumenti con SQL forniscono filtri, raggruppamenti, aggregazioni, indicizzazioni e join complessi che rendono i database relazionali ideali per le analitiche, il reporting e la logica di business complessa.
- Con decenni di maturità, i database relazionali sono ben supportati, con prestazioni affidabili, solidi modelli di sicurezza e disponibilità e un ecosistema di strumenti per ridurre i rischi.
Le limitazioni includono:
- Lo schema rigido e fisso dei database relazionali riduce l'agilità e non è adatto a dati non strutturati o semi-strutturati e a forme di record che cambiano frequentemente.
- I database relazionali sono ottimi per la scalabilità verticale, ma la scalabilità orizzontale è complessa.
- Le prestazioni possono diminuire con set di dati molto grandi e join complessi, che possono rallentare i carichi di lavoro distribuiti.
- Gli RDBMS commerciali possono essere costosi, soprattutto su larga scala.
- L'OLTP non è concepito per query analitiche complesse.
- Facilità di creare silos di dati, con conseguente aumento dei costi di archiviazione.
- Complessità dell'ETL (nel caso di spostamento di dati avanti e indietro tra archivi operativi e analitici).
- Gestione di dati semi-strutturati (Delta, Iceberg, Parquet: ciò che si trova nella lakehouse).
- Difficoltà con i tipi di dati non standard per l'integrazione con ML/IA
- Non progettati per gestire dati in streaming
- Evita di essere vincolato a un unico fornitore
Evoluzione oltre gli RDBMS tradizionali
- Era dei data warehouse: gli RDBMS sono progettati per l'utilizzo di dati correnti e sono ottimizzati per molte piccole letture/scritture per l'Online Transaction Processing (OLTP). Di conseguenza, possono avere difficoltà con le analitiche su Scale. Per superare questa limitazione, i data warehouse utilizzano schemi denormalizzati in grado di gestire query enormi e complesse su dati correnti e storici per l'Online Analytical Processing (OLAP).
- La sfida dei big data: gli RDBMS hanno difficoltà a gestire dati massivi, veloci, diversificati e distribuiti. Lo schema rigido, la scalabilità verticale e l'overhead delle transazioni ACID li hanno resi meno adatti per le analitiche distribuite su larga scala. Gli RDBMS tradizionali si basano su join eseguiti su uno spazio di archiviazione gestito localmente, il che limita la scalabilità negli ambienti distribuiti.
- Requisiti nativo per il cloud: i sistemi di database relazionali tradizionali hanno difficoltà nelle architetture nativo per il cloud che prediligono l'object storage. Sono progettati per il block storage con hardware strettamente accoppiato e accesso al disco a bassa latenza. Storicamente, l'object storage non forniva le garanzie di bassa latenza richieste per l'elaborazione delle transazioni ACID classiche, rendendolo una sfida per i design RDBMS tradizionali. L'object storage è ottimizzato per il throughput piuttosto che per la latenza. Le applicazioni nativo per il cloud scalano anche orizzontalmente, mentre i design RDBMS tradizionali si basano su compute e archiviazione strettamente accoppiate, spesso incentrate su un server primario.
- Data lake moderni: le architetture Lakehouse si sono evolute per superare i limiti dei data lake tradizionali combinando la scalabilità e il basso costo dei data lake con la struttura, la governance e le caratteristiche prestazionali dei data warehouse e dei sistemi relazionali.
Un lakehouse utilizza l'archiviazione a oggetti nativo per il cloud per la persistenza dei dati, introducendo al contempo formati di tabella gestiti, livelli di metadati e log delle transazioni che abilitano l'applicazione di uno schema, l'accesso SQL e le transazioni ACID direttamente su tale archiviazione. Ciò consente a dati strutturati, semi-strutturati e non strutturati di coesistere in un unico sistema.
A differenza dei primi data lake che si basavano molto sullo schema-on-read e sulla logica di elaborazione esterna, le architetture lakehouse supportano lo schema-on-write o l'evoluzione gestita di uno schema a livello di tabella. Ciò consente definizioni di dati coerenti, l'applicazione della qualità dei dati e analitiche affidabili. Disaccoppiando l'archiviazione dal compute, le architetture lakehouse consentono a più motori di compute di operare sugli stessi dati per le analitiche, l'ingegneria dei dati, lo streaming e il machine learning. Questa flessibilità rende le architetture lakehouse adatte per analitiche su larga Scale, Business Intelligence e carichi di lavoro di dati avanzati, mantenendo al contempo l'efficienza dei costi e l'apertura attraverso formati di file e tabelle aperti. - Architettura Lakebase: un lakebase è una nuova categoria di database operativo progettato per applicazioni moderne e intelligenti. Mentre gli RDBMS eccellono nella coerenza transazionale e negli schemi strutturati, sono isolati dai dati analitici, dalle pipeline di machine learning e dall'intelligence in tempo reale da cui le applicazioni dipendono sempre di più. Un Lakebase combina le funzionalità principali di un database come transazioni, indicizzazione e accesso a bassa latenza con l'integrazione nativa con la lakehouse, consentendo alle applicazioni di operare direttamente su dati freschi, condivisi, analitici e pronti per l'IA. Ciò consente a un singolo sistema di supportare sia i carichi di lavoro operativi sia il comportamento intelligente delle applicazioni basato su dati, senza duplicare i dati o suddividere le architetture.
Sfatare i miti comuni
- Tutti i database sono relazionali
Esistono molti database non relazionali che non seguono il modello relazionale (archiviare i dati in tabelle e utilizzare SQL per definire ed eseguire query su le relazioni). - I database relazionali sono solo SQL
La maggior parte dei database relazionali utilizza SQL come linguaggio principale. SQL è stato creato per il modello relazionale, ma alcuni database utilizzano altri linguaggi relazionali, come Quel, Tutorial D, Rel e Datalog. - I database relazionali sono obsoleti
I database relazionali non sono affatto obsoleti. Restano ineguagliati per i dati complessi e strutturati e costituiscono ancora la spina dorsale dei sistemi mission-critical di oggi. E SQL è ancora uno dei linguaggi più utilizzati. Oggi i database relazionali coesistono con NoSQL, data lake e lakehouse, poiché i casi di utilizzo dei dati continuano a evolversi.
Conclusione
I database relazionali con schema strutturato che organizzano i dati in tabelle, righe e colonne, con chiavi e join per un recupero rapido dei dati e transazioni ACID affidabili, rimangono un'architettura fondamentale per applicazioni aziendali mission-critical sicure. Con una struttura progettata per query veloci e affidabili, i database relazionali forniscono l'integrità e la coerenza dei tipi di dati ed è possibile ottimizzare l'archiviazione e le query per mantenere le prestazioni. Possono anche coesistere con database non relazionali in moderni ambienti distribuiti di data lake e lakehouse.
La standardizzazione e la maturità degli RDBMS li rendono collaudati per carichi di lavoro reali e ottimizzati per transazioni estremamente precise. Le architetture moderne come la lakebase estendono queste comprovate basi relazionali negli ambienti nativo per il cloud, consentendo all'affidabilità relazionale e alle analitiche basate su SQL di coesistere con l'object storage scalabile e il compute distribuito.
Risorse aggiuntive
- Introduzione per principianti che tratta tabelle, relazioni e concetti di base
- Panoramica completa dell'architettura, delle funzionalità e delle applicazioni aziendali dei sistemi RDBMS
- Spiegazione completa dalla 1NF alla 5NF con esempi
- Analisi dettagliata di atomicità, consistenza, isolamento e durabilità
- Copertura completa che include le regole di Codd e i fondamenti teorici
- Lakehouse: una nuova generazione di piattaforme aperte che unifica data warehouse e analisi avanzata
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.